前言
Java作為一種平臺無關性的語言,其主要依靠于Java虛擬機——JVM,我們寫好的代碼會被編譯成class檔案,再由JVM進行加載、決議、執行,而JVM有統一的規范,所以我們不需要像C++那樣需要程式員自己關注平臺,大大方便了我們的開發,另外,能夠運行在JVM上的并只有Java,只要能夠編譯生成合乎規范的class檔案的語言都是可以跑在JVM上的,而作為一名Java開發,JVM是我們必須要學習了解的基礎,也是通向高級及更高層次的必修課;但JVM的體系非常龐大,且術語非常多,所以初學者對此非常的頭疼,本系列文章就是筆者自己對于JVM的核心知識(記憶體結構、類加載、物件創建、垃圾回收等)以及性能調優的學習總結,另外未特別指出本系列文章都是基于HotSpot虛擬機進行講解,
正文
JVM包含了非常多的知識,比較核心的有記憶體結構、類加載、類檔案結構、垃圾回收、執行 引擎、性能調優、監控等等這些知識,但所有的功能都是圍繞著記憶體結構展開的,因為我們編譯后的代碼資訊在運行程序中都是存在于JVM自身的記憶體區域中的,并且這塊區域相當的智能,不需要C++那樣需要我們自己手動釋放記憶體,它實作了自動垃圾回識訓制,這也是Java廣受喜愛的原因之一,因此,學習JVM我們首先就得了解其記憶體結構,熟悉包含的東西,才能更好的學習后面的知識,
記憶體結構
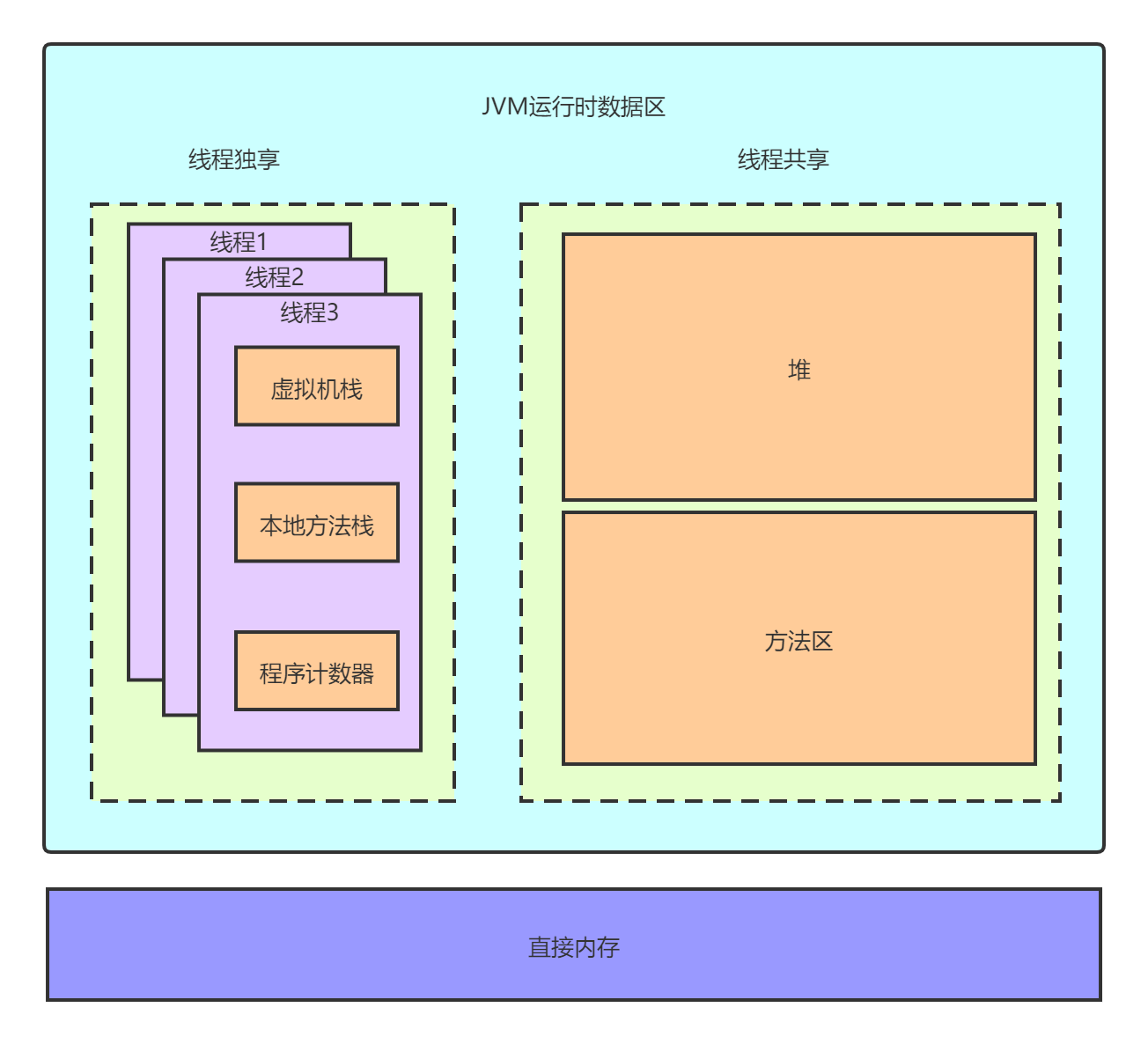
如上圖所示,JVM運行時資料區(即記憶體結構)整體上劃分為執行緒私有和執行緒共享區域,執行緒私有的區域生命周期與執行緒相同,執行緒共享區域則存在于整個運行期間 ,而按照JVM規范細分則分為程式計數器、虛擬機堆疊、本地方法堆疊、方法區和堆五大區域(直接記憶體不屬于JVM),
1. 程式計數器
如其名,這個部件就是用來記錄程式執行的地址的,回圈、跳轉、例外等等需要依靠它,為什么它是執行緒私有的呢?以單核CPU為例,多執行緒在執行時是輪流執行的,那么當執行緒暫停后恢復就需要程式計數器恢復到暫停前的執行位置繼續執行,所以必然是每個執行緒對應一個,由于它只需記錄一個執行地址,所以它是五大區域中唯一一個不會出現OOM(記憶體溢位)的區域,另外它是控制我們JAVA代碼的執行的,在呼叫native方法時該計數器就沒有作用了,而是會由作業系統的計數器控制,
2. 虛擬機堆疊
虛擬機堆疊是方法執行的記憶體區域,每呼叫一個方法都會生成一個堆疊幀壓入堆疊中,當方法執行完成才會彈出堆疊,堆疊幀中又包含了區域變數表、運算元堆疊、動態鏈接、方法出口,其中區域變數表就是用來存盤區域變數的(基本型別值和物件的參考),每一個位置32位,而像long/double這樣的變數則需要占用兩個槽位;運算元堆疊則類似于快取,用于存盤執行引擎在計算時需要用到的區域變數;動態鏈接這里暫時不講,后面的章節會詳細分析;方法出口則包含例外出口和正常出口以及回傳地址,下面來看三個方法示例分別展示堆疊和堆疊幀的運行原理,
- 入堆疊出堆疊程序
public class ClassDemo1 {
public static void main(String[] args) {
new ClassDemo1().a();
}
static void a() { new ClassDemo1().b(); }
static void b() { new ClassDemo1().c(); }
static void c() {}
}
如上所示的方法呼叫入堆疊出堆疊的程序如下:
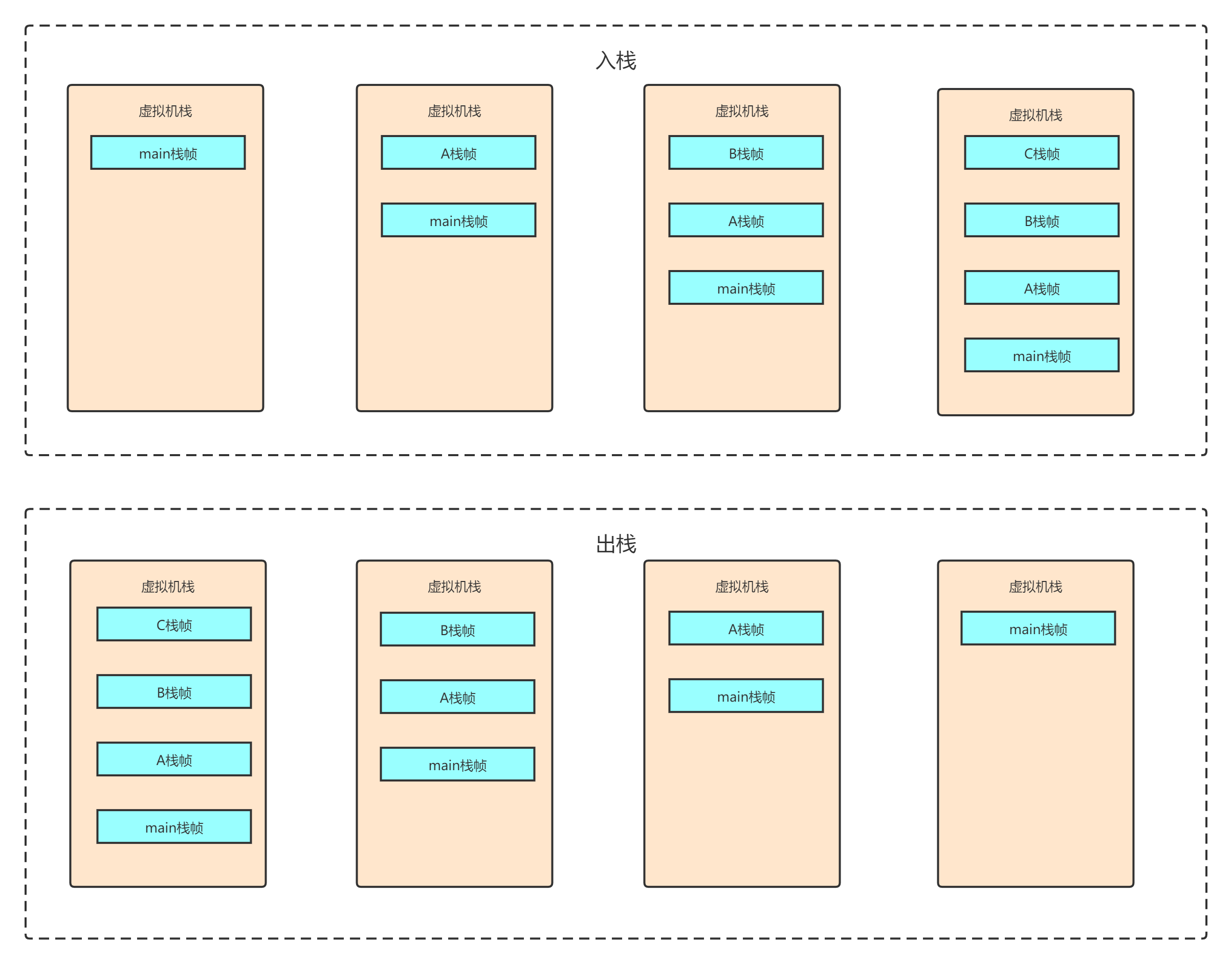
- 堆疊幀執行原理
public class ClassDemo2 {
public int work() {
int x = 3;
int y = 5;
int z = (x + y) * 10;
return z;
}
public static void main(String[] args) {
new ClassDemo2().work();
}
}
上面只是一簡單的計算程式,通過javap -c ClassDemo2.class命令反編譯后看看生成的位元組碼:
public class cn.dark.ClassDemo {
public cn.dark.ClassDemo();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
public int work();
Code:
0: iconst_3
1: istore_1
2: iconst_5
3: istore_2
4: iload_1
5: iload_2
6: iadd
7: bipush 10
9: imul
10: istore_3
11: iload_3
12: ireturn
public static void main(java.lang.String[]);
Code:
0: new #2 // class cn/dark/ClassDemo
3: dup
4: invokespecial #3 // Method "<init>":()V
7: invokevirtual #4 // Method work:()I
10: pop
11: return
}
主要看到work方法中,挨個來解釋(位元組碼指令釋義可以參照這篇文章):執行引擎首先通過iconst_3將常量3存入到運算元堆疊中,然后通過istore_1將該值從運算元堆疊中取出并存入到區域變數表的1號位(注意區域變數表示從0號開始的,但0號位默認存盤了this變數);接著常量5執行同樣的操作,完成后區域變數表中就存了3個變數(this、3、5);之后通過iload指令將局表變數表對應位置的變數加載到運算元堆疊中,因為這里有括號,所以先加載兩個變數到運算元堆疊并執行括號中的加法,即呼叫iadd加法指令(所有二元算數指令會從運算元堆疊中取出頂部的兩個變數進行計算,計算結果自動加入到堆疊中);接著又將常量10壓入到堆疊中,繼續呼叫imul乘法指令,完成后需要通過istore命令再將結果存入到區域變數表中,最后通過ireturn回傳(不管我們方法是否定義了回傳值都會呼叫該指令,只是當我們定義了回傳值時,首先會通過iload指令加載區域變數表的值并回傳給呼叫者),以上就是堆疊幀的運行原理,
該區域同樣是執行緒私有,每個執行緒對應會生成一個堆疊,并且每個堆疊默認大小是1M,但也不是絕對,根據作業系統不同會有所不一樣,另外可以用-Xss控制大小,官方檔案對該該引數解釋如下:

既然可以控制大小,那么這塊區域自然就會存在記憶體不足的情況,對于堆疊當記憶體不足時會出現下面兩種例外:
- 堆疊溢位(StackOverflowError)
- 記憶體溢位(OutOfMemoryError)
為什么會有兩種例外呢?在周志明的《深入理解Java虛擬機》一書中講到,在單執行緒環境下只會出現StackOverflowError例外,即堆疊幀填滿了堆疊或區域變數表過大;而OutOfMemoryError只有當多執行緒情況下,無節制的創建多個堆疊才會出現,因為作業系統對于每個行程是有記憶體限制的,即超出了行程可用的記憶體,無法創建新的堆疊,
- 堆疊幀共享機制
通過上文我們知道同一個執行緒內每個方法的呼叫會對應生成相應的堆疊幀,而堆疊幀又包含了區域變數表和運算元堆疊等內容,那么當方法間傳遞引數時是否可以優化,使得它們共享一部分記憶體空間呢?答案是肯定的,像下面這段代碼:
public int work(int x) throws Exception{
int z =(x+5)*10;// 引數會按照順序放到區域變數表
Thread.sleep(Integer.MAX_VALUE);
return z;
}
public static void main(String[] args)throws Exception {
JVMStack jvmStack = new JVMStack();
jvmStack.work(10);//10 放入運算元堆疊
}
在main方法中首先會把10放入運算元堆疊然后傳遞給work方法,作為引數,會按照順序放入到區域變數表中,所以x會放到區域變數表的1號位(0號位是this),而此時通過HSDB工具查看這時的堆疊呼叫資訊會發現如下情況:

如上圖所示,中間一小塊用紅框圈起來的就是兩個堆疊幀共享的記憶體區域,
3. 本地方法堆疊
和虛擬機堆疊是一樣的,只不過該區域是用來執行本地本地方法的,有些虛擬機甚至直接將其和虛擬機堆疊合二為一,如HotSpot,(通過上面的圖也可以看到,最上面顯示了Thread.sleep()的堆疊幀資訊,并標記了native)
4. 方法區
該區域是執行緒共享的區域,用來存盤已被虛擬機加載的類資訊、常量、靜態變數、即時編譯器編譯后的代碼等資料,該區域在JDK1.7以前是以永久代方式實作的,存在于堆中,可以通過-XX:PermSize(初始值)、-XX:MaxPermSize(最大值)引數設定大小;而1.8以后以元空間方式實作,使用的是直接記憶體(但運行時常量池和靜態變數仍放在堆中),可以通過-XX:MetaspaceSize(初始值)、-XX:MaxMetaspaceSize(最大值)控制大小,如果不設定則只受限于本地記憶體大小,為什么會這么改變呢?因為方法區和堆都會進行垃圾回收,但是方法區中的資訊相對比較靜態,回收難以達到成效,同時需要占用的空間大小更多的取決于我們class的大小和數量,即對該區域難以設定一個合理的大小,所以將其直接放到本地記憶體中是非常有用且合理的,
在方法區中還存在常量池(1.7后放入堆中),而常量池也分了幾種,常常讓初學者比較困惑,比如靜態常量池、運行時常量池、字串常量池,靜態常量池就是指存在于我們的class檔案中的常量池,通過javap -v ClassDemo.class反編譯上面的代碼可以看到該常量池:
Constant pool:
#1 = Methodref #5.#26 // java/lang/Object."<init>":()V
#2 = Class #27 // cn/dark/ClassDemo
#3 = Methodref #2.#26 // cn/dark/ClassDemo."<init>":()V
#4 = Methodref #2.#28 // cn/dark/ClassDemo.work:()I
#5 = Class #29 // java/lang/Object
#6 = Utf8 <init>
#7 = Utf8 ()V
#8 = Utf8 Code
#9 = Utf8 LineNumberTable
#10 = Utf8 LocalVariableTable
#11 = Utf8 this
#12 = Utf8 Lcn/dark/ClassDemo;
#13 = Utf8 work
#14 = Utf8 ()I
#15 = Utf8 x
#16 = Utf8 I
#17 = Utf8 y
#18 = Utf8 z
#19 = Utf8 main
#20 = Utf8 ([Ljava/lang/String;)V
#21 = Utf8 args
#22 = Utf8 [Ljava/lang/String;
#23 = Utf8 MethodParameters
#24 = Utf8 SourceFile
#25 = Utf8 ClassDemo.java
#26 = NameAndType #6:#7 // "<init>":()V
#27 = Utf8 cn/dark/ClassDemo
#28 = NameAndType #13:#14 // work:()I
#29 = Utf8 java/lang/Object
靜態常量池中就是存盤了類和方法的資訊、符號參考以及字面量等東西,當類加載到記憶體中后,JVM就會將這些內容存放到運行時常量池中,同時會將符號參考(可以理解為物件方法的定位描述符)決議為直接參考(即物件的記憶體地址)存入到運行時常量池中(因為在類加載之前并不知道符號參考所對應的物件記憶體地址是多少,需要用符號替代),而字串常量池網上爭議比較多,我個人理解它也是運行時常量池的一部分,專門用于存盤字串常量,這里先簡單提一下,稍后會詳細分析字串常量池,
5. 堆
這個區域是垃圾回收的重點區域,物件都存在于堆中(但隨著JIT編譯器的發展和逃逸分析技術的成熟,物件也不一定都是存在于堆中),可以通過-Xms(最小值)、-Xmx(最大值)、-Xmn(新生代大小)、-XX:NewSize(新生代最小值)、-XX:MaxNewSize(新生代最大值)這些引數進行控制,
在堆中又分為了新生代和老年代,新生代又分為Eden空間、From Survivor空間、To Survivor空間,詳細內容后面文章會詳細講解,這里不過多闡述,
6. 直接記憶體
直接記憶體也叫堆外記憶體,不屬于JVM運行時資料區的一部分,主要通過DirectByteBuffer申請記憶體,該物件存在于堆中,包含了對堆外記憶體的參考;另外也可以通過Unsafe類或其它JNI手段直接申請記憶體,它的大小受限于本地記憶體的大小,也可以通過-XX:MaxDirectMemorySize設定,所以這一塊也會出現OOM例外且較難排查,
字串常量池
這個區域不是虛擬機規范中的內容,所有官方的正式檔案中也沒有明確指出有這一塊,所以這里只是根據現象推匯出結論,什么現象呢?有一個關于字串物件的高頻面試題:下面的代碼究竟會創建幾個物件?
String str = "abc";
String str1 = new string("cde");
我們先不管這個面試題,先來思考下面代碼的輸出結果是怎樣的(以下試驗基于JDK8,更早的版本結果會有所不同):
String s1 = "abc";
String s2 = "ab" + "c";
String s3 = new String("abc");
String s4 = new StringBuilder("ab").append("c").toString();
System.out.println("s1 == s2:" + (s1 == s2));
System.out.println("s1 == s3:" + (s1 == s3));
System.out.println("s1 == s4:" + (s1 == s4));
System.out.println("s1 == s3.intern:" + (s1 == s3.intern()));
System.out.println("s1 == s4.intern:" + (s1 == s4.intern()));
輸出結果如下:
s1 == s2:true
s1 == s3:false
s1 == s4:false
s1 == s3.intern:true
s1 == s4.intern:true
上面的輸出結果和你想象的是否一樣呢?為什么呢?一個個來分析,
- s1 == s2:字面量“abc”會首先去字串常量池找是否有"abc"這個字串,如果有直接回傳參考,如果沒有則創建一個新物件并回傳參考;s2你可能會覺得會創建"ab"、"c"和“abc”三個物件,但實際上首先會被編譯器優化為“abc”,所以等同于s1,即直接從字串常量池回傳s1的參考,
- s1 == s3:s3是通過new創建的,所以這個String物件肯定是存在于堆的,但是其中的char[]陣列是參考字符創常量池中的s1,如果在這之前沒有定義的話會先在常量池中創建“abc”物件,所以這里可能會創建一個或兩個物件,
- s1 == s4:s4通過StringBuilder拼接字串物件,所以看起來理所當然的s1 != s4,但實際上也沒那么簡單,反編譯上面的代碼會可以發現這里又會被編譯器優化為s4 = "ab" + "c",猜猜這下會創建幾個物件呢?拋開前面創建的物件的影響,這里會創建3個物件,因為與s2不同的是s4是編譯器優化過后還存在“+”拼接,因此會在字符創常量池創建“ab”、"c"以及“abc”三個物件,前兩個可以反編譯看位元組碼指令或是通過記憶體搜索驗證,而第三個的驗證稍后進行,
- s1 == s3.intern/s4.intern:這兩個為什么是true呢?先來看看周志明在《深入理解Java虛擬機》書中說的:
使用String類的intern方法動態添加字串常量到運行時常量池中(intern方法在1.6和1.7及以后的實作不相同,1.6字串常量池放于永久代中,intern會把首次遇到的字串實體復制永久代中并回傳永久代中的參考,而1.7及以后常量池也放入到了堆中,intern也不會再復制實體,只是在常量池中記錄首次出現的實體參考),
上面的意思很明確,1.7以后intern方法首先會去字串常量池尋找對應的字串,如果找到了則回傳對應的參考,如果沒有找到則先會在字串常量池中創建相應的物件,因此,上面s3和s4呼叫intern方法時都是回傳s1的參考,
看到這里,相信各位讀者基本上也都能理解了,對于開始的面試題應該也是心中有數了,最后再來驗證剛剛說的“第三個物件”的問題,先看下面代碼:
String s4 = new StringBuilder("ab").append("c").toString();
System.out.println(s4 == s4.intern());
這里結果是true,為什么呢?別急,再來看另外一段代碼:
String s3 = new String("abc");
String s4 = new StringBuilder("ab").append("c").toString();
System.out.println(s3 == s3.intern());
System.out.println(s4 == s4.intern());
這里結果是兩個false,和你心中的答案是一致的么?上文剛剛說了intern會先去字串常量池找,找到則回傳參考,否則在字符創常量池創建一個物件,所以第一段代碼結果等于true正好說明了通過StringBuilder拼接的字串會存到字串常量池中;而第二段代碼中,在StringBuilder拼接字串之前已經優先使用new創建了字串,也就會在字串常量里創建“abc”物件,因此s4.intern回傳的是該常量的參考,和s4不相等,你可能會說是因為優先呼叫了s3.intern方法,但即使你去掉這一段,結果還是一樣的,也剛好驗證了new String("abc")會創建兩個物件(在此之前沒有定義“abc”字面量,就會在字串常量池創建物件,然后堆中創建String物件并參考該常量,否則只會創建堆中的String物件),
總結
本文是JVM系列的開篇,主要分析JVM的運行時資料區、簡單引數設定和位元組碼閱讀分析,這也是學習JVM及性能調優的基礎,讀者需要深刻理解這些內容以及哪些區域會發生記憶體溢位(只有程式計數器不會記憶體溢位),另外關于運行時常量池和字串常量池的內容也需要理解透徹,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/139427.html
標籤:Java