基本思路
- 了解豆瓣圖書網頁結構
- 匯入相關模塊包gevent、request、BeautifulSoup、csv
- 使用monkey.patch_all()方法變成協作式運行
- 利用request獲取網頁回應內容
- 利用BeautifulSoup決議網頁內容,并提取所需的標簽內容
- 創建佇列物件,利用佇列相應的方法,創建多任務執行
- 保存為CSV檔案格式
-
很多人學習python,不知道從何學起,
很多人學習python,掌握了基本語法過后,不知道在哪里尋找案例上手,
很多已經做案例的人,卻不知道如何去學習更加高深的知識,
那么針對這三類人,我給大家提供一個好的學習平臺,免費領取視頻教程,電子書籍,以及課程的源代碼!
QQ群:961562169
爬取豆瓣圖書
![]() ?
?
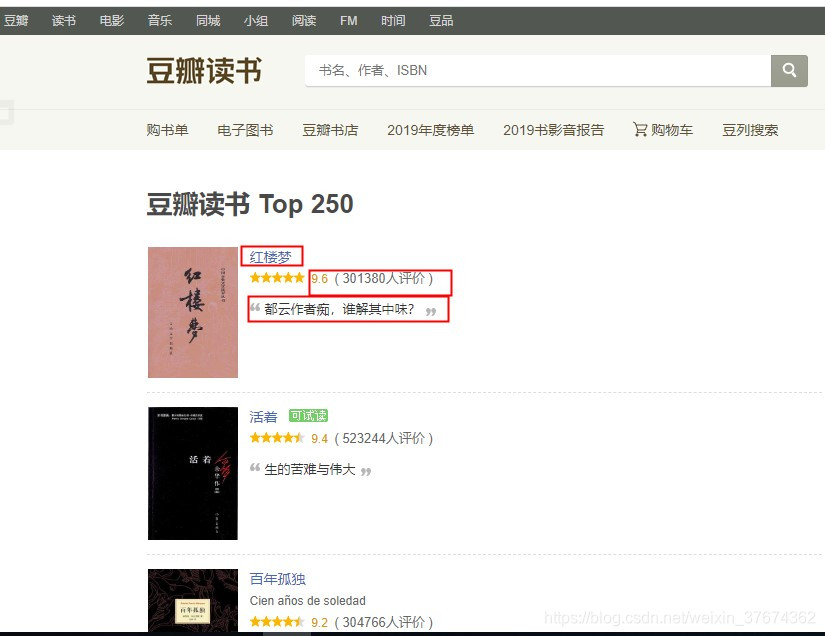
利用多協程和佇列,來爬取豆瓣圖書Top250(書名,作者,評分)并存盤csv 豆瓣圖書:https://book.douban.com/top250?start=0
爬蟲主程式
import csv
from gevent.queue import Queue
import requests
import time
from bs4 import BeautifulSoup
import gevent
from gevent import monkey
# monkey.patch_all()能把程式變成協作式運行,就是可以幫助程式實作異步,注意需放在最前面
monkey.patch_all()
# 計算開始時間
start_time = time.time()
# 偽裝請求頭
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/78.0.3904.108 Safari/537.36'}
url_list = [] # 用于存放URL鏈接
# 使用for回圈生產不同的鏈接,并存放在url_list
for i in range(0, 250, 25):
link = 'https://book.douban.com/top250?start=' + str(i)
url_list.append(link)
# 創建佇列物件,并賦值給work
work = Queue()
# 用put_nowait()函式可以把網址都放進佇列里,
for url in url_list:
work.put_nowait(url)
# 創建一個新的csv檔案用于存放需要提前的資料
book = open('book_info.csv', 'w', newline='', encoding='utf-8')
# 創建列名
column_title = ['書名', '作者', '評分', '鏈接']
writer = csv.writer(book)
# 寫入欄位的列名
writer.writerow(column_title)
# 創建一個新的串列,然后把相應資訊存放到串列中
book_info = []
# 構建一個獲取書籍資訊的函式
def get_info():
# 判斷佇列是否為空并作為回圈的條件
while not work.empty():
# 獲取url
url = work.get_nowait()
# 獲取網頁的回應內容
res = requests.get(url, headers=header)
# 使用BeautifulSoup進行決議提取資料
soup = BeautifulSoup(res.text, 'html.parser')
book_title = soup.find_all('div', class_='pl2')
book_writer = soup.find_all('p', class_="pl")
book_rating_nums = soup.find_all('span', class_="rating_nums")
# 賦予book_info為全域變數
global book_info
for j in range(len(book_title)):
a = book_title[j].a['title'] # 書名
b = book_writer[j].text.strip() # 作者
c = book_rating_nums[j].text.strip() # 評分
d = book_title[j].a['href'] # 書籍鏈接
# 寫入到CSV檔案中
writer.writerow([a, b, c, d])
# 添加到book_info串列
book_info.append([a, b, c, d])
# 查看鏈接、佇列大小、網頁回應狀態
print(url, work.qsize(), res.status_code)
# 創建空任務串列
task_list = []
# 相當于創建3個任務
for k in range(3):
# 用gevent.spawn()函式創建執行crawler()函式的任務
task = gevent.spawn(get_info)
# 往任務串列添加任務
task_list.append(task)
# 用gevent.joinall方法,執行任務串列里的所有任務,就是讓爬蟲開始爬取網站
gevent.joinall(task_list)
# print(book_info)
# 統計執行結束時間
end = time.time()
print(end - start_time)
# 關閉檔案
book.close()
https://book.douban.com/top250?start=0 7 200
https://book.douban.com/top250?start=25 6 200
https://book.douban.com/top250?start=50 5 200
https://book.douban.com/top250?start=125 4 200
https://book.douban.com/top250?start=100 3 200
https://book.douban.com/top250?start=75 2 200
https://book.douban.com/top250?start=150 1 200
https://book.douban.com/top250?start=200 0 200
https://book.douban.com/top250?start=175 0 200
https://book.douban.com/top250?start=225 0 200
2.852992057800293
運行結果

![]() ?
?
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/119950.html
標籤:其他
下一篇:小白求教鏈表多項式加減