Python中re模塊主要功能是通過正則運算式是用來匹配處理字串的
第一步:import re
匯入該模塊后,就可以使用該模塊下的所有方法和屬性
1、正則基本概念
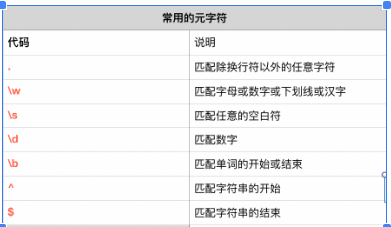
^元字符 以什么開頭
import re
str="匹配規則這個字串是否匹配"
print(re.findall("^匹配規則",str)) #字串開始位置與匹配規則符合就匹配且列印匹配內容,否則不匹配,回傳值是list
列印內容:['匹配規則']
^元字符 如果寫到[]字符集里就是反取
import re
str="匹配s規則這s個字串是否s匹配f規則則re則則則"
print(re.findall("[^a-z]",str)) #反取,匹配出除字母外的字符,回傳值是list
D:\study\python\atp\venv\Scripts\python.exe D:/study/python/atp/lib/t.py
['匹', '配', '規', '則', '這', '個', '字', '符', '串', '是', '否', '匹', '配', '規', '則', '則', '則', '則', '則']
$元字符 以什么結尾
import re
str="匹配s規則這s個字串是否s匹配f規則則re則則則"
print(re.findall("則$",str)) #字串結束位置與則符合就匹配,否則不匹配,回傳值是list
D:\study\python\atp\venv\Scripts\python.exe D:/study/python/atp/lib/t.py
['則']
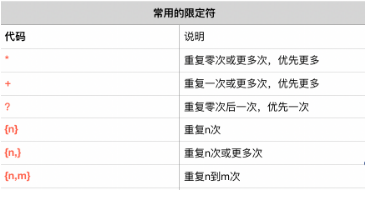
* 元字符 匹配其前面的一個字符0次或多次

import re
str="匹配s規則這s個字串是否s匹配f規則則re則則則"
print(re.findall("則*",str)) #星號前面的一個字符可以是0次或多次,回傳值是list
print(re.findall("規則*",str)) #星號前面的一個字符可以是0次或多次,回傳值是list
D:\study\python\atp\venv\Scripts\python.exe D:/study/python/atp/lib/t.py
['', '', '', '', '則', '', '', '', '', '', '', '', '', '', '', '', '', '', '則則', '', '', '則則則', '']
['規則', '規則則']
+ 元字符 匹配其前面的一個字符1次或多次
import re
str="匹配s規則這s個字串是否s匹配f規則則re則則則"
print(re.findall("則+",str)) #加號前面的一個字符可以是1次或多次,回傳值是list
print(re.findall("規則+",str)) #加號配前面的一個字符可以是1次或多次,回傳值是list
D:\study\python\atp\venv\Scripts\python.exe D:/study/python/atp/lib/t.py
['則', '則則', '則則則']
['規則', '規則則']
?元字符 匹配其前面的一個字符0次或1次
import re
str="匹配s規則這s個字串是否s匹配f規則則re則則則"
print(re.findall("則?",str)) #問號前面的一個字符可以是0次或1次,回傳值是list
print(re.findall("規則?",str)) #問號前面的一個字符可以是0次或1次,回傳值是list
D:\study\python\atp\venv\Scripts\python.exe D:/study/python/atp/lib/t.py
['', '', '', '', '則', '', '', '', '', '', '', '', '', '', '', '', '', '', '則', '則', '', '', '則', '則', '則', '']
['規則', '規則']
{}元字符,范圍
{m}匹配前一個字符m次,{m,n}匹配前一個字符m至n次,若省略n,則匹配m至無限次
{0,}匹配前一個字符0或多次,等同于*元字符
{+,}匹配前一個字符1次或無限次,等同于+元字符
{0,1}匹配前一個字符0次或1次,等同于?元字符
import re
str="匹配s規則這s個字串是否s匹配f規則則re則則則"
print(re.findall("則{2}",str)) #匹配前一個字符2次,回傳值是list
print(re.findall("規則{1,2}",str)) #匹配前一個字符1-2次,回傳值是list
D:\study\python\atp\venv\Scripts\python.exe D:/study/python/atp/lib/t.py
['則則', '則則']
['規則', '規則則']
[]元字符,字符集
需要字串里完全符合,匹配規則,就匹配,(規則里的 [] 元字符)對應位置是[]里的任意一個字符就匹配
import re
str="匹配s規則這s個字串是否s匹配f規則則re則則則"
print(re.findall("匹配[s,f]規則",str)) #匹配字符后,只有符合[]中任意字符均可,回傳值是list
D:\study\python\atp\venv\Scripts\python.exe D:/study/python/atp/lib/t.py
['匹配s規則', '匹配f規則']
\d 匹配任何十進制數,它相當于類[0-9]
import re
str="匹配s規則這s個字串4是否s匹配3f規則則re則則2則"
print(re.findall("\d",str)) #匹配字串所有的數字,回傳值是list
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7 /Users/dongyf/Documents/python/besttest_study/ryg.py
['4', '3', '2']
\d+如果需要匹配一位或者多位數的數字時用
import re
str="匹配s規則這s個字串455是否s匹配3f規則則re則則2則"
print(re.findall("\d+",str)) #匹配字串中一位或多位數字,回傳值是list
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7 /Users/dongyf/Documents/python/besttest_study/ryg.py
['455', '3', '2']
\D匹配任何非數字字符,它相當于類[^0-9]
import re
str="匹配s規則這s個字串455是否s匹配3f規則則re則則2則"
print(re.findall("\D",str)) #匹配字串中非數字,回傳值是list
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7 /Users/dongyf/Documents/python/besttest_study/ryg.py
['匹', '配', 's', '規', '則', '這', 's', '個', '字', '符', '串', '是', '否', 's', '匹', '配', 'f', '規', '則', '則', 'r', 'e', '則', '則', '則']
\s匹配任何空白字符,它相當于類[\t\n\r\f\v]
import re
str="匹配s規則這s個字 符 串 \n \t \f \v455是否s匹配3f規則則re則則2則"
print(re.findall("\s",str)) #匹配字串空白字符(\t\n\r\f\v),回傳值是list
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7 /Users/dongyf/Documents/python/besttest_study/ryg.py
[' ', ' ', ' ', '\n', ' ', '\t', ' ', '\x0c', ' ', '\x0b']
\S匹配任何非空白字符,它相當于類[^\t\n\r\f\v]
import re
str="匹配s規則這s個字 符 串 \n \t \f \v455是"
print(re.findall("\S",str)) #匹配字串非空白字符(\t\n\r\f\v),回傳值是list
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7 /Users/dongyf/Documents/python/besttest_study/ryg.py
['匹', '配', 's', '規', '則', '這', 's', '個', '字', '符', '串', '4', '5', '5', '是']
\w匹配包括下劃線在內任何字母數字漢字字符
import re
str="匹配s規則這s個_字 S符 串-455是"
print(re.findall("\w",str)) #匹配字串下劃線,漢字,字母,數字,回傳值是list
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7 /Users/dongyf/Documents/python/besttest_study/ryg.py
['匹', '配', 's', '規', '則', '這', 's', '個', '_', '字', 'S', '符', '串', '4', '5', '5', '是']
\W匹配非任何字母數字漢字字符包括下劃線在內
import re
str="匹配s規則這s個_字 S符 串-455是"
print(re.findall("\W",str)) #匹配字串非下劃線,漢字,字母,數字,回傳值是list
/Library/Frameworks/Python.framework/Versions/3.7/bin/python3.7 /Users/dongyf/Documents/python/besttest_study/ryg.py
[' ', ' ', '-']
()元字符,分組
也就是分組匹配,()里面的為一個組也可以理解成一個整體
如果()后面跟的是特殊元字符如 (adc)* 那么*控制的前導字符就是()里的整體內容,不再是前導一個字符
import re
str="a3a3ddd"
print(re.search("(a3)+",str).group()) #匹配一個或多個a3
C:\Users\zhaow\AppData\Local\Programs\Python\Python37\python.exe D:/study/python/test/uu.py
a3a3
|元字符,或
|或,或就是前后其中一個符合就匹配
import re str="a3死a3d有dd" print(re.findall(r"死|有+",str)) #匹配|前后一個字符均可 C:\Users\zhaow\AppData\Local\Programs\Python\Python37\python.exe D:/study/python/test/uu.py ['死', '有']
r原生字符
將在python里有特殊意義的字符如\b,轉換成原生字符(就是去除它在python的特殊意義),不然會給正則運算式有沖突,為了避免這種沖突可以在規則前加原始字符r
模塊方法:
match()函式(以后常用)
match,從頭匹配一個符合規則的字串,從起始位置開始匹配,匹配成功回傳一個物件,未匹配成功回傳None
match(pattern, string, flags=0)
# pattern: 正則模型
# string : 要匹配的字串
# falgs : 匹配模式
import re
str="hello egon bcd egon lge egon acd 19"
r=re.match("h\w+",str) #match,從起始位置開始匹配,匹配成功回傳一個物件,未匹配成功回傳None,非字母,漢字,數字及下劃線分割
print(r.group()) # 獲取匹配到的所有結果,不管有沒有分組將匹配到的全部拿出來
print(r.groups()) # 獲取模型中匹配到的分組結果,只拿出匹配到的字串中分組部分的結果
print(r.groupdict()) # 獲取模型中匹配到的分組結果,只拿出匹配到的字串中分組部分定義了key的組結果
hello
()
{}
r2=re.match("h(\w+)",str) #match,從起始位置開始匹配,匹配成功回傳一個物件,未匹配成功回傳None
print(r2.group())
print(r2.groups())
print(r2.groupdict())
hello
('ello',)
{}
r3=re.match("(?P<n1>h)(?P<n2>\w+)",str) #?P<>定義組里匹配內容的key(鍵),<>里面寫key名稱,值就是匹配到的內容
print(r3.group())
print(r3.groups())
print(r3.groupdict())
hello
('h', 'ello')
{'n1': 'h', 'n2': 'ello'}
search()函式
search,瀏覽全部字串,匹配第一符合規則的字串,瀏覽整個字串去匹配第一個,未匹配成功回傳None
search(pattern, string, flags=0)
# pattern: 正則模型
# string : 要匹配的字串
# falgs : 匹配模式
注意:match()函式 與 search()函式基本是一樣的功能,不一樣的就是match()匹配字串開始位置的一個符合規則的字串,search()是在字串全域匹配第一個合規則的字串
import re
str="hello egon bcd egon lge egon acd 19"
r=re.search("h\w+",str) #match,從起始位置開始匹配,匹配成功回傳一個物件,未匹配成功回傳None,非字母,漢字,數字及下劃線分割
print(r.group()) # 獲取匹配到的所有結果,不管有沒有分組將匹配到的全部拿出來
print(r.groups()) # 獲取模型中匹配到的分組結果,只拿出匹配到的字串中分組部分的結果
print(r.groupdict()) # 獲取模型中匹配到的分組結果,只拿出匹配到的字串中分組部分定義了key的組結果
hello
()
{}
r2=re.search("h(\w+)",str) #match,從起始位置開始匹配,匹配成功回傳一個物件,未匹配成功回傳None
print(r2.group())
print(r2.groups())
print(r2.groupdict())
hello
('ello',)
{}
r3=re.search("(?P<n1>h)(?P<n2>\w+)",str) #?P<>定義組里匹配內容的key(鍵),<>里面寫key名稱,值就是匹配到的內容
print(r3.group())
print(r3.groups())
print(r3.groupdict())
hello
('h', 'ello')
{'n1': 'h', 'n2': 'ello'}
findall()函式
findall(pattern, string, flags=0)
# pattern: 正則模型
# string : 要匹配的字串
# falgs : 匹配模式
瀏覽全部字串,匹配所有合規則的字串,匹配到的字串放到一個串列中,未匹配成功回傳空串列
注意:一旦匹配成,再次匹配,是從前一次匹配成功的,后面一位開始的,也可以理解為匹配成功的字串,不在參與下次匹配
import re
r=re.findall("\d+\w\d+","a2b3c4d5") #瀏覽全部字串,匹配所有合規則的字串,匹配到的字串方到一個串列中
print(r)
['2b3', '4d5'] #匹配成功的字串,不再參與下次匹配,所以3c4也符合規則但是沒有匹配到
注意:如果沒寫匹配規則,也就是空規則,回傳的是一個比原始字串多一位的,空字串串列
import re
r=re.findall("","a2b3c4d5") #瀏覽全部字串,匹配所有合規則的字串,匹配到的字串方到一個串列中
print(r)
['', '', '', '', '', '', '', '', ''] #如果沒有寫匹配規則,也就是空規則,回傳的是一個比原始字串多一位的空字串串列,如上是8個字符,回傳是9個空字符
注意:正則匹配到空字符的情況,如果規則里只有一個組,而組后面是*就表示組里的內容可以是0個或者多過,這樣組里就有了兩個意思,一個意思是匹配組里的內容,二個意思是匹配組里0內容(即是空白)所以盡量避免用*否則會有可能匹配出空字串
注意:正則只拿組里最后一位,如果規則里只有一個組,匹配到的字串里在拿組內容是,拿的是匹配到的內容最后一位
import re
r=re.findall("(ca)*","ca2b3caa4d5") #瀏覽全部字串,匹配所有合規則的字串,匹配到的字串方到一個串列中
print(r)
['ca', '', '', '', 'ca', '', '', '', '', '']#用*號會匹配出空字符
無分組:匹配所有合規則的字串,匹配到的字串放到一個串列中
import re
r=re.findall("a\w+","ca2b3 caa4d5") #瀏覽全部字串,匹配所有合規則的字串,匹配到的字串方到一個串列中
print(r)
['a2b3', 'aa4d5']#匹配所有合規則的字串,匹配到的字串放入串列
有分組:只將匹配到的字串里,組的部分放到串列里回傳,相當于groups()方法
import re
r=re.findall("a(\w+)","ca2b3 caa4d5") #有分組:只將匹配到的字串里,組的部分放到串列里回傳
print(r)
['2b3', 'a4d5']#回傳匹配到組里的內容回傳
多個分組:只將匹配到的字串里,組的部分放到一個元組中,最后將所有元組放到一個串列里返
相當于在group()結果里再將組的部分,分別,拿出來放入一個元組,最后將所有元組放入一個串列回傳
import re
r=re.findall("(a)(\w+)","ca2b3 caa4d5") #有多分組:只將匹配到的字串里,組的部分放到一個元組中,最后將所有元組放到一個串列里回傳
print(r)
[('a', '2b3'), ('a', 'a4d5')]#回傳的是多維陣列
分組中有分組:只將匹配到的字串里,組的部分放到一個元組中,先將包含有組的組,看作一個整體也就是一個組,把這個整體組放入一個元組里,然后在把組里的組放入一個元組,最后將所有組放入一個串列回傳
import re
r=re.findall("(a)(\w+(b))","ca2b3 caa4b5") #分組中有分組:只將匹配到的字串里,組的部分放到一個元組中,先將包含有組的組,看作一個整體也就是一個組,把這個整體組放入一個元組里,然后在把組里的組放入一個元組,最后將所有組放入一個串列回傳
print(r)
[('a', '2b', 'b'), ('a', 'a4b', 'b')]#回傳的是多維陣列
?:在有分組的情況下findall()函式,不只拿分組里的字串,拿所有匹配到的字串,注意?:只用于不是回傳正則物件的函式如findall()
import re
r=re.findall("a(?:\w+)","a2b3 a4b5 edd") #?:在有分組的情況下,不只拿分組里的字串,拿所有匹配到的字串,注意?:只用于不是回傳正則物件的函式如findall()
print(r)
['a2b3', 'a4b5']
split()函式
根據正則匹配分割字串,回傳分割后的一個串列
split(pattern, string, maxsplit=0, flags=0)
# pattern: 正則模型
# string : 要匹配的字串
# maxsplit:指定分割個數
# flags : 匹配模式
import re
r=re.split("a\w","sdfadfdfadsfsfafsff")
print(r)
r2=re.split("a\w","sdfadfdfadsfsfafsff",maxsplit=2)
print(r2)
C:\Users\zhaow\AppData\Local\Programs\Python\Python37\python.exe D:/study/python/atp/lib/t.py
['sdf', 'fdf', 'sfsf', 'sff']
['sdf', 'fdf', 'sfsfafsff']
sub()函式
替換匹配成功的指定位置字串
sub(pattern, repl, string, count=0, flags=0)
# pattern: 正則模型
# repl : 要替換的字串
# string : 要匹配的字串
# count : 指定匹配個數
# flags : 匹配模式
import re
r=re.sub("a\w","替換","sdfadfdfadsfsfafsff")
print(r)
C:\Users\zhaow\AppData\Local\Programs\Python\Python37\python.exe D:/study/python/atp/lib/t.py
sdf替換fdf替換sfsf替換sff
subn()函式
替換匹配成功的指定位置字串,并且回傳替換次數,可以用兩個變數分別接受
subn(pattern, repl, string, count=0, flags=0)
# pattern: 正則模型
# repl : 要替換的字串
# string : 要匹配的字串
# count : 指定匹配個數
# flags : 匹配模式
import re
a,b=re.subn("a\w","替換","sdfadfdfadsfsfafsff") #替換匹配成功的指定位置字串,并且回傳替換次數,可以用兩個變數分別接受
print(a) #回傳替換后的字串
print(b) #回傳替換次數
C:\Users\zhaow\AppData\Local\Programs\Python\Python37\python.exe D:/study/python/atp/lib/t.py
sdf替換fdf替換sfsf替換sff
3
備注:參考網站 https://www.cnblogs.com/zjltt/p/6955965.html https://www.cnblogs.com/xiaokuangnvhai/p/11213308.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/141663.html
標籤:Python
上一篇:Flask中資料庫的多對多關系
下一篇:自己設計大學排名-資料庫實踐