面試場景
面試官:Redis有哪些資料型別?
我:String,List,set,zset,hash
面試官:沒了?
我:哦哦哦,還有HyperLogLog,bitMap,GeoHash,BloomFilter
面試官:就這?回家等通知吧,

前言
我敢肯定,第一個回答,100%的人都能說上來,但是第二個回答能回答上來的人可能就不多了,但是這也不是我今天探討的話題,
我就從我自己的去面試的回答思路,以及作為一個面試官他想聽到的標準答案來給大家出一期,Redis基礎型別的文章(系列文章),寫這個的時候我還是很有心得的,不知道大家有多少人跟我最開始一樣,面試官問有哪些型別,就回答出那五種就結束了,如果你是這樣的可以在評論區留言,讓我看看有多少人是這樣的,
但是,一場面試少說都是半小時起步上不封頂,你這樣一句話就回答了這么重要的五個知識點,這個結果是你想要的么?是面試官想要的么?
我再問你一個問題,你可能就懵逼了:String在Redis底層是怎么存盤的?這些資料型別在Redis中是怎么存放的?Redis快的原因就只有單執行緒和基于記憶體么?

寶貝,觸及知識盲區沒?不慌,我以前也是這樣的,我以為我背出那五種就完事了,結果被面試官安排了一波,后面我苦心修煉,總算是好了一點,現在對快取也是非常熟悉了,你不會沒事,有我嘛,乖,
正文
Redis是C語言開發的,C語言自己就有字符型別,但是Redis卻沒直接采用C語言的字串型別,而是自己構建了動態字串(SDS)的抽象型別,

就好比這樣的一個命令,其實我是在Redis創建了兩個SDS,一個是名為aobing的Key SDS,另一個是名為cool的Value SDS,就算是字符型別的List,也是由很多的SDS構成的Key和Value罷了,
SDS在Redis中除了用作字串,還用作緩沖區(buffer),那到這里大家都還是有點疑惑的,C語言的字串不好么為啥用SDS?SDS長啥樣?有什么優點呢?
為此我去找到了Redis的原始碼,可以看到SDS值的結果大概是這樣的,原始碼的在GitHub上是開源的大家一搜就有了,
struct sdshdr{
int len;
int free;
char buf[];
}
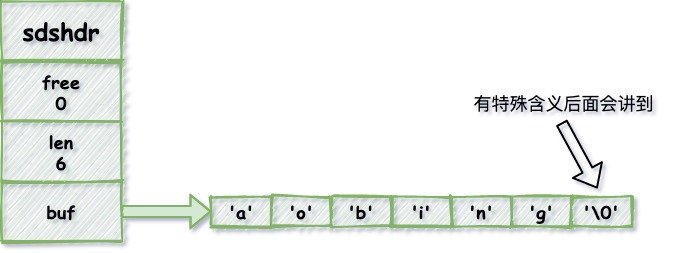
回到最初的問題,為什么Redis用了自己新開發的SDS,而不用C語言的字串?那好我們去看看他們的區別,
SDS與C字串的區別
計數方式不同
C語言對字串長度的統計,就完全來自遍歷,從頭遍歷到末尾,直到發現空字符就停止,以此統計出字串的長度,這樣獲取長度的時間復雜度來說是0(n),大概就像下面這樣:
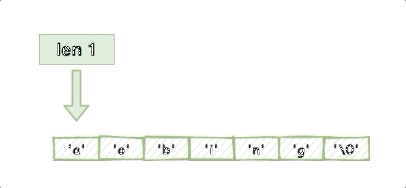
但是這樣的計數方式會留下隱患,所以Redis沒有采用C的字串,我后面會提到,
而Redis我在上面已經給大家看過結構了,他自己本身就保存了長度的資訊,所以我們獲取長度的時間復雜度為0(1),是不是發現了Redis快的一點小細節了?還沒完,不止這些,
杜絕緩沖區溢位
字串拼接是我們經常做的操作,在C和Redis中一樣,也是很常見的操作,但是問題就來了,C是不記錄字串長度的,一旦我們呼叫了拼接的函式,如果沒有提前計算好記憶體,是會產生快取區溢位的,
比如本來字串長這樣:
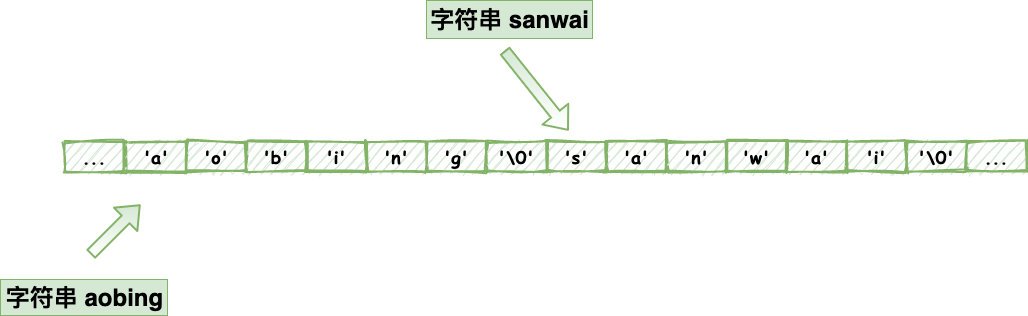
你現在需要在后面拼接 ,但是你沒計算好記憶體,結果就可能這樣了:
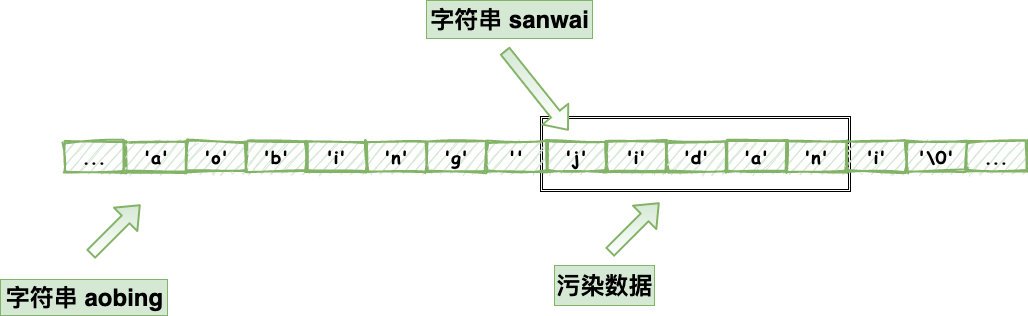
這是你要的結果么?很顯然,不是,你的結果意外的被修改了,這要是放在線上的系統,這不是完了?那Redis是怎么避免這樣的情況的?
我們都知道,他結構存盤了當前長度,還有free未使用的長度,那簡單呀,你現在做了拼接操作,我去判斷一些是否可以放得下,如果長度夠就直接執行,如果不夠,那我就進行擴容,
這些大家在Redis原始碼里面都是可以看到對應的API的,后面我就不一一貼原始碼了,有興趣的可以自己去看一波,需要一點C語言的基礎,
減少修改字串時帶來的記憶體重分配次數
C語言字串底層也是一個陣列,每次創建的時候就創建一個N+1長度的字符,多的那個1,就是為了保存空字符的,這個空字符也是個坑,但是不是這個環節探討的內容,
Redis是個高速快取資料庫,如果我們需要對字串進行頻繁的拼接和截斷操作,如果我們寫代碼忘記了重新分配記憶體,就可能造成緩沖區溢位,以及記憶體泄露,
記憶體分配演算法很耗時,且不說你會不會忘記重新分配記憶體,就算你全部記得,對于一個高速快取資料庫來說,這樣的開銷也是我們應該要避免的,
Redis為了避免C字串這樣的缺陷,就分別采用了兩種解決方案,去達到性能最大化,空間利用最大化:
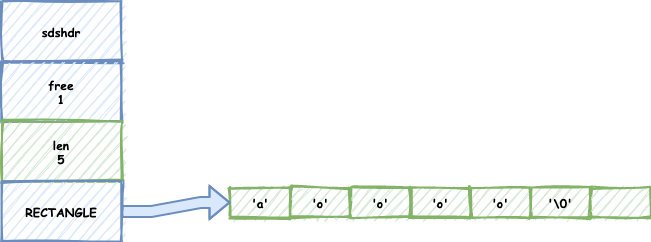
空間預分配:當我們對SDS進行擴展操作的時候,Redis會為SDS分配好記憶體,并且根據特定的公式,分配多余的free空間,還有多余的1byte空間(這1byte也是為了存空字符),這樣就可以避免我們連續執行字串添加所帶來的記憶體分配消耗,
比如現在有這樣的一個字符:
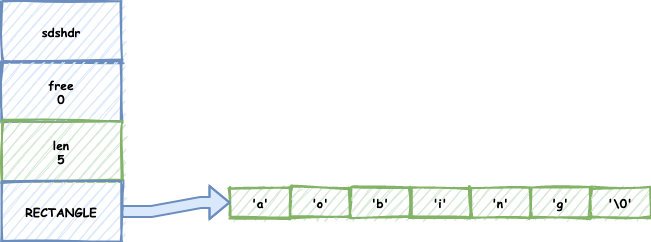
我們呼叫了拼接函式,字串邊長了,Redis還會根據演算法計算出一個free值給他備用:
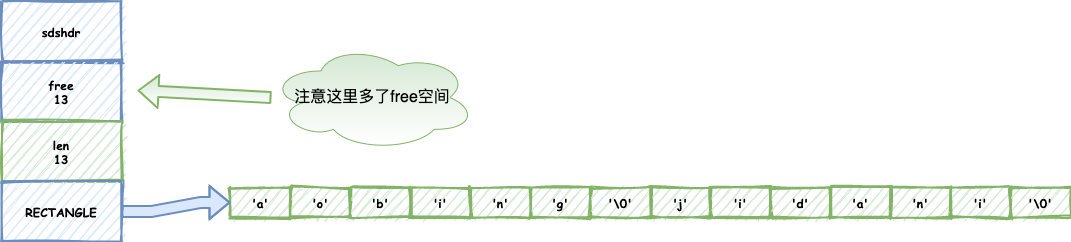
我們再繼續拼接,你會發現,備用的free用上了,省去了這次的記憶體重分配:

惰性空間釋放:剛才提到了會預分配多余的空間,很多小伙伴會擔心帶來記憶體的泄露或者浪費,別擔心,Redis大佬一樣幫我們想到了,當我們執行完一個字串縮減的操作,redis并不會馬上識訓我們的空間,因為可以預防你繼續添加的操作,這樣可以減少分配空間帶來的消耗,但是當你再次操作還是沒用到多余空間的時候,Redis也還是會識訓對于的空間,防止記憶體的浪費的,
還是一樣的字串:
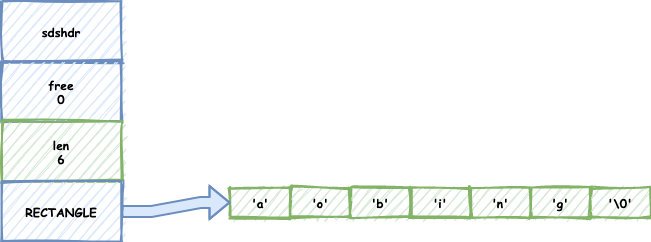
當我們呼叫了刪減的函式,并不會馬上釋放掉free空間:
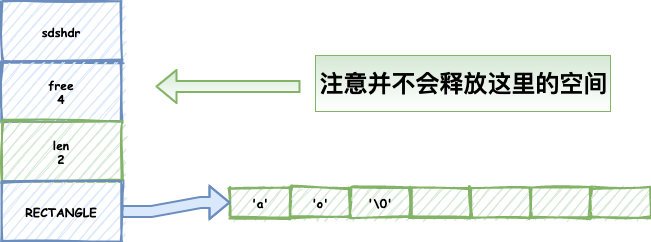
如果我們需要繼續添加這個空間就能用上了,減少了記憶體的重分配,如果空間不需要了,呼叫函式刪掉就好了:
二進制安全
仔細看的仔肯定看到上面我不止一次提到了空字符也就是’\0‘,C語言是判斷空字符去判斷一個字符的長度的,但是有很多資料結構經常會穿插空字符在中間,比如圖片,音頻,視頻,壓縮檔案的二進制資料,就比如下面這個單詞,他只能識別前面的 不能識別后面的字符,那對于我們開發者而言,這樣的結果顯然不是我們想要的對不對,
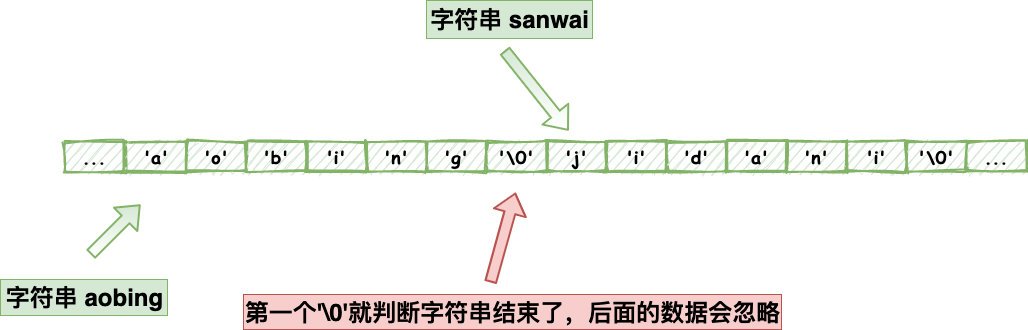
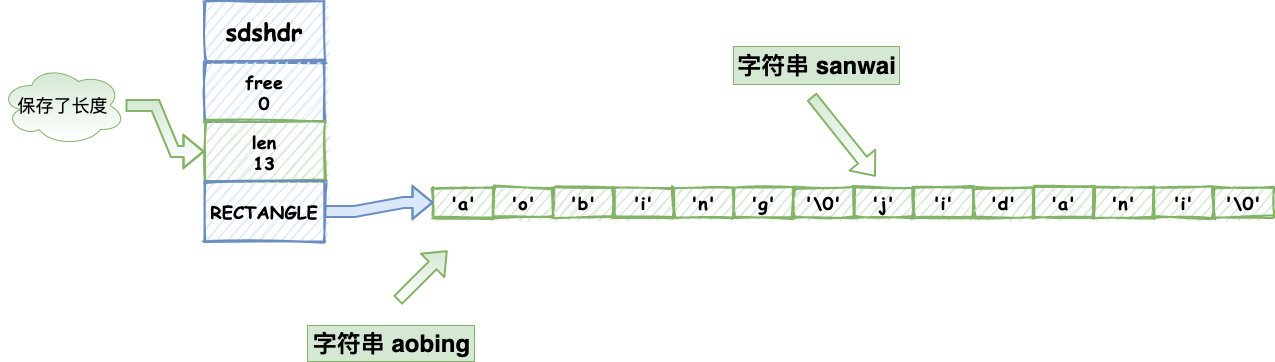
Redis就不存在這個問題了,他不是保存了字串的長度嘛,他不判斷空字符,他就判斷長度對不對就好了,所以redis也經常被我們拿來保存各種二進制資料,我反正是用的很high,經常用來保存小檔案的二進制,
資料參考:Redis設計與實作
總結
大家是不是發現,一個小小的SDS居然有這么多道理在這?
以前就知道Redis快,最多說個Redis是單執行緒的,說個多路IO復用,說個基于記憶體的操作就完了,現在是不是還可以展開說說了?
本文是系列文的第一章,后續會陸續更新的,不知道這樣的型別大家是否喜歡,可以留言給我反饋,
大家一同去面試,一樣的問題,就是有人能過,有人不能過,大家經常歸咎于自己學歷,自己過往經歷的原因,但是你可以問一下自己,底層的細節位元組是否有深究呢?細節往往才是最重要的,也是最少人知道的,如何和別的仔拉開差距拿到offer,我想就是這樣些細節決定的吧,背誰不會呢?
絮叨
另外,敖丙把自己的面試文章整理成了一本電子書,共 1630頁!目錄如下
現在免費送給大家,在我的公眾號三太子敖丙回復 【888】 即可獲取,

我是敖丙,一個在互聯網茍且偷生的程式員,
你知道的越多,你不知道的越多,人才們的 【三連】 就是丙丙創作的最大動力,我們下期見!
注:如果本篇博客有任何錯誤和建議,歡迎人才們留言!
文章持續更新,可以微信搜索「 三太子敖丙 」第一時間閱讀,回復【資料】有我準備的一線大廠面試資料和簡歷模板,本文 GitHub https://github.com/JavaFamily 已經收錄,有大廠面試完整考點,歡迎Star,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/139926.html
標籤:Java
下一篇:Linux下安裝nginx