一、基礎入門
1.1什么是爬蟲
爬蟲(spider,又網路爬蟲),是指向網站/網路發起請求,獲取資源后分析并提取有用資料的程式,
從技術層面來說就是 通程序式模擬瀏覽器請求站點的行為,把站點回傳的HTML代碼/JSON資料/二進制資料(圖片、視頻) 爬到本地,進而提取自己需要的資料,存放起來使用,
1.2爬蟲基本流程
用戶獲取網路資料的方式:
方式1:瀏覽器提交請求--->下載網頁代碼--->決議成頁面
方式2:模擬瀏覽器發送請求(獲取網頁代碼)->提取有用的資料->存放于資料庫或檔案中
爬蟲要做的就是方式2,
入門python爬蟲,10分鐘就夠了,這可能是我見過最簡單的基礎教學

![]() ?
?
1發起請求
使用http庫向目標站點發起請求,即發送一個Request
Request包含:請求頭、請求體等
Request模塊缺陷:不能執行JS 和CSS 代碼
2獲取回應內容
如果服務器能正常回應,則會得到一個Response
Response包含:html,json,圖片,視頻等
3決議內容
決議html資料:正則運算式(RE模塊)、xpath(主要使用)、beautiful soup、css
決議json資料:json模塊
決議二進制資料:以wb的方式寫入檔案
4保存資料
資料庫(MySQL,Mongdb、Redis)或 檔案的形式,
1.3http協議 請求與回應
http協議

![]() ?
?
Request:用戶將自己的資訊通過瀏覽器(socket client)發送給服務器(socket server)
Response:服務器接收請求,分析用戶發來的請求資訊,然后回傳資料(回傳的資料中可能包含其他鏈接,如:圖片,js,css等)
ps:瀏覽器在接收Response后,會決議其內容來顯示給用戶,而爬蟲程式在模擬瀏覽器發送請求然后接收Response后,是要提取其中的有用資料,
1.3.1
request
(1) 請求方式
常見的請求方式:GET / POST
(2)請求的URL
url全球統一資源定位符,用來定義互聯網上一個唯一的資源 例如:一張圖片、一個檔案、一段視頻都可以用url唯一確定
(3)請求頭
User-agent:請求頭中如果沒有user-agent客戶端配置,服務端可能將你當做一個非法用戶host;
cookies:cookie用來保存登錄資訊
注意:一般做爬蟲都會加上請求頭,
請求頭需要注意的引數:
Referrer:訪問源至哪里來(一些大型網站,會通過Referrer 做防盜鏈策略;所有爬蟲也要注意模擬)
User-Agent:訪問的瀏覽器(要加上否則會被當成爬蟲程式)
cookie:請求頭注意攜帶
(4)請求體
請求體 如果是get方式,請求體沒有內容 (get請求的請求體放在 url后面引數中,直接能看到) 如果是post方式,請求體是format data
ps:1、登錄視窗,檔案上傳等,資訊都會被附加到請求體內 2、登錄,輸入錯誤的用戶名密碼,然后提交,就可以看到post,正確登錄后頁面通常會跳轉,無法捕捉到post
1.3.2
response
(1)回應狀態碼
200:代表成功
301:代表跳轉
404:檔案不存在
403:無權限訪問
502:服務器錯誤
(2)response header
回應頭需要注意的引數:Set-Cookie:BDSVRTM=0; path=/:可能有多個,是來告訴瀏覽器,把cookie保存下來
(3)preview就是網頁源代碼
json資料
如網頁html,圖片
二進制資料等
02
二、基礎模塊
2.1requests
requests是python實作的簡單易用的HTTP庫,是由urllib的升級而來,
開源地址:
https://github.com/kennethrei...
中文API:
http://docs.python-requests.o...
2.2re 正則運算式
在 Python 中使用內置的 re 模塊來使用正則運算式,
缺點:處理資料不穩定、作業量大
2.3XPath
Xpath(XML Path Language) 是一門在 XML 檔案中查找資訊的語言,可用來在 XML 檔案中對元素和屬性進行遍歷,
在python中主要使用 lxml 庫來進行xpath獲取(在框架中不使用lxml,框架內直接使用xpath即可)
lxml 是 一個HTML/XML的決議器,主要的功能是如何決議和提取 HTML/XML 資料,
lxml和正則一樣,也是用 C 實作的,是一款高性能的 Python HTML/XML 決議器,我們可以利用之前學習的XPath語法,來快速的定位特定元素以及節點資訊,
2.4BeautifulSoup
和 lxml 一樣,Beautiful Soup 也是一個HTML/XML的決議器,主要的功能也是如何決議和提取 HTML/XML 資料,
使用BeautifulSoup需要匯入bs4庫
缺點:相對正則和xpath處理速度慢
優點:使用簡單
2.5Json
JSON(JavaScript Object Notation) 是一種輕量級的資料交換格式,它使得人們很容易的進行閱讀和撰寫,同時也方便了機器進行決議和生成,適用于進行資料互動的場景,比如網站前臺與后臺之間的資料互動,
在python中主要使用 json 模塊來處理 json資料,Json決議網站:
https://www.sojson.com/simple...
2.6threading
使用threading模塊創建執行緒,直接從threading.Thread繼承,然后重寫__init__方法和run方法
03
三、方法實體
3.1get方法實體
demo_get.py
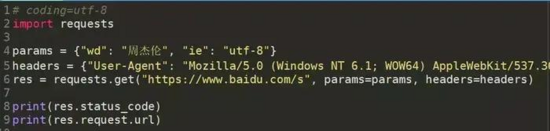
![]() ?
?
3.2post方法實體
demo_post.py
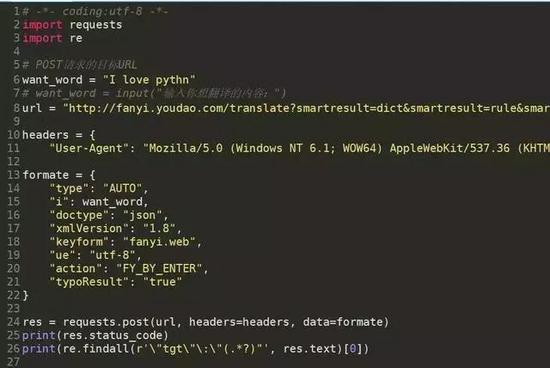
![]() ?
?
3.3添加代理
demo_proxies.py
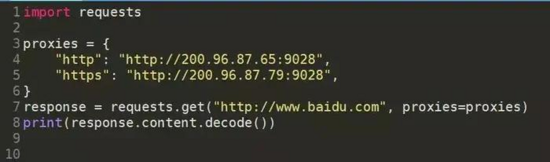
![]() ?
?
3.4獲取ajax類資料實體
demo_ajax.py
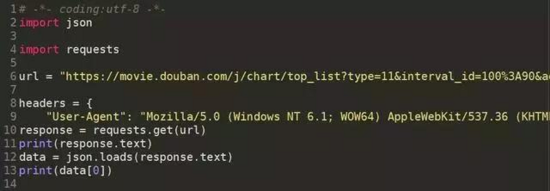
![]() ?
?
3.5使用多執行緒實體
demo_thread.py
04
四、爬蟲框架
4.1Srcapy框架
Scrapy是用純Python實作一個為了爬取網站資料、提取結構性資料而撰寫的應用框架,用途非常廣泛,
Scrapy 使用了 Twisted'tw?st?d異步網路框架來處理網路通訊,可以加快我們的下載速度,不用自己去實作異步框架,并且包含了各種中間件介面,可以靈活的完成各種需求,
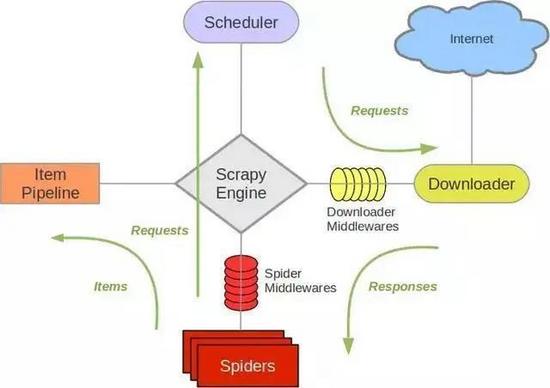
4.2Scrapy架構圖
![]() ?
?
4.3Scrapy主要組件
Scrapy Engine(引擎): 負責Spider、ItemPipeline、Downloader、Scheduler中間的通訊,信號、資料傳遞等,
Scheduler(調度器): 它負責接受引擎發送過來的Request請求,并按照一定的方式進行整理排列,入隊,當引擎需要時,交還給引擎,
Downloader(下載器):負責下載Scrapy Engine(引擎)發送的所有Requests請求,并將其獲取到的Responses交還給Scrapy Engine(引擎),由引擎交給Spider來處理,
Spider(爬蟲):它負責處理所有Responses,從中分析提取資料,獲取Item欄位需要的資料,并將需要跟進的URL提交給引擎,再次進入Scheduler(調度器),
Item Pipeline(管道):它負責處理Spider中獲取到的Item,并進行進行后期處理(詳細分析、過濾、存盤等)的地方.
Downloader Middlewares(下載中間件):你可以當作是一個可以自定義擴展下載功能的組件,
Spider Middlewares(Spider中間件):你可以理解為是一個可以自定擴展和操作引擎和Spider中間通信的功能組件(比如進入Spider的Responses;和從Spider出去的Requests)
4.4Scrapy的運作流程
引擎:Hi!Spider, 你要處理哪一個網站?
Spider:老大要我處理xxxx.com,
引擎:你把第一個需要處理的URL給我吧,
Spider:給你,第一個URL是xxxxxxx.com,
引擎:Hi!調度器,我這有request請求你幫我排序入隊一下,
調度器:好的,正在處理你等一下,
引擎:Hi!調度器,把你處理好的request請求給我,
調度器:給你,這是我處理好的request
引擎:Hi!下載器,你按照老大的下載中間件的設定幫我下載一下這個request請求
下載器:好的!給你,這是下載好的東西,(如果失敗:sorry,這個request下載失敗了,然后引擎告訴調度器,這個request下載失敗了,你記錄一下,我們待會兒再下載)
引擎:Hi!Spider,這是下載好的東西,并且已經按照老大的下載中間件處理過了,你自己處理一下(注意!這兒responses默認是交給def parse()這個函式處理的)
Spider:(處理完畢資料之后對于需要跟進的URL),Hi!引擎,我這里有兩個結果,這個是我需要跟進的URL,還有這個是我獲取到的Item資料,
引擎:Hi !管道 我這兒有個item你幫我處理一下!調度器!這是需要跟進URL你幫我處理下,然后從第四步開始回圈,直到獲取完老大需要全部資訊,
管道``調度器:好的,現在就做!
4.5制作Scrapy爬蟲4步曲
1新建爬蟲專案scrapy startproject mySpider2明確目標 (撰寫items.py)打開mySpider目錄下的items.py3制作爬蟲 (spiders/xxspider.py)scrapy genspider gushi365 "gushi365.com"4存盤內容 (pipelines.py)設計管道存盤爬取內容
05
五、常用工具
5.1fidder
fidder是一款抓包工具,主要用于手機抓包,
5.2XPath Helper
xpath helper插件是一款免費的chrome爬蟲網頁決議工具,可以幫助用戶解決在獲取xpath路徑時無法正常定位等問題,
谷歌瀏覽器插件xpath helper 的安裝和使用:
https://jingyan.baidu.com/art...
06
六、分布式爬蟲
6.1scrapy-redis
Scrapy-redis是為了更方便地實作Scrapy分布式爬取,而提供了一些以redis為基礎的組件(pip install scrapy-redis)
6.2分布式策略
Master端(核心服務器) :搭建一個Redis資料庫,不負責爬取,只負責url指紋判重、Request的分配,以及資料的存盤,
此文轉載文,著作權歸作者所有,如有侵權聯系小編洗掉!
原文地址:https://www.tuicool.com/articles/7v6fEf6
需要源代碼或者想了解更多的(點擊這里下載)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/143228.html
標籤:Python
上一篇:6-python 流程控制
下一篇:Python裝飾器