需要準備的環境:
(1)python3.8
(2)pycharm
(3)截取網路請求資訊的工具,有很多,百度一種隨便用即可,
第一:首先通過python的sqlalchemy模塊,來新建一個表,
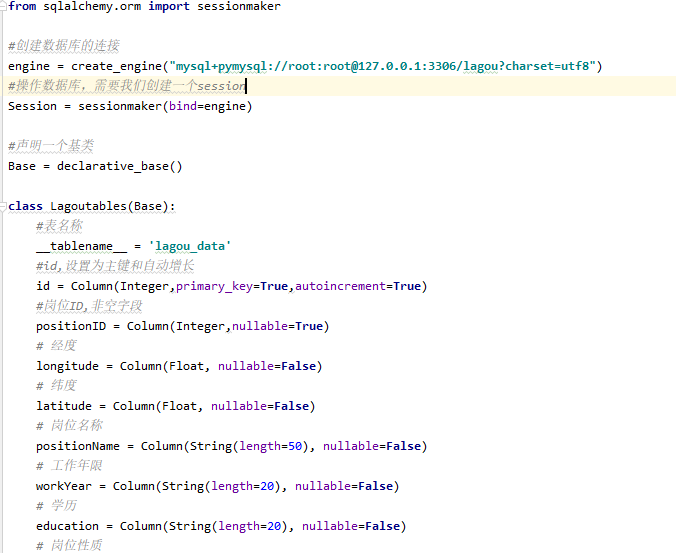
第二:通過python中的request模塊介面的形式調取資料,
思路:(1)先獲取所有城市資訊:需要用request模塊中的【requests.session()】session物件保存訪問介面需要用到的資訊:例如cookies等資訊,
(2)通過城市分組,再用正則運算式篩選來獲取python的崗位資訊,
其中多次用到串列生成器,以后要多注意這方面的冷知識;不然會有莫名的錯誤,、
代碼思路:只要保證可復用即可,其實很簡單,畢竟Python是一門”干凈“的語言,
(1)先把請求方法抽集到一個方法中:
session.get(url(地址),headers(頭資訊),,timeout(時間),proxies(代理資訊))
(2)先獲取所有城市,利用串列生成器生成一個list把資料裝進去,
(3)利用回圈以城市分組拉去Python崗位資訊,
for city in lagou.city_list:
呼叫拉取崗位資訊的方法,
(4)匯入multiprocessing模塊,設定多執行緒加速抓取:multiprocessing.Pool(自定 int or long)
需要注意的是:必須利用代理,以及多執行緒拉取,否則效率低下,可能導致資訊不全,時間太慢,

第三:將拉取的資料存入表中
思路:(1)由于拉取的是JSON格式,所以解讀JSON格式,也是很繁瑣的,需要把要的資料一條一條對應到固定的Key里,如圖:
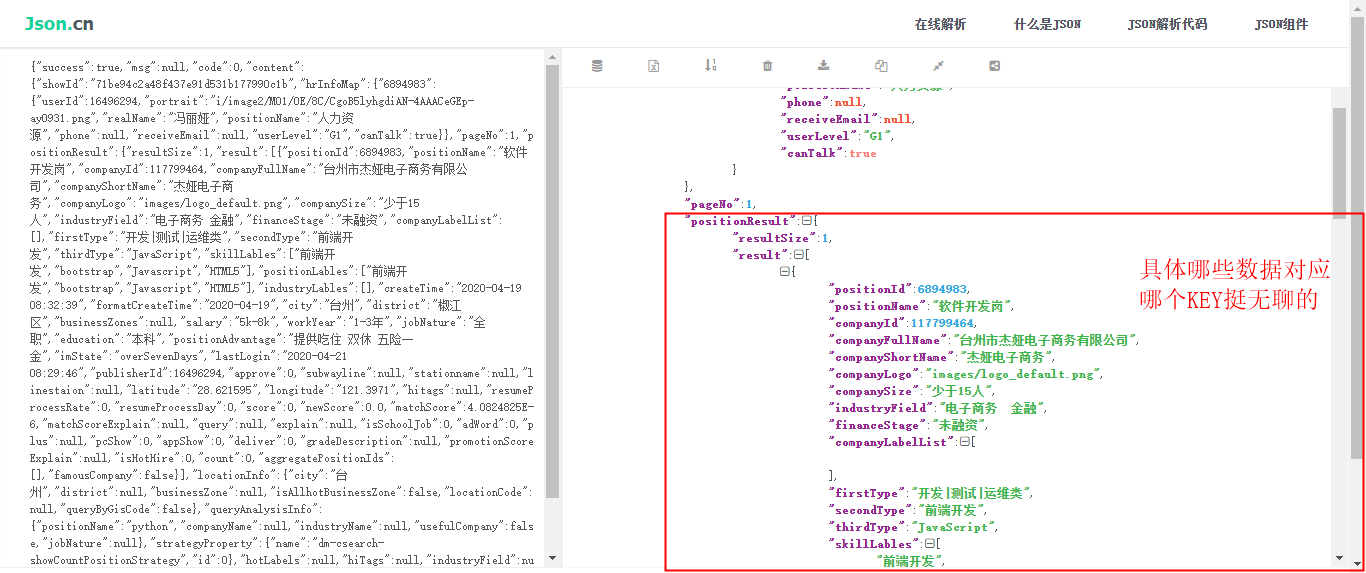
(2)利用session物件的query方法,可以過濾查詢想要的資料, session.query(Lagoutables.workYear).filter(Lagoutables.crawl_date==self.date).all()
第四:利用前臺模板,將資料可視化,
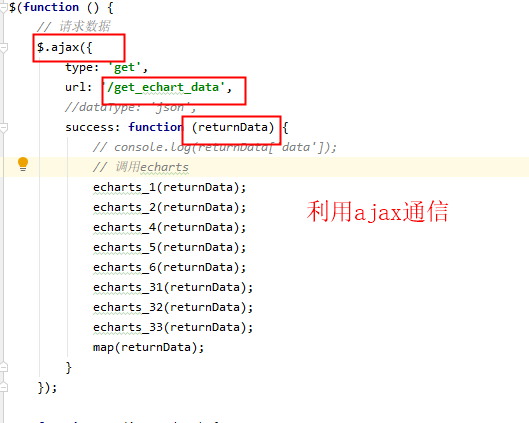
(1)首先需要通過撰寫JS檔案,將幾個圖的資料放在一個方法里提高聚合,抽取出來提高可復用性, (2)然后通過拼接把獲取到的JSON格式的資料,按key:balue格式分配出來, 代碼如下: 利用Ajax通信
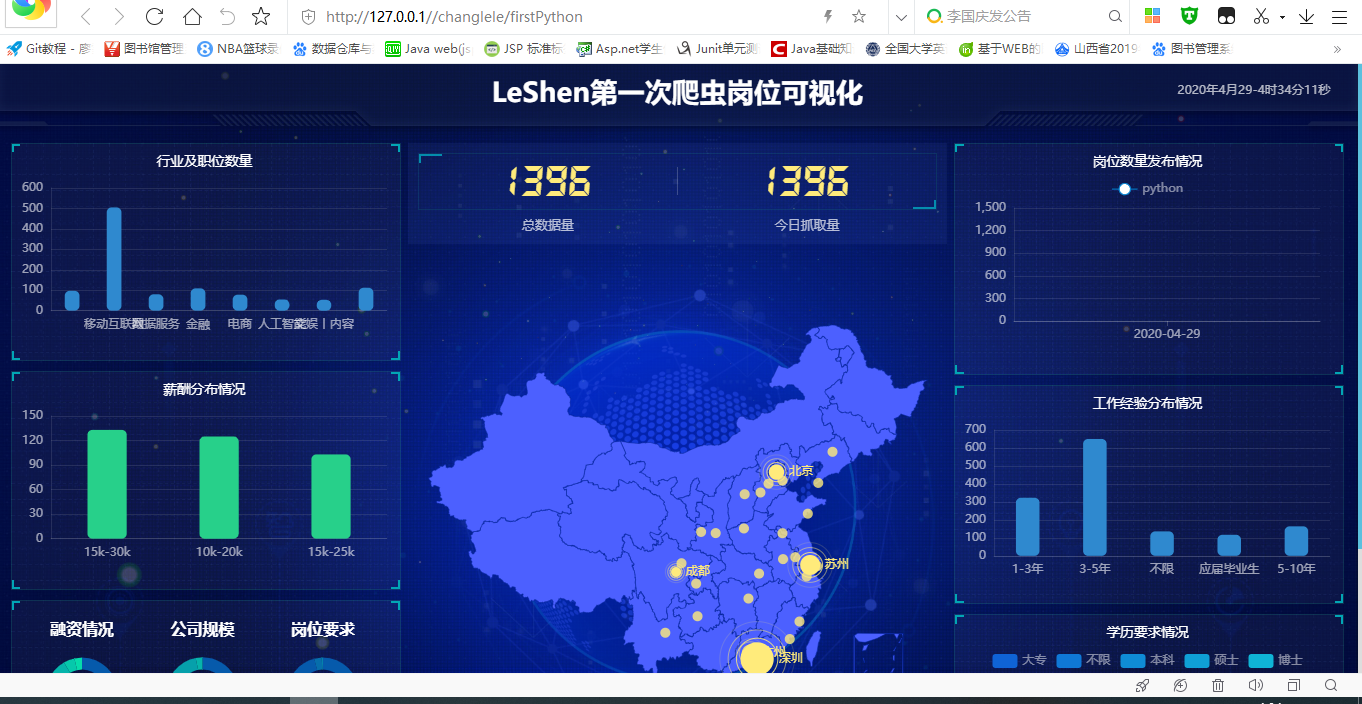
結果展示:
主要代碼展示:
第一部分:拉取資料,
(1)使用session保存cokkies資訊,
self.lagou_session = requests.session()
(2)寫一個request方法;用于請求資料,使用多執行緒,以及代理的方式來;否則會記錄惡意IP,不能爬蟲,
def handle_request(self,method,url,data=https://www.cnblogs.com/leleChang/p/None,info=None):
while True:
#加入阿布云的動態代理
proxyinfo ="http://%s:%s@%s:%s" % ('H1V32R6470A7G90D', 'CD217C660A9143C3', 'http-dyn.abuyun.com', '9020')
proxy = {
"http":proxyinfo,
"https":proxyinfo
}
try:
if method == "GET":
# response = self.lagou_session.get(url=url,headers=self.header,proxies=proxy,timeout=6)
response = self.lagou_session.get(url=url,headers=self.header,timeout=6)
elif method == "POST":
# response = self.lagou_session.post(url=url,headers=self.header,data=https://www.cnblogs.com/leleChang/p/data,proxies=proxy,timeout=6)
response = self.lagou_session.post(url=url,headers=self.header,data=data,timeout=6)
except:
# 需要先清除cookies資訊
self.lagou_session.cookies.clear()
# 重新獲取cookies資訊
first_request_url ="https://www.lagou.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput=" % info
self.handle_request(method="GET", url=first_request_url)
time.sleep(10)
continue
response.encoding = 'utf-8'
if '頻繁' in response.text:
print(response.text)
#需要先清除cookies資訊
self.lagou_session.cookies.clear()
# 重新獲取cookies資訊
first_request_url = "https://www.lagou.com/jobs/list_python?city=%s&cl=false&fromSearch=true&labelWords=&suginput="%info
self.handle_request(method="GET",url=first_request_url)
time.sleep(10)
continue
return response.text
(3)寫一個具體的URL來拉取網頁資訊,比如:
#獲取全國所有城市串列的方法
def handle_city(self):
city_search = re.compile(r'www\.lagou\.com\/.*\/">(.*?)</a>')
city_url = "https://www.lagou.com/jobs/allCity.html"
city_result = self.handle_request(method="GET",url=city_url)
#使用正則運算式獲取城市串列
self.city_list = set(city_search.findall(city_result))
self.lagou_session.cookies.clear()
第二部分:將拉取的資料存入資料庫,
將資料庫欄位與獲取到的JSON資料對應,代碼簡單就不舉例了,
主要是用到資料庫的session資訊;通過導包,獲得該資料庫連接的Session物件,然后操作資料庫,
#插入資料 self.mysql_session.add(data) #提交資料到資料庫 self.mysql_session.commit()
第三部分:將資料庫資料以Echarts工具展示出來,
可以查看官網有教學: https://www.echartsjs.com/zh/index.html
主要也是去修改js檔案,比較簡單;這里就不做示范了,
全部代碼,可以去本人的Githup上下載,
注意:本次爬蟲教學并不是本人所原創,只是分享一下學習結果,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/149783.html
標籤:Python