1.資料結構
資料結構:互相之間存在著一種或者多種關系的資料元素的集合和該集合中資料元素之間關系的組成.
簡單說:資料結構就是設計資料以何種方式組織并存盤在計算機中.(串列,字典,集合,都是一種資料結構)
資料結構分類:
①線性結構:
資料結構中的元素存在一對一的相互關系
②樹結構:
資料結構中的元素存在一對多的相互關系
③圖結構:
資料結構中的元素存在多對多的相互關系
2.串列(python)
注意:32位機器一個整數占4個位元組,一個記憶體地址也是占4個位元組
python時間復雜度
pop:O(1)
append:O(1)
indert:O(n)插入一個得把其他的先挪走,再插入
remove:O(n) 刪一個得把其他的挪過來
陣列與串列的不同:
1.一個陣列內的元素型別要相同,串列可以不同(陣列搜索時時間復雜度是O(1),他要確保每個元素固定長度才能直接取),陣列存的是具體的值,串列存的是地址
2.陣列長度固定,串列長度不固定,python串列長度不夠時,他會重新開辟一塊記憶體,比原來的長一些,再把原來的內容復制過來
3.堆疊
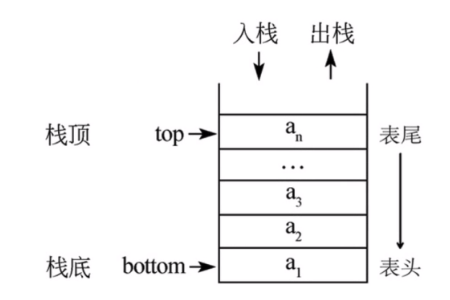
代碼:
#用串列實作堆疊的功能 class Stack: def __init__(self): self.stack = [] def push(self, element): #進堆疊 self.stack.append(element) def pop(self):#出堆疊 if len(self.stack) > 0: return self.stack.pop() else: return None def get_top(self):#取堆疊頂 if len(self.stack) > 0: return self.stack[-1] else: return None def is_empty(self): #判斷堆疊是不是空的 return len(self.stack) == 0 stack=Stack() print(stack.push(1)) print(stack.get_top()) print(stack.pop()) print(stack.pop())
堆疊的應用:
判斷括號匹配問題:
給你一些括號(小括號,中括號,大括號),看看格式是不是對的
#堆疊的應用: # 思路:遇到左括號就往堆疊里添加,遇到右括號就取出(但是左右括號要是一對才行) # 這里只判斷字串里全是括號的情況,如有其他符號或者文字則不適用,需改代碼 class Stack: def __init__(self): self.stack = [] def push(self, element): #進堆疊 self.stack.append(element) def pop(self):#出堆疊 if len(self.stack) > 0: return self.stack.pop() else: return None def get_top(self):#取堆疊頂 if len(self.stack) > 0: return self.stack[-1] else: return None def is_empty(self): #判斷堆疊是不是空的 return len(self.stack) == 0 def brace_match(s): match = {'}':'{', ']':"[", ')':'('} #造字典用右括號直接取左括號 stack = Stack() for ch in s: if ch in {'(','[','{'}: stack.push(ch) else: #ch in {'}',']',')'},此時遇到了右括號 if stack.is_empty(): #如果堆疊里為空,直接來個右括號,那就是不對了 return False elif stack.get_top() == match[ch]:#如果當前堆疊頂存的括號與你遇到的括號匹配,那就把堆疊頂的括號取出,然后繼續匹配下一個 stack.pop() else: # stack.get_top() != match[ch]#如果當前堆疊頂的括號與你遇到的括號不匹配就報錯 return False if stack.is_empty(): return True else: return False print(brace_match('[{()}(){()}[]({}){}]')) print(brace_match('[]}'))
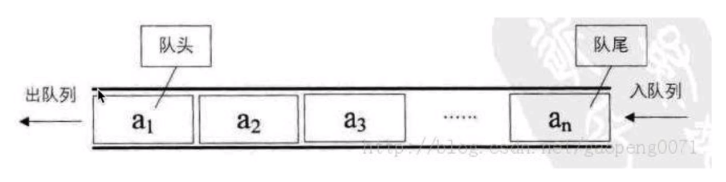
4.佇列
佇列是個資料集合,僅允許在串列的一端進行插入,另一端進行洗掉
隊尾:可以進行插入的一端(插入稱為:進隊/入隊)
隊頭:可以進行洗掉的一端(洗掉動作稱為:出隊)
佇列的性質:先進先出(first-in first-out)FIFO
佇列手動實作方式:環形佇列
不能用串列,因為你要洗掉時(pop(0))操作時間復雜度是o(n)太大了,刪一個其他的要補上來
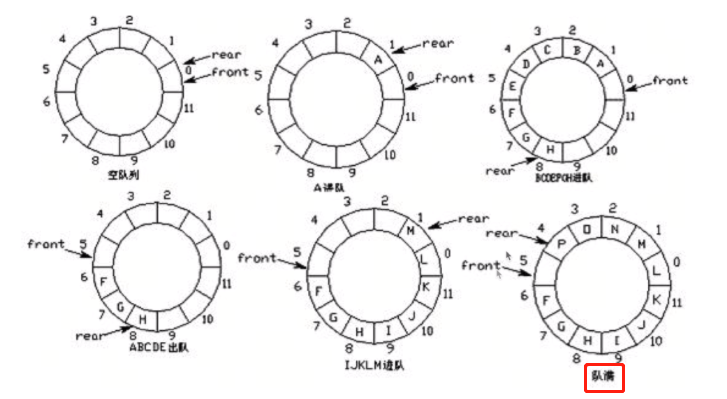
隊首指標:front
隊尾指標:rear
環形佇列總長度為:maxsize(這里是12)
當隊尾指標rear=maxsize-1時(這時rear=11)再向前一步就到了0
此時可以用%maxsize的方法取余數,就知道在佇列的哪個位置了
隊首指標前進1:front=(front+1)%maxsize
隊尾指標前進1:rear=(rear+1)%maxsize
隊空:其實就是隊首和隊尾相等,rear=front
隊滿:其實就是front比rear大1,(rear+1)%12=front
class Queue: def __init__(self, size=100): self.queue = [0 for _ in range(size)] self.size = size self.rear = 0 # 隊尾指標 self.front = 0 # 隊首指標 def push(self, element):#入隊 if not self.is_filled(): self.rear = (self.rear + 1) % self.size self.queue[self.rear] = element else: raise IndexError("Queue is filled.") def pop(self):#出隊 if not self.is_empty(): self.front = (self.front + 1) % self.size return self.queue[self.front] else: raise IndexError("Queue is empty.") # 判斷隊空 def is_empty(self): return self.rear == self.front # 判斷隊滿 def is_filled(self): return (self.rear + 1) % self.size == self.front q = Queue(51) #長度為51的佇列,只能容納50個數字,因為自己設定的,隊首和隊尾之間要保持一個空格,否則無法判斷是慷訓是滿 for i in range(50): q.push(i) print(q.pop()) print(q.pop()) print(q.pop()) print(q.pop()) q.push(4)
雙向佇列(python內置模塊deque)
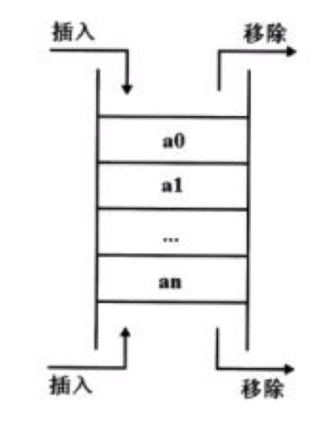
兩端都支持進隊和出隊的佇列
參考模塊:
from collections import deque
創建佇列:
queue=deque()
隊尾進隊:append()
隊首出隊:popleft()
雙向佇列隊首進隊:appendleft()
雙向佇列隊尾出隊:pop()
代碼:
from collections import deque # q = deque()#建空佇列 q = deque([1,2,3,4,5], 5) #第一個引數,建佇列,里面傳5個值(1,2,3,4,5),第二個引數5,表示佇列長度, # 如果超了,再入隊就會把隊首的值踢出去,如果是從隊首添加,就會將隊尾的值踢出去 q.append(6) # 隊尾進隊 print(q.popleft()) # 隊首出隊 # 用于雙向佇列 # q.appendleft(1) # 隊首進隊 # print(q.pop()) # 隊尾出隊
小應用:利用佇列讀取檔案最后n行內容,類似linux的tail命令
def tail(n): with open('test.txt', 'r') as f: q = deque(f, n) #直接一行一行讀,你取幾行,我就建多長的佇列,讀到最后佇列里就剩最后那幾行 return q for line in tail(5): print(line, end='')
迷宮問題:
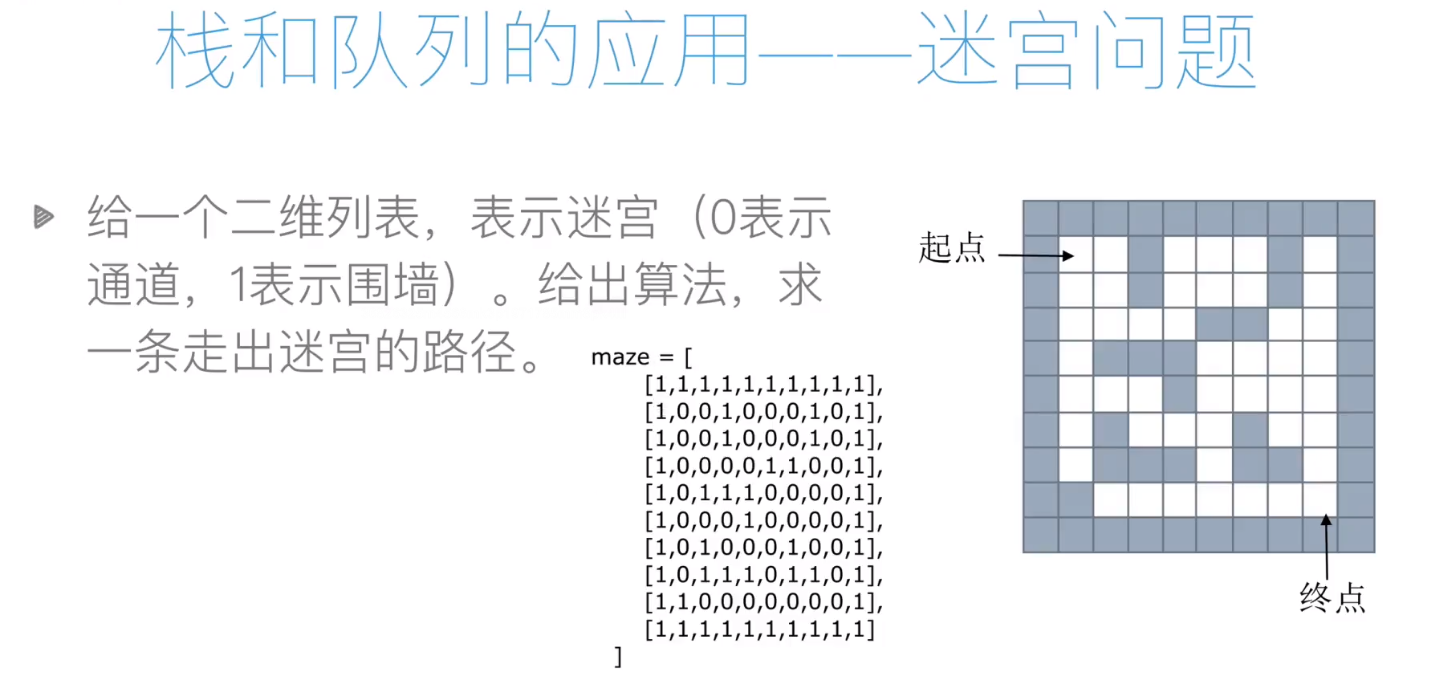
用堆疊來實作:
回溯法(深度優先法):起點開始每一點都從上右下左這四個方向試,能走就走,一條道走到黑,如果不行了,就原路回傳,一個一個退,直到有叉路可以走就不退了,繼續走.
走過的路徑用堆疊來存盤.
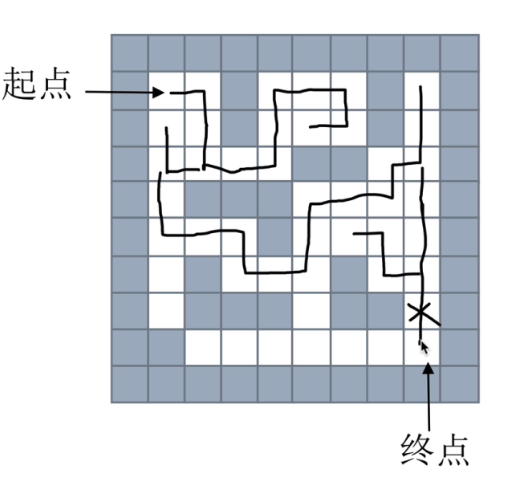
代碼:這種并不是最優的方法,只能找到一種,但是不一定是最短的路徑
maze = [ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 0, 0, 1, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 0, 0, 0, 1], [1, 0, 0, 0, 1, 0, 0, 0, 0, 1], [1, 0, 1, 0, 0, 0, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 1, 1, 0, 1], [1, 1, 0, 0, 0, 0, 0, 0, 0, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1] ] dirs = [ lambda x,y: (x+1,y),#下 lambda x,y: (x-1,y),#上 lambda x,y: (x,y-1),#左 lambda x,y: (x,y+1) #右 ] def maze_path(x1,y1,x2,y2):#x1,y1是起點位置,x2,y2是終點位置 stack = [] stack.append((x1, y1))#起點坐標,串列存了個元組 while(len(stack)>0):#堆疊如果空了那么就認為是沒有方法了,所有路都堵死了(注意:如果沒有路可走,他就會退一格) curNode = stack[-1] # 當前的節點 if curNode[0] == x2 and curNode[1] == y2: # 走到終點了 for p in stack: print(p) return True # x,y 四個方向 上:x-1,y;下 x+1,y;左: x,y-1;右: x,y+1 for dir in dirs: nextNode = dir(curNode[0], curNode[1])#找下一個能走的節點 # 如果下一個節點能走 if maze[nextNode[0]][nextNode[1]] == 0:#0是路,1是墻 stack.append(nextNode) maze[nextNode[0]][nextNode[1]] = 2 # 2表示為已經走過 break else: maze[nextNode[0]][nextNode[1]] = 2 stack.pop() else: print("沒有路") return False maze_path(1,1,8,8)
用佇列實作:
佇列:廣度優先,
思路:起始點開始走,與到分岔路,所有的岔路同時一起走,直到有一條路先到了重點,這條路一定是最近的,
代碼:
from collections import deque maze = [ [1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 1, 0, 0, 0, 1, 0, 1], [1, 0, 0, 0, 0, 1, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 0, 0, 0, 1], [1, 0, 0, 0, 1, 0, 0, 0, 0, 1], [1, 0, 1, 0, 0, 0, 1, 0, 0, 1], [1, 0, 1, 1, 1, 0, 1, 1, 0, 1], [1, 1, 0, 0, 0, 0, 0, 0, 0, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1] ] dirs = [ lambda x, y: (x + 1, y), lambda x, y: (x - 1, y), lambda x, y: (x, y - 1), lambda x, y: (x, y + 1) ] def print_r(path):#將你走過的路徑列印出來 curNode = path[-1] realpath = []#存的是真實的路徑 while curNode[2] != -1: realpath.append(curNode[0:2])#取節點0和1兩個位置的坐標,不要最后2索引上的內容 curNode = path[curNode[2]] realpath.append(curNode[0:2]) # 起點 realpath.reverse()#倒序列印,就是從起點開始 for node in realpath: print(node) def maze_path_queue(x1, y1, x2, y2): queue = deque() queue.append((x1, y1, -1))#存的是x和y的值和帶這個點進來的點的坐標(索引), # 第一個點默認就是-1坐標帶他進來的,不是串列的最后一個,而是串列最左側再出去一個的位置上 path = [] while len(queue) > 0: curNode = queue.popleft()#將佇列頭部的點彈出去,而不是結尾剛進來的點彈出去 path.append(curNode) if curNode[0] == x2 and curNode[1] == y2: # 此時到了終點 print_r(path) return True for dir in dirs:#回圈dirs,找當前這個點的四個方向是否有能前進的點 nextNode = dir(curNode[0], curNode[1]) if maze[nextNode[0]][nextNode[1]] == 0:#如果該點能前進,那么就把該點加到佇列中去 queue.append((nextNode[0], nextNode[1], len(path) - 1)) # 后續節點進隊,記錄哪個節點帶他來的 maze[nextNode[0]][nextNode[1]] = 2 # 標記為已經走過 else: print("沒有路") return False maze_path_queue(1, 1, 8, 8)#注意每一行或者每一列都是從0開始的
5.鏈表
鏈表是一系列節點組成的元素集合,每個節點包含兩部分,資料域item和指向下一個節點的指標next,通過節點之間的互相連接,最終串連成一個鏈表,

創建鏈表有兩種方法:頭插法,尾插法
頭插法:
# 頭插法 class Node:#鏈表的類 def __init__(self,item): self.item=item self.next=None def create_linklist(li):#在head前面創建新的節點 head=Node(li[0]) for element in li[1:]: node =Node(element) node.next=head head=node return head def print_linklist(lk):#列印整個鏈表 while lk: print(lk.item,end=',') lk=lk.next lk=create_linklist([1,2,3,4]) print_linklist(lk)
尾插法:
# 尾插法 class Node:#鏈表的類 def __init__(self,item): self.item=item self.next=None def create_linklist_tail(li): head=Node(li[0]) tail=head #就一個元素,既是head,又是tail for element in li[1:]: node =Node(element) tail.next=node tail=node #結尾tail就指向自己剛建的這個節點 return head def print_linklist(lk):#列印整個鏈表 while lk: print(lk.item,end=',') lk=lk.next lk=create_linklist_tail([1,2,3,4,7,8,9]) print_linklist(lk)
完整鏈表代碼:
class LinkList:#鏈表類(支持for回圈,插入和查找節點) class Node:#鏈表里的節點 def __init__(self,item=None): self.item=item self.next=None class LinkListIterator: #迭代器,支持for回圈(因為這個類有next方法) def __init__(self,node): #傳進來的頭節點,先定義一個node self.node=node def __next__(self): if self.node: #如果node不是空 cur_node=self.node self.node=cur_node.next return cur_node.item else: raise StopIteration def __iter__(self): return self def __init__(self,iterable=None):#傳個串列進來 self.head=None #頭節點 self.tail=None #尾節點 if iterable: #如果有串列傳進來 self.extend(iterable) def append(self,obj): #尾插法 s=LinkList.Node(obj) #做出個節點 if not self.head: #如果head為空 self.head=s self.tail=s else: #如果head不是空 self.tail.next=s self.tail=s def extend(self,iterable): #傳進來串列,插到鏈表后面 for obj in iterable: self.append(obj) #將傳進來的串列一個一個加到原來的鏈表后面 def find(self,obj):#查詢某個節點是否存在 for n in self: if n==obj: return True else: return False def __iter__(self):#寫迭代器,讓鏈表支持for回圈 return self.LinkListIterator(self.head) #把頭節點傳進去 def __repr__(self):#轉換成字串列印出來 return '<<' + ','.join(map(str,self))+'>>' #join-->把self里面每個元素都用逗號隔開 # return '<<' + ','.join(self) + '>>' 如果寫成這樣會報錯,因為self里面全是int型別, # 而join要str型別,所以上面用map把self每一個元素都轉成str型別,并且map自身就可以迭代 lk=LinkList([1,2,3,4,5,6]) print(lk) # 輸出:<<1,2,3,4,5,6>> for i in lk: print(i) # 輸出:1,2,3,4,5,6 print(lk.find(4)) #True print(lk.find(7)) #False
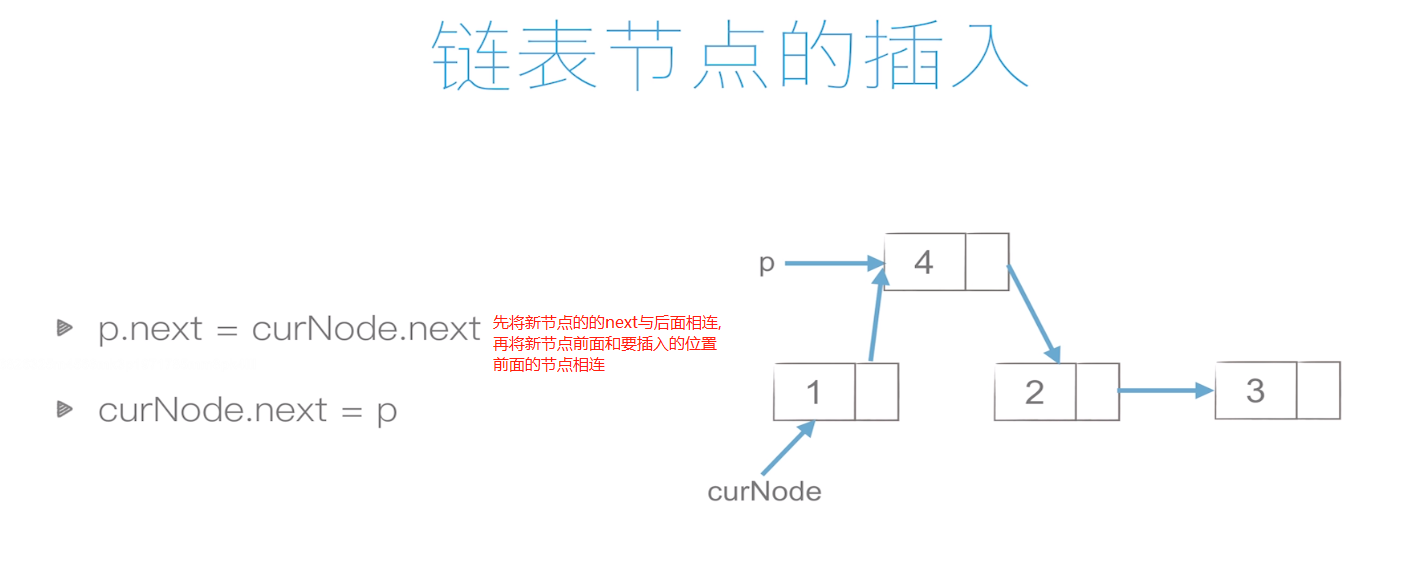
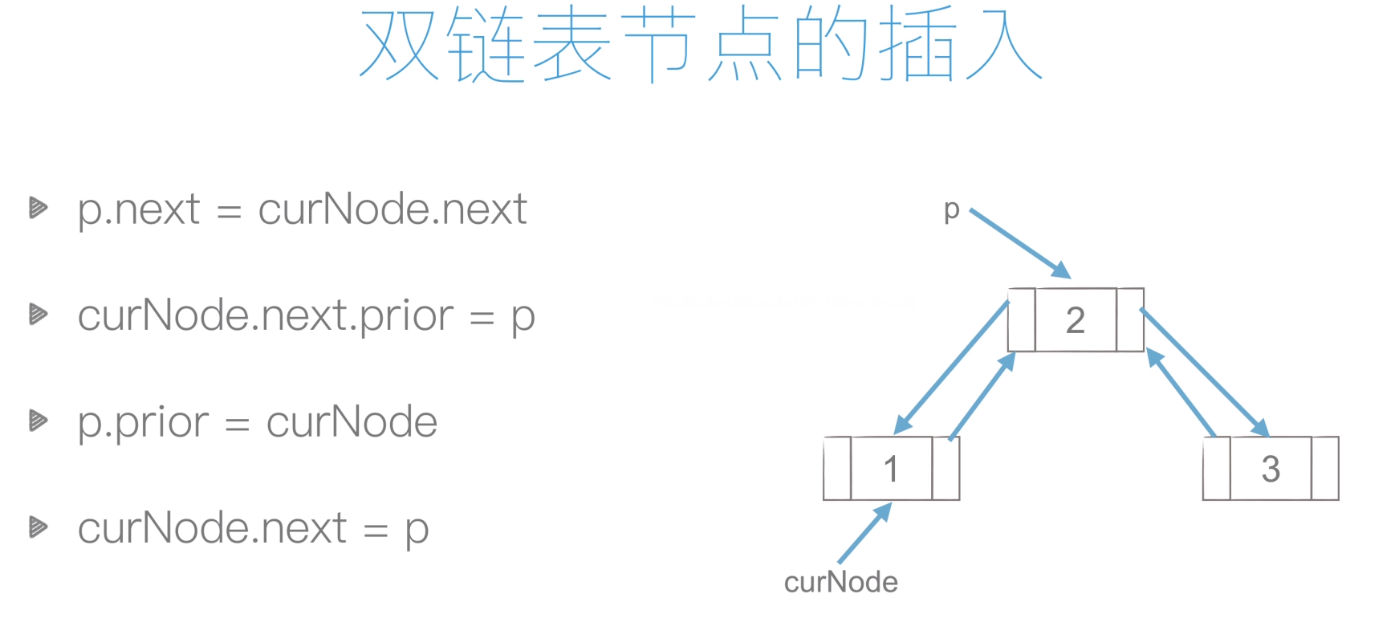
鏈表的插入:
復雜度:O(1)
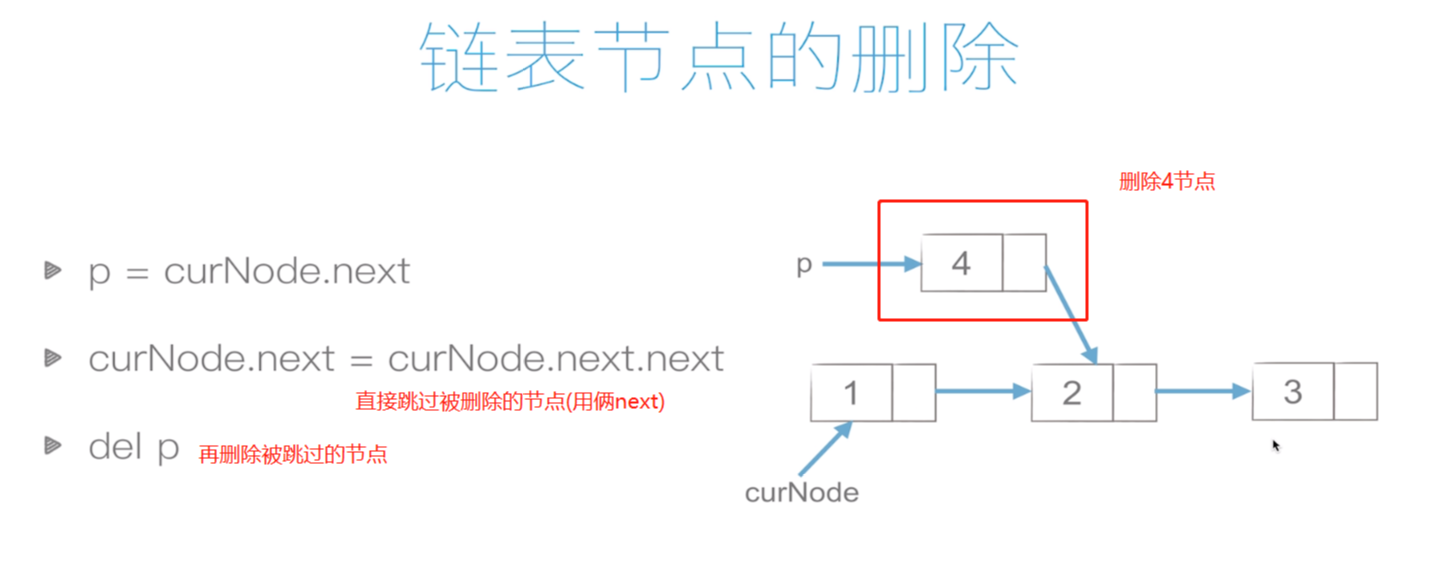
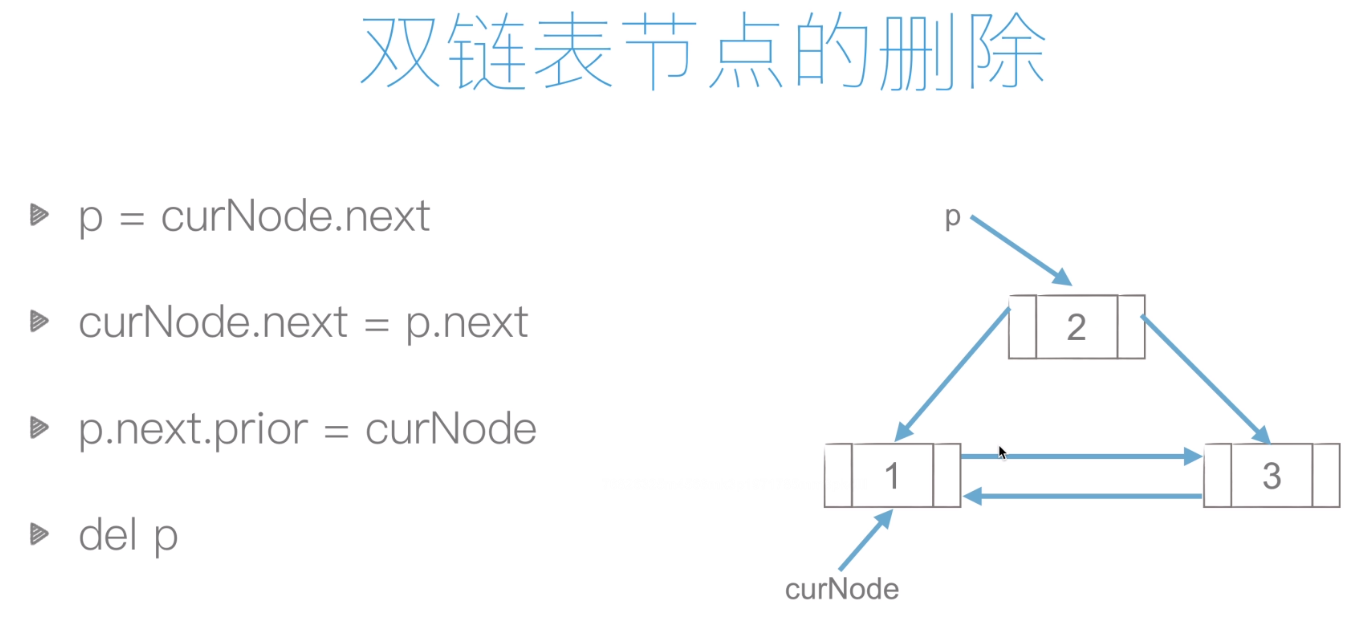
鏈表的洗掉:
復雜度:O(1)
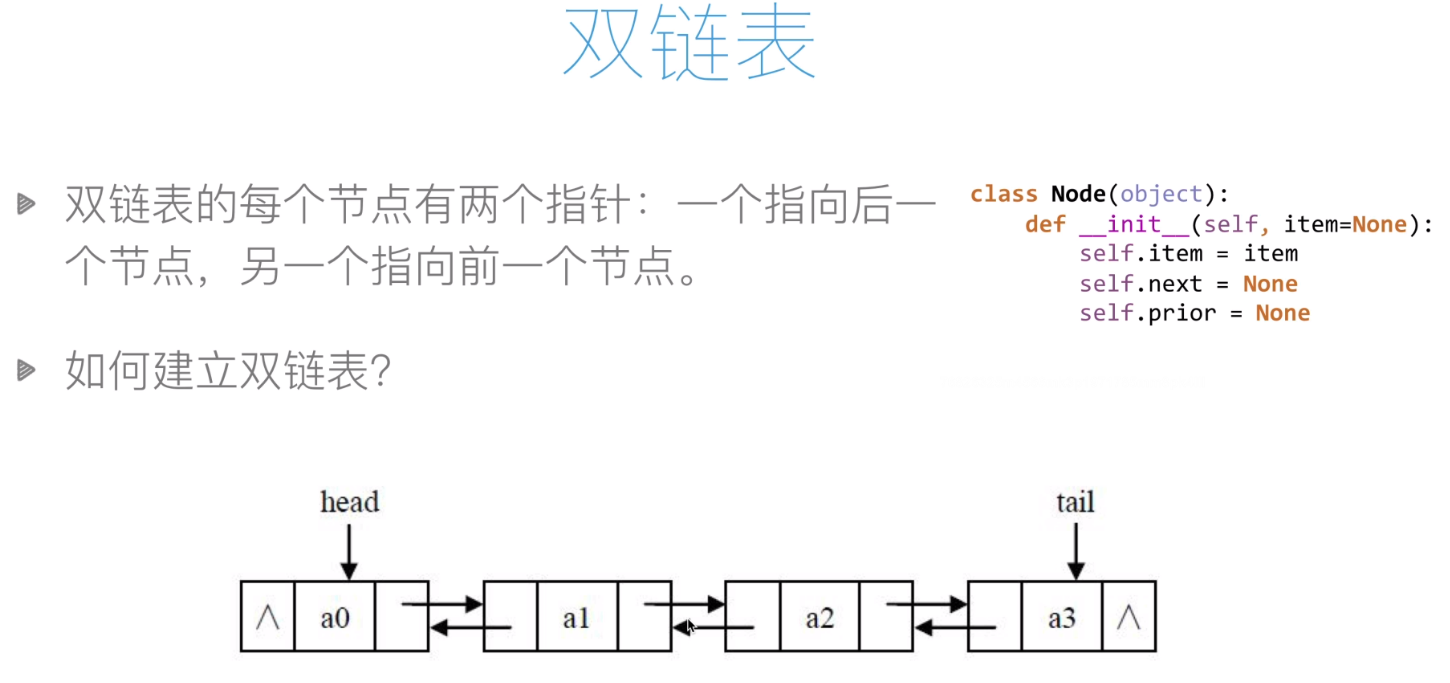
雙向鏈表:
插入:
洗掉:
6.哈希表:
哈希表又叫散串列,是一種線性表的存盤結構,
python中的字典和集合都是通過它來實作的,
哈希表是通過哈希函式來計算資料存盤位置的資料結構,
哈希表是由一個直接尋址表和一個哈希函式組成,
哈希函式h(k)將元素關鍵字k作為自變數,回傳元素的存盤下標,
一般來說會支持:
①insert(key,value):插入鍵值對(key,value).
②get(key):如果存在鍵為key的鍵值對則回傳其value,否則回傳空值.
③delete(key):洗掉鍵為key的鍵值對.

哈希沖突:
由于哈希表的大小是有限的,而要存盤的值的總數量是無限的,因此對于任何哈希函式,都會出現兩個不同元素映射到同一個位置上的情況,這種情況叫做哈希沖突,

解決哈希沖突:
一、開放尋址法(不推薦):
如果哈希函式回傳的位置已經有值,那就向后找新的空的位置來存放這個值,
①線性探查:如果位置m被占用,那就找m+1,m+2...
②二次勘探:如果位置m被占用,那就找m+12,m-12,m+22,m-22...
③二度哈希:有n個哈希函式,當第一個哈希函式h1發生沖突,就使用h2哈希函式,h3,h4...直到沒沖突為止
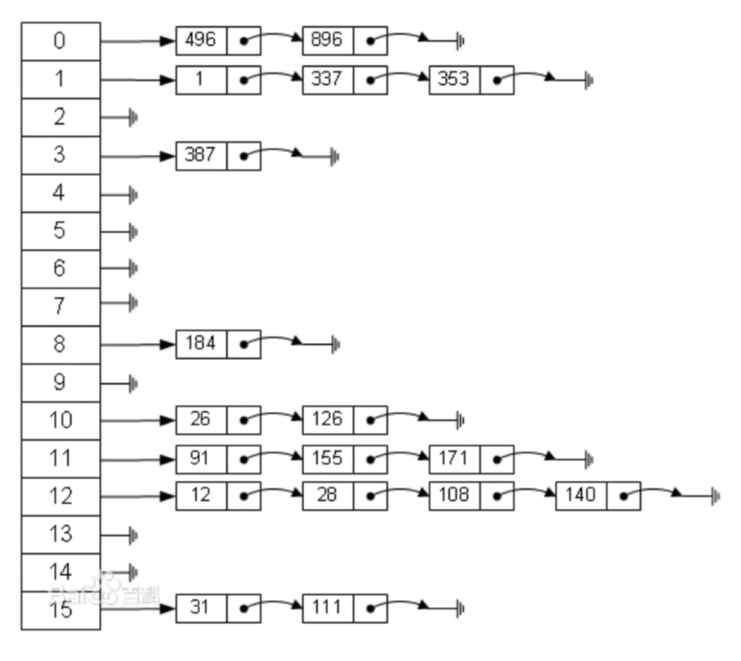
二、拉鏈法:
哈希表每個位置都連接一個鏈表,當發生沖突時,沖突的元素將被加到該位置鏈表的最后,
如圖:
常見的哈希函式:
①除法哈希(比較常見):
h(k)=k%m (m是哈希表的長度)
②乘法哈希:
h(k)=floor(m*(A*key%1)) (floor向下取整,不會四舍五入,A是個小數,%1就是取整)
③全域哈希法:
ha,b(k)=((a*key) % p) % m (a,b=1,2,3,4,5….p-1) a和b是倆常數
用哈希表寫個集合:
#集合:這里的功能有增和查,沒有洗掉 class LinkList:#鏈表類 class Node:#鏈表里的節點 def __init__(self,item=None): self.item=item self.next=None class LinkListIterator: #迭代器,支持for回圈(因為這個類有next方法) def __init__(self,node): #傳進來的頭節點,先定義一個node self.node=node def __next__(self): if self.node: #如果node不是空 cur_node=self.node self.node=cur_node.next return cur_node.item else: raise StopIteration def __iter__(self): return self def __init__(self,iterable=None):#傳個串列進來 self.head=None #頭節點 self.tail=None #尾節點 if iterable: #如果有串列傳進來 self.extend(iterable) def append(self,obj): #尾插法 s=LinkList.Node(obj) #做出個節點 if not self.head: #如果head為空 self.head=s self.tail=s else: #如果head不是空 self.tail.next=s self.tail=s def extend(self,iterable): #傳進來串列,插到鏈表后面 for obj in iterable: self.append(obj) #將傳進來的串列一個一個加到原來的鏈表后面 def find(self,obj):#查詢某個節點是否存在 for n in self: if n==obj: return True else: return False def __iter__(self):#寫迭代器,讓鏈表支持for回圈 return self.LinkListIterator(self.head) #把頭節點傳進去 def __repr__(self):#轉換成字串列印出來 return '<<' + ','.join(map(str,self))+'>>' #join-->把self里面每個元素都用逗號隔開 # return '<<' + ','.join(self) + '>>' 如果寫成這樣會報錯,因為self里面全是int型別, # 而join要str型別,所以上面用map把self每一個元素都轉成str型別,并且map自身就可以迭代 class HashTable:#哈希表--類似于集合的結構(內容不重復) def __init__(self,size=101):#建哈希表時,一起建鏈表(多個)放在每個索引的后面用來存值 self.size=size #size就是哈希表長度 self.T=[ LinkList() for i in range(self.size)] #LinkList()新建空鏈表,哈希表多長,就在里面新建多少個空鏈表 def h(self,k):#呼叫哈希函式,回傳的是哈希表的索引 return k% self.size def find(self,k):#查找 i = self.h(k) return self.T[i].find(k)#這個find呼叫的是LinkList里面的find, # 而不是遞回一直呼叫自己的find,這里回傳True或者False def insert(self,k):#插入 i=self.h(k) if self.find(k):#如果里面找到了,那就不插入,這是集合 print("Duplicated Insert(表中存在,重復插入)") #重復插入 else: #如果沒找到,那就插入進去 self.T[i].append(k) ht=HashTable() ht.insert(0) ht.insert(1) ht.insert(4) ht.insert(102)#1和102都在一個鏈表中 # ht.insert(0)#會告訴你重復插入 print(','.join(map(str,ht.T)))#列印一下整個哈希表 # 輸出:<<0>>,<<1,102>>,<<>>,<<>>,<<4>>,<<>>,一共101個<<>>, # 每個<<>>都是一個鏈表,加起來就是整個哈希表 print(ht.find(102)) #True print(ht.find(6)) #False
哈希表應用:
①字典和集合
python中字典和集合用的是哈希表,他的查詢要比串列速度快
字典的鍵映射成哈希表的下標(某種方法,將字串變成數字用到下標上),而字典的值就存在哈希表中,這樣查鍵就能找到值了
如果發生哈希沖突,就用拉鏈法或者開放尋址方法解決.
②md5
(128位,已經被清華的一個老師破解了)現在安全較重要的場合不要用md5加密

③檔案的哈希值

④SHA2演算法

⑤位元幣

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/148774.html
標籤:Python