背景
公司線上有個tomcat服務,里面合并部署了大概8個微服務,之所以沒有像其他微服務那樣單獨部署,其目的是為了節約服務器資源,況且這8個服務是屬于邊緣服務,并發不高,就算宕機也不會影響核心業務,
因為并發不高,所以線上一共部署了2個tomcat進行負載均衡,
這個tomcat剛上生產線,運行挺平穩,大概過了大概1天后,運維同事反映2個tomcat節點均掛了,無法接受新的請求了,CPU飆升到100%,
排查程序一
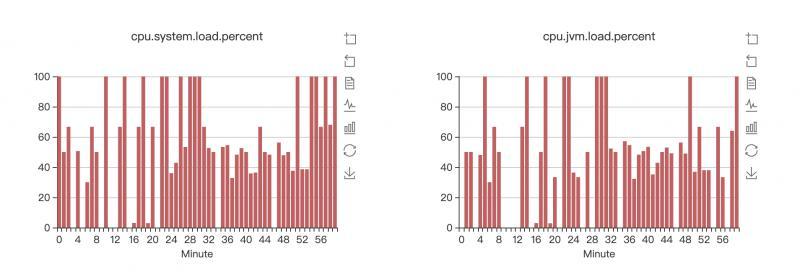
接手這個問題后,首先大致看了下當時的JVM監控,
CPU的確居高不下
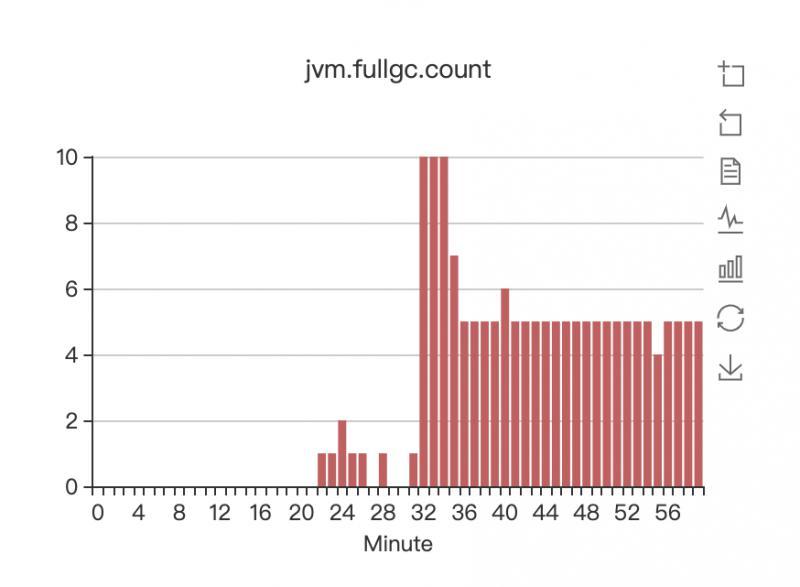
FULL GC從大概這個小時的22分開始,就開始頻繁的進行FULL GC,一分鐘最高能進行10次FULL GC
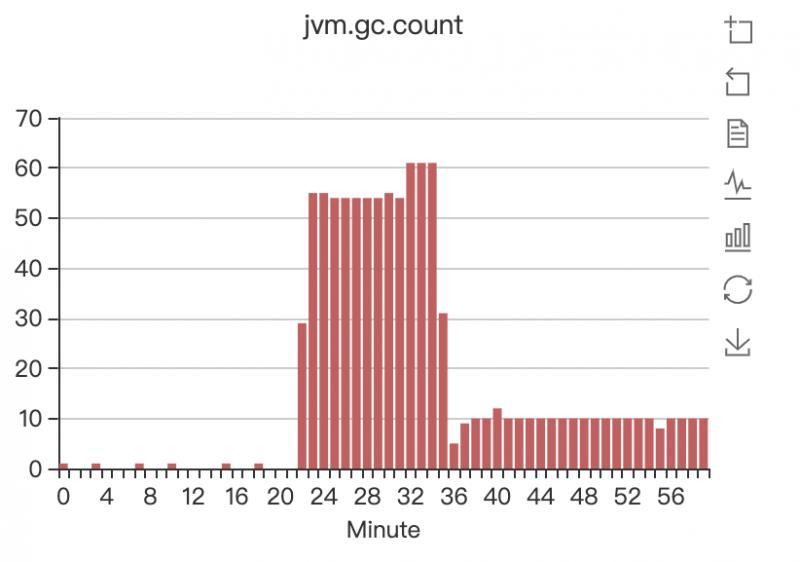
minor GC每分鐘竟然接近60次,相當于每秒鐘都有minor GC
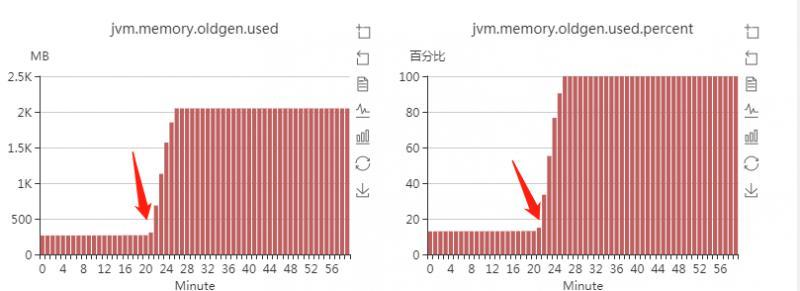
從老年代的使用情況也反應了這一點
隨機對線上應用分析了執行緒的cpu占用情況,用top -H -p pid命令
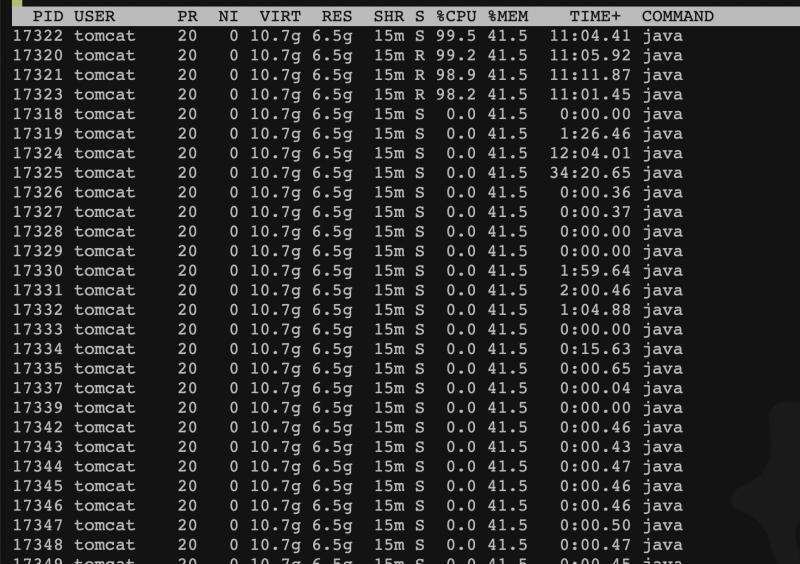
可以看到前面4條執行緒,都占用了大量的CPU資源,隨即進行了jstack,把執行緒堆疊資訊拉下來,用前面4條執行緒的ID轉換16進制后進行搜索,發現并沒有找到相應的執行緒,所以判斷為不是應用執行緒導致的,
第一個結論
通過對當時JVM的的監控情況,可以發現,這個小時的22分之前,系統 一直保持著一個比較穩定的運行狀態,堆的使用率不高,但是22分之后,年輕代大量的minor gc后,老年代在幾分鐘之內被快速的填滿,導致了FULL GC,同時FULL GC不停的發生,導致了大量的STW,CPU被FULL GC執行緒占據,出現CPU飆高,應用執行緒由于STW再加上CPU過高,大量執行緒被阻塞,同時新的請求又不停的進來,最終tomcat的執行緒池被占滿,再也無法回應新的請求了,這個雪球終于還是滾大了,
分析完了案發現場,要解決的問題變成了:
是什么原因導致老年代被快速的填滿?
拉了下當時的JVM引數
-Djava.awt.headless=true -Dfile.encoding=UTF-8 -server -Xms2048m -Xmx4096m -Xmn2048m -Xss512k -XX:MetaspaceSize=512m -XX:MaxMetaspaceSize=512m -XX:+DisableExx
plicitGC -XX:MaxTenuringThreshold=5 -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=80 -XX:+UseCMSInitiatingOccupancyOnly -XX:+UseCMSCompactAtFullCollection
-XX:+PrintGCDetails -Xloggc:/data/logs/gc.log
總共4個G的堆,年輕代單獨給了2個G,按照比率算,JVM記憶體各個區的分配情況如下:
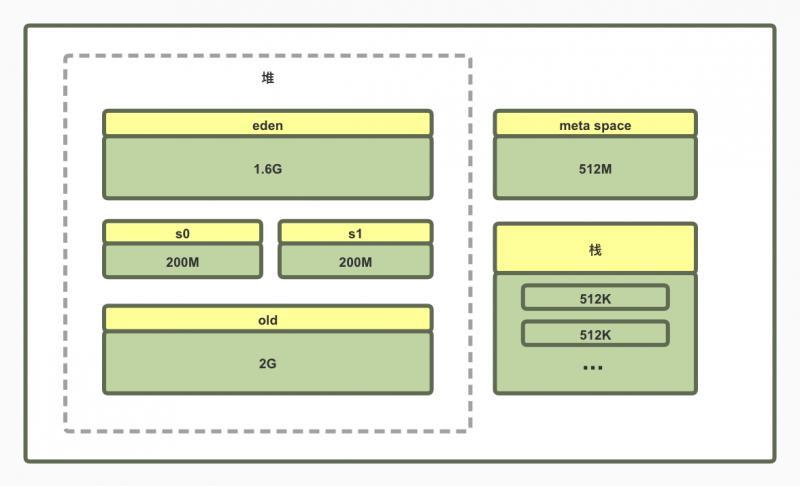
所以開始懷疑是JVM引數設定的有問題導致的老年代被快速的占滿,
但是其實這引數已經是之前優化后的結果了,eden區設定的挺大,大部分我們的方法產生的物件都是朝生夕死的物件,應該大部分都在年輕代會清理了,存活的物件才會進入survivor區,到達年齡或者觸發了進入老年代的條件后才會進入老年代,基本上老年代里的物件大部分應該是一直存活的物件,比如static修飾的物件啊,一直被參考的 快取啊,spring容器中的bean等等,
我看了下垃圾回收進入老年代的觸發條件后(關注公眾號后回復“JVM”獲取JVM記憶體分配和回識訓制的資料),發現這個場景應該是屬于大物件直接進老年代的這種,也就是說年輕代進行minor GC后,存活的物件足夠大,不足以在survivor區域放下了,就直接進入老年代了,
但是一次minor GC應該超過90%的物件都是無參考物件,只有少部分的物件才是存活的,而且這些個服務的并發一直不高,為什么一次minor GC后有那么大量的資料會存活呢,
隨即看了下當時的jmap -histo 命令產生的檔案
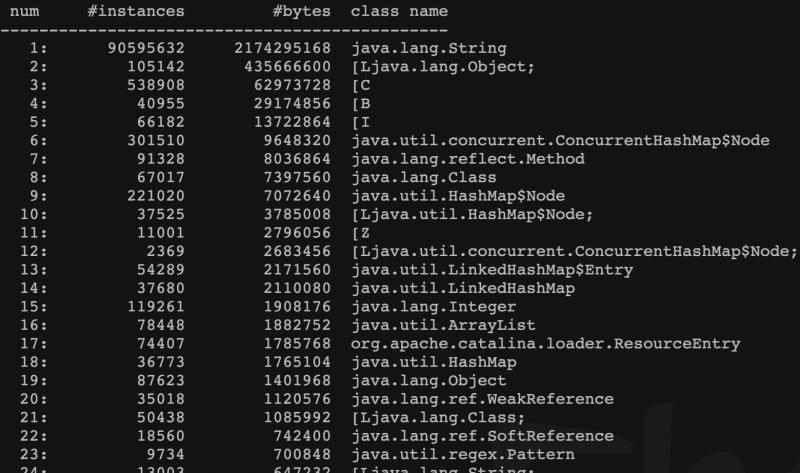
發現String這個這個物件的示例竟然有9000多w個,占用堆超過2G,這肯定有問題,但是tomcat里有8個應用 ,不可能通過分析代碼來定位到,還是要從JVM入手來反推,
第二次結論
程式并發不高,但是在幾分鐘之內,在eden區產生了大量的物件,并且這些物件無法被minor GC回收 ,由于太大,觸發了大物件直接進老年代機制,老年代會迅速填滿,導致FULL GC,和后面CPU的飆升,從而導致tomcat的宕機,
基本判斷是,JVM引數應該沒有問題,很可能問題出在應用本身不斷產生無法被回收的物件上面,但是我暫時定位不到具體的代碼位置,
排查程序二
第二天,又看了下當時的JVM監控,發現有這么一個監控資料當時漏看了
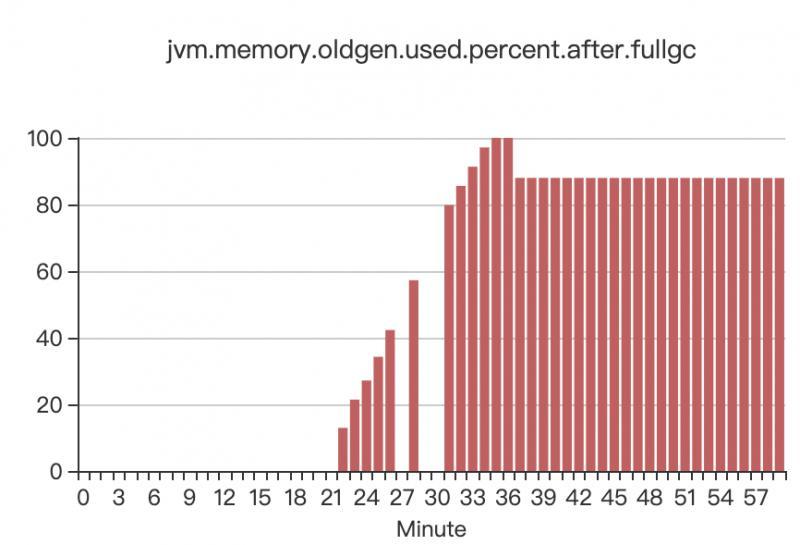
這是FULL GC之后,老年代的使用率,可以看到,FULL GC后,老年代依然占據80%多的空間,full gc就根本清理不掉老年代的物件,這說明,老年代里的這些物件都是被程式參考著的,所以清理不掉,但是平穩的時候,老年代一直維持著大概300M的堆,從這個小時的22分開始,之后就狂飆到接近2G,這肯定不正常,更加印證了我前面一個觀點,這是因為應用程式產生的無法回收的物件導致的,
但是當時我并沒有dump下來jvm的堆,所以只能等再次重現問題,
終于,在晚上9點多,這個問題又重現了,熟悉的配方,熟悉的味道,
直接jmap -dump,經過漫長的等待,產生了4.2G的一個堆快照檔案dump.hprof,經過壓縮,得到一個466M的tar.gz檔案
然后download到本地,解壓,
運行堆分析工具JProfile,裝載這個dump.hprof檔案,
然后查看堆當時的所有類占比大小的資訊
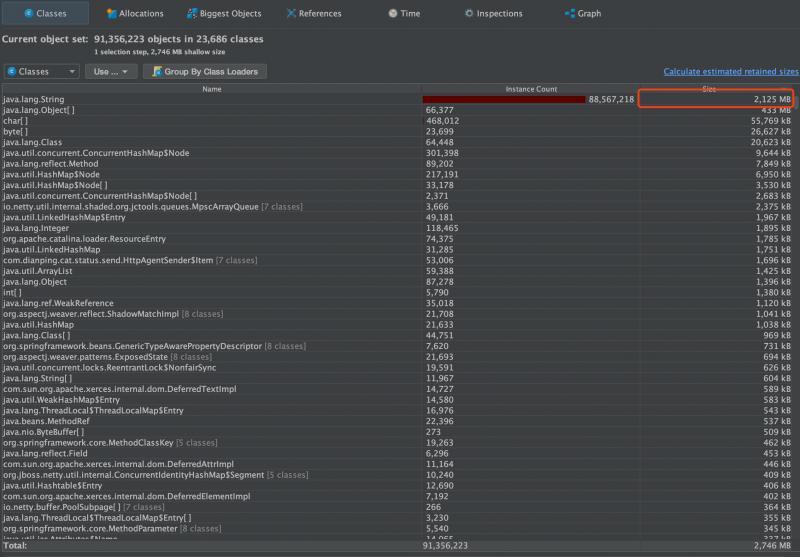
發現導致堆溢位,就是這個String物件,和之前Jmap得出的結果一樣,超過了2個G,并且無法被回收
隨即看大物件視圖,發現這些個String物件都是被java.util.ArrayList參考著的,也就是有一個ArrayList里,參考了超過2G的物件
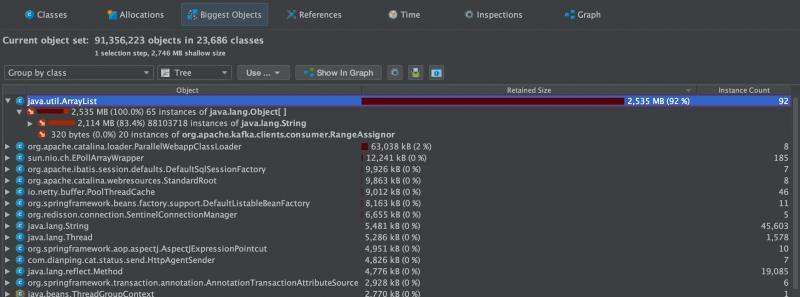
然后查看參考的關系圖,往上溯源,源頭終于顯形:
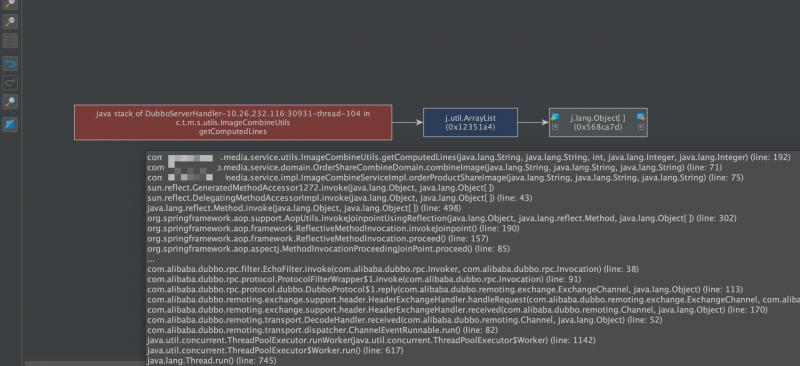
這個ArrayList是被一個執行緒堆疊參考著,而這個執行緒堆疊資訊里面,可以直接定位到相應的服務,相應的類,具體服務是Media這個微服務,
看來已經要逼近真相了!
第三次結論
本次大量頻繁的FULL GC是因為應用程式產生了大量無法被回收的資料,最終進入老年代,最終把老年代撐滿了導致的,具體的定位通過JVM的dump檔案已經分析出,指向了Media這個服務的ImageCombineUtils.getComputedLines這個方法,是什么會產生尚不知道,需要具體分析代碼,
最后
得知了具體的代碼位置, 直接進去看,經過小伙伴提醒,發現這個代碼有一個問題,
這段代碼為一個拆詞方法,具體代碼就不貼了,里面有一個回圈,每一次回圈會往一個ArrayList里加一個String物件,在回圈的某一個階段,會重置回圈計數器i,在普通的引數下并沒有問題,但是某些特定的條件下,就會不停的重置回圈計數器i,導致一個死回圈,
以下是模擬出來的結果,可以看到,才運行了一會,這個ArrayList就產生了322w個物件,且大部分Stirng物件都是空值,
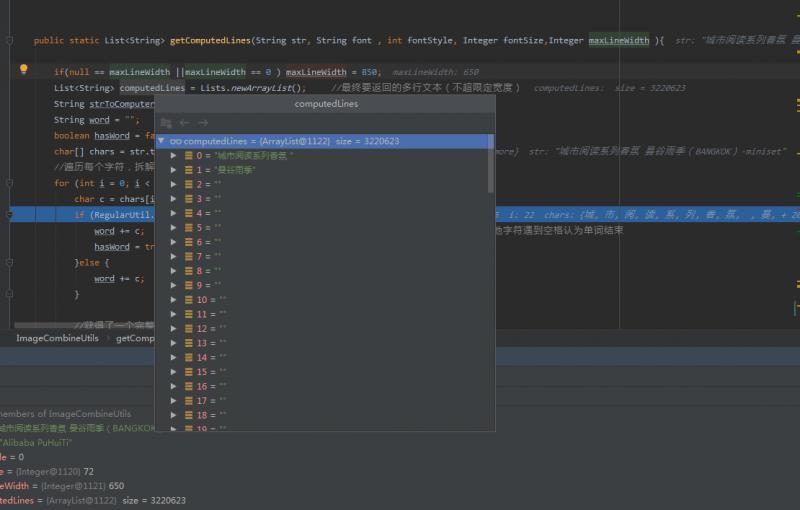
至此,水落石出,
最終結論
因為Media這個微服務的程式在某一些特殊場景下的一段程式導致了死回圈,產生了一個超大的ArrayList,導致了年輕代的快速被填滿,然后觸發了大物件直接進老年代的機制,直接往老年代里面放,老年代被放滿之后,觸發FULL GC,但是這些ArrayList被GC ROOT根參考著,無法回收,導致回收不掉,老年代依舊滿的,隨機馬上又觸發FULL GC,同時因為老年代無法被回收,導致minor GC也沒法清理,不停的進行minor GC,大量GC導致STW和CPU飆升,導致應用執行緒卡頓,阻塞,直至最后整個服務無法接受請求,
聯系作者
微信關注 「jishuyuanren」或者掃描以下二維碼獲取更多技術干貨:

關注公眾號后回復“JVM”獲取JVM記憶體分配和回識訓制的資料
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/139929.html
標籤:Java
上一篇:Linux下安裝nginx
下一篇:隨機生成簡單驗證碼