上帝之火
本系列講述的是開源實時監控告警解決方案Prometheus,這個單詞很牛逼,每次我都能聯想到帶來上帝之火的希臘之神,普羅米修斯,而這個開源的logo也是火,個人挺喜歡這個logo的設計,
本系列著重介紹Prometheus以及如何用它和其周邊的生態來搭建一套屬于自己的實時監控告警平臺,
本系列受眾物件為初次接觸Prometheus的用戶,大神勿噴,偏重于操作和實戰,但是重要的概念也會精煉出提及下,系列主要分為以下幾塊
Prometheus各個概念介紹和搭建,如何抓取資料(本次分享內容)- 如何推送資料至
Prometheus,推送和拉取分別用于什么樣的場景 Prometheus資料的結構以及查詢語言PromQL的使用- Java應用如何和
Prometheus集成,如何啟用服務發現,如果自定義業務指標 Prometheus如何和Grafana可視化套件進行集成和設定告警- 教你如何手寫一個集成了監控Dubbo各個指標的java套件
- 實際案例分享,如何做各個業務端和系統端的監控大盤
Prometheus以及時序資料庫的基本概念
Prometheus現在在Github有3w多的star,基本上過萬星的開源工具,可以認為是社區里絕對的主流,社區也相當活躍,可以有大量的經驗可以借鑒,在企業級系統中,可以放心的使用,
Prometheus 是由 SoundCloud 開發的開源監控報警系統和時序列資料庫,從字面上理解,Prometheus 由兩個部分組成,一個是監控報警系統,另一個是自帶的時序資料庫(TSDB),
關于時序資料庫(TSDB)這里要說下,我們可以簡單的理解為一個優化后用來處理時間序列資料的資料庫,并且資料中的陣列是由時間進行索引的,相比于傳統的結構化資料庫主要有幾個好處:
- 時間序列資料專注于海量資料的快速攝取,時序資料庫視資料的每一次變化為一條新的資料,從而可以去衡量變化:分析過去的變化,監測現在的變化,以及預測未來將如何變化,傳統結構化資料在資料量小的時候能做到,在資料量大的時候就需要花費大量的成本,
- 高精度資料保存時間較短,中等或更低精度的摘要資料保留時間較長,對于實時監控來說,不一定需要每一個精準的資料,而是固定時間段時間資料的摘要,這對于結構化資料庫來說就意味著要進行篩選,在保證大量的寫入同時還要進行帥選,這是一個超出結構化資料庫設計來處理的作業量,
- 資料庫本身必須連續計算來自高精度資料的摘要以進行長期存盤,這些計算既包括一些簡單的聚合,同時也有一些復雜計算,傳統資料庫無法承受那么大量的計算,因為必須去實時統計這些聚合和復雜運算,
開始搭建Prometheus
https://prometheus.io/
在Prometheue官網Download標簽頁進行下載,這里以linux版本為例:

下載好之后,解壓,運行
nohup /data/prometheus/prometheus --web.listen-address=0.0.0.0:9090 --config.file=/data/prometheus/prometheus.yml --web.enable-lifecycle --storage.tsdb.path=/data/prometheus/data --storage.tsdb.retention.time=15d &
這樣,就簡單的搭建起來Prometheus服務端了,這時候,我們可以在web上訪問
http://127.0.0.1:9090
就可以訪問到管理頁面
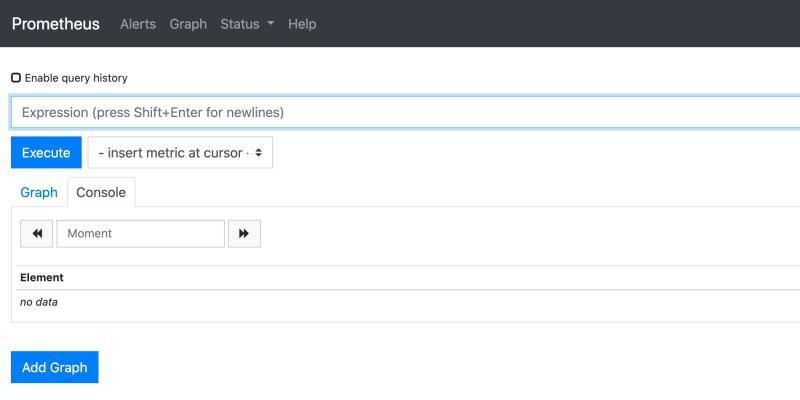
界面上幾個標簽說明下:
Alert:用來配置告警規則,之后我們會用Grafana自身的告警界面配置來代替這個,
Graph:用來運行PromQL陳述句的一個控制臺,并且可以把運行出來的陳述句用用圖形化進行展示,此塊我們后面章節會介紹到,
Status:包含系統資訊,系統狀態,配置資訊,目標節點的狀態,服務發現狀態等元資訊的查看,
Prometheus整體架構以及生態
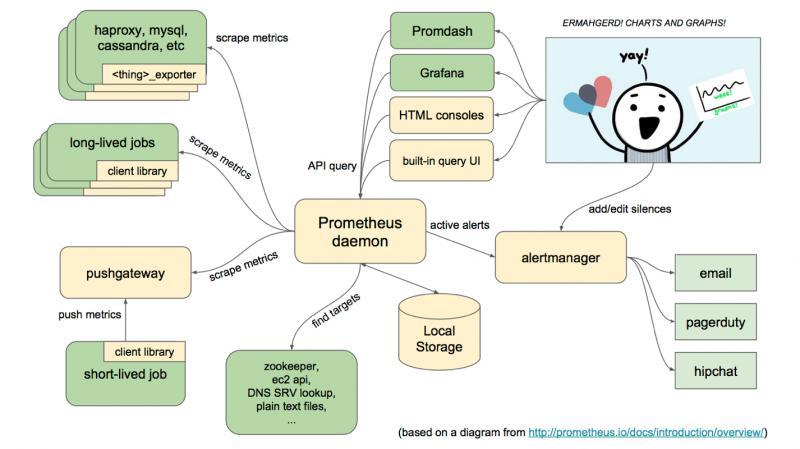
這張圖是官方的整體架構圖,米黃色部分是Prometheus自己的組件,綠色的為第三方的中間件和應用,
簡單介紹下整個Prometheus的生態架構:
Prometheus獲取資料的方式只有一種,就是scrape,也稱作pull,意為拉取,Prometheus每隔一段時間會從目標(target)這里以Http協議拉取指標(metrics),這些目標可以是應用,也可以是代理,快取中間件,資料庫等等一些中間件,- 拉取出來的資料
Prometheus會存到自己的TSDB資料庫,自己的WebUI控制臺以及Grafana可以對其資料進行時間范圍內的不斷查詢,繪制成實時圖表工展現, Prometheus支持例如zookeeper,consul之類的服務發現中間件,用以對目標(target)的自動發現,而不用一個個去配置target了,alertManager組件支持自定義告警規則,告警渠道也支持很多種
拉取資料
Prometheus主要是通過拉取的方式獲取資料,說簡單點,就是每隔固定時間去訪問配置的target,target就是一個獲取資料的url,
現在我們就來模擬一個資料源,并讓prometheus去拉取,
新建一個springboot的web專案,pom依賴加上
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>
application.properties里加上
server.port=8080
anagement.endpoints.web.exposure.include=*
啟動完畢后,我們就可以在頁面上訪問如下地址:
http://127.0.0.1:8080/actuator/prometheus
得到如下資料:
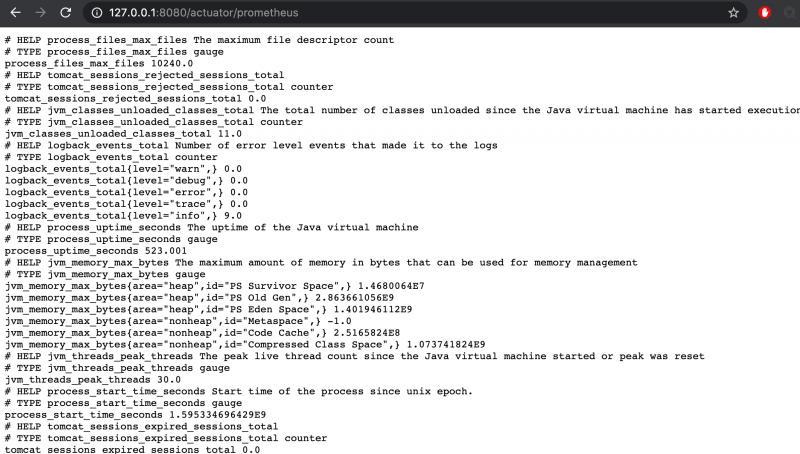
關于actuator如何監控應用指標以及自定義指標我會在之后的系列里單獨分析,這里只要理解成我們啟動了一個服務,提供了一個url能列出一些kv形式的指標就行了,
例如jvm_memory_max_bytes{area="heap",id="PS Old Gen",} 2.863661056E9這個指標,前面是key,后面為value,
其中key上又分key name和key labels,key name就是``jvm_memory_max_bytes,key labels有2個,
這個指標提供了jvm的最大記憶體,其中area為heap,表明這是堆記憶體區域,id為PS Old Gen,表明這是老年代,綜合起來看,這個指標就是jvm中老年代的最大值,數值型別是byte,換算下來大概是286M左右,
我們有指標的資料源后,再在prometheus 的根目錄下編輯prometheus.yml檔案,添加如下配置:
- job_name: 'test'
scrape_interval: 5s
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['localhost:8080']
labels:
instance: demo
這個配置表示:prometheue每隔5秒鐘從http://localhost:8080/actuator/prometheus這個url拉取指標,并且為每個指標添加instance這個標簽,
添加完畢后,重啟prometheus,進入web頁面中的targets頁面,如果前面步驟沒問題的話,會看到:

狀態為UP表明prometheue已經成功獲取到了這個target 的資料,
在查詢頁面上輸入剛才那個指標的key:
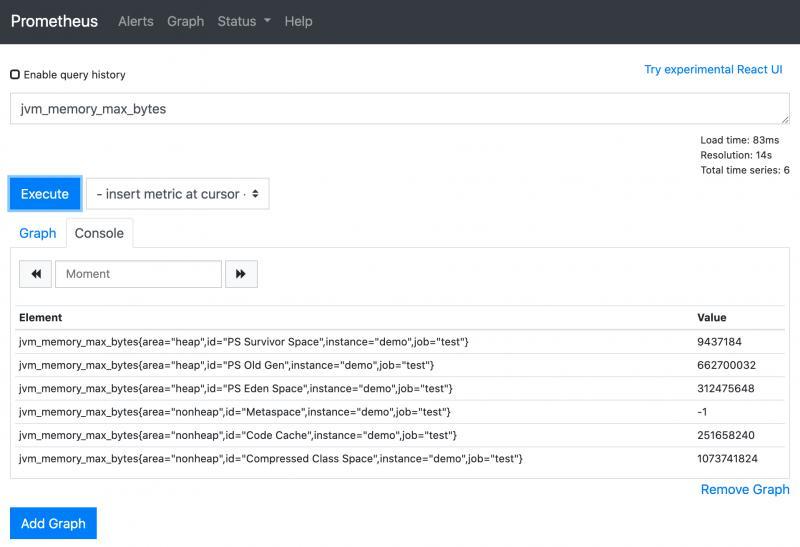
這里每個value都是prometheus最近一次抓取的資料,你每執行一次,資料都會變,
這里為什么會有多條資料呢,是因為每個指標他們的標簽不一樣,完全一樣的標簽會被歸為一種指標,
點Graph這標簽可以看到在時間序列下,某個指標的變化趨勢
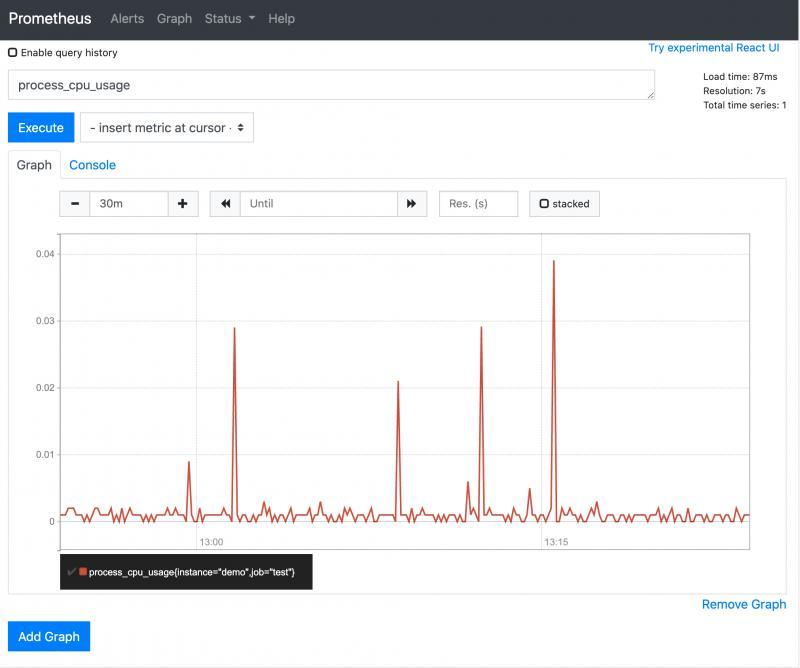
上圖展示了系統cpu指標的變化圖,
最后
如今微服務盛行,小規模的企業的微服務節點也快上百了,Prometheus生態能夠用最小的代價使所有的資料實時可視化,這對于開發和運維來說,意義在于,所有的資料不再是黑盒了,至少我個人覺得所有的資料能夠被觀測和分析,是具有安全感的,
這個系列旨在利用實戰操作教你一步步搭建自己系統和業務監控大盤,后面會繼續更新,下一個章節將分析:搭建pushgateway去push資料到prometheus,以及2種不同的資料獲取方式分別用于什么樣的場景,
聯系作者
歡迎微信公眾號關注 「元人部落」
關注后回復 "資料" 免費獲取50G的技術資料,包含一整套企業級微服務課程以及一套秒殺課程

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/137664.html
標籤:Java
上一篇:c 語言用c++頭檔案
下一篇:深入理解ThreadLocal