這篇文章本意上是想總結Java集合中的知識點,奈何東西太多,同時網上關于集合的有不少出色的文章,所以,本人是根據網上內容進行的整理,畢竟附上了文章的網址,如果有侵權,請聯系我洗掉
再次,感謝以下博主的分析
本文主要的閱讀方向是:
1.了解Java集合的主要框架
2.了解集合中每個分支的含義和特點
3.List和Map的常用方法
4.HashMap的底層原理(面試經常會問到)
后面有更加深入的理解之后會更新,,,,,,,,,,
http://www.cnblogs.com/paddix/
從文章中轉載了部分內容
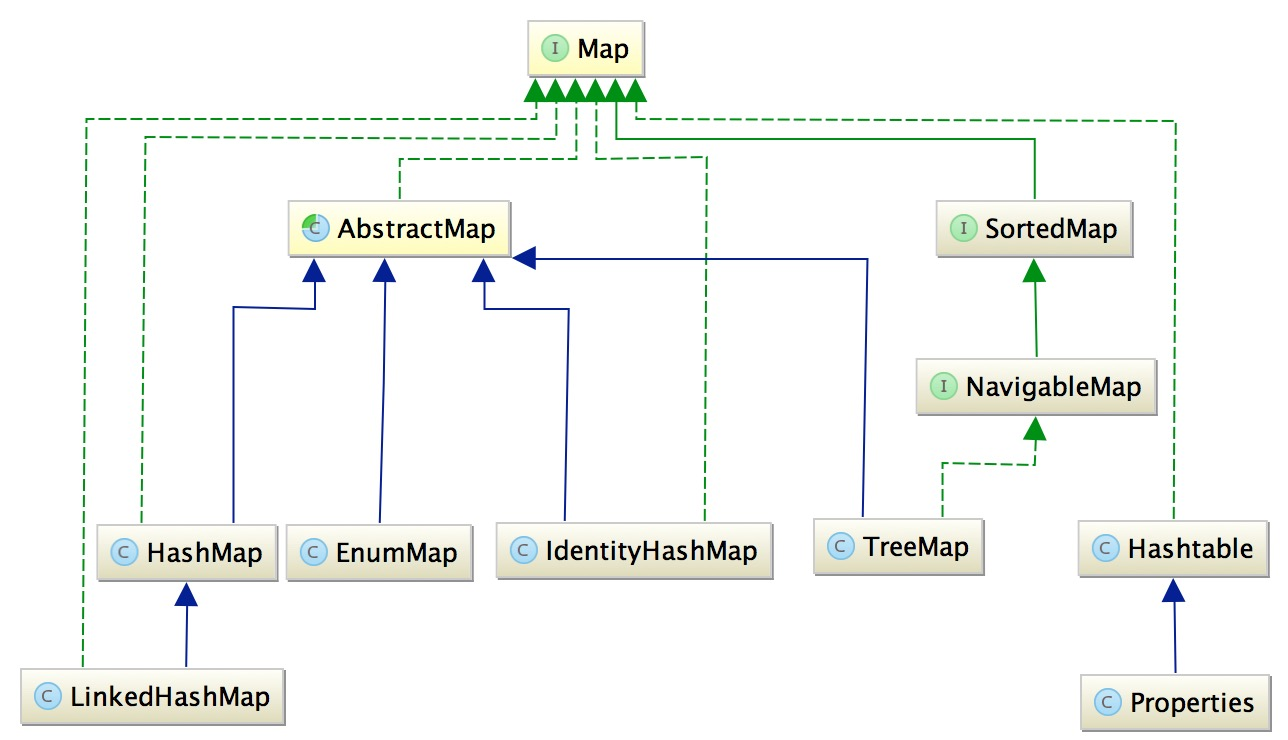
圖中的綠色的虛線代表實作,綠色實線代表介面之間的繼承,藍色實線代表類之間的繼承,
首先擺出兩張照片,Java集合中主要是 Collection 介面 和 Map 介面兩種
Iterator所有的集合類,都實作了Iterator介面
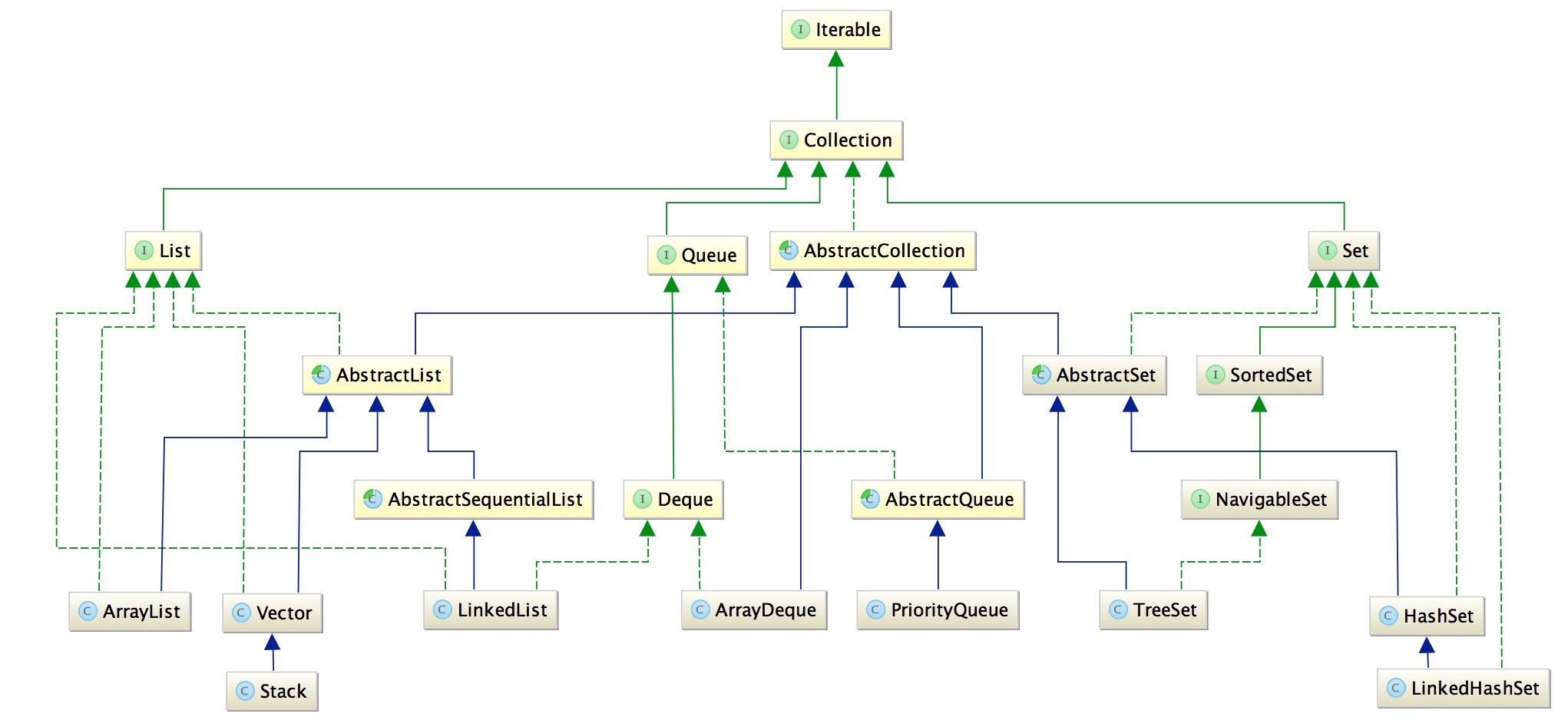
Collection 是一個介面,包含了 List和Set兩大分支
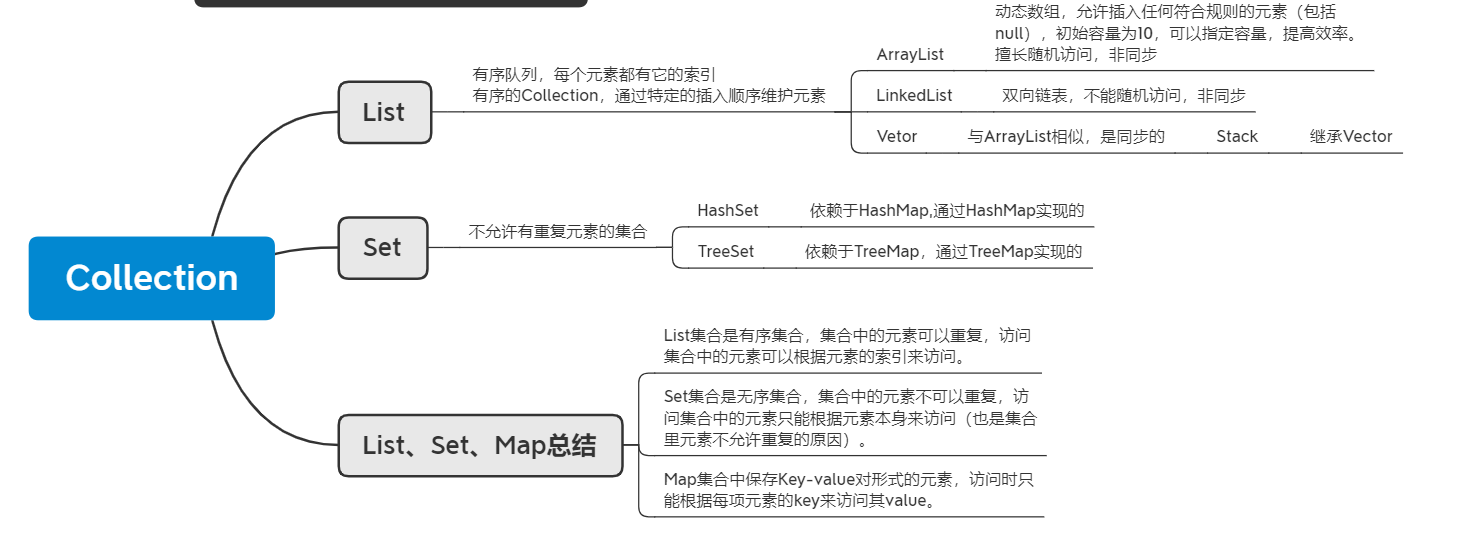
List:存放的物件是有序的,同時也是可以重復的,List關注的是索引,擁有一系列和索引相關的方法,查詢速度快,因為往list集合里插入或洗掉資料時,會伴隨著后面資料的移動,所有插入洗掉資料速度慢,
Set:存放的物件是無序,不能重復的,集合中的物件不按特定的方式排序,只是簡單地把物件加入集合中
List分支
ArrayList::基于陣列的,在初始化ArrayList時,會構建空陣列(Object[] elementData=https://www.cnblogs.com/zhu-qi/p/{}),ArrayList是一個無序的,它是按照添加的先后順序排列,當然,他也提供了sort方法,如果需要對ArrayList進行排序,只需要呼叫這個方法,提供Comparator比較器即可
LinkedList:基于鏈表的,它是一個雙向鏈表,每個節點維護了一個prev和next指標,同時對于這個鏈表,維護了first和last指標,first指向第一個元素,last指向最后一個元素,LinkedList是一個無序的鏈表,按照插入的先后順序排序,不提供sort方法對內部元素排序,
Vector:非常類似ArrayList,但是Vector是同步的
Set分支
HashSet:基于HashMap來實作的,操作很簡單,更像是對HashMap做了一次“封裝”,而且只使用了HashMap的key來實作各種特性,而HashMap的value始終都是PRESENT
TreeSet:基于 TreeMap 的 NavigableSet 實作,使用元素的自然順序對元素進行排序,或者根據創建 set 時提供的 Comparator進行排序,具體取決于使用的構造方法
Map:存盤的是鍵值對,鍵不能重復,值可以重復,根據鍵得到值,對map集合遍歷時先得到鍵的set集合,對set集合進行遍歷,得到相應的值
HashMap:以哈希表資料結構實作,查找物件時通過哈希函式計算其位置,它是為快速查詢而設計的,其內部定義了一個hash表陣列(Entry[] table),元素會通過哈希轉換函式將元素的哈希地址轉換成陣列中存放的索引,如果有沖突,則使用散列鏈表的形式將所有相同哈希地址的元素串起來,可能通過查看HashMap.Entry的原始碼它是一個單鏈表結構,
LinkedHashMap:是HashMap的一個子類,它保留插入的順序,如果需要輸出的順序和輸入時的相同,那么就選用LinkedHashMap,LinkedHashMap是Map介面的哈希表和鏈接串列實作,具有可預知的迭代順序,此實作提供所有可選的映射操作,并允許使用null值和null鍵,此類不保證映射的順序,特別是它不保證該順序恒久不變,
TreeMap :一個有序的key-value集合,非同步,基于紅黑樹(Red-Black tree)實作,每一個key-value節點作為紅黑樹的一個節點,TreeMap存盤時會進行排序的,會根據key來對key-value鍵值對進行排序,其中排序方式也是分為兩種,一種是自然排序,一種是定制排序,具體取決于使用的構造方法,
簡單整理一下集合中的各種方法
List常用方法
1、void add(int index, E element)
在指定位置插入元素,后面的元素都往后移一個元素,
2、boolean addAll(int index, Collection<? extends E> c)
在指定的位置中插入c集合全部的元素,如果集合發生改變,則回傳true,否則回傳false
3、E get(int index)
回傳list集合中指定索引位置的元素
4、int indexOf(Object o)
回傳list集合中第一次出現o物件的索引位置,如果list集合中沒有o物件,那么就回傳-1
5、E remove(int index)
洗掉指定索引的物件
6、E set(int index, E element)
在索引為index位置的元素更改為element元素
7、List<E> subList(int fromIndex, int toIndex)
回傳從索引fromIndex到toIndex的元素集合,包左不包右
Map常用方法
1、V put(K key, V value)
向map集合中添加Key為key,Value為value的元素,當添加成功時回傳null,否則回傳value
2、void putAll(Map<? extends K,? extends V> m)
向map集合中添加指定集合的所有元素
3、void clear()
把map集合中所有的鍵值洗掉
4、boolean containsKey(Object key)
檢出map集合中有沒有包含Key為key的元素,如果有則回傳true,否則回傳false
5、boolean containsValue(Object value)
檢出map集合中有沒有包含Value為value的元素,如果有則回傳true,否則回傳false,
6、Set<Map.Entry<K,V>> entrySet()
回傳map到一個Set集合中,以map集合中的Key=Value的形式回傳到set中
7、boolean equals(Object o)
判斷兩個Set集合的元素是否相同
8、Collection<V> values()
回傳map集合中所有的Value到一個Collection集合
在網上摘抄的總結這個異同點
附上網址
https://www.cnblogs.com/xiaoxi/p/6089984.html
1.ArrayList和LinkedList
(1)ArrayList是實作了基于動態陣列的資料結構,LinkedList基于鏈表的資料結構,
(2)對于隨機訪問get和set,ArrayList絕對優于LinkedList,因為LinkedList要移動指標,
(3)對于新增和洗掉操作add和remove,LinedList比較占優勢,因為ArrayList要移動資料,
這一點要看實際情況的,若只對單條資料插入或洗掉,ArrayList的速度反而優于LinkedList,但若是批量隨機的插入洗掉資料,LinkedList的速度大大優于ArrayList. 因為ArrayList每插入一條資料,要移動插入點及之后的所有資料,
2.HashTable與HashMap
相同點:
(1)都實作了Map、Cloneable、java.io.Serializable介面,
(2)都是存盤"鍵值對(key-value)"的散串列,而且都是采用拉鏈法實作的,
不同點:
(1)歷史原因:HashTable是基于陳舊的Dictionary類的,HashMap是Java 1.2引進的Map介面的一個實作 ,
(2)同步性:HashTable是執行緒安全的,也就是說是同步的,而HashMap是執行緒式不安全的,不是同步的 ,
(3)對null值的處理:HashMap的key、value都可為null,HashTable的key、value都不可為null ,
(4)基類不同:HashMap繼承于AbstractMap,而Hashtable繼承于Dictionary,
Dictionary是一個抽象類,它直接繼承于Object類,沒有實作任何介面,Dictionary類是JDK 1.0的引入的,雖然Dictionary也支持“添加key-value鍵值對”、“獲取value”、“獲取大小”等基本操作,但它的API函式比Map少;而且Dictionary一般是通過Enumeration(列舉類)去遍歷,Map則是通過Iterator(迭代M器)去遍歷, 然而由于Hashtable也實作了Map介面,所以,它即支持Enumeration遍歷,也支持Iterator遍歷,
AbstractMap是一個抽象類,它實作了Map介面的絕大部分API函式;為Map的具體實作類提供了極大的便利,它是JDK 1.2新增的類,
(5)支持的遍歷種類不同:HashMap只支持Iterator(迭代器)遍歷,而Hashtable支持Iterator(迭代器)和Enumeration(列舉器)兩種方式遍歷,
3.HashMap、Hashtable、LinkedHashMap和TreeMap比較
Hashmap 是一個最常用的Map,它根據鍵的HashCode 值存盤資料,根據鍵可以直接獲取它的值,具有很快的訪問速度,遍歷時,取得資料的順序是完全隨機的,HashMap最多只允許一條記錄的鍵為Null;允許多條記錄的值為Null;HashMap不支持執行緒的同步,即任一時刻可以有多個執行緒同時寫HashMap;可能會導致資料的不一致,如果需要同步,可以用Collections的synchronizedMap方法使HashMap具有同步的能力,
Hashtable 與 HashMap類似,不同的是:它不允許記錄的鍵或者值為空;它支持執行緒的同步,即任一時刻只有一個執行緒能寫Hashtable,因此也導致了Hashtale在寫入時會比較慢,
LinkedHashMap保存了記錄的插入順序,在用Iterator遍歷LinkedHashMap時,先得到的記錄肯定是先插入的,也可以在構造時用帶引數,按照應用次數排序,在遍歷的時候會比HashMap慢,不過有種情況例外,當HashMap容量很大,實際資料較少時,遍歷起來可能會比LinkedHashMap慢,因為LinkedHashMap的遍歷速度只和實際資料有關,和容量無關,而HashMap的遍歷速度和他的容量有關,如果需要輸出的順序和輸入的相同,那么用LinkedHashMap可以實作,它還可以按讀取順序來排列,像連接池中可以應用,LinkedHashMap實作與HashMap的不同之處在于,后者維護著一個運行于所有條目的雙重鏈表,此鏈接串列定義了迭代順序,該迭代順序可以是插入順序或者是訪問順序,對于LinkedHashMap而言,它繼承與HashMap、底層使用哈希表與雙向鏈表來保存所有元素,其基本操作與父類HashMap相似,它通過重寫父類相關的方法,來實作自己的鏈接串列特性,
TreeMap實作SortMap介面,內部實作是紅黑樹,能夠把它保存的記錄根據鍵排序,默認是按鍵值的升序排序,也可以指定排序的比較器,當用Iterator 遍歷TreeMap時,得到的記錄是排過序的,TreeMap不允許key的值為null,非同步的,
一般情況下,我們用的最多的是HashMap,HashMap里面存入的鍵值對在取出的時候是隨機的,它根據鍵的HashCode值存盤資料,根據鍵可以直接獲取它的值,具有很快的訪問速度,在Map 中插入、洗掉和定位元素,HashMap 是最好的選擇,
TreeMap取出來的是排序后的鍵值對,但如果您要按自然順序或自定義順序遍歷鍵,那么TreeMap會更好,
LinkedHashMap 是HashMap的一個子類,如果需要輸出的順序和輸入的相同,那么用LinkedHashMap可以實作,它還可以按讀取順序來排列,像連接池中可以應用,
HashMap和Hashtable的底層原理總結:
1.兩者都是依托于Hash表,所以原理具有相似性
2.Hash表是用資料和鏈表,并且加入了hash演算法的特性組合而成的
3.利用key的hashCode重新hash計算出當前物件的元素在陣列中的下標,不同的key會被轉化成不同的索引,但是那是理想的狀態,往往會出現不同的key經過計算之后被轉化成相同的索引,這就是沖突
4.處理沖突是采用的是拉鏈法和線性探索法
hash表:
陣列與鏈表,陣列的特點就是查找容易,插入洗掉困難;而鏈表的特點就是查找困難,但是插入洗掉容易,既然兩者各有優缺點,那么我們就將兩者的有點結合起來,讓它查找容易,插入洗掉也會快起來,哈希表就是講兩者結合起來的產物,
Hash演算法:
1.概念:散列方法的主要思想是根據結點的關鍵碼值來確定其存盤地址:以關鍵碼值K為自變數,通過一定的函式關系h(K)(稱為散列函式),計算出對應的函式值來,把這個值解釋為結點的存盤地址,將結點存入到此存盤單元中,檢索時,用同樣的方法計算地址,然后到相應的單元里去取要找的結點,通過散列方法可以對結點進行快速檢索,散列(hash,也稱“哈希”)是一種重要的存盤方式,也是一種常見的檢索方法,
2.散列的核心就是:由散列函式決定關鍵碼值(X.key)與散列地址h(X.key)之間的對應關系,通過這種關系來實作組織存盤并進行檢索,
3.用處:檔案校驗、數字簽名、鑒權協議
鏈表:
鏈表是一種物理存盤單元上非連續、非順序的存盤結構,資料元素的邏輯順序是通過鏈表中的指標連接次序實作的,
每一個鏈表都包含多個節點,節點又包含兩個部分,一個是資料域(儲存節點含有的資訊),一個是參考域(儲存下一個節點或者上一個節點的地址),
特點:
獲取資料麻煩,需要遍歷查找,比陣列慢
方便插入、洗掉
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/143898.html
標籤:Java
下一篇:一個老程式員在互聯網寒冬下的感悟