scrapy組件
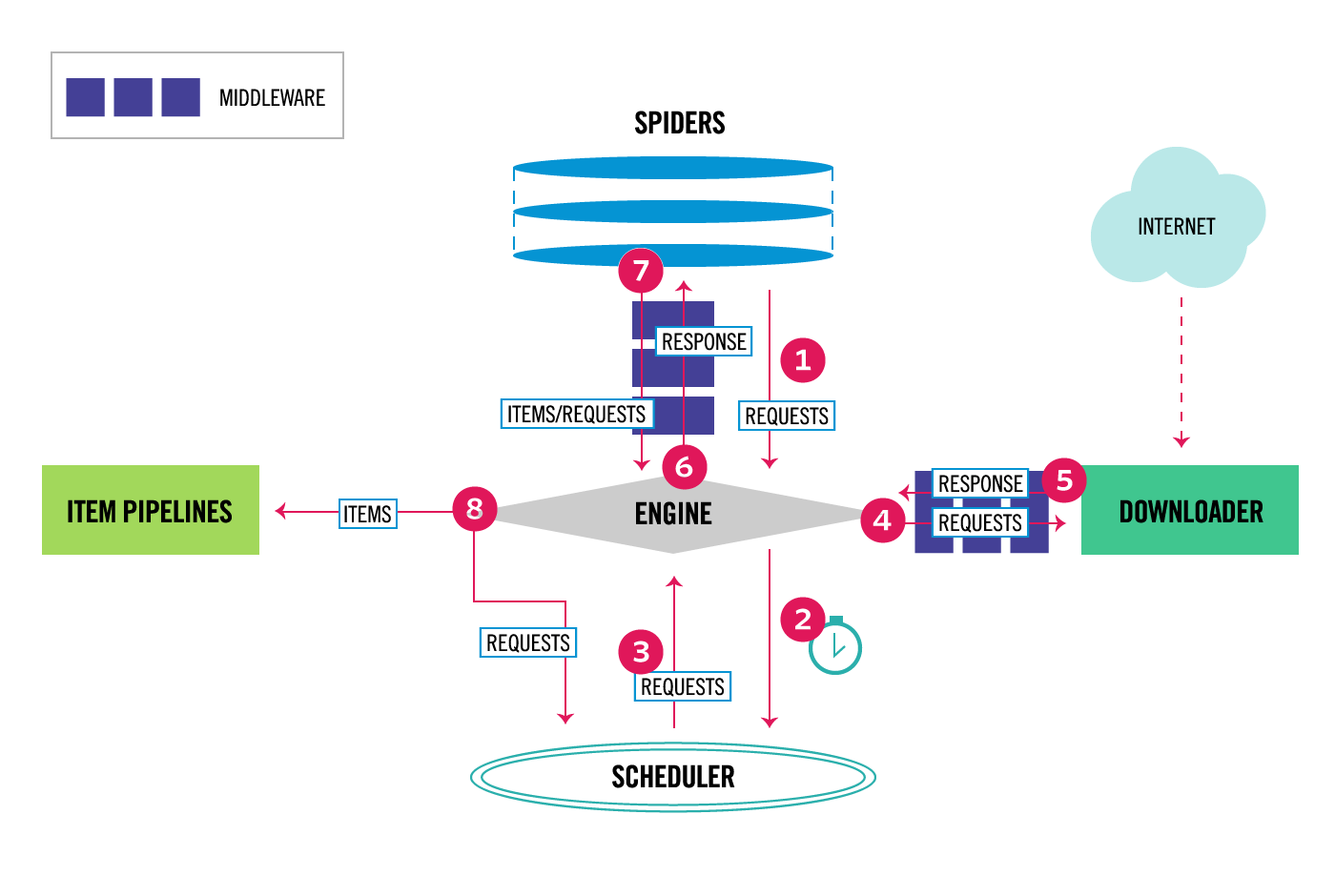
首先我們看下scrapy官網提供的新結構圖,乍一看這畫的是啥啊,這需要你慢慢的理解其原理就很容易看懂了,這些都是一個通用爬蟲框架該具有的一些基本組件,上一篇博客說了專案管道(也就是圖中的ITEM PIPELINES),可以看到中間的引擎(ENGINE)將item傳遞給了專案管道,也就是讓專案管道來處理抓取到的內容,另外圖中的所謂的組件只是抽象出來的東西比較容易讓人理解,其實這些都是python的類實體化的東西,
下載中間件處于引擎和下載器的中間,就像是引擎和下載器有一根管道,管道上面有兩個路障就是下載中間件了,而引擎和下載器之間只傳遞請求(REQUESTS)和回應(RESPONSE),所以這兩個路障很明顯的作用就是攔截請求和回應(至于攔截之后想干嘛就隨便了,比如更改請求或回應內容,更改請求頭或回應頭,或者什么都不干,記錄一下就放過去),
蜘蛛中間件處于蜘蛛和引擎之間,這里說的蜘蛛就是我們在spider目錄下撰寫的蜘蛛類,已經寫過蜘蛛的應該知道,在蜘蛛中一般會處理回應(默認決議是parse方法),回傳item,或者回傳(準確點應該是迭代)請求(scrapy.Request),而在圖中也很明顯,蜘蛛和引擎之間會傳遞請求(REQUESTS)、回應(RESPONSE)和items,回應是由下載器從網站上下載得到的,在傳遞給引擎后給蜘蛛來處理,而items一般是由蜘蛛從回應內容中決議出來傳遞給引擎在給專案管道處理,而請求一般是由蜘蛛中的start_urls中定義的URL和蜘蛛決議出的新的URL準備傳遞給引擎在交由調度器統一管理,
上面的一堆屁話說的:中間件的作用就是攔截兩個組件傳遞的內容,
看了這些組件的功能和使用你會發現為什么要這么麻煩,你看我用requests庫只需要請求一下得到回應直接處理就行了,這引擎和調度器感覺沒什么存在的意義啊,這就需要慢慢理解了,或者自己寫一個簡單通用爬蟲框架可能就知道了,
中間件的撰寫
中間件的啟用
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'newspider.middlewares.UAMiddleware': 500 #newspider為scrapy專案名稱,也就是settings.py中BOT_NAME的值,UAMiddleware為定義的中間件的名字
}
字典的值如何選擇,500這個值改成其他的行不行呢?先看一下官方是怎么說的:
scrapy會將DOWNLOADER_MIDDLEWARES設定與DOWNLOADER_MIDDLEWARES_BASE設定合并,然后按值的順序排序以獲取啟用的中間件的最終排序串列:值最小的中間件離引擎更近,最大的中間件離下載器更近,換句話說,每個中間件的process_request() 方法將以遞增的順序被呼叫,而每個中間件的process_response()方法將以遞減的順序呼叫,
要決定分配給中間件的順序,請查看 DOWNLOADER_MIDDLEWARES_BASE設定并根據您要插入中間件的位置選擇一個值,順序很重要,因為每個中間件執行不同的操作,并且您的中間件可能取決于所應用的某些先前(或后續)中間件,
如果要禁用內置中間件(DOWNLOADER_MIDDLEWARES_BASE默認情況下在定義和啟用的中間件 ),則必須在專案的DOWNLOADER_MIDDLEWARES設定為None,
上面的一些話中有一句很重要:每個中間件的process_request() 方法將以遞增的順序被呼叫,而每個中間件的process_response()方法將以遞減的順序呼叫,這應該就很清楚值怎么選吧,不過一般中間件并沒有確定的順序,只要不產生矛盾就行了,
舉個例子吧:你已經寫了一個中間件newspider.middlewares.UAMiddleware,但是你在啟用的時候沒有禁止內置的UserAgentMiddleware,怎么才能使你的中間件生效呢?代碼如下:
DOWNLOADER_MIDDLEWARES = {
#'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'newspider.middlewares.UAMiddleware': 501 #newspider為scrapy專案名稱,也就是settings.py中BOT_NAME的值,UAMiddleware為定義的中間件的名字
}
因為默認的UserAgentMiddleware值為500,因為修改請求頭是在process_request,而process_request是以遞增的形式被呼叫,所以會先呼叫內置UserAgentMiddleware,在呼叫你定義的UAMiddleware,則內置的會被覆寫,不過因為很多人修改請求頭都是以字典訪問的形式修改(request.headers["User-Agent"] = ""),這樣的話即使你設定值為499,結果還是你設定的User-Agent,而不是默認內置的,
其實看一下內置的代碼就可以理解了:源代碼
代碼使用的是request.headers.setdefault(b'User-Agent', self.user_agent),setdefault是當不存在鍵時設定,存在則不設定,
內置下載中間件
DOWNLOADER_MIDDLEWARES_BASE = {
'scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware': 300,
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware': 400,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': 500,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': 550,
'scrapy.downloadermiddlewares.ajaxcrawl.AjaxCrawlMiddleware': 560,
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware': 580,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware': 600,
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware': 700,
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware': 750,
'scrapy.downloadermiddlewares.stats.DownloaderStats': 850,
'scrapy.downloadermiddlewares.httpcache.HttpCacheMiddleware': 900,
}
下載中間件的撰寫
- process_request(request,spider): 所有請求都會呼叫此方法
- process_response(request, response, spider): 這里的引數比上面的多了response,肯定是用來處理response的
- process_exception(request, exception, spider):處理例外
- from_crawler(cls, crawler):從settings.py獲取配置
假設我們需要一個自動管理cookie的中間件,應該怎么撰寫?首先管理cookie一般就是將服務器回傳的Set-cookie更新一下已保存的cookie,偽代碼如下:
from scrapy.exceptions import NotConfigured
class CookieMiddleware(object):
def __init__(self):
# 實際上cookies并不能使用字典來保存,因為cookies是可以包含相同的鍵的
# 這里只做簡單的演示,正常可以使用scrapy.http.cookies.CookieJar
self.cookies = {}
def process_request(request, spider):
self.addcookies(request, self.cookies)
def process_response(request, response, spider):
newcookie = response.headers.getlist('Set-Cookie')
self.updatecookies(self.cookies, newcookie)
return response
def process_exception(request, exception, spider):
pass
def addcookies(self, request, cookies):
'''
給請求加cookie
'''
pass
def updatecookie(self, cookies, cookie):
'''
更新cookie字典(物件)
'''
pass
@classmethod
def from_crawler(cls, crawler):
if not crawler.settings.get('是否開啟cookie'):
#這個方法在__init__之前,拋出例外的話,類中的所有方法就都不執行了
raise NotConfigured
其實scrapy已經內置了cookies管理的中間件,可以參考一下源代碼:https://docs.scrapy.org/en/latest/_modules/scrapy/downloadermiddlewares/cookies.html#CookiesMiddleware
想要一個隨機User-Agent的中間件也很簡單,只需要在process_request方法中改變請求頭就行了,其實process_request和process_response這兩個方法是有回傳值的,在上面的例子中只是對請求頭和回應頭做了修改,所以沒有涉及到回傳值,如果我們需要對請求和回應整個做更改的話就需要重新構造請求和回應,這里最典型的例子就是selenium中間件了,
spider示例代碼:
import scrapy
from selenium import webdriver
class SeleniumSpider(scrapy.Spider):
name = 'seleniumspider'
start_urls = ['https://example.com']
# 實體化瀏覽器物件, 因為瀏覽器物件只需要實體化一次, 所以不在中間件中進行實體化
bro = webdriver.Chrome(executable_path=r'E:\spiderman\day13\wynews\wynews\wynews\chromedriver.exe')
def parse(self, response):
'''
和正常一樣,該怎么決議怎么決議
'''
pass
selenium中間件示例代碼(只是簡單演示,為了更好理解中間件怎么寫):
from selenium.common.exceptions import TimeoutException
from scrapy.http import HtmlResponse
class SeleniumMiddleware(object):
def __init__(self, timeout=None, options=None):
pass
def process_reqeust(self, request, spider):
try:
url = request.url
spider.bro.get(url)
return HtmlResponse(url=url, body=spider.bro.page_source, request=request,encoding='utf-8',status=200)
except TimeoutException:
return HtmlResponse(url=url, status=500, request=request)
@classmethod
def from_crawler(cls, crawler):
pass
在代碼中HtmlResponse類就是我們新構建的回應,這樣前面的spider處理的response就是這個回應了,這里有個疑問?為什么要在process_reqeust這個方法中回傳回應,就不能在process_response中嗎?其實也可以,區別在于process_reqeust回傳的話,會忽略其他中間件中的process_reqeust和process_exception方法,只執行其他中間件的process_response方法,試想一下如果你還有一個cookie管理的中間件,process_reqeust的操作是不是就和SeleniumMiddleware中的矛盾了,所以我們要在process_reqeust回傳response來使其他中間件的process_reqeust方法失效,
回傳值
process_reqeust方法回傳值
- None:如果回傳None,則一切正常傳遞
- request物件:如果回傳request物件,scrapy會停止呼叫接下來的中間件而重新處理request物件(也就是交由引擎重新管理)
- response物件:...,Scrapy不再呼叫其他中間件的process_request()或process_exception()方法,它將直接呼叫其他中間件的process_response方法
- IgnoreRequest例外:依次呼叫所有中間件的process_exception方法
process_response方法回傳值(注意這個方法必須回傳一個物件,不能是None)
- response物件:傳遞給下一個中間件的process_response方法
- request物件:scrapy會停止呼叫接下來的中間件而重新處理request物件(也就是交由引擎重新管理)
- IgnoreRequest例外:依次呼叫所有中間件的process_exception方法
process_exception方法回傳值
- None:繼續傳遞
- request物件:scrapy會停止呼叫接下來的中間件的process_exception方法而重新處理request物件(也就是交由引擎重新管理)
- response物件:停止傳遞接下來的中間件中的process_exception,而開始呼叫所有process_response方法
蜘蛛中間件
- process_spider_input(response, spider):所有請求都會呼叫這個方法
- process_spider_output(response, result, spider):spider決議完response之后呼叫該方法,result就是決議的結果(是一個可迭代物件),其中可能是items也可能是request物件
- process_spider_exception(response, exception, spider):處理例外
- process_start_requests(start_requests, spider):同process_spider_output,不過只處理spider中start_requests方法回傳的結果
- from_crawler(cls, crawler):...
同樣是攔截請求和回應,那么和下載中間件有什么區別呢?因為下載中間件是連通引擎和下載器的,所以如果修改請求只會影響下載器回傳的結果,如果修改回應,會影響蜘蛛處理,而蜘蛛中間件是連通引擎和蜘蛛的,如果修改請求則會影響整個scrapy的請求,因為scrapy的所有請求都來自于蜘蛛,當然包括調度器和下載器,如果修改回應,則只會影響蜘蛛的決議,因為回應是由引擎傳遞給蜘蛛的,
上面說的有點亂,整理一下這兩個的功能:
蜘蛛中間件:記錄深度、丟棄非200狀態碼回應、丟棄非指定域名請求等
下載中間件:修改請求頭、修改回應、管理cookies、丟棄非200狀態碼回應、丟棄非指定域名請求等
丟棄非指定域名請求一般使用蜘蛛中間件,如果使用下載中間件會導致引擎和調度器的無效任務變多,丟棄非200狀態碼回應我感覺應該用下載中間件,但是scrapy內置的使用的是蜘蛛中間件,可能是我理解不夠透徹吧,
scrapy已經提供了很多內置的中間件,只需要啟用即可,另外,蜘蛛中間件一般用于操作蜘蛛回傳的request,而下載中間件用于操作向互聯網發起請求的request和回傳的response,更多的示例可以看一些內置中間件的原始碼,蜘蛛中間件一般不需要自己撰寫,使用內置的幾個也足夠了
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/145097.html
標籤:Python