我們把前面的程式稍微改一下,來了解python中的變數,
# file: ./4/4_1.py # 定義變數 hello_str = "hello, world!" # 字串列印 print(hello_str)
建議通過視頻來學習本節內容: 查看本節視頻
這段代碼實作的功能也是在終端列印出“hello,world!”這一字串,與我們最開始那個程式不同的是,它定義了一個變數“hello_str”用于存盤這個字串,然后再呼叫print函式輸出,
本節我們來學習什么是變數? 變數,顧名思義就是可以變化的一個資料,與其對應的不能改變的資料,叫做“常量”,
變數和常量,是所有編程語言的一個基本概念,
Python里面沒有專門定義常量的語法,通常用變數來替代,所以我們不專門介紹常量,
抽象了看,所有的程式,無論大小,其本質都是在操作一系列的資料按照我們預設的邏輯去運算,這些資料在運算程序中,會被臨時存盤在記憶體中,我們可以認為變數就是對這些存盤空間的一個命名,我們可以在代碼中通過使用變數,來達到操作對應資料的目的,而不需要感知這個資料具體是怎么被計算機存盤的,
我們通過pycharm來除錯該段代碼,看看變數是如何存盤資料的:
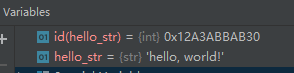
我們通過id(hello_str)來獲取變數hello_str的地址,這個地址是我們看來很奇怪的一串值,其實這個值是一個記憶體地址,它指向的是一段記憶體空間的起始位置,“hello,world!”這一串字符就存盤在這段記憶體空間中, 變數的存盤空間是堆(heap)和堆疊(stack),堆疊是有很大區別的,在C語言里面你需要非常清晰的搞清楚它們,但是python封裝得更好,不需要太去深究它們,如果感興趣,你可以參考下圖,或者百度,
總結一下,變數是用來臨時存盤資料的,它本質上指向的是一段存盤空間的起始地址, Python里面,對于變數的命名有一些約束,如下:
- 變數的第一個字符必須是字母表中字母或下劃線 _ ,
- 變數的其他的部分由字母、數字和下劃線組成,
- 識別符號對大小寫敏感,
- 變數不能采用python的保留字命名,
我們可以在windows命令列中采用下面的方法查詢保留字:
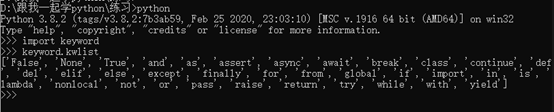
理論上,python3可以支持采用中文字符命名變數,
下面我們通過一個有意思的例子來進一步深入理解python的變數,
1 # file: ./4/4_2.py 2 3 score1 = 10score2 = 50 4 5 # score1 score2的地址 6 print('id(score1): %x, id(score2): %x, ' % (id(score1), id(score2))) 7 score2 = score2 - score1 8 9 # 字串列印 10 print('score2: ', score2) 11 12 # score1 score2的地址 13 print('id(score1): %x, id(score2): %x, ' % (id(score1), id(score2))) 14 score3 = 40 15 print('id(score3): %x' % (id(score3)))
這個例子的輸出如下:
id(score1): 7ffc5331d7c0, id(score2): 7ffc5331dcc0,
score2: 40
id(score1): 7ffc5331d7c0, id(score2): 7ffc5331db80,
id(score3): 7ffc5331db80
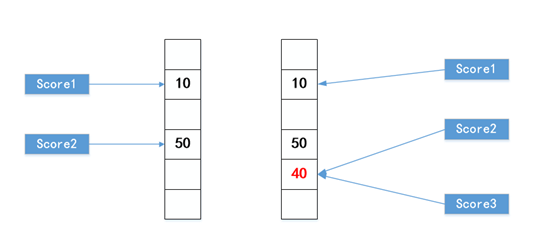
我們可以看到,在score2的值變為40之后,它指向了一個新的地址7ffc5331db80,而我們定義了一個新變數score3,給它賦值40,它居然也和score2指向了同一塊地址空間,寫慣了C語言的程式員對此會感到費解,但python就是這樣的,
當我們給score1賦值為10時,python會先給10創建一個物件并分配一個存盤空間,然后再將score1指向這個物件,
當score2做減法后,python也會先給40分配一個物件空間,然后將score2指向這個新的物件,所以我們看到score2的地址變了,
當我們給score3賦值為40時,由于40對應的物件存在,所以直接將score3指向了這個物件,所以我們看到score2和score3的地址相同,
如下圖所示:
那么原來那個值為50的物件怎么處理呢?如果是C語言,需要程式員主動去將其釋放,否則就會記憶體泄露,幸運的是,python為我們提供了自動垃圾回識訓制(GC),當它發現這個物件沒有被參考后會自動將其釋放,關于垃圾回識訓制,這是一個很大的話題,我們現在沒必要去深究它,有興趣的同學可以百度,
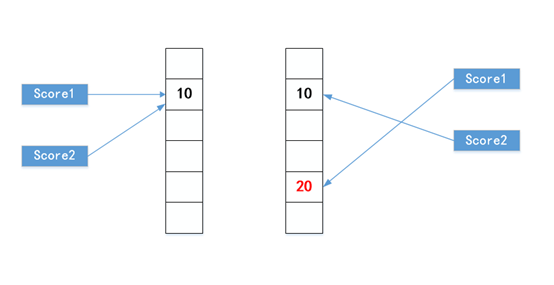
我們再來看一個有意思的例子:
1 # file: ./4/4_3.py 2 3 4 5 score1 = 10 6 7 score2 = score1 8 score1 = 20 9 10 print('score1: ', score1) 11 print('score2: ', score2) 12 13
它的輸出是:
score1: 20
score2: 10
沒有編程經驗的同學會對此感到疑惑,不是score2=score1嗎,為什么score1改變了,score2卻沒有改變?我們同樣可以把變數的地址列印出來,就很好理解了,
# file: ./4/4_3.py score1 = 10 print('id(score1): %x' % (id(score1))) score2 = score1 print('id(score2): %x' % (id(score2))) score1 = 20 print('id(score1): %x, id(score2): %x, ' % (id(score1), id(score2))) print('score1: ', score1) print('score2: ', score2)
它的輸出是:
id(score1): 7ffc5331d7c0
id(score2): 7ffc5331d7c0
id(score1): 7ffc5331d900, id(score2): 7ffc5331d7c0,
score1: 20
score2: 10
我們可以看到,在score2 = score1后,score2的確指向了score1的地址,但是我們改變score1的值為20后,score1指向了另外一塊地址空間,而score2并沒有跟著改變,所以score2依然是10,
如下圖所示:
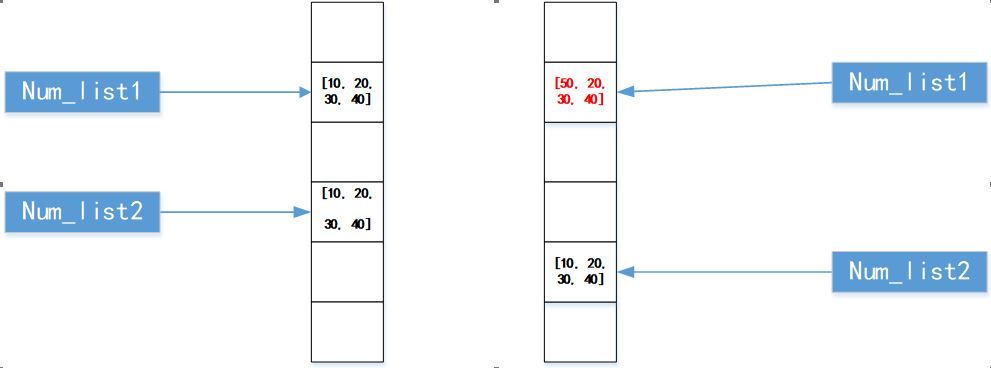
我們最后再看一個例子,這個例子里面我們給變數賦了一個串列資料結構的值,關于資料結構,我們下一節會詳細介紹,大家不用太關注,我們看看對于串列結構,它的變數是否也如同上面兩個例子那樣,
1 # file: ./4/4_4.py 2 3 4 # 串列 5 num_list1 = [10, 20, 30, 40] 6 num_list2 = [10, 20, 30, 40] 7 8 print('id(num_list1): %x, id(num_list2): %x' % (id(num_list1), id(num_list2))) 9 10 num_list1[0] = 50 11 print('num_list1: ', num_list1) 12 13 print('id(num_list1): %x, id(num_list2): %x' % (id(num_list1), id(num_list2)))
它的輸出是:
id(num_list1): 292bd87df00, id(num_list2): 292bd9ba880
num_list1: [50, 20, 30, 40]
id(num_list1): 292bd87df00, id(num_list2): 292bd9ba880
可以看出,在初始賦值時,雖然num_list1和num_list2的值是相同的,但是它們指向的地址空間并不相同,我們修改了num_list1的值之后,num_list1也并沒有重新指向一個新的地址,所以,串列資料型別和我們上面兩個例子中的變數處理是不一樣的,Python會給串列對應的變數分配獨立的地址空間,即便值相同,也不會多個變數復用,
對于不同資料型別的變數,python的處理方式是不一樣的,也許你現在會覺得有點亂,沒關系,下節我們學習了python的資料型別之后,你就能理解python的解釋器為什么要這樣區別處理了,
另外,從這些例子我們也能理解變數給我們帶來的好處了,試想如果沒有變數的話,程式員幾乎沒法寫代碼,因為你想要的那個資料一會兒存在A地址,一會兒又存在了B地址,但是有了變數的話,程式員只需要對這個變數進行操作即可,不需要關心它具體指向哪兒,
好了,下節我們學習python的資料型別,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/150267.html
標籤:Python