《Java面試題系列》:一個長知識又很有意思的專欄,深入挖掘、分析原始碼、匯總原理、圖文結合,打造公眾號系列文章,面試與否均可提升Level,歡迎持續關注【程式新視界】,本篇為第6篇,
關于字串的比較在前面文章中已經詳解過,本篇文章基于字串常量池的存盤及在使用intern方法時所引起的記憶體變化進行一步深層次的講解,
重點內容:當字串呼叫intern方法后,再進行字串的比較,會發生什么變化?
本文內容均以HotSpot虛擬機為基礎講解,
面試題
先通過一個面試題形象的了解一下我們本篇文章要講的內容的呈現形式:
String s1 = new String("he") + new String("llo");
String s2 = new String("h") + new String("ello");
String s3 = s1.intern();
String s4 = s2.intern();
System.out.println(s1 == s3);
System.out.println(s1 == s4);
執行上面的代碼,會發現列印的結果都是true,那么,為什么本來不相等的字串,呼叫了intern方法之后便相等了呢?下面我們就來逐步分析這其中的底層實作,
intern方法的作用
intern()方法的功能定義:
(1)如果當前字串內容存在于字串常量池(即equals()方法為true,也就是內容一樣),那直接回傳此字串在常量池的參考;
(2)如果當前字串不在字串常量池中,那么在常量池創建一個參考并指向堆中已存在的字串,然后回傳常量池中的參考,
簡單說intern方法就是判斷并將字串是否存在于字串常量池,如果不存在則創建,存在則回傳,
字串常量池
在HotSpot中實作字串常量池功能的是一個StringTable類,它是一個Hash表,默認值大小長度是1009,在每個HotSpot虛擬機的實體中只有一份,被所有的類共享,字串常量由一個個字符組成,放在了StringTable上,
在《面試題系列第5篇:JDK的運行時常量池、字串常量池、靜態常量池,還傻傻分不清?》一文中我們已經專門介紹了字串常量池的位置隨著JDK版本的變化而變化,可以參考,
JDK6及之前版本,字串常量池是放在Perm Gen區(方法區)中,StringTable的長度是固定的,長度是1009,當String字串過多時會造成hash沖突,導致鏈表過長,性能大幅度下降,此時字串常量池里面放的全部是字串常量(字面值),
由于永久代的空間有限且固定,JDK6的存盤模式很容易造成OutOfMemoryError,
而JDK7時正在著手去永久代的作業,因此字串常量池被放在了堆中,此時,即使堆的大小也是固定的,但對于應用調優作業,只需要調整堆大小就行了,
在JDK7中字串常量池不僅僅可以存放字串常量,還可以存放字串的參考,也就是說,堆中的字串的參考可以作為常量池的值而存在,
字串池化流程分析
在了解了上面的基礎理論,我們下面以圖文相結合的形式來逐步演示字串池化的流程和分類,以下實體以JDK8版本為基礎來進行分析講解,
當我們通過雙引號宣告一個字串:
String wechat = "程式新視界";
此時,雙引號內的字串會被直接存盤在字串常量池中,
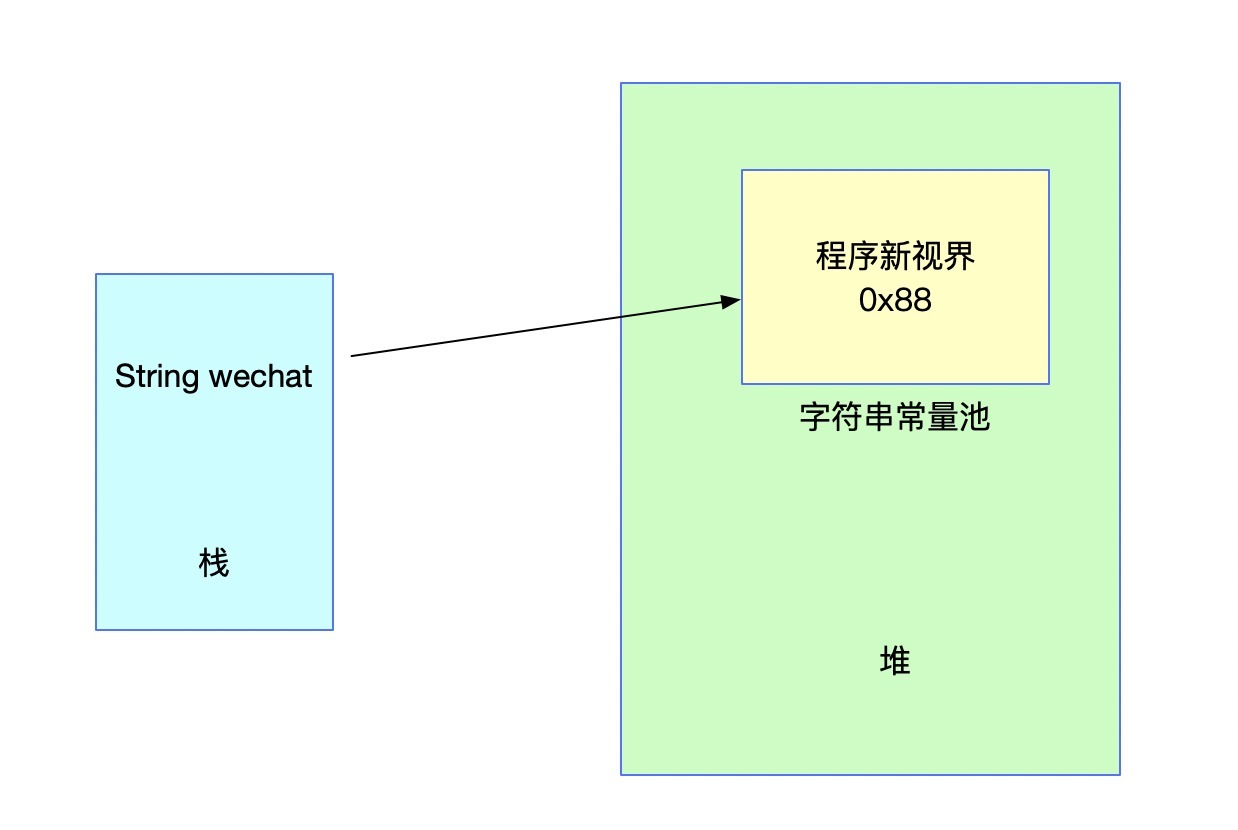
關于上面的存盤結構,我們已經在之前文章中提到,不再過多解釋,下面如果我們再宣告同樣的字串看看會有什么樣的變化,
String wechat = "程式新視界";
String wechat1 = "程式新視界";
上述代碼中宣告wechat1時,會發現常量池中已經存在了對應的字串,則不會再重新創建,只是把對應的參考回傳給wechat1,對應結構圖如下:
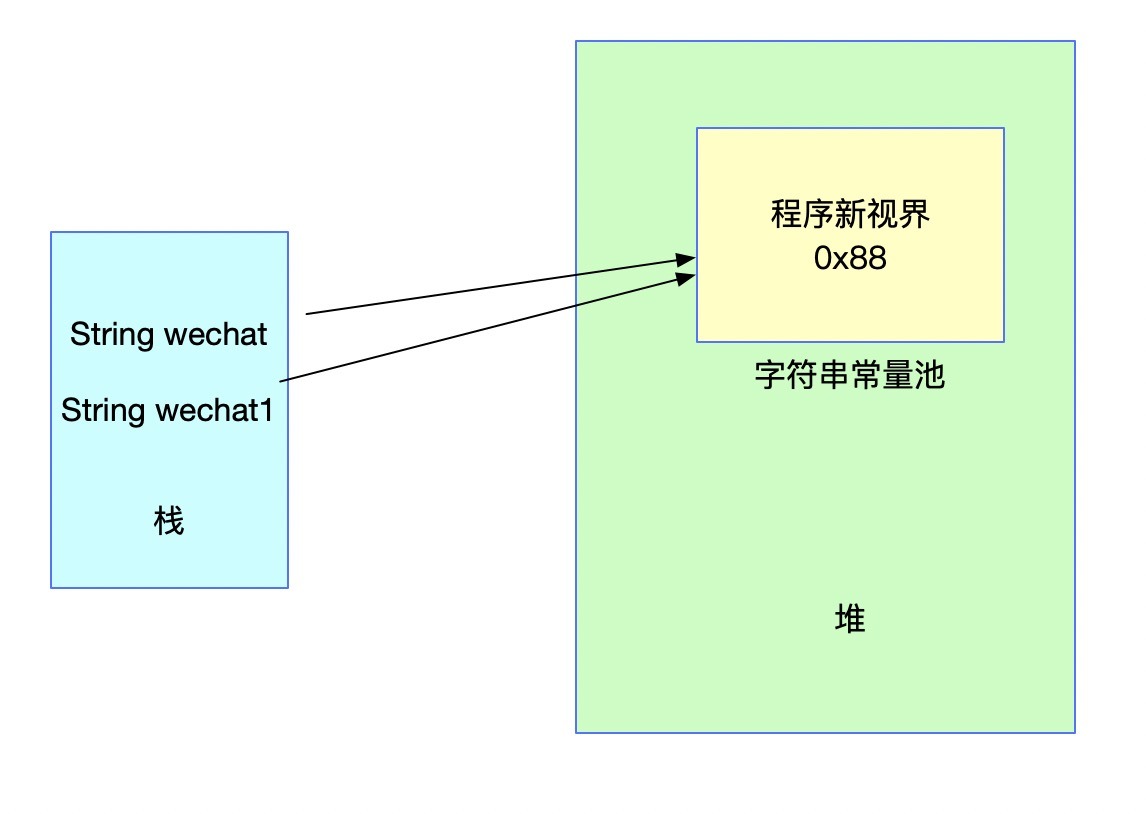
此時,如果直接用雙等號比較wechat和wechat1肯定是相等的,因為它們的參考和字面值都是相同的,
上面是直接雙引號賦值的情況,那么如果通過new的形式創建字串對應的流程又是如何呢?前面文章已經講到這分兩種情況:常量池存在對應的值和不存在對應的值,
String wechat2 = new String("程式新視界");
如果存在對應的值,此時會先在堆中創建一個針對wechat2變數的物件參考,然后將這個物件參考指向字串常量池中已經存在的常量,
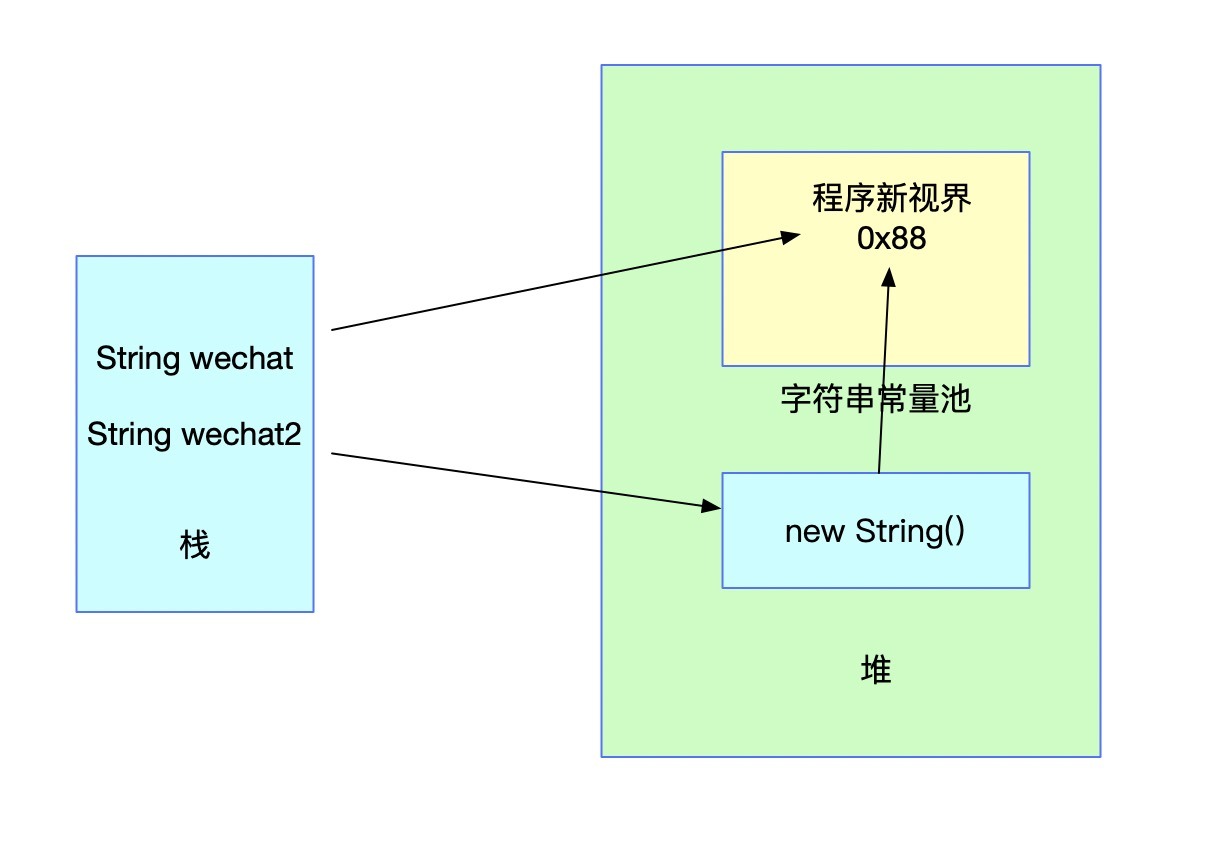
此時直接使用雙等號比較wechat和wechat2變數肯定是不相等的,而通過equals方法進行對比字面值則是相等的,
另外一種情況就是通過new創建時,字串常量池中并不存在對應的常量,這種情況會現在字串常量池中創建一個字串常量,然后再在堆中創建一個字串,持有常量池中對應字串的參考,并把堆中物件的地址回傳給wechat2,最終效果圖依舊如上圖,
在此時,如果不是直接new字串賦值,而是通過+號操作,情況就有所不同,
String s1 = "程式";
String wechat3 = new String(s1 + "新視界");
上述代碼s1會存入常量池,而wechat3的值則由于JVM編譯時采用了StringBuilder進行加號的拼接,只會在堆中創建一個String物件,并不會在常量池中存盤對應的字串,
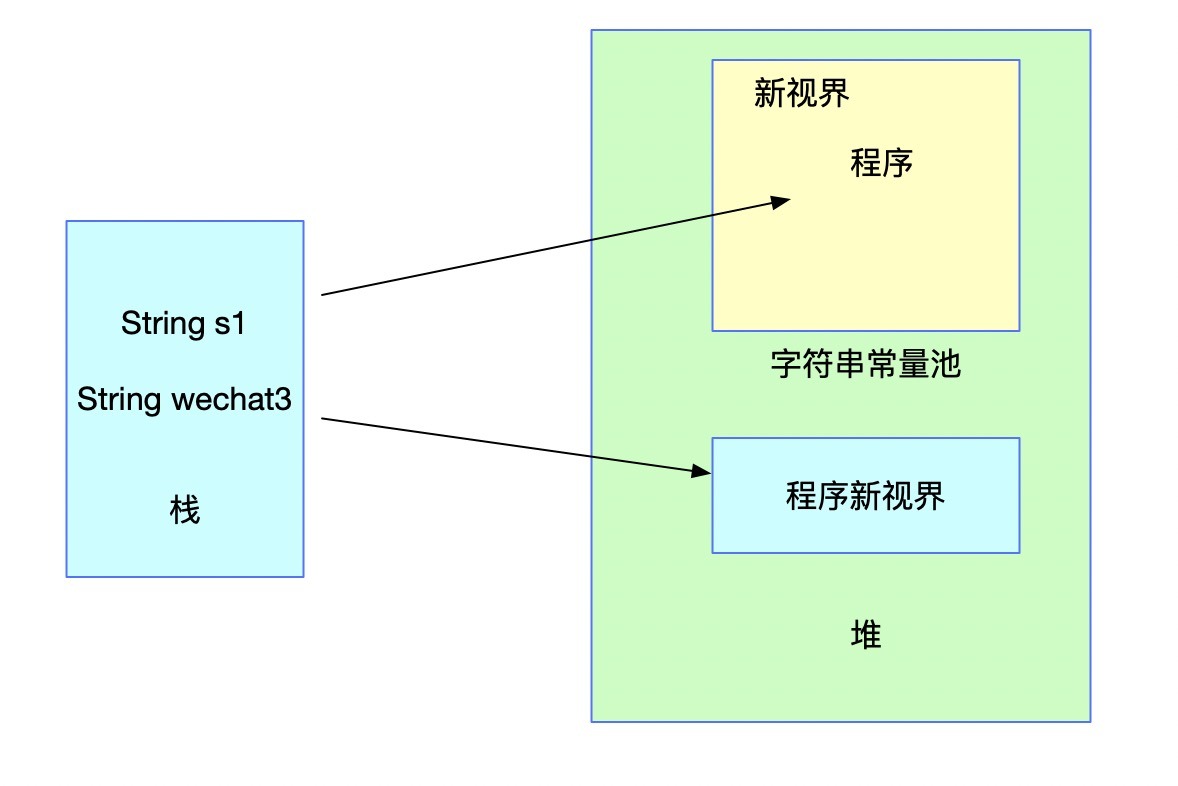
此時的情況已經涉及到我們面試題中創建字串的情況了,那么,下面我們就通過intern方法進行池化操作,看看字串常量池的具體變化,
還以上面的代碼為例,此時wechat、wechat1、wechat2三個變數和wechat3直接用雙等號比較肯定是不相等的,下面對wechat3進行intern池化處理,
String s1 = "程式";
String wechat3 = new String(s1 + "新視界");
wechat3 = wechat3.intern();
此時會發現wechat、wechat1兩個變數與wechat3的值相等了,由于wechat和wechat1其實是一個,這里只以wechat和wechat3的比較為例來分析一下這個流程,
在沒有呼叫intern方法之前記憶體的狀態是下圖(忽略掉s1部分)這樣的:
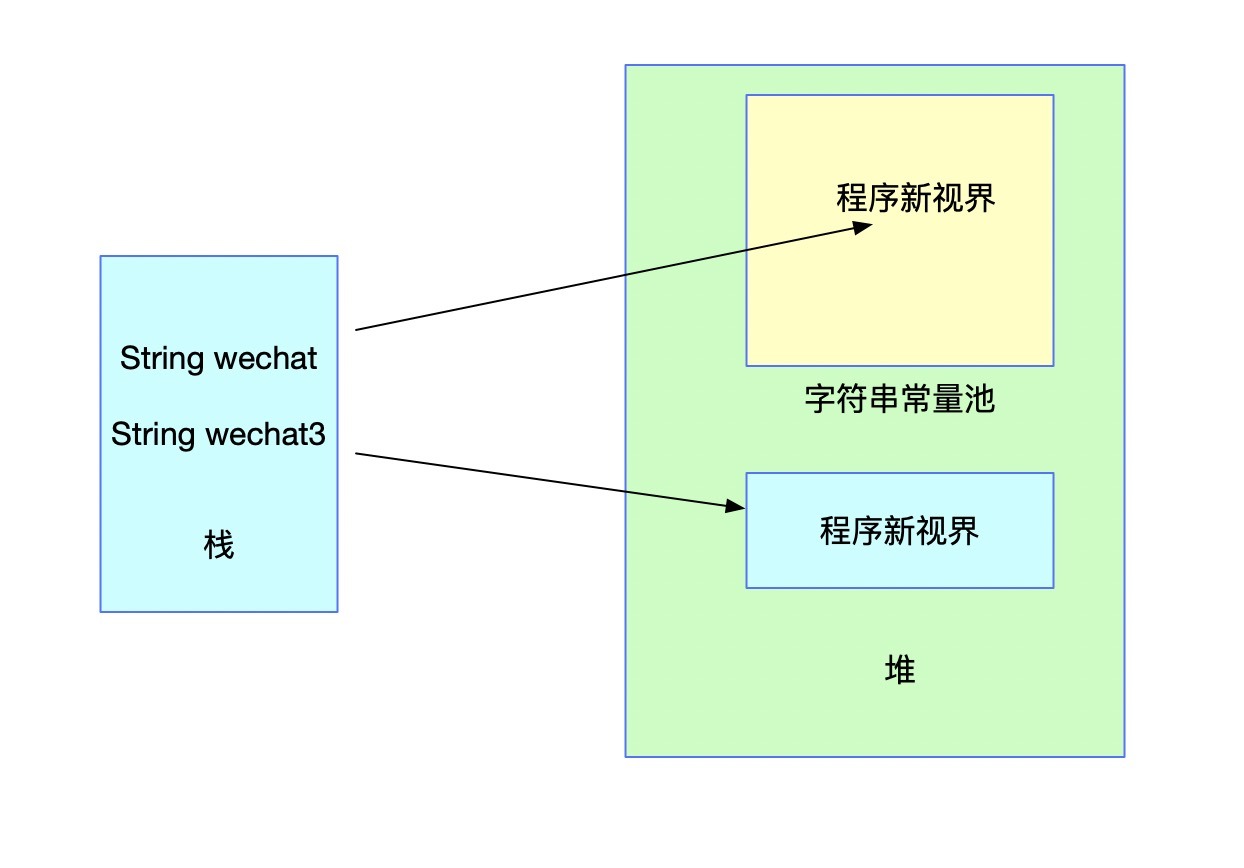
看上圖它們的值不相等也就不奇怪了,下面對wechat3進行池化處理,并把池化的結果賦值給wechat3,就是上面的代碼,記憶體結構會發生如下變化:
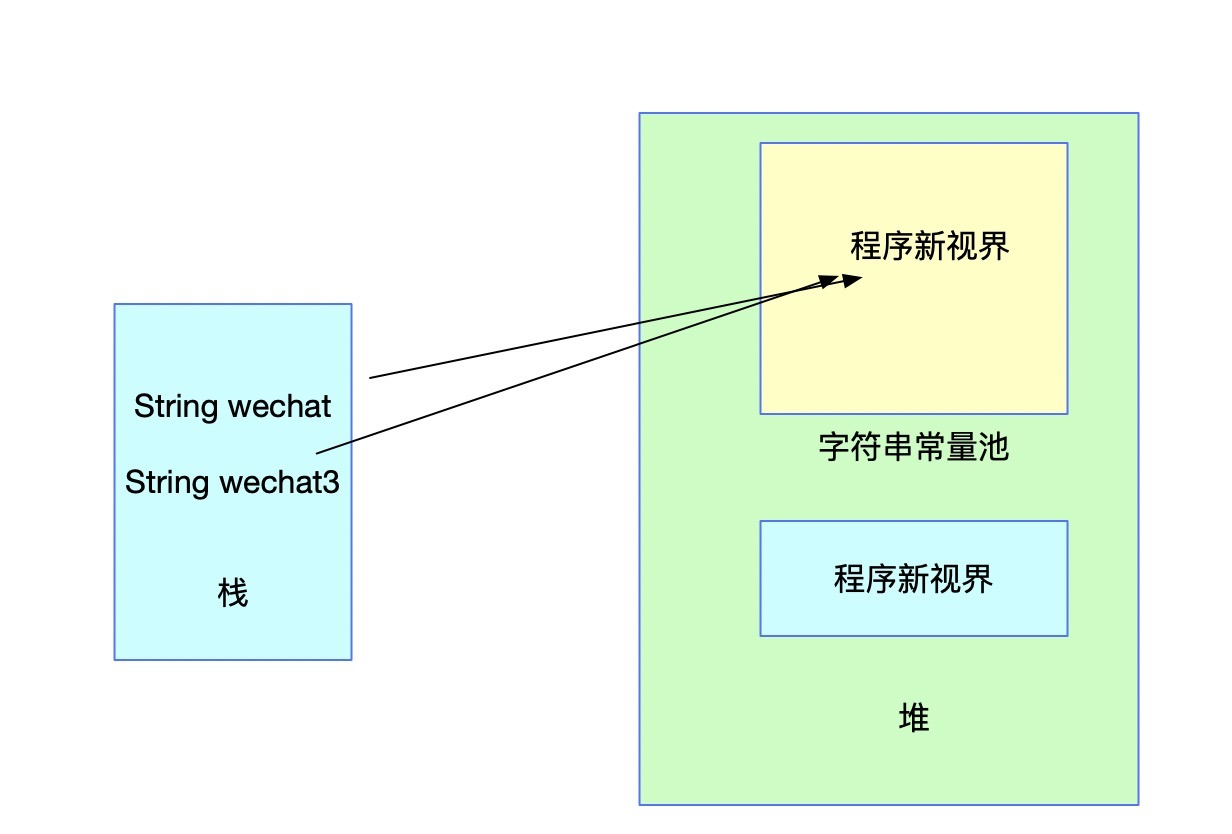
此時,再判斷對應的兩個值,因為參考和字面值全部相同,因此便相等了,具體intern的判斷規則我們上面已經知道,如果常量池中存在對應的值,則直接回傳參考,
那還有另外一種情況,就是常量池中不存在對應的值會是如何處理的呢?先看如下代碼:
String s2 = "關注";
String wechat4 = new String(s2 + "公眾號");
wechat4 = wechat4.intern();
在呼叫intern之前的操作我們前面已經說過,會在堆中創建一個String物件,而常量池中并不會存盤一份,與wechat3的圖一樣,
此時常量池中并未存在對應的字串,此時呼叫intern方法之后,記憶體結構如下:
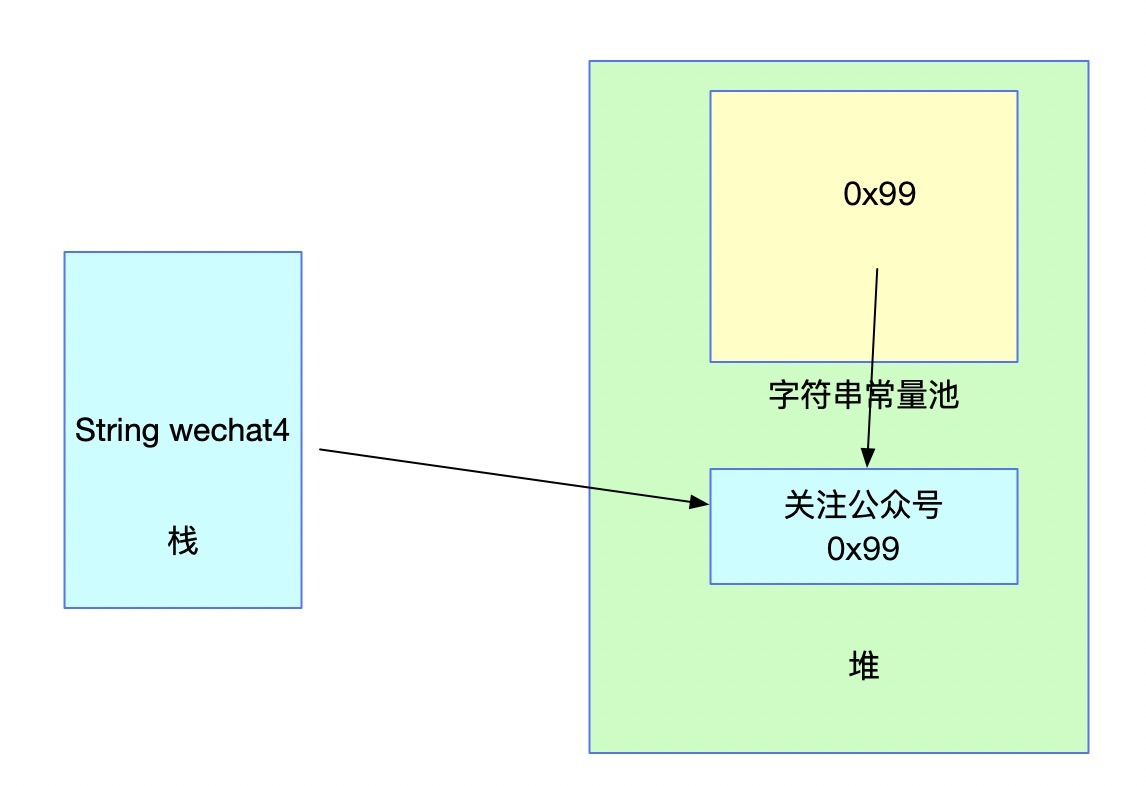
經intern方法之后,常量池中存了堆中對應字串的參考,對照上面說的,JDK7及之后字串常量池中可以存盤參考了,
需要注意的是,當字串常量池中并不存在對應字串時,呼叫intern方法回傳的地址為堆中的地址,對應圖中的0x99,而wechat4本來地址指向的就是堆中的地址,因此不會發生變化,
此時如果再定義一個雙引號賦值的wechat5,如下代碼:
String s2 = "關注";
String wechat4 = new String(s2 + "公眾號");
wechat4 = wechat4.intern();
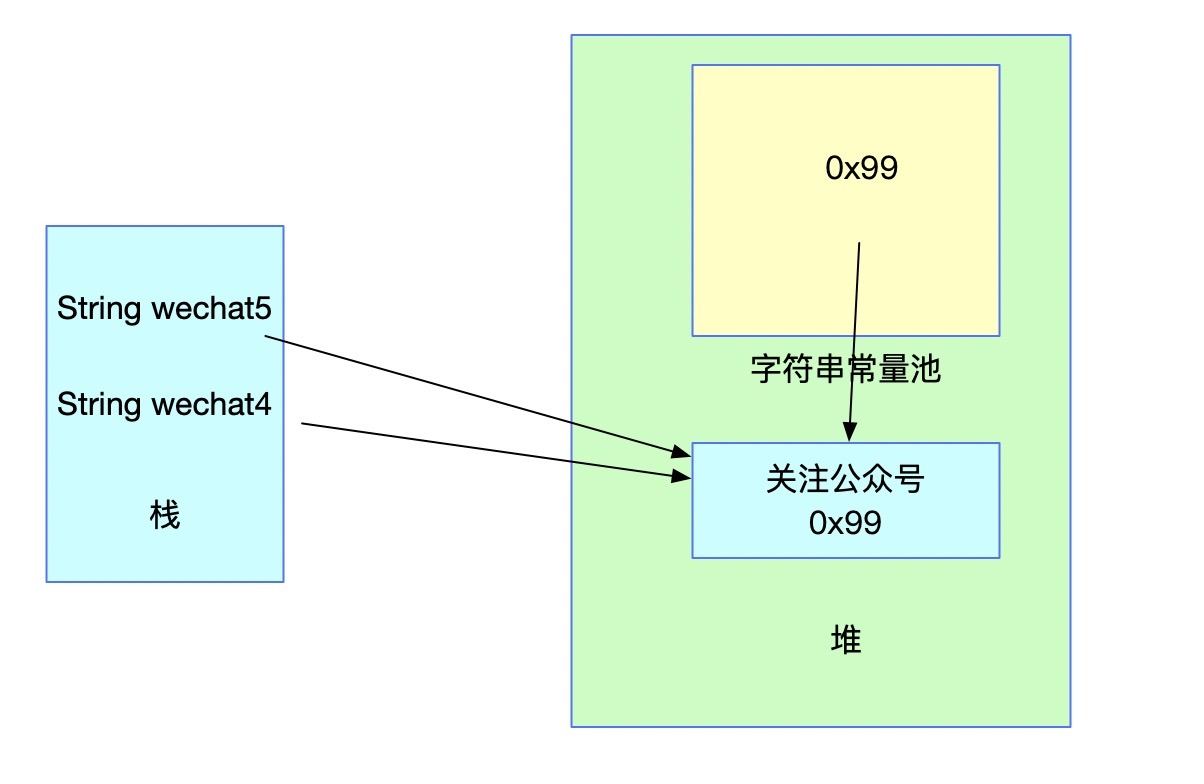
String wechat5 = "關注公眾號";
System.out.println(wechat4 == wechat5);
變數wechat5初始化時發現字串常量池中已經存在了一個參考,那么wechat5會直接指向這個參考,也就是wechat5和wechat4一樣,都指向記憶體中的String物件,
小結
上面這個演示實體時需要注意的重點是intern方法回傳的參考地址,如果字串常量池中已經存在對應的字串時,此時回傳的是字串常量的地址【常量池中存盤的是字串】,如果字串常量池中不存在對應的字串,此時會把堆中的參考放在常量池對應的位置【常量池中存盤的是堆中字串的參考】,此時intern回傳的是堆中字串對應的參考,
搞清楚了上面的回傳邏輯再看最初的代碼:
String s1 = new String("he") + new String("llo");
String s2 = new String("h") + new String("ello");
String s3 = s1.intern();
String s4 = s2.intern();
System.out.println(s1 == s3);
System.out.println(s1 == s4);
其中s1為堆中字串“hello”的地址;s2為堆中另外一個“hello”字串的地址,當s1.intern(),常量池中存盤了s1的地址,此時s1.intern()回傳的也是s1的地址,因此s1=s3,都是同一個地址嘛,
然后執行s2.intern(),此時常量池中已經有hello字串,型別為參考且指向s1的地址,執行之后回傳的便是s1的地址,賦值給s4,因此s1和s4也指向同一個地址,因此相等,
通過上面的更深層次的分析,想必大家對字串常量、字串常量池以及intern方法有了更加深刻的理解,相關的面試題如果按照這個思路分析,基本上都可以進行準確解答了,
參考文章:
https://www.zhihu.com/question/55994121

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/13871.html
標籤:Java
上一篇:Java 的八種排序演算法