先達到極限,然后再突破它
HA高可用
HA概述
-
所謂HA(High Available),即高可用(7*24小時不中斷服務),
-
實作高可用最關鍵的策略是消除單點故障,HA嚴格來說應該分成各個組件的HA機制:HDFS的HA和YARN的HA,
-
Hadoop2.0之前,在HDFS集群中NameNode存在單點故障(SPOF),
-
NameNode主要在以下兩個方面影響HDFS集群
NameNode機器發生意外,如宕機,集群將無法使用,直到管理員重啟
NameNode機器需要升級,包括軟體、硬體升級,此時集群也將無法使用
HDFS HA功能通過配置Active/Standby兩個NameNodes實作在集群中對NameNode的熱備來解決上述問題,如果出現故障,如機器崩潰或機器需要升級維護,這時可通過此種方式將NameNode很快的切換到另外一臺機器,
HDFS-HA作業要點
1.元資料管理方式需要改變
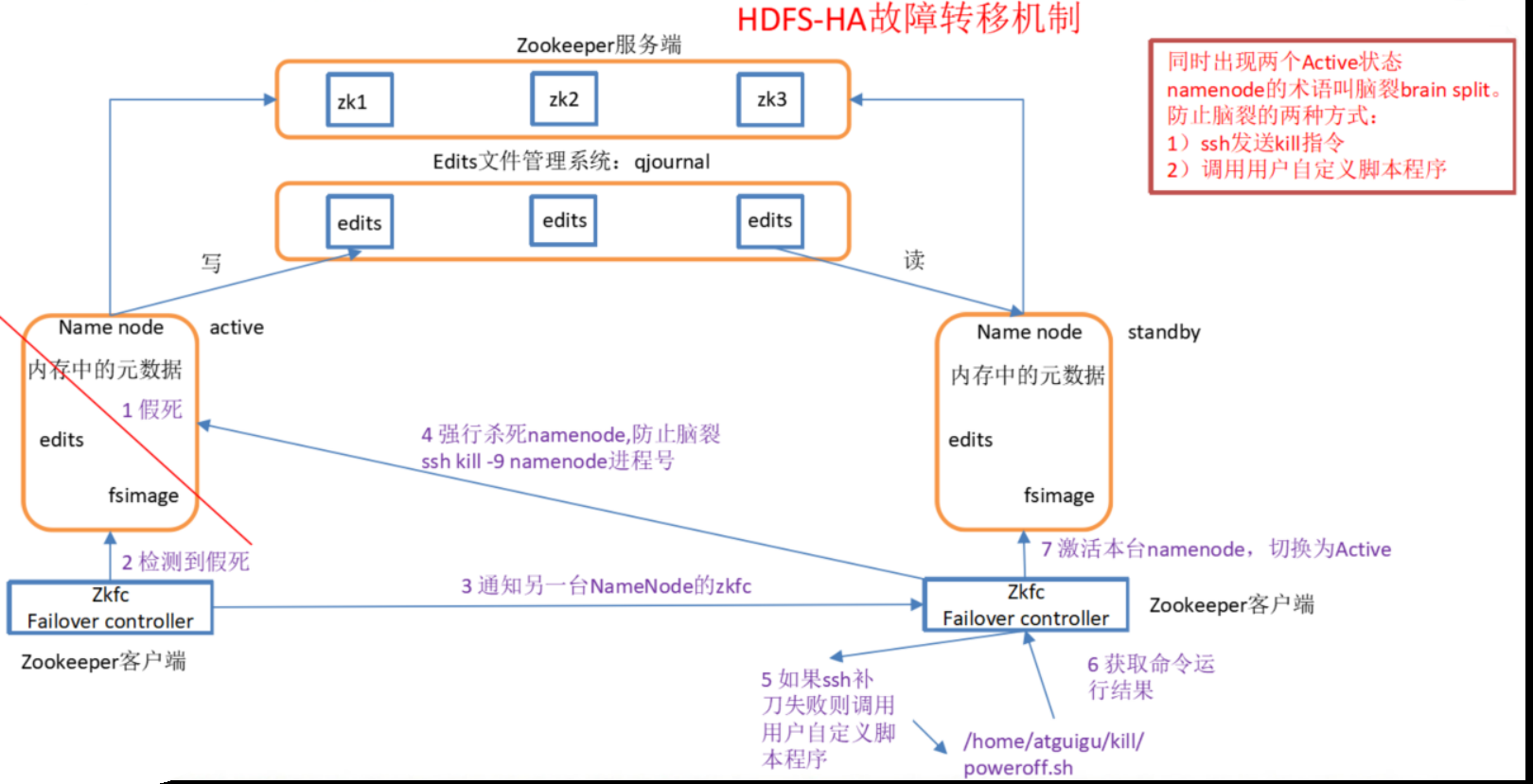
記憶體中各自保存一份元資料;Edits日志只有Active狀態的NameNode節點可以做寫操作;兩個NameNode都可以讀取Edits;共享的Edits放在一個共享存盤中管理(qjournal和NFS兩個主流實作);
2.需要一個狀態管理功能模塊
實作了一個zkfailover,常駐在每一個namenode所在的節點,每一個zkfailover負責監控自己所在NameNode節點,利用zk進行狀態標識,當需要進行狀態切換時,由zkfailover來負責切換,切換時需要防止brain split現象的發生,
3.必須保證兩個NameNode之間能夠ssh無密碼登錄
4.隔離(Fence),即同一時刻僅僅有一個NameNode對外提供服務
HDFS-HA自動故障轉移作業機制
手動轉移命令
hdfs haadmin -failover
但是手動轉移不夠方便,我們需要配置自動故障轉移,自動故障轉移為HDFS部署增加了兩個新組件ZooKeeper和ZKFailoverController(ZKFC)行程
HA的自動故障轉移依賴于ZooKeeper的以下功能:
-
故障檢測:集群中的每個NameNode在ZooKeeper中維護了一個持久會話,如果機器崩潰,ZooKeeper中的會話將終止,ZooKeeper通知另一個NameNode需要觸發故障轉移,
-
現役NameNode選擇:ZooKeeper提供了一個簡單的機制用于唯一的選擇一個節點為active狀態,如果目前現役NameNode崩潰,另一個節點可能從ZooKeeper獲得特殊的排外鎖以表明它應該成為現役NameNode,
ZKFC是自動故障轉移中的另一個新組件,是ZooKeeper的客戶端,也監視和管理NameNode的狀態,每個運行NameNode的主機也運行了一個ZKFC行程,ZKFC負責;
-
健康監測:ZKFC使用一個健康檢查命令定期地ping與之在相同主機的NameNode,只要該NameNode及時地回復健康狀態,ZKFC認為該節點是健康的,如果該節點崩潰,凍結或進入不健康狀態,健康監測器標識該節點為非健康的,
-
ZooKeeper會話管理:當本地NameNode是健康的,ZKFC保持一個在ZooKeeper中打開的會話,如果本地NameNode處于active狀態,ZKFC也保持一個特殊的znode鎖,該鎖使用了ZooKeeper對短暫節點的支持,如果會話終止,鎖節點將自動洗掉,
-
基于ZooKeeper的選擇:如果本地NameNode是健康的,且ZKFC發現沒有其它的節點當前持有znode鎖,它將為自己獲取該鎖,如果成功,則它已經贏得了選擇,并負責運行故障轉移行程以使它的本地NameNode為Active,故障轉移行程與前面描述的手動故障轉移相似,首先如果必要保護之前的現役NameNode,然后本地NameNode轉換為Active狀態,
相關資料

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/146914.html
標籤:Java
下一篇:Spring的學習與實戰