Github專案地址
![]()
![]()
前言
該專案始于個人興趣,本意為給無代碼經驗的朋友做到能開箱即用
閱讀此文需要少量Scrapy,PyQt 知識,全文僅分享交流 摘要思路,如需可閱讀原始碼,歡迎提 issue
一、Scrapy
思路構想
基類封裝了框架所需方法,框架基于三級頁面 (標題-章節-詳情頁) 網站,內部方法分岔線基于互動思想
- GUI傳參并開啟后臺 >> spider開始作業于重寫的start_requests >> 在parse等處理resp的方法后掛起等待選擇
- 執行順序為 (1) parse -- frame_book --> (2) parse_section -- frame_section -->(3) yield item frame方法下述講解
- pipeline對item作最后的下載,改名等處理,至此spider完成一個生命周期,發送結束信號邏輯交回GUI
BaseClassSpider
class BaseComicSpider(scrapy.Spider):
"""改寫start_requests"""
step = 'loop'
current_status = {}
print_Q = None
current_Q = None
step_Q = None
bar = None # 此處及以上變數均為互動信號
total = 0 # item 計數,pipeline處講解
search_url_head = NotImplementedError('需要自定義搜索網址')
mappings = {'': ''} # mappings自定義關鍵字對應網址
# ……………………
def parse(self, response):
frame_book_results = self.frame_book(response)
yield scrapy.Request(url=title_url, ………………)
def frame_book(self, response) -> dict:
raise NotImplementedError
def elect_res(self, elect: list, frame_results: dict, **kw) -> list:
# 封裝方法實作(1)選擇elect與(2)frame方法格式化后的顯示result ->
# -> 回傳[[elected_title1, title1_url], [title2, title2_url]……]的格式資料
pass
# ……………………
def close(self, reason):
# ………處理管道,session等關閉作業
self.print_Q.put('結束信號')
InstanceClassSpider
后臺執行的實體,簡單的二級頁面僅需復寫兩個frame方法,對應的是擴展的基類2
frame方法功能為定位目標元素位置,實時清洗資料回傳給前端顯示
class ComicxxxSpider(BaseComicSpider2):
name = 'comicxxx'
allowed_domains = ['m.xxx.com']
search_url_head = 'http://m.xxx.com/search/?keywords='
mappings = {'更新': 'http://m.xxx.com/update/', '排名': 'http://m.xxx.com/rank/'}
def frame_book(self, response):
# ……………………
title = target.xpath(title_xpath).get().strip()
self.print_Q.put(example_b.format(str(x + 1), title)) # 發送前端print信號
def frame_section(self, response):
pass # 類上
setting
setting.py自定義部分與部署相關,使用 工具集 的方法讀取組態檔構成變數
IMAGES_STORE, log_path, PROXY_CUST, LOG_LEVEL = get_info()
os.makedirs(f'{log_path}', exist_ok=True)
# 日志輸出
LOG_FILE = f"{log_path}/scrapy.log"
SPECIAL = ['joyhentai']
pipelines
def file_path(self, request, response=None, info=None):
"""圖片下載存盤前呼叫,默認為url的md5后字串,此處修改成自定義的有序命名"""
title = sub(r'([|.:<>?*"\\/])', '-', request.item.get('title')) # 對非法字符預處理
section = sub(r'([|.:<>?*"\\/])', '-', request.item.get('section'))
page = '第%s頁.jpg' % request.item.get('page')
spider = self.spiderinfo.spider # setting.py的引數在此使用
basepath = spider.settings.get('IMAGES_STORE')
path = f"{basepath}\\特殊\\{title}" if spider.name in spider.settings.get(
'SPECIAL') else f"{basepath}\\{title}\\{section}\\"
os.makedirs(path, exist_ok=True)
return os.path.join(path, page)
def image_downloaded(self, response, request, info):
"""繼承的ImagesPipeline圖片(檔案)下載完成方法,下載進度條動態顯示的實作就在此處"""
self.now += 1 # (ComicPipeline)self.now即為現時處理量
spider = self.spiderinfo.spider
percent = int((self.now / spider.total) * 100) # spider.total即為item的總任務量
if percent > self.threshold:
percent -= int((percent / self.threshold) * 100) # 進度緩慢化(演算法待優化)
spider.bar.put(int(percent)) # 后臺列印百分比進度扔回GUI界面
super(ComicPipeline, self).image_downloaded(response=response,request=request, info=info)
其他:Items與Middlewares要點不多,略過
二、GUI (Qt)
主界面及功能
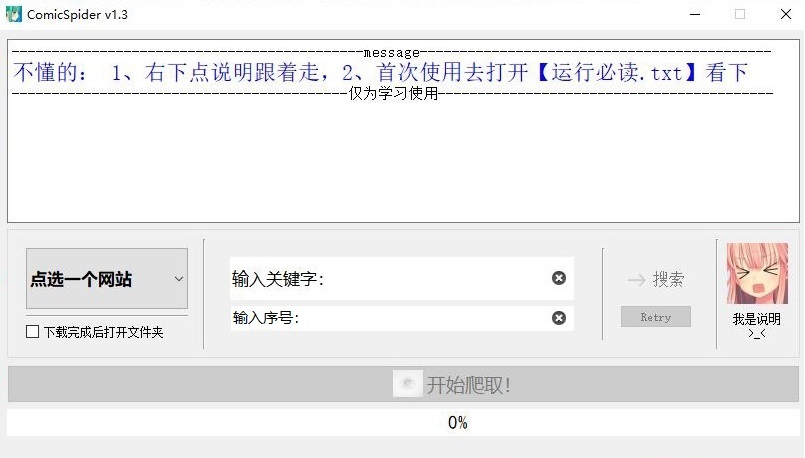
-
按鍵邏輯:槽函式實作,內部實作一定量的按鈕禁用方法引導操作
- 選取網站 按鈕與 輸入關鍵字 構成引數,由→搜索 按鈕觸發作業執行緒等生成,然后替換成 Next 按鈕
- Next 按鈕為正常流程 -- 觸發解除后臺因等待輸入造成的主動阻塞 同時傳遞 輸入序號 的值
- Retry 按鈕承擔后臺Spider中parse方法間的逆跳轉,以及重啟GUI的功能
-
視窗與資訊
-
主視窗textbrowser,流式顯示;整體行內其他視窗,略過
-
說明按鈕通用說明、底下狀態欄通過setStatusTip方法于各操作時提供人性化操作提示
-
進度條,關聯 pipeline 的信號輸出
-
節選 Next 按鈕邏輯的 槽函式
def next_schedule(self):
def start_and_search():
self.log.debug('===--→ -*- searching')
self.next_btn.setText('Next')
keyword = self.searchinput.text()[6:].strip()
index = self.chooseBox.currentIndex()
if self.nextclickCnt == 0: # 從section步 回parse步 的話以免重開
self.bThread = WorkThread(self)
def crawl_btn(text):
if len(text) > 5:
self.crawl_btn.setEnabled(self.step_recv()=='parse section')
self.next_btn.setDisabled(self.crawl_btn.isEnabled())
self.chooseinput.textChanged.connect(crawl_btn)
self.p = Process(target=crawl_what, args=(index, self.print_Q, self.bar, self.current_Q, self.step_Q))
self.bThread.print_signal.connect(self.textbrowser_load)
self.bThread.item_count_signal.connect(self.processbar_load)
self.bThread.finishSignal.connect(self.crawl_end)
self.p.start()
self.bThread.start()
self.log.info(f'-*-*- Background thread starting')
self.chooseBox.setDisabled(True)
self.params_send({'keyword':keyword})
self.log.debug(f'website_index:[{index}], keyword [{keyword}] success ')
def _next():
self.log.debug('===--→ nexting')
self.judge_retry() # 非retry的時候先把retry=Flase解鎖spider的下一步
choose = judge_input(self.chooseinput.text()[5:].strip())
if self.nextclickCnt == 1:
self.book_choose = choose
# 選0的話這里要爬蟲回傳書本數量資料
self.book_num = len(self.book_choose)
if self.book_num > 1:
self.log.info('book_num > 1')
self.textBrowser.append(self.warning_(f'警告!!多選書本時不要隨意使用 retry<br>'))
self.chooseinput.clear()
# choose邏輯 交由crawl, next,retry3個btn的schedule控制
self.params_send({'choose': choose})
self.log.debug(f'send choose: {choose} success')
self.retrybtn.setEnabled(True)
if self.next_btn.text()!='搜索':
_next()
else:
start_and_search()
self.nextclickCnt += 1
self.searchinput.setEnabled(False)
self.chooseinput.setFocusPolicy(Qt.StrongFocus)
self.step_recv() # 封裝的self.step_Q處理方法
self.log.debug(f"===--→ next_schedule end (now step: {self.step})\n")
后臺執行緒
后臺爬蟲行程創建方法 ,上述UI主執行緒中Next邏輯的 start_and_search() 呼叫
def crawl_what(index, print_Q, bar, current_Q, step_Q):
spider_what = {1: 'comic1,
2: 'comic2',
3: 'comic3'}
freeze_support()
process = CrawlerProcess(get_project_settings())
process.crawl(spider_what[index], print_Q=print_Q, bar=bar, current_Q=current_Q, step_Q=step_Q)
process.start()
process.join()
process.stop()
分離UI主執行緒與作業執行緒(專案代碼中此處可整合爬蟲行程一起)
class WorkThread(QThread):
item_count_signal = pyqtSignal(int)
print_signal = pyqtSignal(str)
finishSignal = pyqtSignal(str)
active = True
def __init__(self, gui):
super(WorkThread, self).__init__()
self.gui = gui
def run(self):
while self.active:
self.msleep(8)
if not self.gui.print_Q.empty():
self.msleep(8)
self.print_signal.emit(str(self.gui.print_Q.get()))
if not self.gui.bar.empty():
self.item_count_signal.emit(self.gui.bar.get())
self.msleep(10)
if '完成任務' in self.gui.textBrowser.toPlainText():
self.item_count_signal.emit(100)
self.msleep(20)
break
if self.active:
from ComicSpider.settings import IMAGES_STORE
self.finishSignal.emit(IMAGES_STORE)
輔助工具
資源處理工具
- PYUIC >>> 將.ui界面檔案轉換成py檔案
- pyrcc5 >>> 將編入資源路徑后的qrc檔案,轉換成py檔案
工具集 utils.py
def get_info():
with open(f'./setting.txt', 'r', encoding='utf-8') as fp:
text = fp.read()
sv_path = re.findall(r'<([\s\S]*)>', text)[0]
level = re.findall('(DEBUG|INFO|ERROR)', text)[0]
# ………………
def cLog(name, level='INFO', **kw) -> Logger:
# 同理讀取setting.txt,
level = re.search('(DEBUG|WARNING|ERROR)', text).group(1)
def judge_input(_input: str) -> list:
"""
"6" return [6] // "1+3+5" return [1,3,5]
"4-6" return [4,5,6] // "1+4-6" return [1,4,5,6]
"""
三、部署
部署實為pyinstaller打包成exe
pyinstaller注意要點:
- 查閱資料和前人摸路,scrapy的打包需要在主運行檔案中匯入大量模塊,可參考 我的配置
- spec的
datas中每個值前為專案現位置,后為運行時位置;慎用網上傳授的('.', '.'),使用不當會使得git體積飛漲 - 將
debug、console設定為True,方便除錯 ( 與上述匯入模塊除錯有所關聯
spec參考
# -*- mode: python -*-
block_cipher = None
a = Analysis(['crawl_go.py'],
pathex=['D:\\xxxxxxxxxxxxxxxx\\ComicSpider'],
binaries=[],
datas=[('D:\python\Lib\site-packages\scrapy\mime.types','scrapy'),
('D:\python\Lib\site-packages\scrapy\VERSION','scrapy'),
('./ComicSpider','ComicSpider'), ('./GUI', 'GUI'),
('./gui.py', '.'), ('./material_ct.py', '.'), ('./utils.py', '.'),
], # -*-
hiddenimports=[],
hookspath=[],
runtime_hooks=[],
excludes=[],
win_no_prefer_redirects=False,
win_private_assemblies=False,
cipher=block_cipher,
noarchive=False)
pyz = PYZ(a.pure, a.zipped_data,
cipher=block_cipher)
exe = EXE(pyz,
a.scripts,
a.binaries,
a.zipfiles,
a.datas,
[],
name='ComicSpider',
debug=True, # -*-
bootloader_ignore_signals=False,
strip=False,
upx=True,
runtime_tmpdir=None,
console=True, icon='exe.ico') # -*-
打包后目錄樹
├── ComicSpider.exe
├── log
│ ├── GUI.log
│ └── scrapy.log
├── scrapy.cfg # 經測驗過,scrapy.cfg內置到exe中并不起作用,猜測與快取路徑有關,外置無傷大雅
├── setting.txt
總結
scrapy用在這種單機互動上的效果不錯,pyqt方面還只算用到了皮毛
歡迎大家前往 本專案 試用下交流下意見
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/139690.html
標籤:其他