本文從原始碼層面講解tornado實作HTTP服務器的原理, 使用的tornado版本為1.0.0, 它的代碼量比較少, 便于我們找到其核心部分. 在這里可以下載1.0.0版本的tornado.
一.基本流程
使用下面的代碼實作一個最簡單的tornado服務器:
import tornado.httpserver import tornado.ioloop import tornado.web class MainHandler(tornado.web.RequestHandler): def get(self): self.write('hello world') if __name__ == '__main__': application = tornado.web.Application( handlers=[ (r'/', MainHandler) ] ) http_server = tornado.httpserver.HTTPServer(application) http_server.listen(8000) tornado.ioloop.IOLoop.instance().start()
這里使用了tornado的httpserver, ioloop和web三個模塊, 其中httpserver就是http服務器, 它負責接收和處理連接; ioloop則是底層的事件回圈系統, 負責在監聽到事件時進行通知; web模塊就相當于web應用.
總的來說, 一個tornado服務器可以分為四層, 作業流程大致是下面這樣:
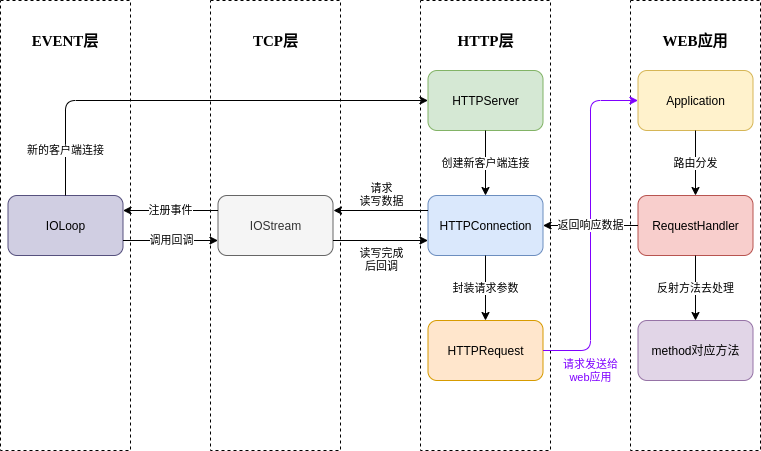
上面這張圖可能有點復雜, 一時看不懂沒關系, 后面會進行詳細的講解.
二.事件回圈和異步非阻塞socket
tornado的高性能主要來自于ioloop.IOLoop和iostream.IOStream兩個類, 前者是一個事件回圈, 通過epoll對不同的socket物件進行監聽和調度. IOStream類則是socket物件的封裝, 它依靠著IOLoop的事件回圈, 實作了對socket讀寫功能的非阻塞+異步回呼.
ioloop.IOLoop的主要代碼如下:
import select import logging class IOLoop(object): _EPOLLIN = 0x001 _EPOLLPRI = 0x002 _EPOLLOUT = 0x004 _EPOLLERR = 0x008 _EPOLLHUP = 0x010 _EPOLLRDHUP = 0x2000 _EPOLLONESHOT = (1 << 30) _EPOLLET = (1 << 31) # 可以監聽的事件型別,從字面上理解就行 NONE = 0 READ = _EPOLLIN WRITE = _EPOLLOUT ERROR = _EPOLLERR | _EPOLLHUP | _EPOLLRDHUP def __init__(self): self._impl = select.epoll() # 在不支持epoll的系統中, 事件通知機制會退化為kqueue或者select self._handlers = {} @classmethod def instance(cls): # 需要IOLoop物件時,不直接實體化,而是呼叫這個類方法,這樣可以保證IOLoop是單例的 if not hasattr(cls, "_instance"): cls._instance = cls() return cls._instance def add_handler(self, fd, handler, events): self._handlers[fd] = handler self._impl.register(fd, events | self.ERROR) def update_handler(self, fd, events): self._impl.modify(fd, events | self.ERROR) def remove_handler(self, fd): self._handlers.pop(fd, None) try: self._impl.unregister(fd) except (OSError, IOError): logging.debug("Error deleting fd from IOLoop", exc_info=True) def start(self): while 1: event_pairs = self._impl.poll() for fd, events in event_pairs: self._handlers[fd](fd, events)
IOLoop的本質是對epoll的封裝, 它的用法比較簡單: 首先, 我們可以呼叫add&update&remove_handler方法來設定需要監聽的句柄, 對應的事件和回呼函式, 然后, 只要呼叫start方法, IOLoop就會使用epoll一直監聽下去, 并且在監聽到事件時, 呼叫對應的回呼函式, 這樣就實作了監聽和調度的功能.
iostream.IOStream類的主要代碼如下:
import errno import logging import socket class IOStream: def __init__(self, socket, io_loop, read_chunk_size=4096): self.socket = socket self.socket.setblocking(False) self.io_loop = io_loop self.read_chunk_size = read_chunk_size self._read_buffer = "" self._write_buffer = "" self._read_delimiter = None self._read_callback = None self._write_callback = None self._state = self.io_loop.ERROR self.io_loop.add_handler( self.socket.fileno(), self._handle_events, self._state) def read_until(self, delimiter, callback): loc = self._read_buffer.find(delimiter) if loc != -1: callback(self._consume(loc + len(delimiter))) return self._read_delimiter = delimiter self._read_callback = callback self._add_io_state(self.io_loop.READ) def write(self, data, callback=None): self._write_buffer += data self._add_io_state(self.io_loop.WRITE) self._write_callback = callback def _consume(self, loc): # 這個方法負責把讀取緩沖區的指定長度截下來回傳 result = self._read_buffer[:loc] self._read_buffer = self._read_buffer[loc:] return result def close(self): if self.socket is not None: self.io_loop.remove_handler(self.socket.fileno()) self.socket.close() self.socket = None def _add_io_state(self, state): # 呼叫這個方法添加要監聽的事件 if not self._state & state: self._state = self._state | state self.io_loop.update_handler(self.socket.fileno(), self._state) def _handle_events(self, fd, events): # 這個方法由事件回圈進行回呼 # 它首先根據事件型別呼叫對應方法去處理,然后根據處理結果更新在事件回圈中注冊的事件 if events & self.io_loop.READ: self._handle_read() if not self.socket: return if events & self.io_loop.WRITE: self._handle_write() if not self.socket: return if events & self.io_loop.ERROR: self.close() return # 判斷是否還需要讀&寫資料,然后重新注冊事件 state = self.io_loop.ERROR if self._read_delimiter: state |= self.io_loop.READ if self._write_buffer: state |= self.io_loop.WRITE if state != self._state: self._state = state self.io_loop.update_handler(self.socket.fileno(), self._state) def _handle_read(self): # 當有可讀事件時觸發這個方法,讀取可讀緩沖區的資料并寫入到self._read_buffer中 try: chunk = self.socket.recv(self.read_chunk_size) except socket.error, e: if e[0] in (errno.EWOULDBLOCK, errno.EAGAIN): return else: logging.warning("Read error on %d: %s", self.socket.fileno(), e) self.close() return if not chunk: self.close() return self._read_buffer += chunk # 如果設定了終止符,并且已經讀到終止符了,就不再讀取 if self._read_delimiter: loc = self._read_buffer.find(self._read_delimiter) if loc != -1: callback = self._read_callback delimiter_len = len(self._read_delimiter) self._read_callback = None self._read_delimiter = None callback(self._consume(loc + delimiter_len)) def _handle_write(self): # 當有可寫事件時觸發這個函式,把self._write_buffer的資料寫入可寫緩沖區,直到寫完或者寫不下為止 while self._write_buffer: try: num_bytes = self.socket.send(self._write_buffer) self._write_buffer = self._write_buffer[num_bytes:] except socket.error, e: if e[0] in (errno.EWOULDBLOCK, errno.EAGAIN): break else: logging.warning("Write error on %d: %s", self.socket.fileno(), e) self.close() return # 寫完之后,呼叫預先設定的回呼 if not self._write_buffer and self._write_callback: callback = self._write_callback self._write_callback = None callback()
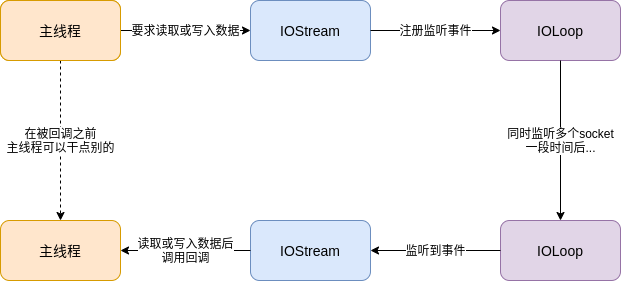
IOStream本質是一個socket物件, 只不過通過事件回圈變為異步的了. 我們呼叫它的read_until或者write方法時, IOStream并不會馬上嘗試去讀取或寫入資料, 而是設定一個回呼函式, 然后呼叫_add_io_state方法在事件回圈中添加對可讀或可寫事件的監控. 然后, 事件回圈在監聽到事件時, 呼叫IOStream的_handle_events方法, 該方法根據事件的型別再呼叫_handle_read和_handle_write去讀取或寫入資料, 并呼叫之前設定好的回呼, 這樣一次讀取&寫入才算結束.
除此之外, IOStream還將自己的socket設定為非阻塞的狀態, 避免在socket不可讀&不可寫的情況下產生阻塞. tornado的高性能主要就是因為事件回圈回呼和非阻塞socket這兩點, 首先, 異步回呼的機制可以使tornado在單個執行緒中同時維護多個socket連接, 當某個連接觸發事件時, 呼叫回呼去處理就行. 然后, socket的非阻塞狀態可以避免處理事件時產生的阻塞, 從而最大程度地利用CPU時間.
總的來說, IOStream + IOLoop的作業流程如下:
三.HTTP服務器
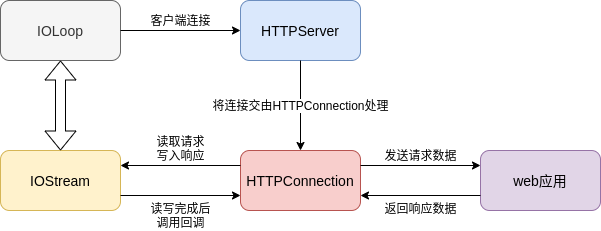
httpserver模塊中有三個類: HTTPServer, HTTPConnection和HTTPRequest, HTTPServer相當于服務端socket的封裝, 負責接收客戶端的連接. 該連接會交由HTTPConnection去處理, HTTPConnection利用iostream模塊讀取客戶端的請求資料, 然后將請求資料封裝成一個HTTPRequest物件, 將這個物件交由最上層的web應用去處理.
HTTPServer的主要代碼如下:
import errno import socket class HTTPServer: def __init__(self, application): self.application = application self.io_loop = ioloop.IOLoop.instance() self._socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM, 0) self._socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) self._socket.setblocking(0) def listen(self, port, address=''): self._socket.bind((address, port)) self._socket.listen(128) self.io_loop.add_handler(self._socket.fileno(), self._handle_events, ioloop.IOLoop.READ) def _handle_events(self, fd, events): while 1: try: connection, address = self._socket.accept() except socket.error, e: # 已經接收到客戶端后,就跳出回圈 if e[0] in (errno.EWOULDBLOCK, errno.EAGAIN): return raise stream = iostream.IOStream(connection, io_loop=self.io_loop) HTTPConnection(stream, address, self.application)
HTTPServer是web服務器端的入口, 首先, 我們通過實體化這個物件來指定web服務器所配套的web應用. 然后, 呼叫它的listen方法, 就會通過ioloop監聽指定埠的可讀事件, 也就是客戶端連接. 當有客戶端連接時, HTTPServer會首先實體化一個IOStream物件, 這個物件相當于對客戶端socket物件的封裝, 然后新建一個HTTPConnection物件去處理這個新連接.
HTTPConnection的主要代碼如下:
import tornado.httputil class HTTPConnection: def __init__(self, stream, address, application): self.stream = stream self.address = address self.application = application self.stream.read_until("\r\n\r\n", self._on_headers) def _on_headers(self, data): eol = data.find("\r\n") start_line = data[:eol] method, uri, version = start_line.split(" ") headers = tornado.httputil.HTTPHeaders.parse(data[eol:]) # 這里會把請求資料決議成一個字典物件回傳 self._request = HTTPRequest( connection=self, method=method, uri=uri, version=version, headers=headers, remote_ip=self.address[0]) self.application(self._request) def write(self, chunk): self.stream.write(chunk, self._on_write_complete) def _on_write_complete(self): self.stream.close()
在HTTPServer接收到新連接后, 由HTTPConnection來處理這個新連接. 首先, HTTPConnection使用IOStream異步回呼地讀取客戶端的請求資料, 決議出請求行的內容以及請求頭資料之后, 將這些資料封裝到一個HTTPRequest物件中, 讓web應用去處理這個請求物件. web應用處理結束后, 再呼叫它的write方法, 通過IOStream將回應資料寫入, 最后關閉socket連接, 這樣一個請求就處理完畢了.
HTTPRequest主要是對請求資料的封裝, 沒什么好說的. 它的主要代碼如下:
import urlparse class HTTPRequest: def __init__(self, method, uri, version="HTTP/1.0", headers=None, remote_ip=None, connection=None): self.method = method self.uri = uri self.version = version self.headers = headers self.remote_ip = remote_ip self.host = self.headers.get("Host") or "127.0.0.1" self.connection = connection scheme, netloc, path, query, fragment = urlparse.urlsplit(uri) self.path = path self.query = query def write(self, chunk): # web應用呼叫這個方法寫入回應資料,通過HTTPConnection最終由IOStream來寫入資料 self.connection.write(chunk)
這樣, 一個http服務器就完成了, 它的流程像是下面這樣:
四.web應用
web應用的職責是, 接收web服務器發過來的請求資料, 根據這些資料執行一些邏輯之后, 回傳回應結果. tornado的web模塊就負責web應用這塊.
我們首先分析web.Application類, 簡單來說, 它的代碼差不多是下面這樣:
import re class Application(object): """ 實際上, 這個類還做了其它一些作業, 比如設定debug模式, 指定wsgi等等 另外, 路由的映射關系實際上是由web.URLSpec這個類進行封裝的 但是, 這些都不是重點, 這段代碼只是為了方便理解, 說明Application主要做什么事 """ def __init__(self, handlers): self.handlers = handlers def __call__(self, request): path = request.path h_obj = None for pattern, handler in self.handlers: if re.match(pattern, path): h_obj = handler(request) h_obj._execute()
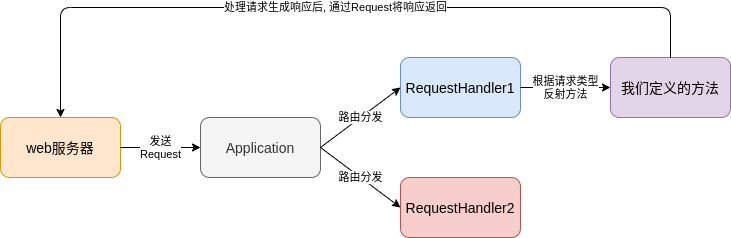
web.Application是web應用的入口, 由剛才的代碼可以看出來, 它負責路由的分發. 首先我們實體化物件并傳入handlers = [(r'/', MainHandler)]這樣的引數, 然后呼叫這個Application物件并傳入request, 它就會根據請求資料所給的路徑找到對應的handler類, 實體化這個handler類并呼叫handler的_execute方法, 讓handler物件來執行具體的操作.
一般來說, 我們指定的handler類都會繼承web.RequestHandler, 它的代碼差不多是下面這樣:
import httplib class RequestHandler(object): """ 這里的RequestHandler也只列出了最核心的代碼 除此之外, RequestHandler還實作了獲取和設定cookie, 用戶認證以及防csrf攻擊等功能 """ def __init__(self, request): self.request = request self._headers = { "Content-Type": "text/html; charset=UTF-8", } self._write_buffer = [] self._status_code = 200 def get(self): # 這個方法需要我們根據請求型別自己定義,除get外,還支持head,post,delete和put raise HTTPError(405) def write(self, chunk): self._write_buffer.append(chunk.encode('utf8')) def finish(self): # 首先生成回應狀態和回應頭 lines = [self.request.version + " " + str(self._status_code) + " " + httplib.responses[self._status_code]] lines.extend(["%s: %s" % (n, v) for n, v in self._headers.iteritems()]) headers = "\r\n".join(lines) + "\r\n\r\n" # 然后生成回應內容 chunk = "".join(self._write_buffer) self.request.write(headers + chunk) def _execute(self): getattr(self, self.request.method.lower())() self.finish()
RequestHandler對回應進行了封裝. Application呼叫它的_execute方法, 就會根據請求型別反射到我們所重寫的方法, 比如get方法. 在執行完我們定義的方法之后, 呼叫自己的finish方法來生成回應訊息, 并通過request將回應訊息回傳.
Application和RequestHandler實作了一個web應用的框架, 用戶只需要繼承RequestHandler類, 然后重寫請求型別的對應方法就可以了. 總的來看, 這個web應用的處理流程如下:
五.總結
綜上所述, tornado服務器可以分為四層: 事件回圈層, TCP傳輸層, HTTP層和web應用, 作業起來像是下面這樣:

在寫demo應用的階段, 我們做了四件事:
- 繼承RequestHandler, 重寫請求型別對應的方法, 比如get方法
- 定義Application的路由
- 為HTTPServer指定app和埠
- 啟動IOLoop
這樣, 一個tornado應用就啟動了, 一個請求的流程是這樣的:
- IOLoop監聽到新的客戶端連接, 通知HTTPServer
- HTTPServer實體化一個HTTPConnection來處理這個新的客戶端
- HTTPConnection利用IOStream異步讀取客戶端的請求資料
- IOStream通過IOLoop注冊可讀事件, 在事件觸發時讀取資料, 然后呼叫HTTPConnection的回呼函式
- HTTPConnection將讀取的請求資料進行決議, 用一個HTTPRequest物件封裝決議后的請求資料
- HTTPConnection把HTTPRequest發送給Application
- Application通過路由找到對應的RequestHandler, 讓它來處理請求
- RequestHandler通過反射找到請求型別對應的處理方法, 處理請求
- 處理完成后, RequestHandler呼叫HTTPRequest的write方法寫入回應結果
- HTTPRequest將回應結果交給HTTPConnection, HTTPConnection使用IOStream來寫入回應資料
- IOStream繼續使用IOLoop異步地寫入資料, 寫入完畢后, 呼叫HTTPConnection的回呼函式
- HTTPConnection被回呼, 它關閉socket連接, 請求結束 (http1.1或者keep-alive的情況不討論)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/151093.html
標籤:Python
上一篇:跟哥一起學python(2)- 運行第一個python程式&環境搭建
下一篇:樹與堆