一、執行緒(Thread)
1、定義:執行緒是作業系統能進行運算調度的最小單位,它包含在行程中,是行程的實際運作單位,一條執行緒是行程中一個單一順序的控制流,一個行程中可以并發多個執行緒,每條執行緒并行執行不同的任務,簡單理解:執行緒是一系列指令的集合,作業系統通過這些指令呼叫硬體,
2、同一個執行緒中的所有執行緒共享同一個記憶體空間資源,
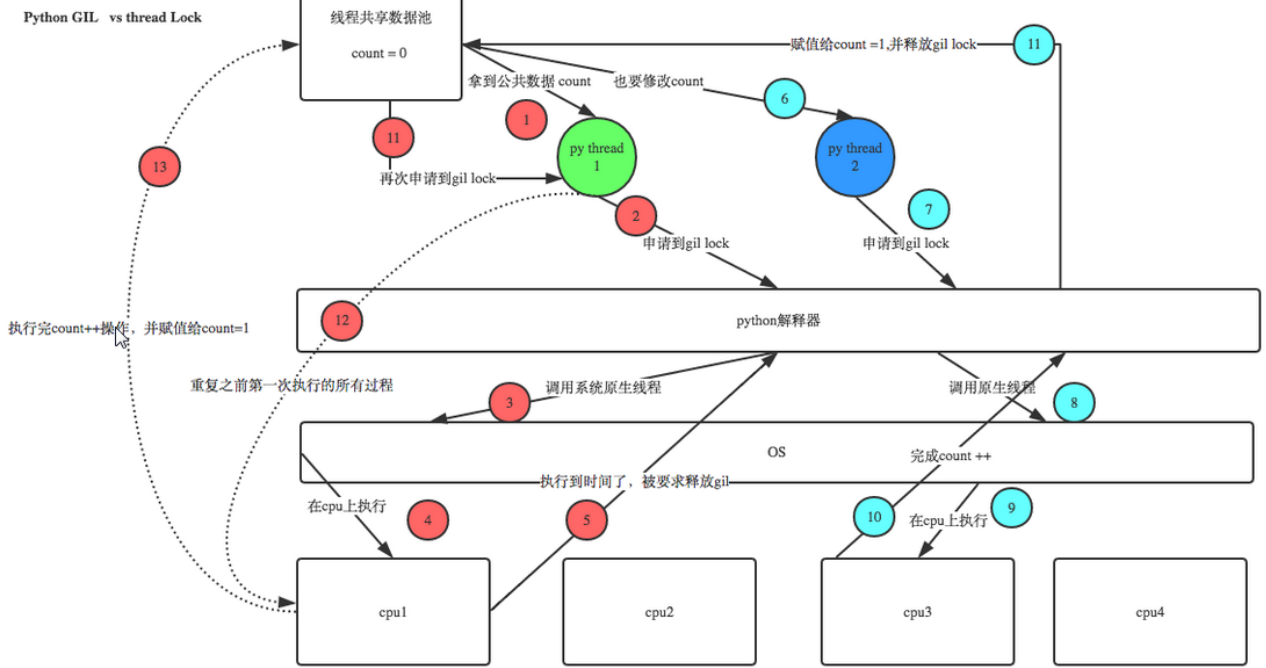
3、Python的多執行緒是偽多執行緒,是利用CPU背景關系切換的方式造成并發效果,其實同時運行的只有一個執行緒,如下面的圖1,
4、多執行緒代碼:
import threading import time class MyThread(threading.Thread): """ # 用自定義一個子類的方式來啟動執行緒 """ def __init__(self, n): super(MyThread, self).__init__() self.n = n def run(self): print("你好,%s" % self.n) time.sleep(2) start_time = time.time() thread_list = [] # 啟動50個執行緒 for i in range(50): t1 = MyThread("t%s" % i) t1.start() thread_list.append(t1) # 等待所有執行緒執行完畢后主執行緒再繼續執行 for i in thread_list: i.join() print("總共執行時間:%s" % float(time.time() - start_time))
5、全域解釋器鎖(GIL)
5.1、定義:GIL 是最流行的 CPython 解釋器(平常稱為 Python)中的一個技術術語,中文譯為全域解釋器鎖,其本質上類似作業系統的 Mutex(即互斥鎖,意思是我修改的時候你不能修改,也就是鎖的意思)
5.2、功能:在 CPython 解釋器中執行的每一個 Python 執行緒,都會先鎖住自己,以阻止別的執行緒執行,這樣在同個時間一個CPU只執行一個執行緒,當然,CPython 不可能容忍一個執行緒一直獨占解釋器,check interval 機制會在一個時間段后釋放前面一個執行緒的全域鎖執行下一個執行緒,以達到輪流執行執行緒的目的,這樣一來,用戶看到的就是“偽”并行,即 Python 執行緒在交替執行,來模擬真正并行的執行緒,
5.3、CPython 引進 GIL,可以最大程度上規避類似記憶體管理這樣復雜的競爭風險問題,有了 GIL,并不意味著無需去考慮執行緒安全,因為即便 GIL 僅允許一個 Python 執行緒執行,但別忘了 Python 還有 check interval 這樣的搶占機制,所以就要引入執行緒鎖的機制,保證同個時間只有一個執行緒修改資料,
《圖1》
5.4:執行緒鎖的代碼如下
import threading import time num = 0 lock_obj = threading.Lock() def run(): # 申請鎖,使別的執行緒進不來 lock_obj.acquire() global num time.sleep(1.1) num = num + 1 # 解鎖,解鎖后別的執行緒可以進來 lock_obj.release() t_list = [] start_time = time.time() # 啟動1000個執行緒 for i in range(100): t1 = threading.Thread(target=run) t1.start() t_list.append(t1) for i in t_list: i.join() time.sleep(3) print("num:%d" % num) print("time:%f" % float(time.time() - start_time))
6、遞回鎖:一個鎖套另外一個鎖,形成鎖止回圈,這種情況就要用到遞回鎖RLOCK
import threading, time def run1(): print("grab the first part data") lock.acquire() global num num += 1 lock.release() return num def run2(): print("grab the second part data") lock.acquire() global num2 num2 += 1 lock.release() return num2 def run3(): lock.acquire() res = run1() print('--------between run1 and run2-----') res2 = run2() lock.release() print(res, res2) num, num2 = 0, 0 # 這里如果用Lock()就會無限回圈,找不到具體用哪個鑰匙打開鎖,如果用RLock就不會,如果又多重鎖嵌套的情況一定要用遞回鎖 lock = threading.Lock() for i in range(1): t = threading.Thread(target=run3) t.start() while threading.active_count() != 1: print("當前活躍的執行緒數:",threading.active_count()) else: print('----all threads done---') print("列印num和num2:",num, num2)
7、信號量(Semaphore):允許同時間最多幾個執行緒進入執行,每出來一個進去一個,同時保持預先設定的執行緒最大允許數量,
import threading, time def run(n): semaphore.acquire() time.sleep(1) print("run the thread: %s\n" % n) semaphore.release() if __name__ == '__main__': semaphore = threading.BoundedSemaphore(5) # 最多允許5個執行緒同時運行 for i in range(22): t = threading.Thread(target=run, args=(i,)) t.start() while threading.active_count() != 1: pass # print threading.active_count() else: print('----all threads done---') #print(num)
8、事件(Event)
8.1、定義:通過標識位和狀態,來實作執行緒之間的互動,簡單說,就是一個標志位,只有兩種狀態,一種是設定(Event.set()),一直是沒有設定(Event.clear()),
8.2、Event類還有兩個方法,wait()等待被設定,isset()判斷是否被設定
8.3、以下代碼實作一個簡單事件,一個執行緒控制紅綠燈,另外一個執行緒控制車子,當紅綠燈是紅色的時候,車子停止,綠的時候,車子行駛的效果
import time import threading event = threading.Event() def lighter(): count = 0 event.set() # 剛開始的標識位先設定綠燈 while True: if 5 < count < 10: # 改成紅燈 event.clear() # 把標志位清了 print("\033[41;1mred light is on....\033[0m") elif count > 10: event.set() # 變綠燈 count = 0 else: print("\033[42;1mgreen light is on....\033[0m") time.sleep(1) count += 1 def car(name): while True: if event.is_set(): # 代表綠燈 print("[%s] running..." % name) time.sleep(1) else: print("[%s] sees red light , waiting...." % name) event.wait() print("\033[34;1m[%s] green light is on, start going...\033[0m" % name) light = threading.Thread(target=lighter, ) light.start() car1 = threading.Thread(target=car, args=("Tesla",)) car1.start()
9、守護執行緒
9.1、定義:即服務于非守護執行緒的執行緒,在非守護執行緒終止運行后被終止,這里說的終止不是代碼結束,而是主執行緒要等非守護執行緒全部運行完畢才能終止(回收資源),所以被標識為守護執行緒的執行緒,其實是可以先考慮被終止的執行緒,
9.2、注意:無論是行程還是執行緒,都遵循:守護xx會等待主xx運行完畢后被銷毀,需要強調的是:運行完畢并非終止運行,
from threading import Thread import time def foo(): print(123) time.sleep(2) # 注意,這里因為主執行緒已經接受了,所以被標識為守護執行緒的t1,就不會輸出end123 print("end123") def bar(): print(456) time.sleep(1) print("end456") t2 = Thread(target=bar) t1 = Thread(target=foo) t2.start() t1.daemon = True t1.start() print("main-------")
二、行程(Progress)
1、定義:一個程式對各資源管理和呼叫的集合就是行程,比如QQ對網卡、記憶體、硬碟的調度和管理,對于作業系統來說,某一個行程是統一的整體,行程操作CPU就要先創建一個執行緒,行程本身是一個資源集合,執行需要靠執行緒,
2、為什么要用多行程?
2.1、IO操作(讀硬碟,網路Socke等操作)不占用CPU,計算(算術計算等)才占用CPU,python的多執行緒本質上是單執行緒的,所以遇到需要大量CPU密集操作的情況不適合用python多執行緒,而大量IO的操作比較適合python多執行緒,
2.2、Python的多執行緒是偽多執行緒,本質是單執行緒,如果要實作多執行緒的效果,怎么辦?那么就要用到多行程,CPU的一核運行一個行程,如果8核,那么就是八個執行緒(每個行程執行一個主執行緒)在跑,大大提高了作業效率,
3、多行程優點:因為行程之間本身無法互相訪問記憶體空間,所以不存在鎖的問題,
缺點:多行程共享資料上增加了一定難度,
4、每一個行程都是他的父行程啟動的,可以用os.getppid()查看父親行程的ID,用os.getpid()查看本行程的ID
5、多行程的代碼:
from multiprocessing import Process import os def run(name): print("行程 %s 的ID是%s" % (name,os.getpid())) if __name__ == '__main__': # 啟動十個行程 for i in range(10): p = Process(target=run, args=("P%i" % i,)) p.start()
6、多行程之間的通信:因為行程的記憶體是獨立的,所以原則上A執行緒要訪問B執行緒的資料是無法訪問的,如果一定要訪問可以用以下中間件,
6.1、行程專用佇列(Queue):它和執行緒佇列不同之處在于,執行緒佇列只能在本行程里面的執行緒才能訪問,如果出了行程就不能用了,但是行程專用佇列是可以在行程之間使用的,將行程專用佇列傳參給行程,這時是克隆了一個佇列物件傳參,實際是兩個佇列物件,當子執行緒往自己的佇列中放資料以后行程專用佇列物件通過反序列化的操作將資料又回傳給父行程,雖然是兩個佇列物件但是看起來就像一個物件一樣,所以這里不存在鎖的問題,每個行程實際上都修改的是自己的佇列物件,此物件用來通信,不能修改共享資料
from multiprocessing import Process,Queue import os def run(name,q): q.put("hello %s" % name) print("行程 %s 的ID是%s" % (name,os.getpid())) if __name__ == '__main__': q = Queue() list_obj = [] # 啟動十個行程 for i in range(10): p = Process(target=run, args=("P%i" % i,q)) list_obj.append(p) p.start() for i in list_obj: # 等待行程全部執行完畢 i.join() for i in range(q.qsize()): print("得到的行程式列:", q.get_nowait())
6.2、管道(Pipe):相當于電話線,一頭連著父行程,一頭連著子行程,相當于建立了soket連接通信,此物件用來通信,不能修改共享資料
from multiprocessing import Process,Pipe import os def run(name,cc): cc.send("我是行程 %s 的ID是%s" % (name,os.getpid())) cc.send("我是行程 %s 的ID是%s" % (name,os.getpid())) print(cc.recv()) if __name__ == '__main__': # 創建一個管道,會回傳管道的兩頭,一頭給父行程用,一頭給子行程用 parent_conn,child_conn = Pipe() p = Process(target=run, args=("P1", child_conn)) p.start() print(parent_conn.recv()) print(parent_conn.recv()) # # 子執行緒只發送了兩條資料,所以這一潭訓卡住等待子執行緒繼續發送 # print(parent_conn.recv()) # 以下這一條,在子執行緒不join的情況下也是可以接收到的 parent_conn.send("我是父行程!")
6.3、Manager:可以實作多行程之間真正的資料共享,而且不用加鎖,因為Manager中已經默認加鎖了,不允許兩個行程同時進去添加修改資料,其實作原理跟行程專用佇列一樣,都是克隆了一個Manager給子執行緒
# 多行程 Manager import os from multiprocessing import Process, Manager def run(m_dict1, m_list1): m_dict1[os.getpid()] = os.getpid() m_list1.append(os.getpid()) if __name__ == '__main__': m = Manager() # 行程間可以共享的字典物件 m_dict = m.dict() # 行程間可以共享的串列物件 m_list = m.list() p_list = [] for i in range(20): p = Process(target=run, args=(m_dict, m_list)) p.start() p_list.append(p) for i in p_list: i.join() print(m_dict) print(m_list)
6.4、行程的鎖:雖然行程大部分情況下不存在操作同個資源的問題,但是也有例外的情況,這種情況就需要用到行程鎖,比如以下代碼,這里的公共資源即是螢屏,多行程同時對螢屏輸出就需要加鎖
from multiprocessing import Process, Lock def run(name, lock_obj): lock_obj.acquire() print("我的名字是:%s" % name) lock_obj.release() if __name__ == '__main__': lock = Lock() # 啟動十個行程 for i in range(10): p = Process(target=run, args=("P%i" % i, lock)) p.start()
7、行程池(Pool):因為每一次啟動一個行程,相當于克隆一份父行程,如果父行程很大,那么系統開銷就很大,這里就要使用行程池,初始化固定數量的行程數量,共同承擔多行程任務,
import time from multiprocessing import Pool, current_process, Queue, Process def run(): # 因為行程池里有3個可用行程,所以會每三個任務執行一次,然后執行下一批任務, time.sleep(1) print(current_process().name) # 回呼函式,這里一定要加一個形參,不然無法運行, def exit_method2(arg): print("子行程程呼叫以后主,主行程將呼叫本回呼方法",current_process().name,arg) if __name__ == '__main__': # 運行行程池里面同時放入3個行程 pool = Pool(processes=3) list_val = [] for i in range(10): pool.apply_async(func=run,callback=exit_method2) print("主行程即將結束") pool.close() print("繼續等待所有子執行緒運行完畢...如果不加join那么pool.close()就會直接結束所有行程不會等待子行程") pool.join()
三、協程(Coroutine)
1、定義:用戶態的輕量級的執行緒,又稱為微執行緒,協程擁有自己暫存器背景關系和堆疊,協程調度切換時,將暫存器背景關系和堆疊保存到其他地方,在切回來時恢復到之前的暫存器背景關系和堆疊,以此協程可以保存上一次的狀態,進入上一次呼叫時的狀態,進入上一次離開時所處邏輯流的位置,協程是跑在執行緒里面的,其原理是遇到IO操作(IO操作很耗時)就切換到下一個命令,IO操作完畢又切換回來,只留下CPU運算,這樣就可以最大程度的提高速度,在CPU層面只又執行緒,CPU不知道協程的存在,協程是用戶自己控制的,
2、協程的優點:
> 無需執行緒背景關系切換的開銷
> 無需原子操作鎖定及同步的開銷,因為本質是單執行緒,
> 方便切換控制流,簡化編程模型
> 高并發+高擴展+低成本,一個CPU支持上萬協程都沒有問題,很適合并發處理,
3、協程的缺點:
> 無法利用單個CPU的多核,本質是單執行緒,需要和行程配合才能運行在多個CPU上,我們平時撰寫的大部分程式都沒有這個必要,除非是CPU密集型程式,
> 進行阻塞(blocking)操作時會阻塞掉整個程式,
4、用yield實作簡單協程:
import time def consumer(name): print("--->%s starting eating baozi..." % name) while True: new_baozi = yield # 含有yield的函式consumer(name)只有在外部代碼con.__next__()的時候才會執行,一直到yield為止程式流將切到外面, print("[%s] is eating baozi %s" % (name, new_baozi)) #time.sleep(1) def producer(): r = con.__next__() # 碰到__next__()則程式流程切換到含有yield標記的函式內部, r = con2.__next__() n = 0 while n < 5: n += 1 con.send(n) # 碰到send函式則回到上一次yield退出的地方,并且將seed的引數賦給yield的位置, con2.send(n) time.sleep(1) print("\033[32;1m[producer]\033[0m is making baozi %s" % n) if __name__ == '__main__': con = consumer("c1") # 這里僅分配con的記憶體空間,但是因為內部含有yield標記,所以不進入執行,只有碰到__next__()的時候才進入, con2 = consumer("c2") # 同上 p = producer()
5、安裝第三方greenlet庫,此庫是封裝的協程庫,可以用來手動切換協程:
1、如果遇到“Microsoft Visual C++ 14.0 is required ”無法安裝,可以參考這個文章:https://www.jianshu.com/p/7b24274c569a
2、注意一點,作業系統中不能有別的C++版本,先卸載以后再安裝以上教程中的C++版本,
3、安裝完C++ 14.0后,在Pycharm中的設定路徑:File | Settings | Project: python_base | Project Interpreter,在 Project Interpreter搜索greenlet安裝即可,
4、使用greenlet庫的協程:
from greenlet import greenlet def test1(): print(12) gr2.switch() # 手動切換到gr2協程 print(34) gr2.switch() def test2(): print(56) gr1.switch() print(78) gr1 = greenlet(test1) # 啟動1個協程 gr2 = greenlet(test2) # 啟動1個協程 gr1.switch() # 手動切換到gr1協程
6、安裝第三方庫Gveent庫,此庫是對greenlet的再次封裝,可以自動切換協程,當程式遇到IO操作時自動切換,可以利用其實作并發同步和異步編程
import gevent # 本程式因為使用了協程自動切換,所以總執行市場為2秒,不需要3秒,就省了1秒的時間 def foo(): print('Running in foo') gevent.sleep(2) # 遇到IO操作切換到下面一個協程 print('Explicit context switch to foo again') def bar(): print('Explicit精確的 context內容 to bar') gevent.sleep(1) # 遇到IO操作切換到下面一個協程 print('Implicit context switch back to bar') def func3(): print("running func3 ") # 遇到IO操作自動切換到第一個協程, # 但因為第一個協程還在等待,所以又自動切換到第二個協程, # 第二個協程也在等待,所以自動切換到自己并且輸出下面一句話, gevent.sleep(0) print("running func3 again ") gevent.join_all([ gevent.spawn(foo), # 生成,1個自動協程 gevent.spawn(bar), # 生成,1個自動協程 gevent.spawn(func3), # 生成,1個自動協程 ])
一個簡單的Gveent爬蟲,實作遇到IO的自動切換,這樣爬取速度會很快:
from urllib import request import gevent, time from gevent import monkey # 把當前程式的所有的io操作給我單獨的做上標記,如果不加這句話gevent是檢測不到urllib包內部的IO操作的也就無法做自動切換 monkey.patch_all() def f(url): print('GET: %s' % url) resp = request.urlopen(url) data = resp.read() print('%d bytes received from %s.' % (len(data), url)) # 三個反爬等級很低的網站 urls = ['http://www.pelle.cn/', 'http://it.sxcqjykj.cn/', 'https://www.niu.com/'] time_start = time.time() for url in urls: f(url) print("同步 總耗時", time.time() - time_start) print() print() async_time_start = time.time() gevent.joinall([ gevent.spawn(f, urls[0]), gevent.spawn(f, urls[1]), gevent.spawn(f, urls[2]), ]) print("異步 總耗時", time.time() - async_time_start)
7、使用協程,實作多協程的Socket服務器
######## Server ############# import sys import socket import time import gevent from gevent import socket, monkey monkey.patch_all() def server(port): s = socket.socket() s.bind(('0.0.0.0', port)) s.listen(500) while True: cli, addr = s.accept() gevent.spawn(handle_request, cli) def handle_request(conn): try: while True: data = conn.recv(1024) print("recv:", data) conn.send(data) if not data: conn.shutdown(socket.SHUT_WR) except Exception as ex: print(ex) finally: conn.close() if __name__ == '__main__': server(54971) ######## Client ############# import socket HOST = 'localhost' # The remote host PORT = 54971 # The same port as used by the server s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.connect((HOST, PORT)) while True: msg = bytes(input(">>:"), encoding="utf8") s.sendall(msg) data = s.recv(1024) print('Received', data) s.close()
四、事件驅動的編程范式:
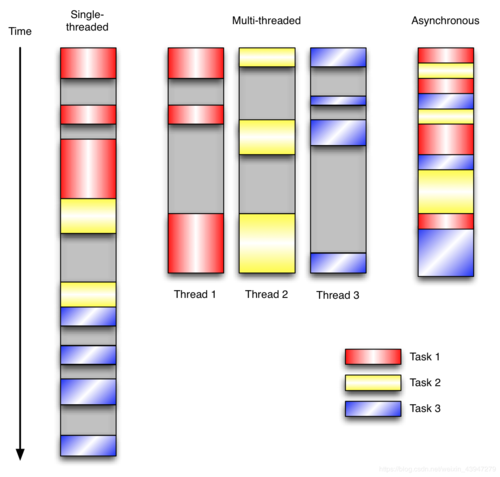
1、定義:這里程式的執行流由外部事件來決定,特點是包含一個事件回圈,當外部事件發生時使用回呼來觸發相應的處理,另外兩個常見范式是單執行緒同步編程和多執行緒編程,
關于三種編程范式的執行流程圖解,如下圖,Asynchronous異步就是事件驅動編程,這里用到了協程實作,
2、通常服務器處理模型有以下三種模型:
> 接到請求后創建一個新執行緒處理(涉及到執行緒同步,有可能面臨死鎖等問題),
> 接到請求后創建一個新行程處理(開銷大,性能差但是實作簡單),
> 接到請求后創建一個協程處理(即收到請求,放入事件串列,讓主行程通過非阻塞IO的方式來處理請求,寫的代碼比前面兩種都要復雜,但這是網路服務器普遍采用的方式)
3、以UI編程為例,如何知曉界面上用戶是否點擊了某個元素呢?有下面兩個方法可以
> 創建一個不斷回圈的執行緒,用來監控用戶的行為,如果點擊了,就觸發事件,但缺點是:如果收到一個點擊后處理事件太長,那么就會形成阻塞,其他點擊行為就無法及時的處理,
> 事件驅動模型,有一個事件訊息佇列,用戶點擊滑鼠后,往這個佇列增加一個訊息,有一個執行緒專門從佇列中取出訊息,根據事件不同呼叫相應的函式解決,每一個訊息都各自保存處理函式的指標,這樣每個訊息都有獨立的處理函式,
4、先來看看程式處理流程都有幾種I/O處理方式:
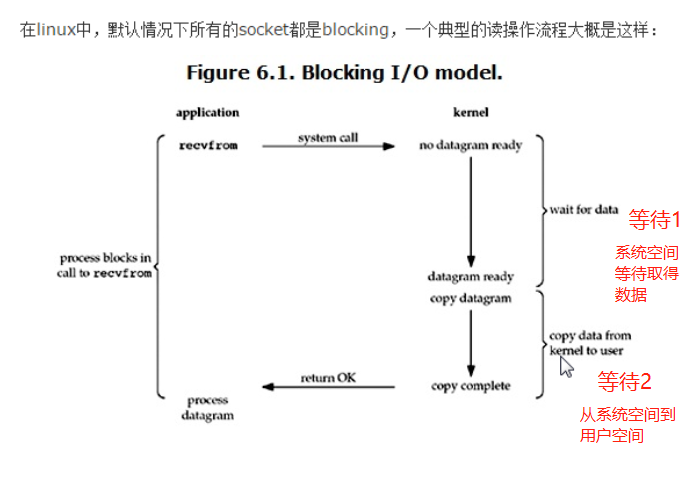
> 阻塞I/O(Blocking I/O):(同步的),用戶程式申請I/O資料,是向作業系統的相關I/O介面申請資料,然后作業系統取回資料以后放在內核記憶體空間,再從內核空間拷貝到用戶記憶體空間,這個程序有兩個等待時間,這個等待時間整個執行緒處于阻塞狀態
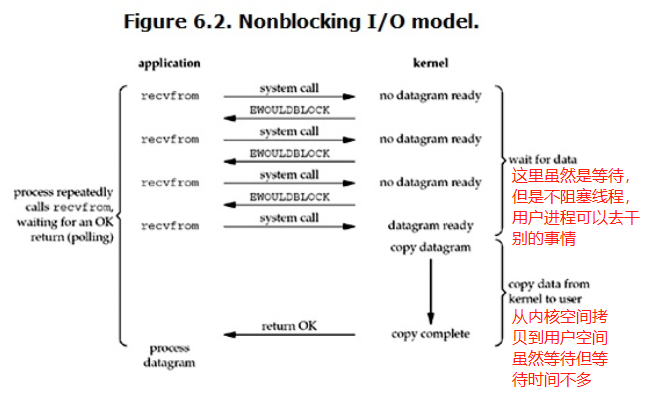
> 非阻塞I/O(Nonblocking I/O):(同步的),用戶執行緒發出I/O請求以后會不斷詢問內核是否所有資料都準備好了,內核馬上回應錯誤則說明未準備好,不需要阻塞,此時用戶行程可以干別的事情,如果準備好了則將資料從內核空間拷貝到用戶空間,這個程序是阻塞的,如果資料很多,那么整個拷貝程序就會卡很久,整個程序的特點是用戶行程需要不斷詢問內核是否將資料準備好,
>同步I/O多路復用:(同步的),也就是事件驅動I/O,有三種模式,select,poll,epoll,select和poll單執行緒就可以同時處理多個網路連接的I/O,其原理是select和poll不斷的輪詢所有Socket,這個程序是阻塞的,通過輪詢獲得哪個資料準備好了然后將資料從內核空間取回,與第一種阻塞I/O的區別是,這里是一次性給多個Socket給內核委托其監控這些Socket狀態,而第一種是一次只給一個Socket,所以如果多連接的情況用這種是更快的,select和poll的區別是,前者有規定監測多少數量的sockte而poll沒有規定數量,epoll與前面兩者的區別就在于,不需要一直輪詢,內核會給epoll一個socket連接,某個socket有資料的時候通知epoll取回,然后epoll只需要拿著這個連接找到有資料的那個socket就行,不需要一直保持輪詢,Nginx就是同步IO多路復用,它不是異步IO!
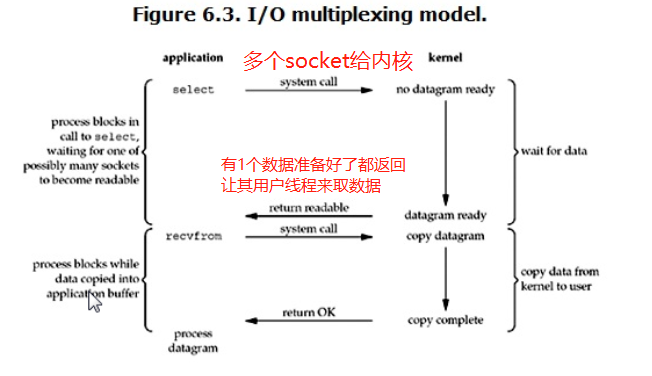
>異步I/O (Asynchronous I/O):(異步的),程式行程發出資料請求以后馬上可以回傳,內核負責將準備好的資料拷貝到用戶空間,這個程序完全不會阻塞,Notejs就是異步IO的,
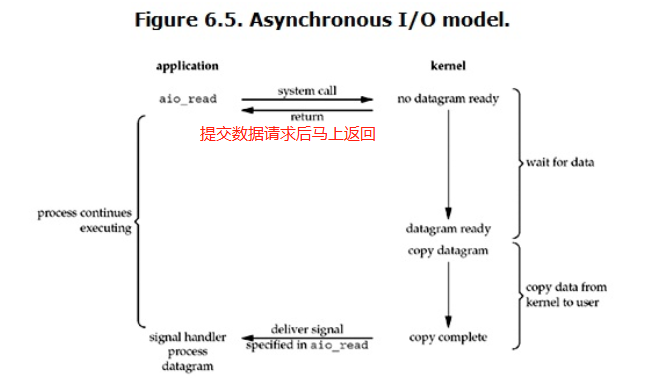
> I/O流程的總結:
I/O操作程序分成兩個步驟:第一、系統準備資料,第二、資料從系統記憶體拷貝到用戶行程記憶體,如果處理不好的話,那么第一和第二步驟都會有阻塞,
阻塞和非阻塞區別:前者會一直阻塞等待資料回傳,而后者如果內核在準備資料就會馬上回傳,
同步和異步的區別:阻塞IO、非阻塞IO和IO多路復用,都屬于同步IO,IO多路復用雖然是部分非阻塞的,但是資料從內核空間拷貝到用戶空間需要用戶行程去取資料所以是需要阻塞的,而異步IO完全不需要阻塞,

> 同步、異步、阻塞、非阻塞之間的區別:
1.同步與異步
同步和異步關注的是訊息通信機制 (synchronous communication/ asynchronous communication)
所謂同步,就是在發出一個*呼叫*時,在沒有得到結果之前,該*呼叫*就不回傳,但是一旦呼叫回傳,就得到回傳值了,
換句話說,就是由*呼叫者*主動等待這個*呼叫*的結果,
而異步則是相反,*呼叫*在發出之后,這個呼叫就直接回傳了,所以沒有回傳結果,換句話說,當一個異步程序呼叫發出后,呼叫者不會立刻得到結果,而是在*呼叫*發出后,*被呼叫者*通過狀態、通知來通知呼叫者,或通過回呼函式處理這個呼叫,典型的異步編程模型比如Node.js
舉個通俗的例子:
你打電話問書店老板有沒有《分布式系統》這本書,如果是同步通信機制,書店老板會說,你稍等,”我查一下",然后開始查啊查,等查好了(可能是5秒,也可能是一天)告訴你結果(回傳結果),
而異步通信機制,書店老板直接告訴你我查一下啊,查好了打電話給你,然后直接掛電話了(不回傳結果),然后查好了,他會主動打電話給你,在這里老板通過“回電”這種方式來回呼,
2. 阻塞與非阻塞
阻塞和非阻塞關注的是程式在等待呼叫結果(訊息,回傳值)時的狀態.
阻塞呼叫是指呼叫結果回傳之前,當前執行緒會被掛起,呼叫執行緒只有在得到結果之后才會回傳,
非阻塞呼叫指在不能立刻得到結果之前,該呼叫不會阻塞當前執行緒,
還是上面的例子,
你打電話問書店老板有沒有《分布式系統》這本書,你如果是阻塞式呼叫,你會一直把自己“掛起”,直到得到這本書有沒有的結果,如果是非阻塞式呼叫,你不管老板有沒有告訴你,你自己先一邊去玩了, 當然你也要偶爾過幾分鐘check一下老板有沒有回傳結果,
在這里阻塞與非阻塞與是否同步異步無關(同步也可能是非阻塞的,比如上面的IO多路復用,提交資料以后馬上回傳沒有阻塞掛起執行緒,之后要自己check檢測是否有資料,從系統取回資料的時候又是阻塞的),跟老板通過什么方式回答你結果無關,
四、執行緒和行程的區別
1、同個行程的執行緒之間共享記憶體空間,包括資料交換和通信,但不同行程之間的記憶體是獨立的
2、子行程是克隆了一份父行程的資料,子行程之間是互相獨立的,不能互相訪問,資料也不能共享,
3、兩個行程要通信,必須通過一個中間行程代理來實作,
4、一個執行緒可以操作同一個行程中的其他執行緒,但是行程只能操作子行程
5、對主執行緒的修改,可能會影響到其他的子執行緒,因為他們共享記憶體資料,但對主行程的修改,不會影響其他子行程,
6、行程和執行緒之間本質上不具備可比性,行程是一系列資源的總和,行程需要依靠執行緒執行,每個行程又至少包含一個主執行緒,而執行緒是一系列指令集的集合,是放到CPU中執行的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/146937.html
標籤:Python
上一篇:Python 捕獲terminate信號優雅關閉行程
下一篇:python 元組