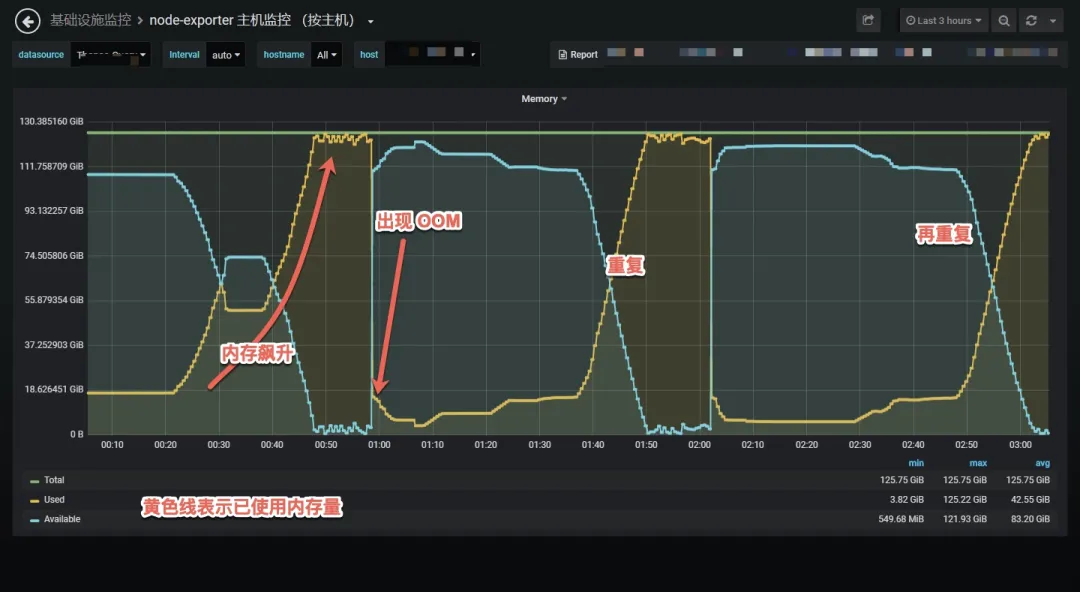
在最近的一次百萬長連接壓測中,32C 128G 的四臺 Nginx 頻繁出現 OOM,出現問題時的記憶體監控如下所示,
排查的程序記錄如下,
現象描述
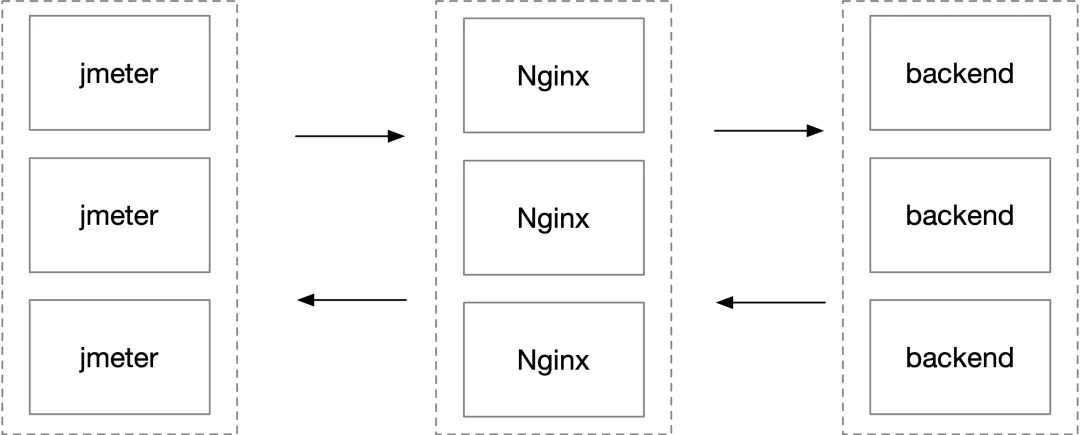
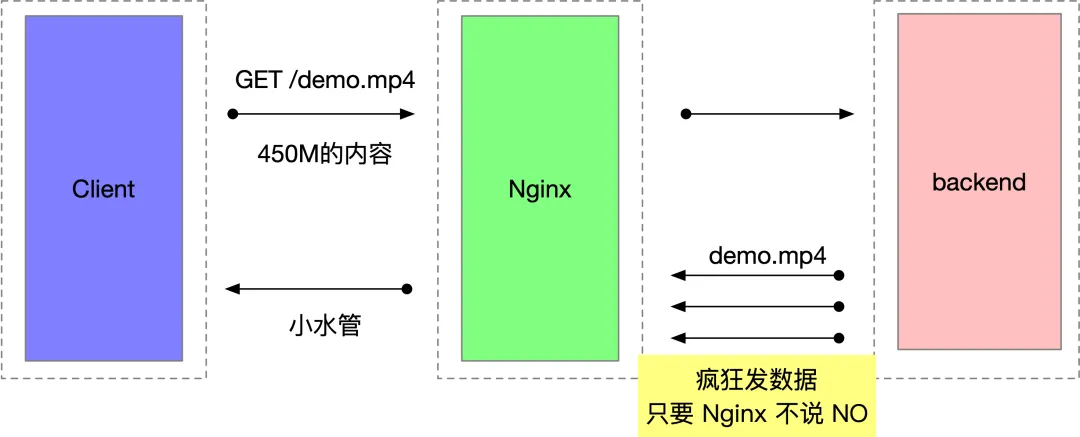
這是一個 websocket 百萬長連接收發訊息的壓測環境,客戶端 jmeter 用了上百臺機器,經過四臺 Nginx 到后端服務,簡化后的部署結構如下圖所示,
在維持百萬連接不發資料時,一切正常,Nginx 記憶體穩定,在開始大量收發資料時,Nginx 記憶體開始以每秒上百 M 的記憶體增長,直到占用記憶體接近 128G,woker 行程開始頻繁 OOM 被系統殺掉,32 個 worker 行程每個都占用接近 4G 的記憶體,dmesg -T 的輸出如下所示,
[Fri Mar 13 18:46:44 2020] Out of memory: Kill process 28258 (nginx) score 30 or sacrifice child [Fri Mar 13 18:46:44 2020] Killed process 28258 (nginx) total-vm:1092198764kB, anon-rss:3943668kB, file-rss:736kB, shmem-rss:4kB
work 行程重啟后,大量長連接斷連,壓測就沒法繼續增加資料量,
排查程序分析
拿到這個問題,首先查看了 Nginx 和客戶端兩端的網路連接狀態,使用 ss -nt 命令可以在 Nginx 看到大量 ESTABLISH 狀態連接的 Send-Q 堆積很大,客戶端的 Recv-Q 堆積很大,Nginx 端的 ss 部分輸出如下所示,
State Recv-Q Send-Q Local Address:Port Peer Address:Port ESTAB 0 792024 1.1.1.1:80 2.2.2.2:50664 ...
在 jmeter 客戶端抓包偶爾可以看到較多零視窗,如下所示,
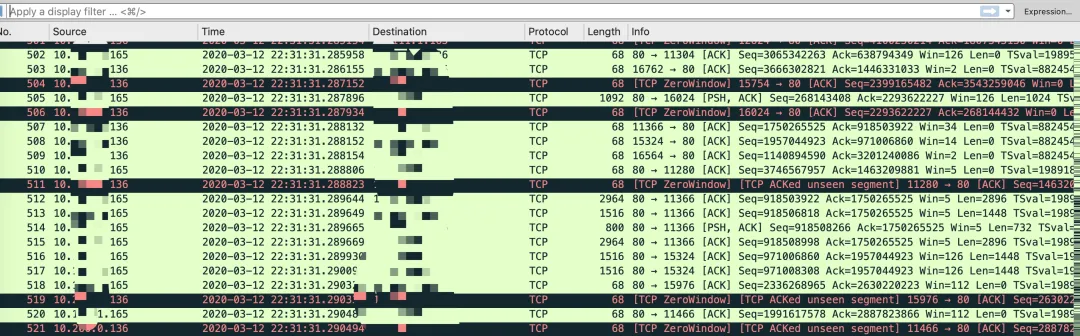
到了這里有了一些基本的方向,首先懷疑的就是 jmeter 客戶端處理能力有限,有較多訊息堆積在中轉的 Nginx 這里,
為了驗證想法,想辦法 dump 一下 nginx 的記憶體看看,因為在后期記憶體占用較高的狀況下,dump 記憶體很容易失敗,這里在記憶體剛開始上漲沒多久的時候開始 dump,
首先使用 pmap 查看其中任意一個 worker 行程的記憶體分布,這里是 4199,使用 pmap 命令的輸出如下所示,
pmap -x 4199 | sort -k 3 -n -r 00007f2340539000 475240 461696 461696 rw--- [ anon ] ...
隨后使用 cat /proc/4199/smaps | grep 7f2340539000 查找某一段記憶體的起始和結束地址,如下所示,
cat /proc/3492/smaps | grep 7f2340539000 7f2340539000-7f235d553000 rw-p 00000000 00:00 0
隨后使用 gdb 連上這個行程,dump 出這一段記憶體,
gdb -pid 4199 dump memory memory.dump 0x7f2340539000 0x7f235d553000
隨后使用 strings 命令查看這個 dump 檔案的可讀字串內容,可以看到是大量的請求和回應內容,
這樣堅定了是因為快取了大量的訊息導致的記憶體上漲,隨后看了一下 Nginx 的引數配置,
location / { proxy_pass http://xxx; proxy_set_header X-Forwarded-Url "$scheme://$host$request_uri"; proxy_redirect off; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_set_header Cookie $http_cookie; proxy_set_header Host $host; proxy_set_header X-Forwarded-Proto $scheme; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; client_max_body_size 512M; client_body_buffer_size 64M; proxy_connect_timeout 900; proxy_send_timeout 900; proxy_read_timeout 900; proxy_buffer_size 64M; proxy_buffers 64 16M; proxy_busy_buffers_size 256M; proxy_temp_file_write_size 512M; }
可以看到 proxy_buffers 這個值設定的特別大,接下來我們來模擬一下,upstream 上下游收發速度不一致對 Nginx 記憶體占用的影響,
模擬 Nginx 記憶體上漲
我這里模擬的是緩慢收包的客戶端,另外一邊是一個資源充沛的后端服務端,然后觀察 Nginx 的記憶體會不會有什么變化,
緩慢收包客戶端是用 golang 寫的,用 TCP 模擬 HTTP 請求發送,代碼如下所示,
package main import ( "bufio" "fmt" "net" "time" ) func main() { conn, _ := net.Dial("tcp", "10.211.55.10:80") text := "GET /demo.mp4 HTTP/1.1\r\nHost: ya.test.me\r\n\r\n" fmt.Fprintf(conn, text) for ; ; { _, _ = bufio.NewReader(conn).ReadByte() time.Sleep(time.Second * 3) println("read one byte") } }
在測驗 Nginx 上開啟 pidstat 監控記憶體變化
pidstat -p pid -r 1 1000
運行上面的 golang 代碼,Nginx worker 行程的記憶體變化如下所示,
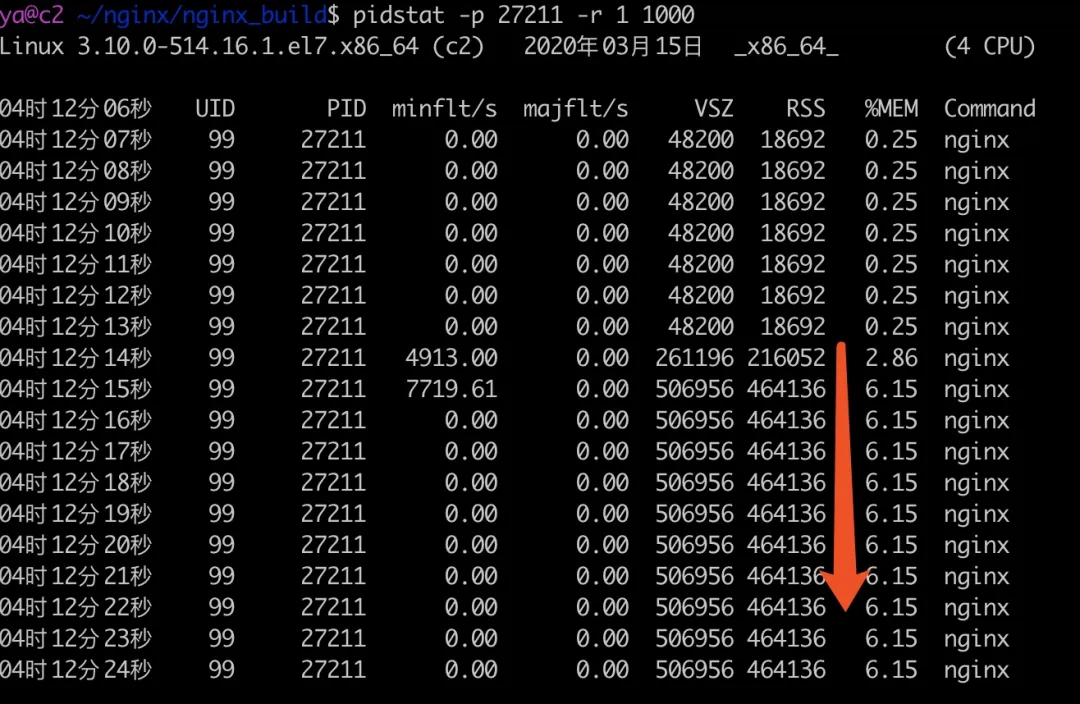
04:12:13 是 golang 程式啟動的時間,可以看到在很短的時間內,Nginx 的記憶體占用就漲到了 464136 kB(接近 450M),且會維持很長一段時間,
同時值得注意的是,proxy_buffers 的設定大小是針對單個連接而言的,如果有多個連接發過來,記憶體占用會繼續增長,下面是同時運行兩個 golang 行程對 Nginx 記憶體影響的結果,
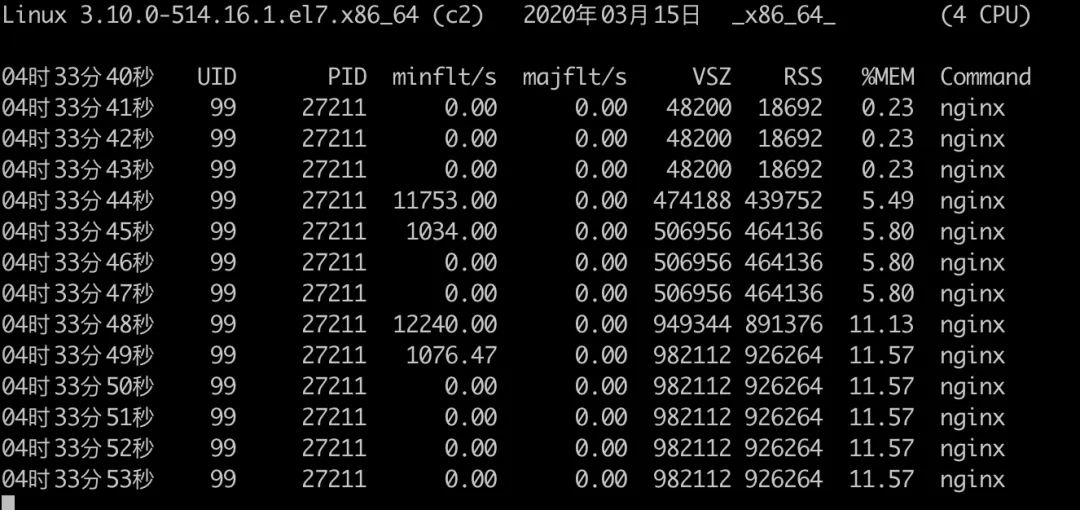
可以看到兩個慢速客戶端連接上來的時候,記憶體已經漲到了 900 多 M,
解決方案
因為要支持上百萬的連接,針對單個連接的資源配額要小心又小心,一個最快改動方式是把 proxy_buffering 設定為 off,如下所示,
proxy_buffering off;
經過實測,在壓測環境修改了這個值以后,以及調小了 proxy_buffer_size 的值以后,記憶體穩定在了 20G 左右,沒有再飆升過,后面可以開啟 proxy_buffering,調整 proxy_buffers 的大小可以在記憶體消耗和性能方面取得更好的平衡,重復剛才的測驗,結果如下所示,
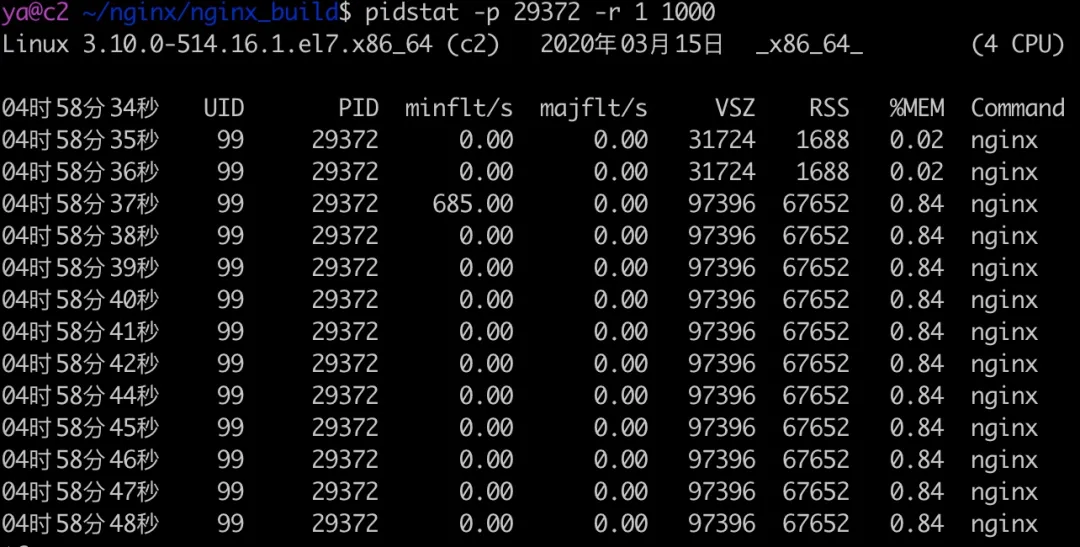
可以看到這次記憶體值增長了 64M 左右,為什么是增長 64M 呢?來看看 proxy_buffering 的 Nginx 檔案(nginx.org/en/docs/htt…
When buffering is enabled, nginx receives a response from the proxied server as soon as possible, saving it into the buffers set by the proxy_buffer_size and proxy_buffers directives. If the whole response does not fit into memory, a part of it can be saved to a temporary file on the disk. Writing to temporary files is controlled by the proxy_max_temp_file_size and proxy_temp_file_write_size directives.
When buffering is disabled, the response is passed to a client synchronously, immediately as it is received. nginx will not try to read the whole response from the proxied server. The maximum size of the data that nginx can receive from the server at a time is set by the proxy_buffer_size directive.
可以看到,當 proxy_buffering 處于 on 狀態時,Nginx 會盡可能多的將后端服務器回傳的內容接收并存盤到自己的緩沖區中,這個緩沖區的最大大小是 proxy_buffer_size * proxy_buffers 的記憶體,
如果后端回傳的訊息很大,這些記憶體都放不下,會被放入到磁盤檔案中,臨時檔案由 proxy_max_temp_file_size 和 proxy_temp_file_write_size 這兩個指令決定的,這里不展開,
當 proxy_buffering 處于 off 狀態時,Nginx 不會盡可能的多的從代理 server 中讀資料,而是一次最多讀 proxy_buffer_size 大小的資料發送給客戶端,
Nginx 的 buffering 機制設計的初衷確實是為了解決收發兩端速度不一致問題的,沒有 buffering 的情況下,資料會直接從后端服務轉發到客戶端,如果客戶端的接收速度足夠快,buffering 完全可以關掉,但是這個初衷在海量連接的情況下,資源的消耗需要同時考慮進來,如果有人故意偽造比較慢的客戶端,可以使用很小的代價消耗服務器上很大的資源,
其實這是一個非阻塞編程中的典型問題,接收資料不會阻塞發送資料,發送資料不會阻塞接收資料,如果 Nginx 的兩端收發資料速度不對等,緩沖區設定得又過大,就會出問題了,
Nginx 原始碼分析
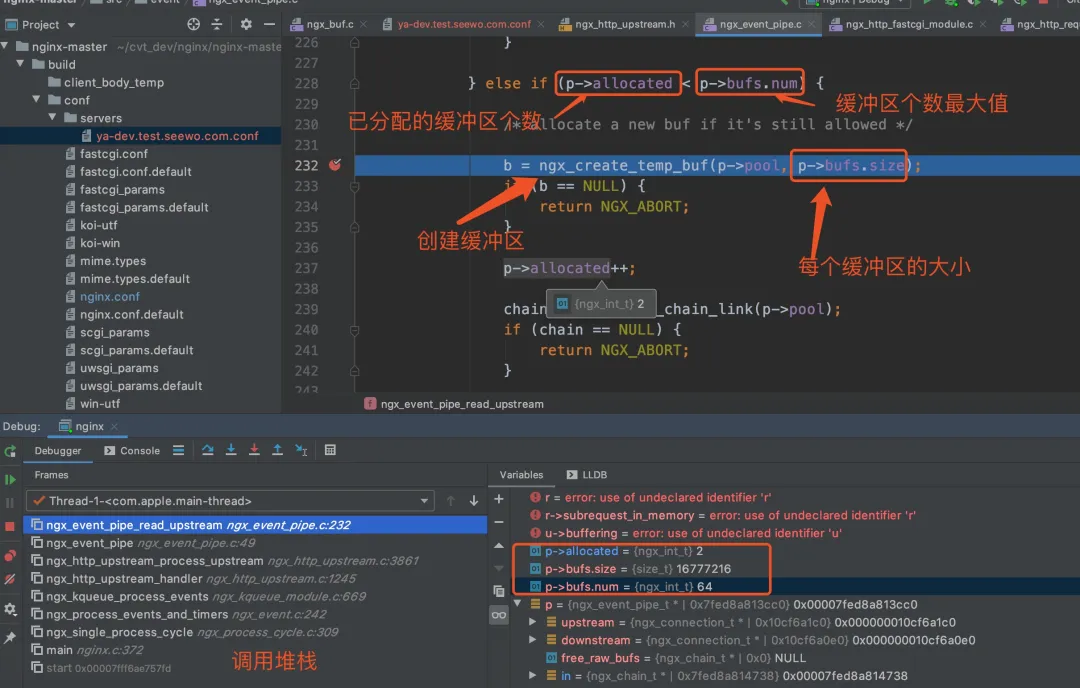
讀取后端的回應寫入本地緩沖區的原始碼在 src/event/ngx_event_pipe.c 中的 ngx_event_pipe_read_upstream 方法中,這個方法最侄訓呼叫 ngx_create_temp_buf 創建記憶體緩沖區,創建的次數和每次緩沖區的大小由 p->bufs.num(緩沖區個數) 和 p->bufs.size(每個緩沖區的大小)決定,這兩個值就是我們在組態檔中指定的 proxy_buffers 的引數值,這部分原始碼如下所示,
static ngx_int_t ngx_event_pipe_read_upstream(ngx_event_pipe_t *p) { for ( ;; ) { if (p->free_raw_bufs) { // ... } else if (p->allocated < p->bufs.num) { // p->allocated 目前已分配的緩沖區個數,p->bufs.num 緩沖區個數最大大小 /* allocate a new buf if it's still allowed */ b = ngx_create_temp_buf(p->pool, p->bufs.size); // 創建大小為 p->bufs.size 的緩沖區 if (b == NULL) { return NGX_ABORT; } p->allocated++; } } }
Nginx 原始碼除錯的界面如下所示,
后記
還有程序中一些輔助的判斷方法,比如通過 strace、systemtap 工具跟蹤記憶體的分配、釋放程序,這里沒有展開,這些工具是分析黑盒程式的神器,
除此之外,在這次壓測程序中還發現了 worker_connections 引數設定不合理導致 Nginx 啟動完就占了 14G 記憶體等問題,這些問題在沒有海量連接的情況下是比較難發現的,
最后,底層原理是必備技能,調參是門藝術,上面說的內容可能都是錯的,看看排查思路就好,
看完三件事??
如果你覺得這篇內容對你還蠻有幫助,我想邀請你幫我三個小忙:
-
點贊,轉發,有你們的 『點贊和評論』,才是我創造的動力,
-
關注公眾號 『 java爛豬皮 』,不定期分享原創知識,
-
同時可以期待后續文章ing??
作者:挖坑的張師傅
出處:club.perfma.com/article/433…
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/136234.html
標籤:Java