答應我一次做好一件事情就可以了
DataNode相關概念
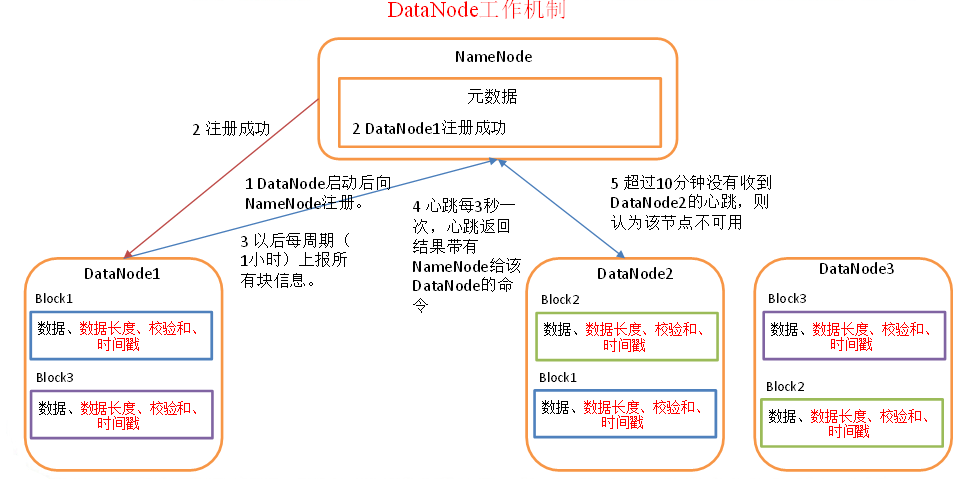
DataNode作業機制
- 一個資料塊在DataNode上以檔案形式存盤在磁盤上,包括兩個檔案,一個是資料本身,一個是元資料包括資料塊的長度,塊資料的校驗和,以及時間戳,
- DataNode啟動后向NameNode注冊,通過后,周期性(1小時)的向NameNode上報所有的塊資訊,
- 心跳是每3秒一次,心跳回傳結果帶有NameNode給該DataNode的命令如復制塊資料到另一臺機器,或洗掉某個資料塊,如果超過10分鐘沒有收到某個DataNode的心跳,則認為該節點不可用,
- 集群運行中可以安全加入和退出一些機器【后面介紹新增節點和退役節點】,
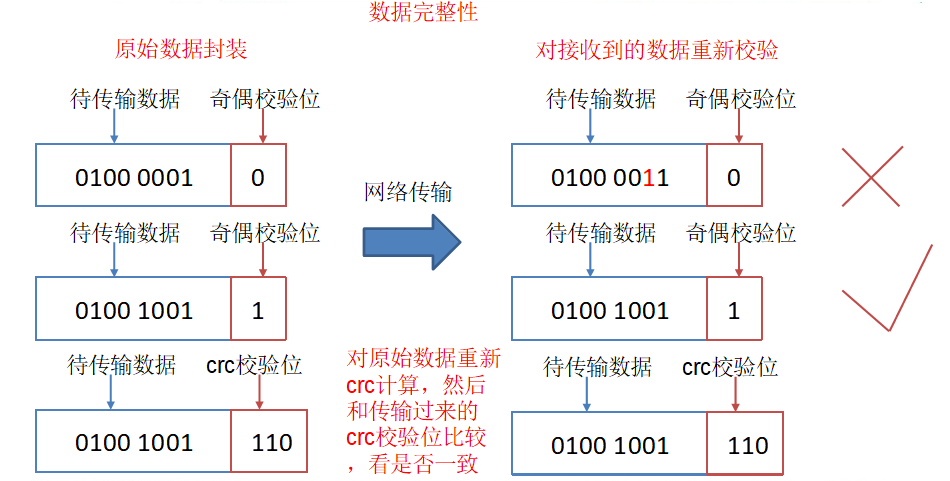
資料完整性
? 當DataNode讀取Block的時候,它會計算CheckSum,如果計算后的CheckSum,與Block創建時值不一樣,說明Block已經損壞,Client讀取其他DataNode上的Block,DataNode在其檔案創建后周期驗證CheckSum,如圖所示
掉線時限引數設定
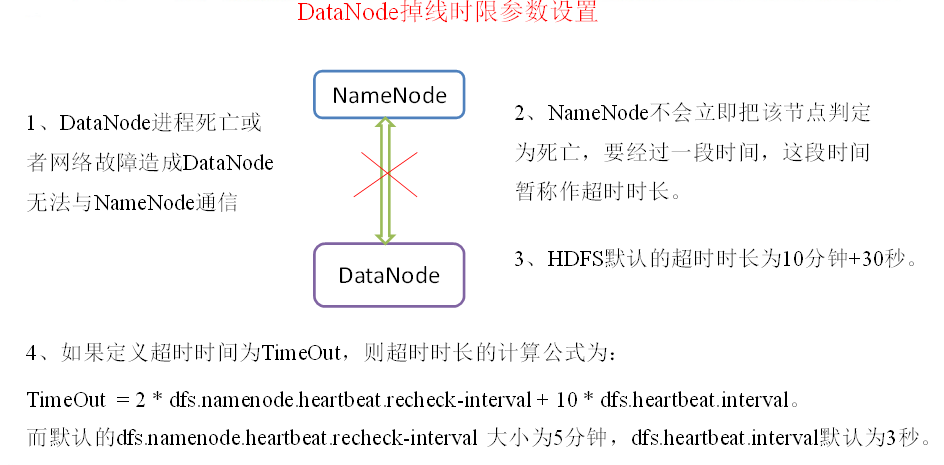
在hdfs-site.xml中配置
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value> # 單位毫秒
</property>
<property>
<name> dfs.heartbeat.interval </name>
<value>3</value> # 單位秒
</property>
服役新資料節點
技術背景
隨著公司業務量越來越大,原來的資料節點已經不能滿足其存盤資料的需求,需要進行節點的動態擴充
如果是使用云服務器就需要在創建一個實體,如果是自己的虛擬機克隆一臺就行
下面演示虛擬機克隆來新增節點
1.環境準備
(1)在hadoop104主機上再克隆一臺hadoop105主機
(2)修改IP地址和主機名稱
(3)洗掉原來HDFS檔案系統留存的檔案(/opt/module/hadoop-2.7.2/data 和log)
(4)source 一下組態檔: source /etc/profile
2.服務節點步驟
(1)直接啟動DataNode,即可關聯到集群,是不是超級簡單
[zhutiansama@hadoop105 hadoop-2.7.2]$ sbin/hadoop-daemon.sh start datanode
[zhutiansama@hadoop105 hadoop-2.7.2]$ sbin/yarn-daemon.sh start nodemanager
(2)在hadoop105上上傳檔案
[zhutiansama@hadoop105 hadoop-2.7.2]$ hadoop fs -put /opt/module/hadoop-2.7.2/LICENSE.txt /
(3)如果資料不均衡,可以用命令實作集群的再平衡
[zhutiansama@hadoop102 sbin]$ ./start-balancer.sh
退役舊資料節點【白名單】
要點:直接將想要的從機添加到白名單即可
配置白名單步驟如下:
(1)在NameNode的/opt/module/hadoop-2.7.2/etc/hadoop目錄下創建dfs.hosts檔案
[zhutiansama@hadoop102 hadoop]$ pwd
/opt/module/hadoop-2.7.2/etc/hadoop
[zhutiansama@hadoop102 hadoop]$ touch dfs.hosts
[zhutiansama@hadoop102 hadoop]$ vi dfs.hosts
添加如下主機名稱(不添加hadoop105)
hadoop102
hadoop103
hadoop104
(2)在NameNode的hdfs-site.xml組態檔中增加dfs.hosts屬性
<property>
<name>dfs.hosts</name>
<value>/opt/module/hadoop-2.7.2/etc/hadoop/dfs.hosts</value>
</property>
(3)組態檔分發
[zhutiansama@hadoop102 hadoop]$ xsync hdfs-site.xml
(4)重繪NameNode
[zhutiansama@hadoop102 hadoop-2.7.2]$ hdfs dfsadmin -refreshNodes
(5)更新ResourceManager節點
[zhutiansama@hadoop102 hadoop-2.7.2]$ yarn rmadmin -refreshNodes
(6)在web瀏覽器上查看
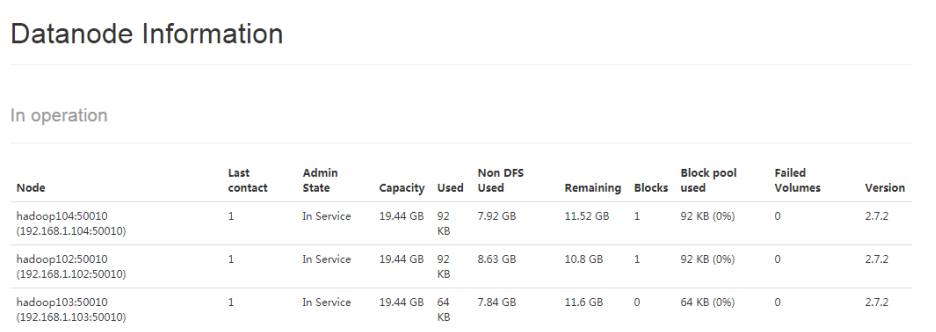
如果資料不平衡可以再使用start-balancer.sh命令
退役舊資料節點【黑名單】
操作同上,只是將白名單檔案換位黑名單檔案dfs.hosts.exclude
在黑名單上的主機都會被踢出集群
Datanode多目錄配置
這個多目錄不是副本的意思,是表明你不想要把所有資料都放在一個目錄下罷了
具體配置如下hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2</value>
</property>
相關資料

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/147636.html
標籤:Java