服務端性能優化--最大QPS推算及驗證
影響QPS(即吞吐量)的因素有哪些?每個開發都有自己看法,一直以為眾說紛紜,例如:
- QPS受編程語言的影響,(PHP是最好的語言?)
- QPS主要受編程模型的影響,比如不是coroutine、是不是NIO、有沒有阻塞?
- QPS主要由業務邏輯決定,業務邏輯越復雜,QPS越低,
- QPS受資料結構和演算法的影響,
- QPS受執行緒數的影響,
- QPS受系統瓶頸的影響,
- QPS和RT關系非常緊密,
- more...
嗯,這些說法好像都對,但是好像又有點不對,好像總是不太完整,有沒有一個系統點的說法能讓人感覺一聽就豁然開朗?
今天我們就這個話題來闡述一下,將一些現有的理論作為依據,把上方這些看起來比較零碎的看法總結歸納起來,希望能為服務端的性能提升進行一點優化,這也是一個優化的起點,未來才有可能做更多的優化,例如TCP、DNS、CDN、系統監控、多級快取、多機房部署等等優化的手段,

好了,廢話不多說,直接開聊,
我們經常再做優化的時候,例如電商的促銷秒殺等活動頁,一開始可能會認為說Gzip并不是影響CPU的最大因子,直到拿出一次又一次的實驗資料,研發們才開始慢慢接受(尬不尬),這是為什么?難道說Gzip真的是影響CPU的最大因子嗎?那我們就拿出一點資料來驗證一下對吧,接下來我們從RT著手開始慢慢了解,看到文章結尾就知道為什么Gzip和CPU的關系,同事也會發現,性能優化的相關知識其實也是體系化的,并不是分散零碎的,
RT
什么是 RT ?是概念還是名詞還是理論?
RT其實也沒那么玄乎,就是 Response Time (就是回應時間嘛,哈哈哈),只不過看你目前在什么場景下,也許你是c端(app、pc等)的用戶,回應時間是你請求服務器到服務器回應你的時間間隔,對于我們后端優化來說,就是接受到請求到回應用戶的時間間隔,這聽起來怎么感覺這不是在說廢話嗎?這說的不都是服務端的處理時間嗎?不同在哪里?其實這里有個容易被忽略的因素,叫做網路開銷,
所以服務端RT ≈ 網路開銷 + 客戶端RT,也就是說,一個差的網路環境會導致兩個RT差距的懸殊(比如,從深圳訪問上海的請求RT,遠大于上海本地內的請求RT)
客戶端的RT則會直接影響客戶體驗,要降低客戶端RT,提升用戶的體驗,必須考慮兩點,第一點是服務端的RT,第二點是網路,對于網路來說常見的有CDN、AND、專線等等,分別適用于不同的場景,有機會寫個blog聊一下這個話題,
對于服務端RT來說,主要看服務端的做法,
有個公式:RT = Thread CPU Time + Thread Wait Time
從公式中可以看出,要想降低RT,就要降低 Thread CPU Time 或者 Thread Wait Time,這也是馬上要重點深挖的一個知識點,
Thread CPU Time(簡稱CPU Time)
Thread Wait Time(簡稱Wait Time)
單執行緒QPS
我們都知道 RT 是由兩部分組成 CPU Time + Wait Time ,那如果系統里只有一個執行緒或者一個行程并且行程中只有一個執行緒的時候,那么最大的 QPS 是多少呢?
假設 RT 是 199ms (CPU Time 為 19ms ,Wait Time 是 180ms ),那么 1000s以內系統可以接收的最大請求就是
1000ms/(19ms+180ms)≈5.025,
所以得出單執行緒的QPS公式:
\[單執行緒QPS = 1000ms/RT \]最佳執行緒數
還是上面的那個話題 (CPU Time 為 19ms ,Wait Time 是 180ms ),假設CPU的核數1,假設只有一個執行緒,這個執行緒在執行某個請求的時候,CPU真正花在該執行緒上的時間就是CPU Time,可以看做19ms,那么在整個RT的生命周期中,還有 180ms 的 Wait Time,CPU在做什么呢?拋開系統層面的問題(這里不考慮什么時間片輪循、背景關系切換等等),可以認為CPU在這180ms里沒做什么,至少對于當前的業務來說,確實沒做什么,
- 一核的情況
由于每個請求的接收,CPU只需要作業19ms,所以在180ms的時間內,可以認為系統還可以額外接收180ms/19ms≈9個的請求,由于在同步模型中,一個請求需要一個執行緒來處理,因此,我們需要額外的9個執行緒來處理這些請求,這樣,總的執行緒數就是:
多執行緒之后,CPU Time從19ms變成了20ms,這1ms的差值代表多執行緒之后背景關系切換、GC帶來的額外開銷(對于我們java來說是jvm,其他語言另外計算),這里的1ms只是代表一個概述,你也可以把它看做n,
-
兩核的情況
一核的情況下可以有10個執行緒,那么兩核呢?在理想的情況下,可以認為最佳執行緒數為:2 x ( 180ms + 20ms )/20ms = 20個 -
CPU利用率
我們之前說的都是CPU滿載下的情況,有時候由于某個瓶頸,導致CPU不得不有效利用,比如兩核的CPU,因為某個資源,只能各自使用一半的能效,這樣總的CPU利用率就變成了50%,再這樣的情況下,最佳執行緒數應該是:50% x 2 x( 180ms + 20ms )/20ms = 10個
這個等式轉換成公式就是:最佳執行緒數 = (RT/CPU Time) x CPU 核數 x CPU利用率
當然,這不是隨便推測的,在收集到的很多的一些著作或者論壇的檔案里都有這樣的一些實驗去論述這個公式或者這個說法是正確的,
最大QPS
1.最大QPS公式推導
假設我們知道了最佳執行緒數,同時我們還知道每個執行緒的QPS,那么執行緒數乘以每個執行緒的QPS既這臺機器在最佳執行緒數下的QPS,所以我們可以得到下圖的推算,
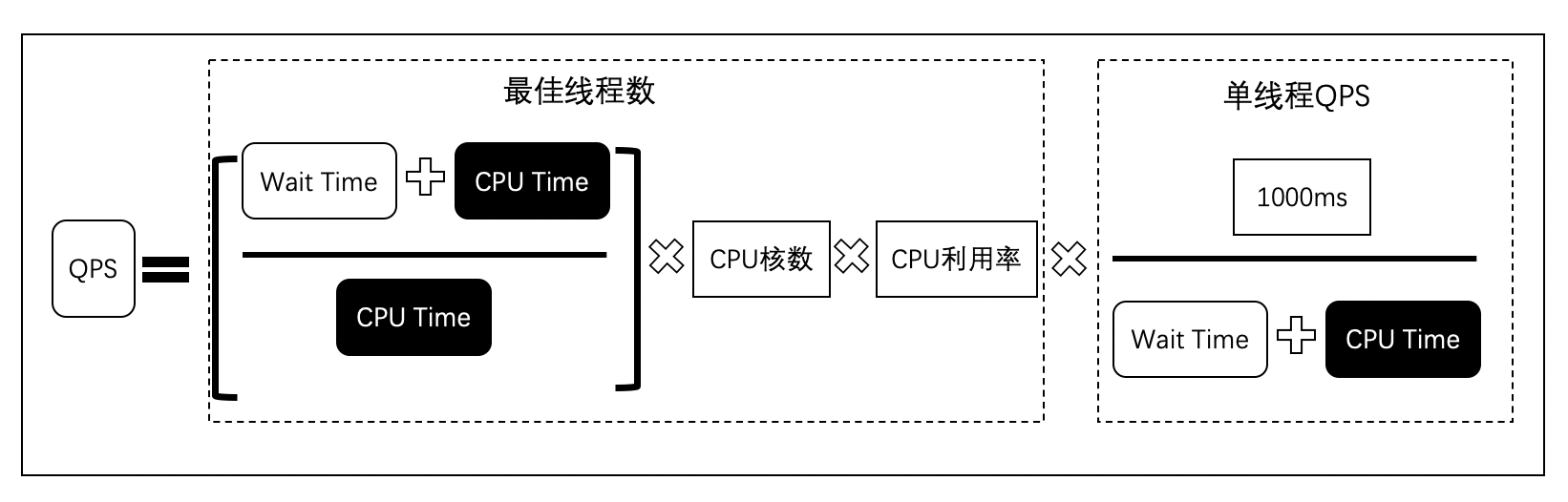
我們可以把分子和分母去約數,如下圖,
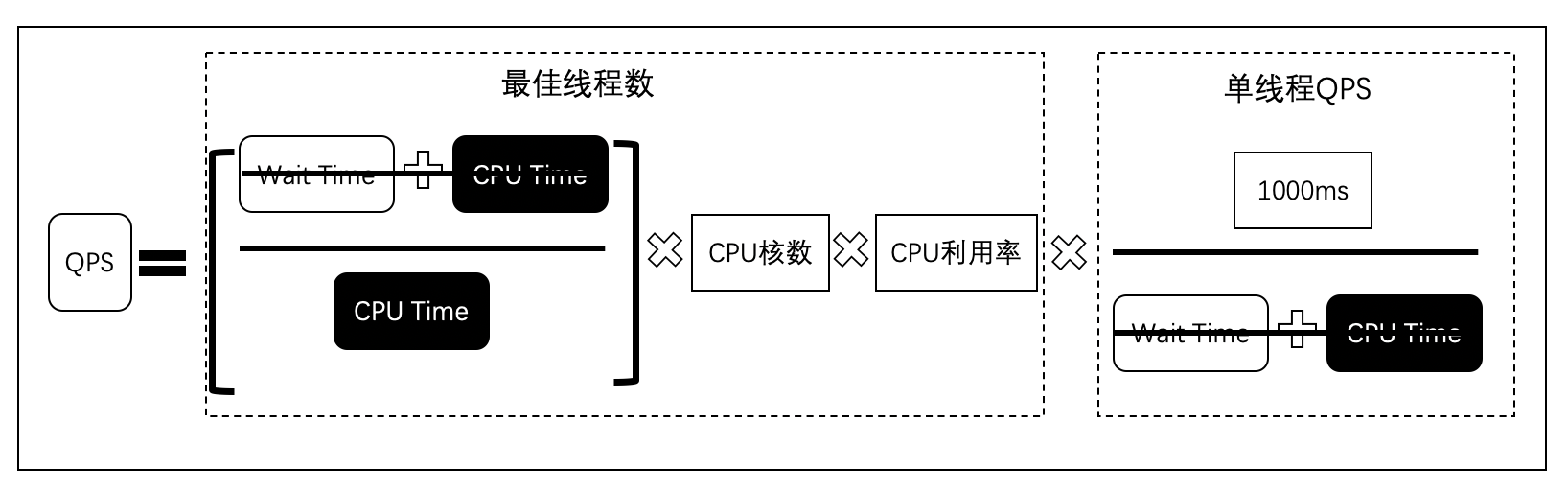
于是簡化后的公式如下圖.
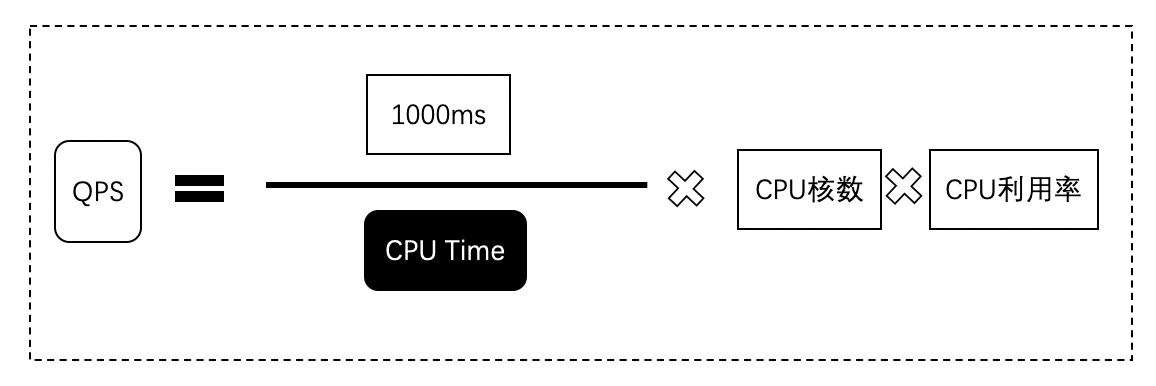
從公式可以看出,決定QPS的時CPU Time、CPU核數和CPU利用率,CPU核數是由硬體做決定的,很難操縱,但是CPU Time和CPU利用率與我們的代碼息息相關,
雖然宏觀上是正確的,但是推算的程序中還是有一點小小的不完美,因為多執行緒下的CPU Time(比如高并發下的GC次數增加消耗更多的CPU Time、執行緒背景關系切換等等)和單執行緒的CPU Time是不一樣的,所以會導致推算出來的結果有誤差,
尤其是在同步模型下的相同業務邏輯中,單執行緒時的CPU Time肯定會比大量多執行緒的CPU Time小,但是對于異步模型來說,切換的開銷會變得小很多,為什么?這里先賣個葫蘆吧,看完本篇就知道了,
既然決定QPS的是CPU Time和CPU核數,那么這兩個因子又是由誰來決定的呢?(越看越懵哈)
2.CPU Time
終于講到了 CPU Time,CPU Time不只是業務邏輯所消耗的CPU時間,而是一次請求中所有環節上消耗的CPU時間之和,比如在web應用中,一個請求過來的HTTP的決議所消耗的CPU時間,是CPU Time的一部分,另外,這個請求中請求RPC的encode和decode所消耗的CPU時間也是CPU Time的一部分,
那么CPU Time是由哪些因素決定的呢?兩個關鍵字:資料結構+演算法,
舉一些例子吧
- 均攤問題
- hash問題
- 排序和查找問題
- 狀態機問題
- 序列化問題
3.CPU利用率
CPU利用率不高的情況時常發生,一下因素都會影響CPU的利用率,從而影響系統可以支持的最大QPS,
1) IO能力
- 磁盤IO
- 網路IO
·帶寬,比如某大促壓力測驗時,由于某個應用放在Tair中的資料量大,導致Tair的機器網卡跑滿,
·網路鏈路,還是這次大促,借用了其他核心交換機下的機器,導致客戶端RT明顯增加,
2) 資料庫連接池(并發能力=PoolWaitTime/RT(Client) x PoolSize),
3) 記憶體不足,GC大量占用CPU,導致給業務邏輯使用的CPU利用率下降,而且GC時還滿足Amdahl定律鎖定義的場景,
4) 共享資源的競爭,比如各種鎖策略(讀寫鎖、鎖分離等),各種阻塞佇列,等等,
5) 所依賴的其他后端服務QPS低造成的瓶頸,
6) 執行緒數或者行程數,甚至編程模型(同步模型,異步模型),
在壓力測驗程序中,出現最多的就是網路IO層面的問題,GC大量占用CPU Time之類的問題也經常出現,
4.CPU核數,Amdahl定律,Gustafson定律
1)Amdahl定律(安達爾定律,不是達爾文定律!!!)
Amdahl定律是用來描述可伸縮性的,什么是可伸縮性?說白了就是比如增加計算機資源,如CPU、記憶體、寬帶等,QPS能夠相應的進行改進,
既然Amdahl定律是描述可伸縮性的,那它是如何描述的呢?
Amdahl在自己的論文中指出,可伸縮性是指在一個系統中,基于可并行化和串行化的組件各自所占的比例,當程式獲得額外的計算資源(如CPU或者記憶體等)時,系統理論上能夠獲得的加速值(QPS或者其他指標可以翻幾倍),用一個公式來表達,如果F表示必須串行化執行的比例,那么在一個N核處理器的機器中,加速:
\[Speedup \leq \frac{1}{F+\frac{1-F}{N}} \]這個公式代表的意義是比較廣泛的,在專案管理中也有一句類似的話:
一個女人生一個孩子要9個月,但是永遠不可能讓9個女人在一個月內就生一個孩子,
我們根據這個例子套一個公式先,這里設F=100%,9個女人表示N=9,于是就有1/(100%+(1-100%)/9)=1,所以9個女人的加速比為1,等于沒有加速,
到這里,其實這個公式還只是描述了在增加資源的情況下系統的加速比,而不是在資源不變的情況下優化資料結構和演算法之后帶來的提升,優化資料結構和演算法帶來的提升要看前文中最大的QPS公式,不過這兩個公式也不是完全沒有聯系的,在增加資源的情況下,它們的聯系還是比較緊密的,
2) Gustafson定律(古斯塔夫森定律)
這個定律名字有點長,但這不是關鍵,關鍵的是,它是Amdahl定律的補充,公式為:
\[S(P) = P-α·(P-1) \]P是處理器的個數,α是串行時間占總執行時間的比例,
生孩子的案例再次套上這個公式,P為女人的個數,等于9,串行比例是100%,Speedup=9-100%x(9-1)=1,也就是9個女人是無法在一個月內把孩子生出來的……
之所以說是Amdahl定律的補充,是因為兩個定律的關系是相輔相成的關系,前者從串行和并行執行時間的角度來推導,后者從串行和并行的計算量角度來推導,不管是哪個角度,最終的結果其實是一樣的,
3)CPU核數和Amdahl定律的關系
通過最大QPS公式,我們發現,在CPU Time和CPU利用率不變的情況下,核數越多,QPS就越大,比如核數從1到4,在CPU Time和CPU利用率不變的情況下,加速比應該是4,所以QPS應該也是增加4倍,
這是資源增加(CPU核數增加)的情況下的加速比,也可以通過Amdahl定律來衡量,考慮串行和并行的比例在增加資源的情況下是否會改變,也就是要考慮在N增加的情況下,F受哪些因素的影響:
\[Speedup \leq \frac{1}{F+\frac{1-F}{N}} \]只要F大于0,最大QPS就不會翻4倍,
一個公式說要增加4被倍,一個定理說 沒有4倍,互相矛盾?
其實事情是這樣的,通過最大QPS公式,我們可以發現,如果CPU Time和CPU 利用率不變,核數從1增加到4,QPS會相應的增加4倍,但是在實際情況下,當核數增加時,CPU Time和CPU 利用率大部分時候是變化的,所以前面的假設不成立,即一般場景下QPS不能增加4倍,
而Amdahl定律中的N變化時,F也可能會變化,即一般場景下,最大QPS并不能增加4被,所以這其實并不矛盾,相反它們是相輔相成的,這里一定要注意,這里說的是一般場景,如果你的場景完全沒有串行(程式沒有串行,系統沒有串行,背景關系切換沒有串行,什么串行都沒有),那么理論上是可以增加4倍的,
為什么增加計算機資源時,最大QPS公式中的CPU Time和CPU利用率會變化,F也會變化呢?我們可以從宏觀上分析一下,增加計算機資源時,達到滿載:
-
QPS會更高,單位時間內產生的物件會更多,在同等條件下,minor GC被觸發的次數增加,還有些場景發生過物件多到回應沒回傳它們就進了“老年代”,從而fullGC被觸發,宏觀上,這是屬于串行的部分,對于Amdahl公式來說F會受到影響,對于最大QPS公式來說,CPU Time和CPU利用率也受到影響.
-
在同步模型下大量的執行緒在完成一次請求中,背景關系被切換的次數大大增加,
-
尤其是在有 串行模塊的時候,串行的執行和等待時間增加,F會變化,某些場景下CPU
利用率也達不到理想效果,這取決于你的代碼,這也是要做鎖分離、為什么要縮小同步
塊的原因,當然還有鎖自身的優化,比如偏向、自旋、讀寫分離等技術,都是為了不斷
地減少Amdahl定律中的F,也是為了減少CPU Time ( 鎖本身的優化),提高CPU利
用率(使用鎖的方法的優化),
,鎖本身的優化最為津津樂道的是自旋、偏向、自適應,synchronized分析,還有reetrantLock的代碼及AQS等等,
,使用鎖的優化方法最常見的是縮小鎖區間、鎖分離、無鎖化、volatile,
所以在增加計算資源時,更高的并發產生,會引起最大QPS公式中兩個引數的變化,也會
引起Amdahl定律中F值的變化,同時公式和定律變化的趨勢是相同的,Amdahl定律是得到廣
泛認可的,也是得到資料驗證的,最大QPS公式好像沒有人驗證過,這里參考一個比較有名的
測驗結果,如下圖.
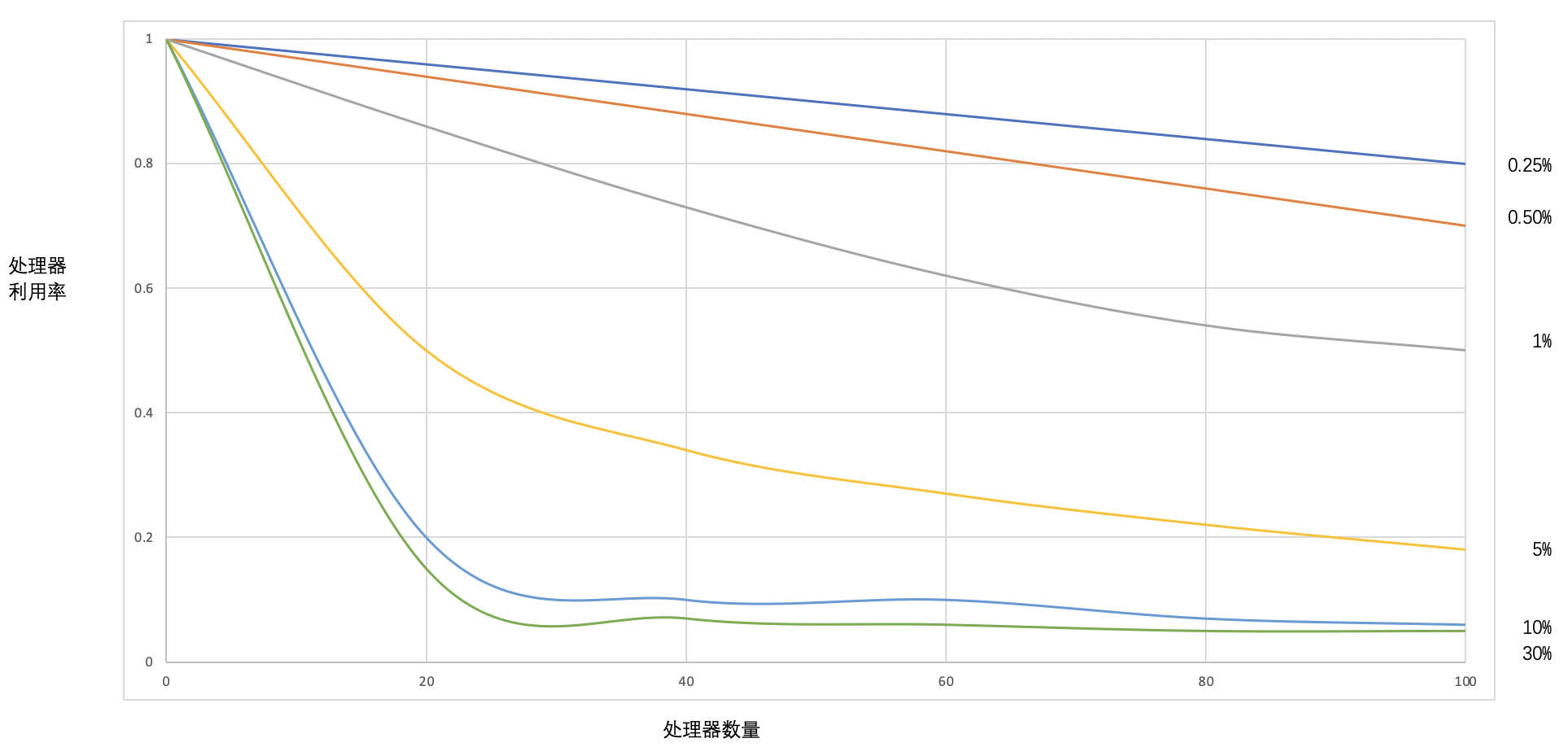
- 當計算資源(處理器數量)增加時,在串行部分比例不變的情況下,CPU利用率下降,
- 當計算資源(處理器數量)增加時,串行占的比例越大,CPU利用率下降得越多,
實驗資料驗證公式
所以其實到現在我們一直在說理論,帶了一點點的公式,聽起來好像是那么回事,但是公式到底怎么用?準不準確?可以精準測驗還是概要測驗即可?
我們接下來實驗一下吧,
!!! 接下來會涉及到CPU Time 包含了作業系統對CPU的消耗,比如行程,執行緒調度等,
1.資料準備
這里就用之前的一個電商活動頁面的優化來說吧,在這個程序中,我們做了大量測驗,由于測驗中使用了localhost方式,所以Java行程在IO上的Wait Time是非常小的,接下來,由于最佳執行緒數接近CPU核數,
所以在兩核的機器上使用了10個Java行程,客戶端發起了10個并發請求,這是在最佳執行緒數下(最佳執行緒數在一個區間里,在這個區間里QPS總體變化不大,并且也用了5、15個并發測驗效果,發現QPS值基本相同)得出的大量結果,接下來就分析一下這些測驗結果,見下表,
1)測驗QPS結果
| 原始頁面大小 | 壓縮后的大小 | 優化前QPS | 優化后QPS | 優化前RT | 優化后RT |
|---|---|---|---|---|---|
| 92kb | 17kb | 164 | 2024 | 60.7ms | 4.9ms |
| 138kb | 8.7kb | 143 | 1859 | 69.8ms | 3.3ms |
| 182kb | 11.4kb | 121 | 2083 | 82.3ms | 4.8ms |
| 248kb | 32kb | 77 | 1977 | 129.6ms | 5.0ms |
| 295kb | 34.4kb | 70 | 1722 | 141.1ms | 5.8ms |
我們其實只要關注各項優化前后的QPS變化即可,
2) CPU利用率
由于Apache Bench和Java部署在同一臺機器.上,所以CPU利用率應該減去Apache Bench
的CPU資源消耗,根據觀察,優化前Apache Bench 的CPU消耗在1.7%到2%之間,優化后
Apache Bench 的CPU資源消耗在20%左右,為什么優化前后有這么大的差距呢?因為優化后
回應能夠及時回傳,所以導致Apache Bench使用的CPU資源多了,
在接下來的計算中,我們將優化前的CPU利用率設定為98%,優化后的CPU利用率設定為80%,
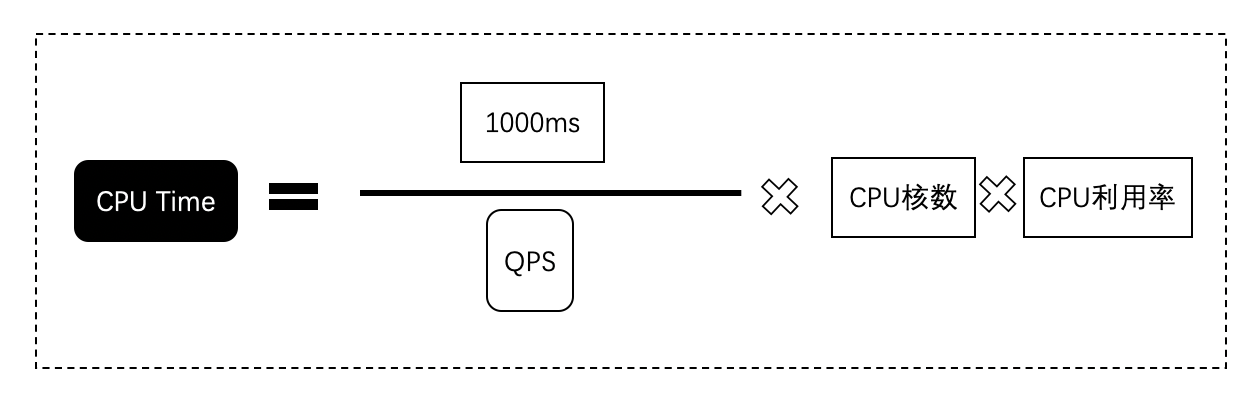
3)CPU Time 計算公式
根據QPS的計算方法,把QPS挪到右邊的分母中,CPU Time移到等號左邊,就會得到下圖的公式,
4) CPU Time計算示例
根據上方列出的三點(CPU利用率、QPS和CPU核數),接下里我們就詳細的描述一下推算方法了,
計算得到的CPU Time
根據上方的表格計算方法,利用QPS計算出各頁面理論上的CPU Time,計算后的結果如下表:
| 原始頁面92kb | 計算公式 |
|---|---|
| 優化前CPU Time計算 | 1000 / 164 x 2 x 0.98 = 12ms |
| 優化后CPU Time計算 | 1000 / 2024 x 2 x 0.8 = 0.8ms |
| 原始頁面大小 | 壓縮后的大小 | 優化前QPS | 優化后QPS | 優化前CPU Time | 優化后CPU Time |
|---|---|---|---|---|---|
| 92kb | 17kb | 164 | 2024 | 12ms | 0.8ms |
| 138kb | 8.7kb | 143 | 1859 | 13.7ms | 0.86ms |
| 182kb | 11.4kb | 121 | 2083 | 16.2ms | 0.77ms |
| 248kb | 32kb | 77 | 1977 | 25.5ms | 0.81ms |
| 295kb | 34.4kb | 70 | 1722 | 28ms | 0.93ms |
這里主要看一下各項的CPU Time優化前后的變化,接下來,我們把兩個值做減法,然后和開篇中提到過的實測程式中Gzip的CPU Time進行對比,
實測CPU Time
1) 5個頁面的Gzip所消耗的CPU Time
實測5個頁面做Gzip所消耗的時間,然后跟公式計算出來的CPU Time做一個對比,如下表:
| 原始頁面大小 | CPU Time公式差值(上表的CPU Time差值) | Gzip CPU Time測量值(10次平均值) | 差值 |
|---|---|---|---|
| 92kb | 11.2ms | 8ms | 3.2ms |
| 138kb | 12.8ms | 7ms | 5.8ms |
| 182kb | 15.4ms | 9ms | 6.4ms |
| 248kb | 24.7ms | 21ms | 3.0ms |
| 295kb | 27.1ms | 23ms | 4.1ms |
可以看到,計算出來的CPU Time值要比測出來的要多一點,多了幾毫秒,這是為什么呢?
其實是因為在優化前,有兩個消耗CPU Time的階段,一個是執行Java代碼時,另一個是執行Gzip時,而優化后,整個邏輯變成了從快取獲取資料后直接回傳,只有非常少的Java代碼在消耗CPU Time(10行以內),
2) Java頁面執行消耗的CPU Time
大體上可以認為:
優化前的CPU Time - 優化后的CPU Time = Gzip CPU Time + 全頁面Java代碼的CPU Time
在實驗中,一開始只統計了 Gzip 本身的消耗,而在 Java 檔案中 Java代碼執行的時間并沒有包含在內,所以兩者差距比較大,于是,我們單獨統計了5個頁面的Java代碼的執行時間,發現檔案中Java碼執行的時間為3~6ms,實際測量的Gzip CPU Time 加上3~6ms的Java代碼執行時間,和使用公式計算出來的CPUTime基本吻合,
根據上面的計算和測量結果,我們發現 Gzip 的 CPU Time消耗加上Java代碼的CPU Time消耗,與公式測量出來的總的CPU Time消耗非常接近,誤差為1~2ms,考慮到CPU Time測量是單執行緒測量,而壓力測驗QPS是并發情況下(會多出行程切換的開銷和GC等的開銷),我們認為這點誤差是合理的,測驗結果說明公式在宏觀上是正確的,
壓力測驗最佳執行緒數和QPS臨界點
前面講到了公式的推導,并在一個固定的條件下驗證了公式在該場景下的正確性,
假設在一個thread-per-client的場景,有一一個Ajax請求,這個請求回傳一個Json字串,每個請求的CPU Time為1ms,WaitTime為300ms(比如讀寫Socket和執行緒調度的等待開銷),那么最佳執行緒數是
\[(300+1/1 )x4x 100%=1204 \]尤其在廣域網上,Wait Time=300ms是正常的數值,在國際環境下,300ms就更加常見了,這意味著如果是4核的機器,需要1204個執行緒,如果是8核的機器則需要2408個執行緒,實際上,有些HTTP服務的CPU Time是遠小于1ms的,比如上面的場景中將頁面壓縮并快取起來之后,CPU Time基本為0.8ms,如果WaitTime還是300ms,那么需要數以千計的執行緒啊!當執行緒數不斷增加的時候,到達某個臨界點之后對系統就開始產生負面影響了,
(1) 大量執行緒背景關系切換的開銷,引起CPU Time的增加及QPS的減少,所以,有時候還沒有達到最佳執行緒數,而QPS已經開始略微下降了,因為CPU Time發生變化、執行緒多了之后,調度引起的CPU Time提升的百分比和QPS下降的百分比成正比(上方的QPS公式),背景關系切換帶來的開銷如下,
- 背景關系切換(微妙級別)
- JVM本身的開銷
- CPU Cache加載
(2)執行緒的堆疊空間會占用大量的記憶體,假設每個執行緒的堆疊空間是1MB,這么多的執行緒就要占用數GB的記憶體,
(3)在CPU Time不變的情況下,因為執行緒背景關系切換和作業系統想盡力為執行緒在宏觀上平均分配時間片的行為,導致每個執行緒的Wait Time都增加了,于是每個請求的RT也增加了,最終就會產生用戶體驗下降的情況,
可以 用一張圖來表示一下臨界點的概念,
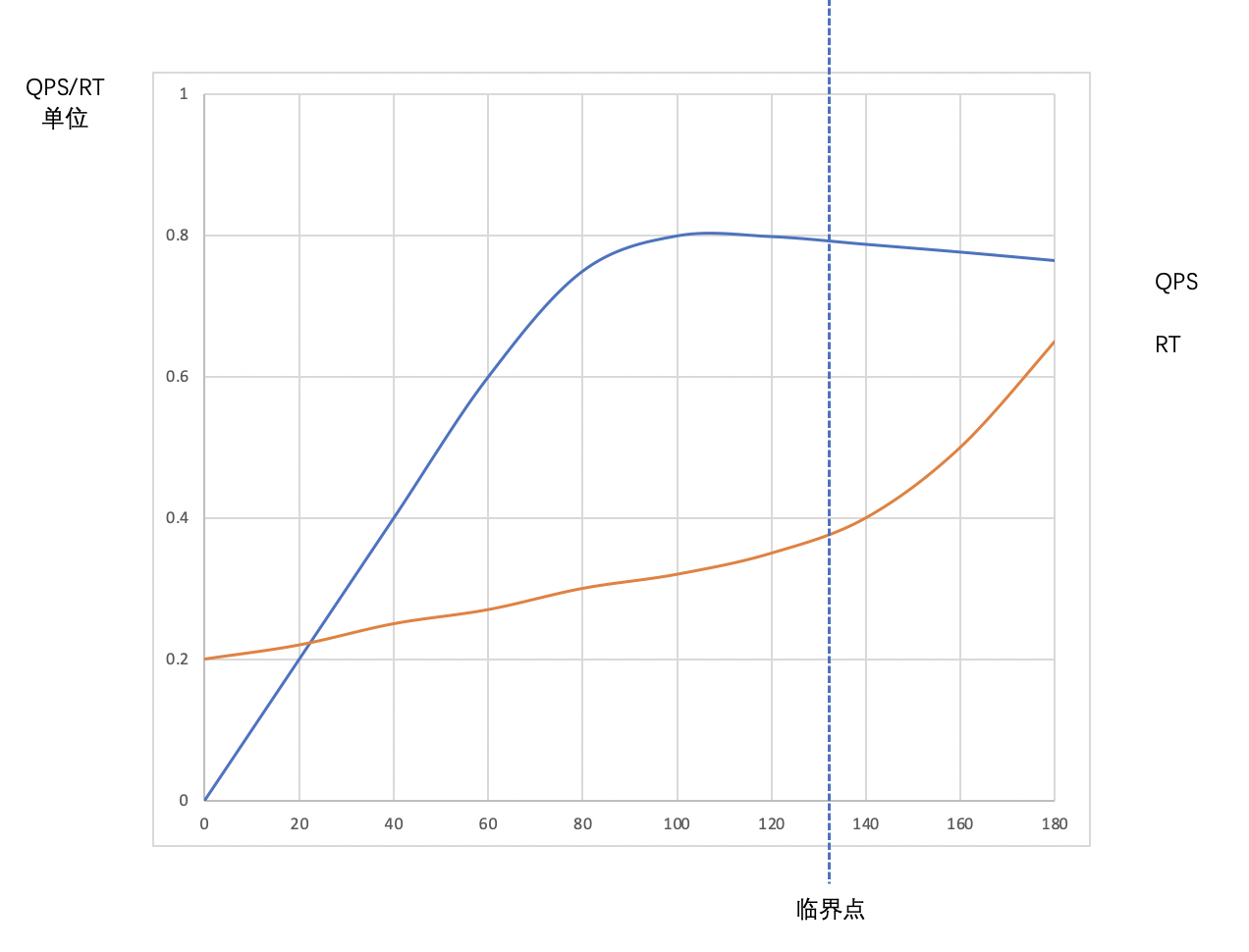
由于執行緒數增加超過某個臨界點會影響CPU Time、QPS和RT,所以很難精確測量高并發下的CPU Time,它隨著機器硬體、作業系統、執行緒數等因素不斷變化,我們能做的就是壓力測驗QPS,并在壓力測驗的程序中調整執行緒數,使QPS達到臨界點,這個臨界點是QPS的一個峰值點,這個峰值點的執行緒數即當前系統的最佳執行緒數,當然如果這個時候CPU利用率沒有達到100%,那么證明系統中可能存在瓶頸,應該在找到并處理瓶頸之后繼續壓力測驗,并且重新找到這個臨界點,
當資料結構發生改變、演算法改進或者業務邏輯發生改變時,最佳執行緒數有可能會跟著變化,
總結:
這篇 blog的例子中,在CPU Time下降到lms左右而Wait Time需要數百毫秒的場景下,我們需要很多執行緒,但是當達到這個執行緒數的時候,有可能早就達到了臨界點,所以系統整體已經不是最健康的狀態了,但是現有的編程模型已經阻礙了我們前進,那么應該怎么辦呢?為使某個系統達到最優狀態?
所以下一篇blog我們來說一下編程中的同步模型和異步模型問題,以及為什么異步模型只需要這么少的執行緒,是不是公式在異步模型下失效了,
我的個人站點
SUMMER https://www.huangyingsheng.com/about
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/134884.html
標籤:其他