不斷關聯,不斷加入,不斷迭代,不斷應用
HDFS資料讀寫流程
HDFS寫資料流程

- 客戶端通過Distributed FileSystem模塊向NameNode請求上傳檔案,NameNode檢查目標檔案是否已存在,父目錄是否存在,
- NameNode回傳是否可以上傳,
- 客戶端請求第一個 Block上傳到哪幾個DataNode服務器上,
- NameNode回傳3個DataNode節點,分別為dn1、dn2、dn3,
- 客戶端通過FSDataOutputStream模塊請求dn1上傳資料,dn1收到請求會繼續呼叫dn2,然后dn2呼叫dn3,將這個通信管道建立完成,
- dn1、dn2、dn3逐級應答客戶端,
- 客戶端開始往dn1上傳第一個Block(先從磁盤讀取資料放到一個本地記憶體快取),以Packet為單位,dn1收到一個Packet就會傳給dn2,dn2傳給dn3;dn1每傳一個packet會放入一個應答佇列等待應答,
- 當一個Block傳輸完成之后,客戶端再次請求NameNode上傳第二個Block的服務器,(重復執行3-7步),
NameNode:可以理解為DataNode管理器
DataNode:存盤塊資料,默認128M為一塊
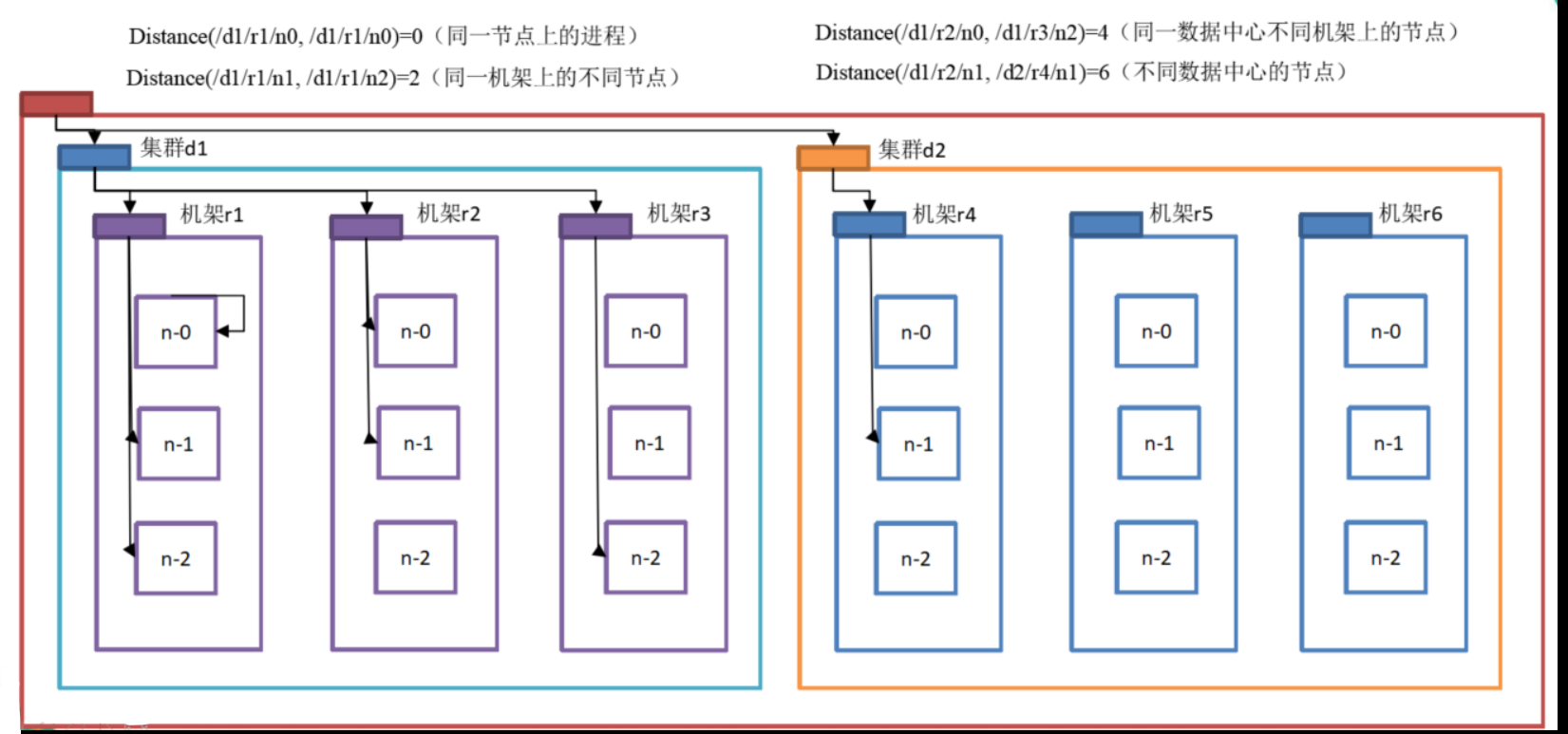
網路拓撲-節點距離計算
? 在HDFS寫資料的程序中,NameNode會選擇距離待上傳資料最近距離的DataNode接收資料,那么這個最近距離怎么計算呢?
節點距離:兩個節點到達最近的共同祖先的距離總和,
不好理解的就是共同祖先啥意思,可以理解為上級節點,節點等級如下
【資料中心(集群d)---> 機架r ---> 具體節點n】
舉個例子:計算節點d1/r1/n1到節點d1/r1/n2的節點距離
確認共同祖先為r1,節點n1到它的距離為1,節點n2到它的距離也為1,兩者和為2
所以它們之間的節點距離就是2
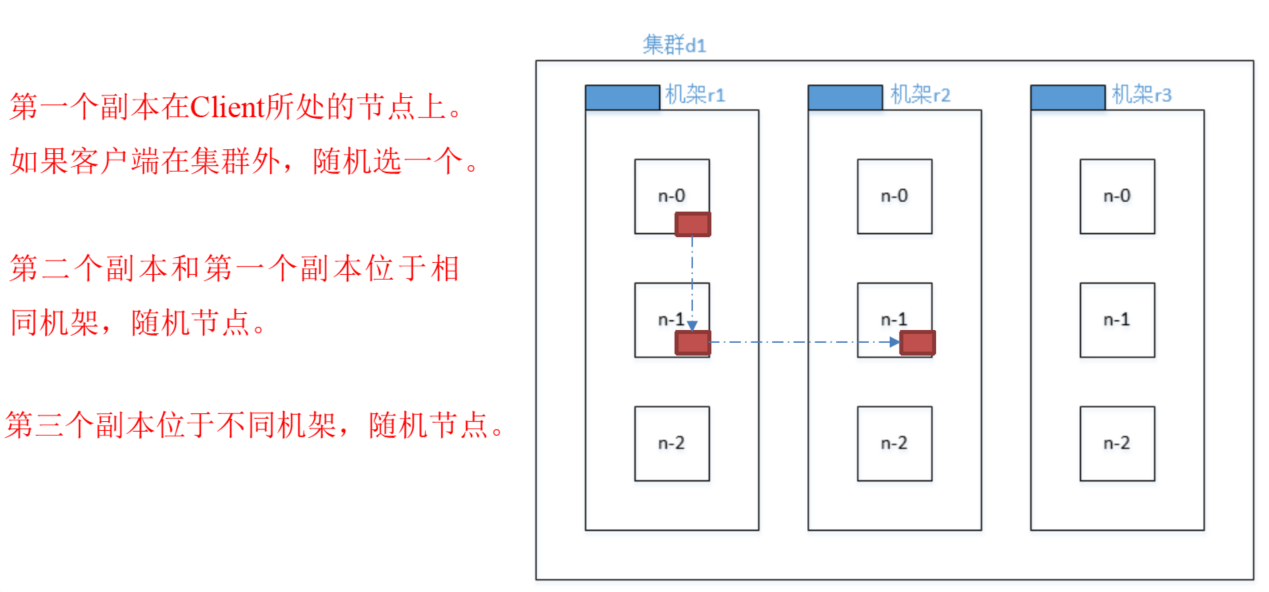
機架感知
機架感知說明
http://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
其實機架感知聽起來高大上,但可以理解為副本節點的位置的選擇就行
HDFS讀資料流程
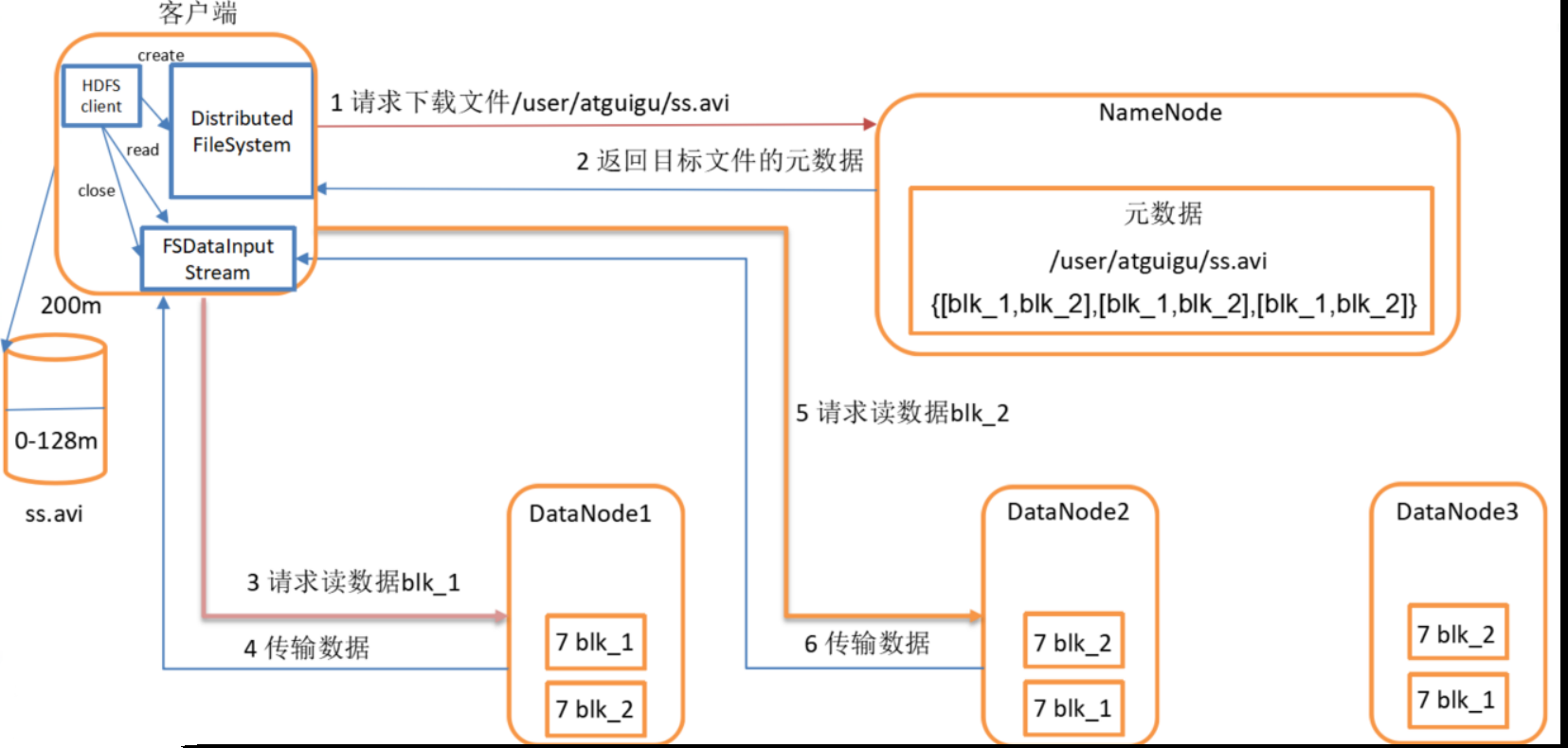
- 客戶端通過Distributed FileSystem向NameNode請求下載檔案,NameNode通過查詢元資料,找到檔案塊所在的DataNode地址,
- 挑選一臺DataNode(就近原則,然后隨機)服務器,請求讀取資料,
- DataNode開始傳輸資料給客戶端(從磁盤里面讀取資料輸入流,以Packet為單位來做校驗),
- 客戶端以Packet為單位接收,先在本地快取,然后寫入目標檔案,
相關資料
本文配套GitHub:https://github.com/zhutiansama/FocusBigData
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/149776.html
標籤:Java