接下來我們將在爬蟲主體檔案中對Item的值進行填充,
1、首先在爬蟲主體檔案中將Item模塊匯入進來,如下圖所示,
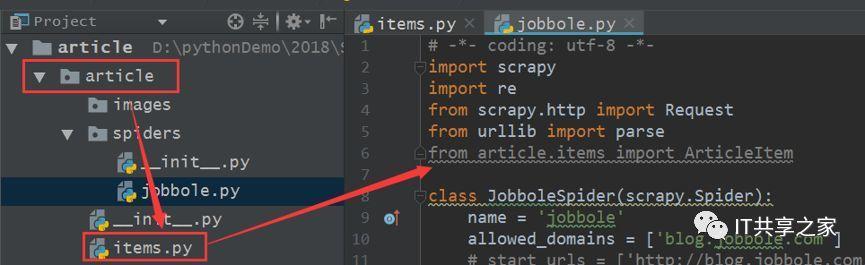
2、第一步的意思是說將items.py中的ArticleItem類匯入到爬蟲主體檔案中去,將兩個檔案串聯起來,其中items.py的部分內容如下圖所示,
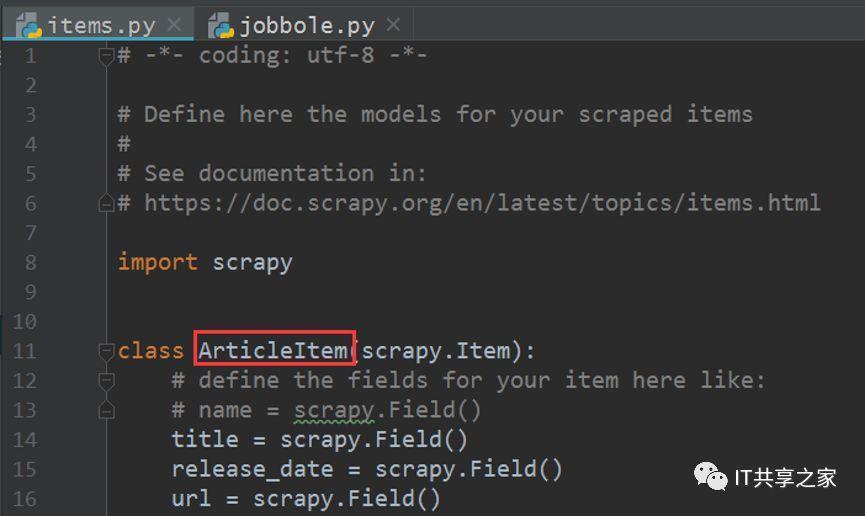
3、將這個ArticleItem類匯入之后,接下來我們就可以對這個類進行初始化,并對其進行相應值的填充,首先去parse_detail函式下對其進行實體化,實體化的方法也十分簡單,如下圖所示,
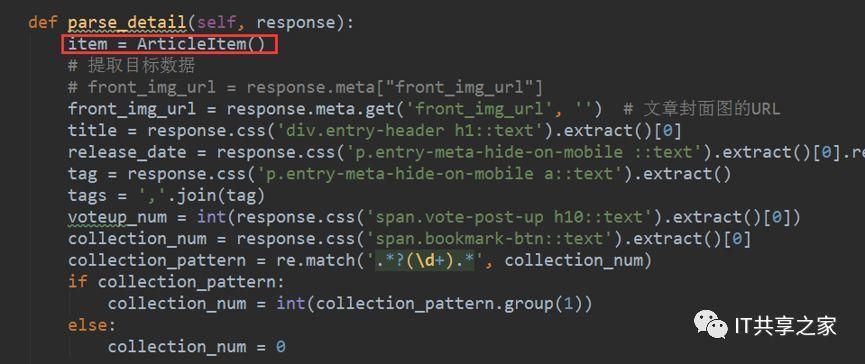
4、接下來,我們將填充對應的值,實際上我們在之前通過Xpath或者CSS選擇器已經獲取到了目標資料,如下圖所示,現在要做的就是依次填充目標欄位的值,
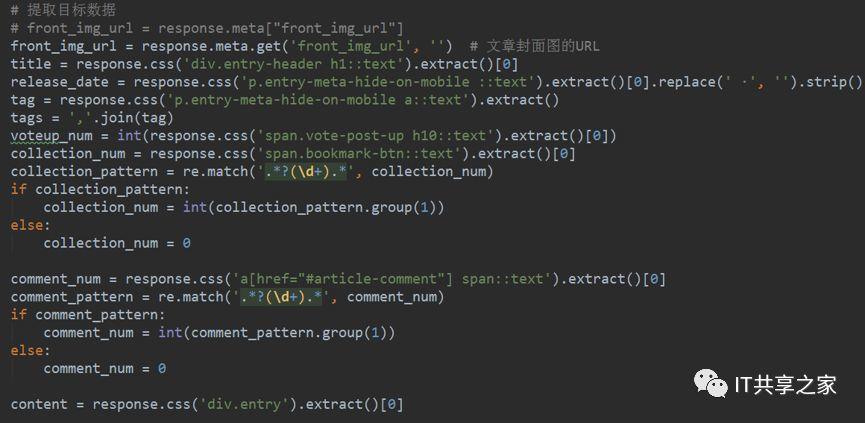
5、我們可以像字典一樣來給目標欄位傳值,例如item[“title”]= title,其他的目標欄位的填充也是形如該格式,填充完成之后如下圖所示,
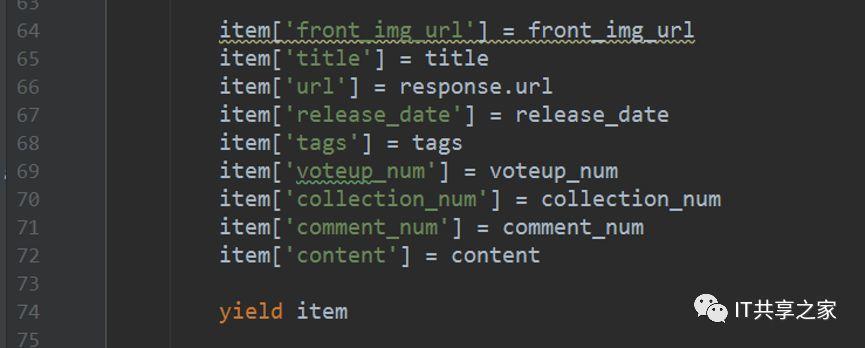
其中,目標欄位可以參考items.py中定義的item,這樣可以加快填充的速度,
6、到這里,我們已經將需要填充的欄位全部填充完成了,之后我們需要呼叫yield,這點十分重要,再呼叫yield之后,實體化后的item就會自動傳遞到pipeline當中去,可以看到下圖中的pipelines.py中默認給出的代碼,說明pipeline其實是可以接收item的,
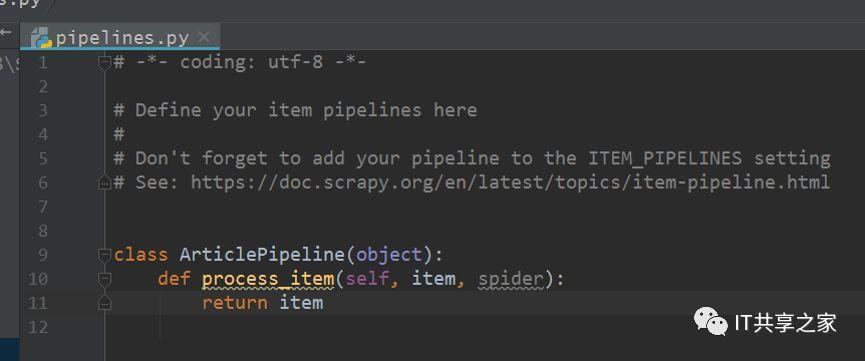
7、到這里,關于實體化item的步驟就已經完成了,是不是比較簡單呢?我們后面把pipeline配置起來,一步一步的將Scrapy串起來,
看完本文有識訓?請轉發分享給更多的人
IT共享之家
入群請在微信后臺回復【入群】

想學習更多Python網路爬蟲與資料挖掘知識,可前往專業網站:http://pdcfighting.com/
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/148123.html
標籤:Python