【一、專案背景】
豆瓣電影提供最新的電影介紹及評論包括上映影片的影訊查詢及購票服務,可以記錄想看、在看和看過的電影電視劇 、順便打分、寫影評,極大地方便了人們的生活,
今天以電視劇(美劇)為例,批量爬取對應的電影,寫入csv檔案 ,用戶可以通過評分,更好的選擇自己想要的電影,
【二、專案目標】
獲取對應的電影名稱,評分,詳情鏈接,下載 電影的圖片,保存檔案,
【三、涉及的庫和網站】
1、網址如下:
https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start={}
2、涉及的庫:requests****、fake_useragent、json****、csv
3、軟體:PyCharm
【四、專案分析】
1、如何多網頁請求?
點擊下一頁時,每增加一頁paged自增加20,用{}代替變換的變數,再用for回圈遍歷這網址,實作多個網址請求,
2、如何獲取真正請求的地址?
請求資料時,發現頁面上并沒有對應資料,其實豆瓣網采用javascript動態加載內容,防止采集,
1)F12右鍵檢查,找到Network,左邊選單Name , 找到第五個資料,點擊Preview,
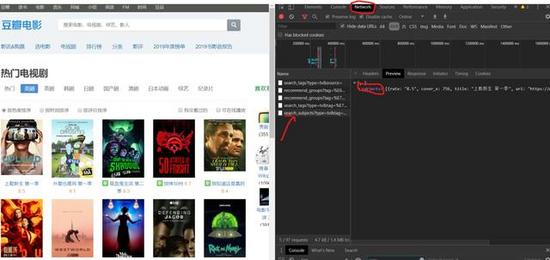
![]() ?
?
2)點開subjects,可以看到 title 就是對應電影名稱,rate就是對應評分,通過js決議subjects字典,找到需要的欄位,
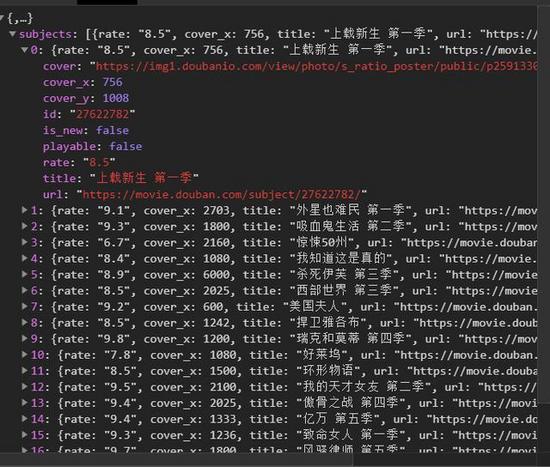
![]() ?
?
- 如何網頁訪問?
https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=0 https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=20 https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=40 https://movie.douban.com/j/search_subjects?type=tv&tag=%E7%BE%8E%E5%89%A7&sort=recommend&page_limit=20&page_start=60
當點擊下一頁時,每增加一頁page自增加20,用{}代替變換的變數,再用for回圈遍歷這網址,實作多個網址請求,
【五、專案實施】
1、我們定義一個class類繼承object,然后定義init方法繼承self,再定義一個主函式main繼承self,匯入需要的庫和請求網址,

![]() ?
?
2、隨機產生UserAgent,構造請求頭,防止反爬,
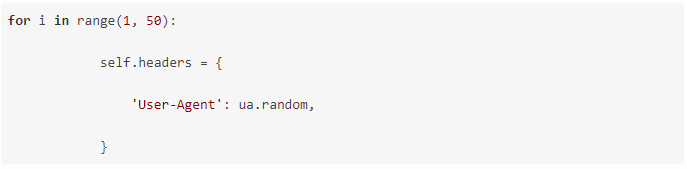
![]() ?
?
3、發送請求 ,獲取回應,頁面回呼,方便下次請求,

![]() ?
?
4、json決議頁面資料,獲取對應的字典,

![]() ?
?
5、for遍歷,獲取對應的電影名、 評分、下詳情頁鏈接,

![]() ?
?
6、創建csv檔案進行寫入,定義對應的標題頭內容,保存資料 ,

![]() ?
?
7、圖片地址進行請求,定義圖片名稱,保存檔案,

![]() ?
?
8、呼叫方法,實作功能,

![]() ?
?
9、專案優化:
1)設定時間延時,
![]()
![]() ?
?
2)定義一個變數u, for遍歷,表示爬取的是第幾頁,(更清晰可觀),

![]() ?
?
【六、效果展示】
1、點擊綠色小三角運行輸入起始頁,終止頁( 從0頁開始 ),

![]() ?
?
2、將下載成功資訊顯示在控制臺,
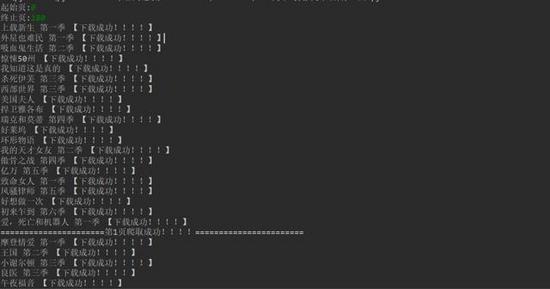
![]() ?
?
3、保存csv檔案,

![]() ?
?
4、電影圖片展示,
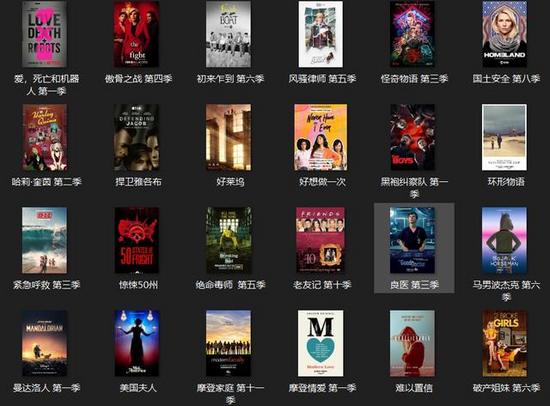
![]() ?
?
【七、總結】
1、不建議抓取太多資料,容易對服務器造成負載,淺嘗輒止即可,
2、本文章就Python爬取豆瓣網,在應用中出現的難點和重點,以及如何防止反爬,做出了相對于的解決方案,
3、希望通過這個專案,能夠幫助了解json決議頁面的基本流程,字串是如何拼接,format函式如何運用,
4、本文基于Python網路爬蟲,利用爬蟲庫,實作豆瓣電影及其圖片的獲取,實作的時候,總會有各種各樣的問題,切勿眼高手低,勤動手,才可以理解的更加深刻,
此文轉載文,著作權歸作者所有,如有侵權聯系小編洗掉!
原文地址:https://www.tuicool.com/articles/muiIZj2
需要源代碼或者想了解更多(點擊這里查看)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/142641.html
標籤:其他