sparkAPI @zhouhonglin
1.RDD
彈性分布式資料集:
RDD是由多個partition組成
最小單位是partition:與讀取的block是一一對應的. 有多少個block就有多少個partion.
算子就是函式:作用再rdd的partition上的.
對彈性的理解:某個RDD損壞了,可以進行恢復.他們直接有依賴關系
磁區器是作用在kv格式RDD上很難理解
partition提供資料計算的最佳位置,利用資料處理的本地化
計算移動,資料不移動
2.相關問題:
1. 什么是KV格式的RDD,
RDD中的資料是一個個tuple2資料,那么就是kv格式的資料
2.Spark讀取hdfs資料的方法:textFile.底層是呼叫MR讀取HDFS的方法,首先會split,每個split對應一個一個block,每個split對應生產RDD的每個parttition.
3.哪里體現了RDD的彈性:容錯
RDD之間有依賴關系,
RDD的磁區,parttiton可多可少
4,哪里體現了分布式:
RDD的partition分布在多個節點上
3.spark的執行原理
Driver: 負責發送任務和回收任務,
Worker:負責進行資料操作
4.算子
多個RDD組成一個有向無環圖
1. 懶執行算子:
只有在遇到行動算子的時候,才會觸發懶執行算子
sparkapplication是由多個jab組成的
每個行動算子,觸發一個job
算子:
map
filter
flatMap
sample
reduceByKey
groupByKey
union
join
規律總結:懶執行算子,都是由RDD轉換為RDD
2.行動算子
算子:
count
collect
reduce
5.持久化算子
--cache:默認將資料存盤在記憶體中,懶執行
--persist:可以手動指定持久化級別
-- cache和persist都是懶執行,最小的持久化單位是partition.
---cache和persist之后就可以直接賦值給一個值,后面不可以緊跟行動算子
6.寬窄依賴
Application:基于Spark的用戶程式,包含了driver程式和運行在集群上的excutor程式,依據寬窄依賴進行劃分,
窄依賴:一對一的依賴,稱為窄依賴 ,多對一
寬依賴:一對多:存在與多個節點的資料傳輸
spark用在迭代的場景,會很快,沒有用在迭代的場景,和,mapreduce沒什么區別
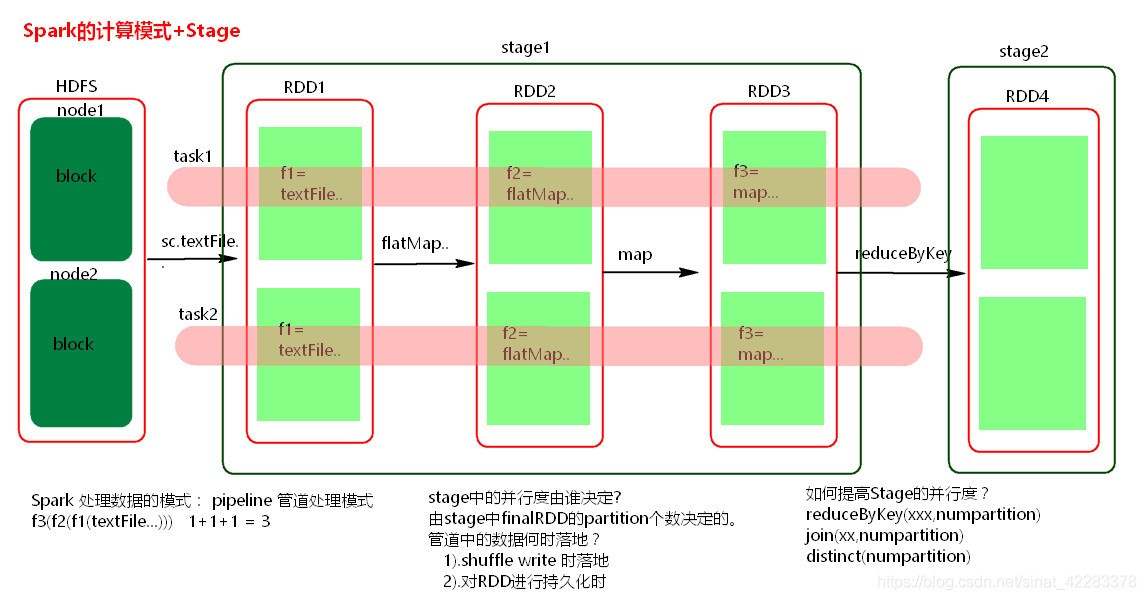
spark處理資料的模式,pipiline管道處理模式,
一個stage由多個并行的task
stage的并行度是誰決定的?
由stage中的finalpartition的個數決定的
管道中的資料何時可以落地?
shuffle write的時候落地,
對RDD進行持久化的時候,落地
如何提高Stage的并行度
reduceByKey
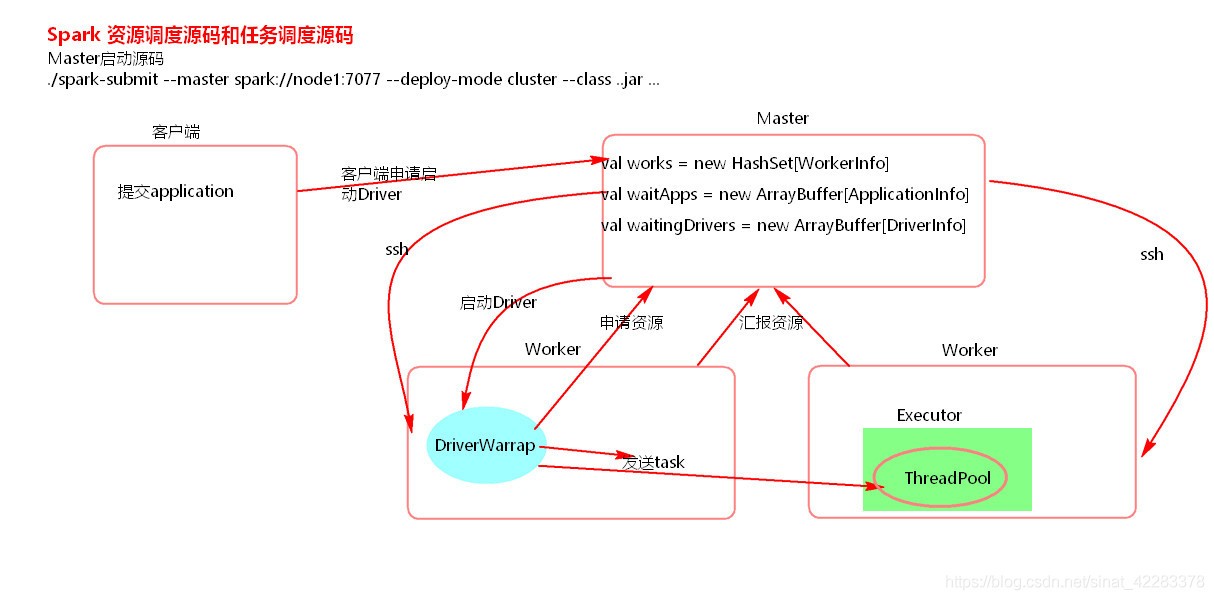
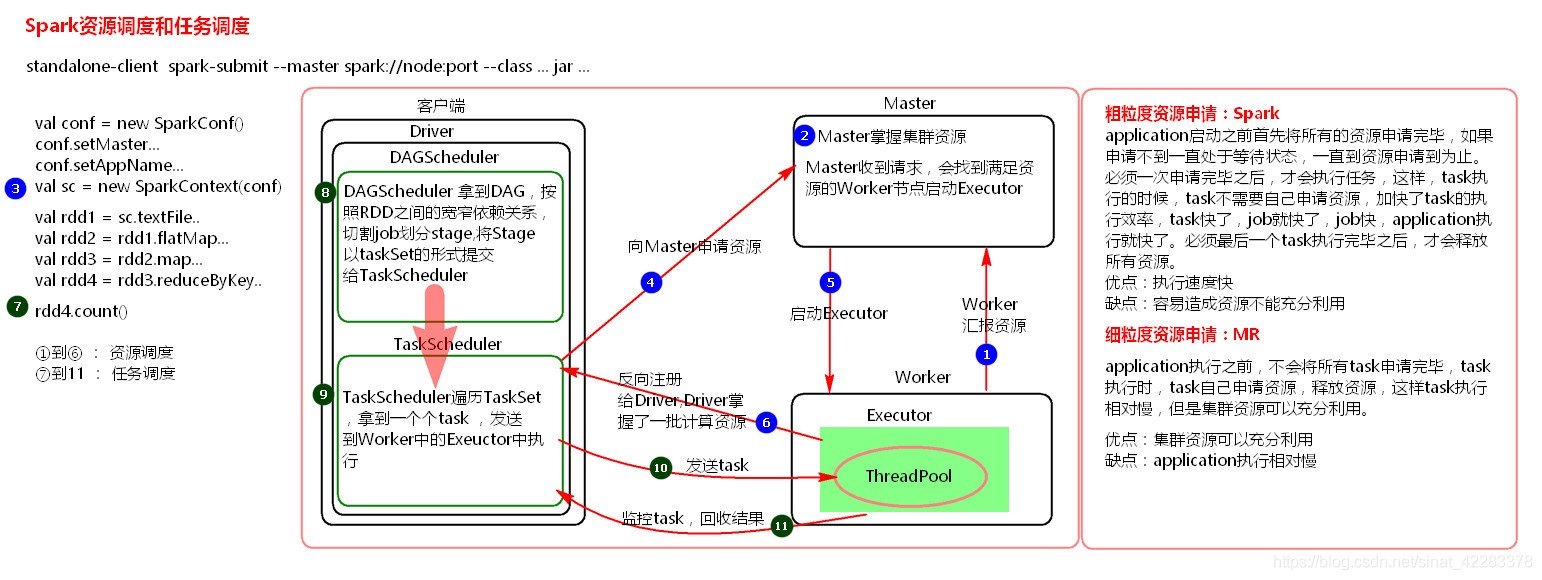
7. 資源調度和任務調度
原始碼:
計算模式圖
資源調度圖和任務調度
資源調度是粗粒度的呼叫:spark:application啟動之前首先將所有的資源都申請完畢,如果申請不到,則一直處于等待狀態,一直到申請到資源為止,必須一次申請完畢后,才會執行任務,這樣,task的我執行效率,task快了,job快了,job快了,application就快了,必須最后一個task執行完畢后,才會釋放所有資源,
優點:執行速度快
缺點:容易造成資源的浪費
細粒度資源shenq:MR
與粗粒度相反
算子
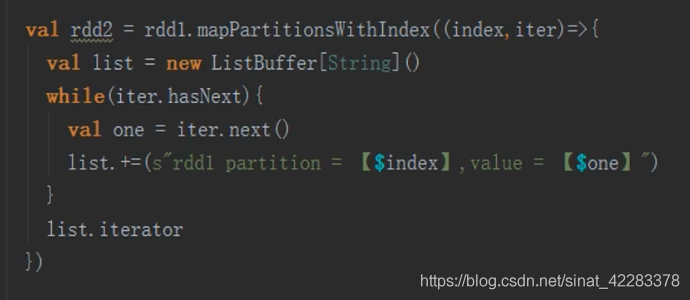
1.maPartitionWithIndex算子
輸入一個索引和迭代器,輸入一個迭代器
2. repartiton:可以增多磁區,也可以減少磁區
是一個寬依賴的算子,會產生shuffer
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/137350.html
標籤:python