生日悖論: 是指在不少于 23 個人中至少有兩人生日相同的概率大于 50%,例如在一個 30 人的小學班級中,存在兩人生日相同的概率為 70%,對于 60 人的大班,這種概率要大于 99%,從引起邏輯矛盾的角度來說,生日悖論并不是一種 “悖論”,但這個數學事實十分反直覺,故稱之為一個悖論,
生日悖論是有個有趣的概念,但這和我省上百G的記憶體有什么關系?
背景
首先介紹下背景,作業中我負責了一個廣告資料系統,其中一個功能就是對同一次請求的廣告曝光去重,因為我們只需要知道這次請求這個廣告的一次曝光就行了,那些同一次請求產生的重復曝光記錄下來沒有意義,而且還耗會增加我們的存盤成本,所以這里就需要有個邏輯去判斷每條新到的曝光是否只之前已經記錄過的,舊的方案是在redis中存盤請求唯一標識(uuid)和廣告ID(adid),每次資料過來我們就看redis里有沒有uuid+adid這個key,有就過濾掉,沒有就不過濾并在redis記錄下來已出現,
問題就來了,redis記錄的這份數很大(兩天資料超過400G),而且隨著我們業務的增長,我們的Redis集群快盛不下了…… 當然花錢加機器是最簡單的方式,畢竟能用錢解決的問題都不是問題,而優秀的我,為了替公司省錢,走了優化的路,
如何優化?
首先可以肯定的是資料條數不會少,因為業務量就在那里,所以減少資料量的這條路肯定行不通,那是否可以減少每條資料的長度呢?
我們再來看下redis存盤的設計,如下圖:

這樣下來一條記錄總共用了45個位元組,這個長度能不能縮短? 當然能,我們可以截取部分UUID,但這樣又帶來一個新的問題,截取UUID會增加重復的概率,所以首先搞清楚怎么截取,截多少?
這里我們用的是隨機UUID,這個版本中有效二進制位是122個,所以總共有$2^{122}$個有效的UUID, 因為是隨機產生的所以肯定有重復的概率,UUID重復的概率有多少? 要算這個重復概率,光有$2^{122}$這個總數還不行,還得知道你擁有的UUID個數, 我把這個問題具體下,求:在$2^{36}$個UUID中有重復的概率是多少?
$$
p(n) \approx 1-e{-\frac{n{2}}{2 x}}
$$
這不就是生日悖論的資料放大版嗎? 當然這個概率可以根據上面公式計算,其中x是UUID的總數$2{122}$,n是$2{36}$,參考百度百科的資料,概率為$4 *10^{-16}$ 這比你出門被隕石撞的概率還小很多,
| n | 幾率 |
|---|---|
| 2^36 | 4 x 10^-16 |
| 2^41 | 4 x 10^-13 |
| 2^46 | 4 x 10^-10 |
另外,從上面的公式也可以看出,在n固定的時候,隨著有效二進制位的減少,概率p就會增加, 回到我們廣告去重的場景下,每天最大請求數n是基本固定的,而且我們也可以忍受一個較小的概率p(小于萬分之一),然后就可以反推出這個x有多大,
其實只要$\frac{n^{2}}{2 x} < 0.0001$,p就會小于萬分之一,我可以從歷史數中統計出n的大小,然后計算出x,再留一定的buff,然后根據n的大小重新設計了redis的key,(因為涉及公司資料,這里不公布中間計算程序)
新設計
最終有效位我選取了40個有效二進制位(10個16進制位),但我并沒有直接截取UUID的前10位,因為UUID的前幾位和時間有關,隨機性并不強,我選擇將整個UUID重新md5散列,然后截取md5的前10位,然后拼接adId形成最終的key,如下圖:
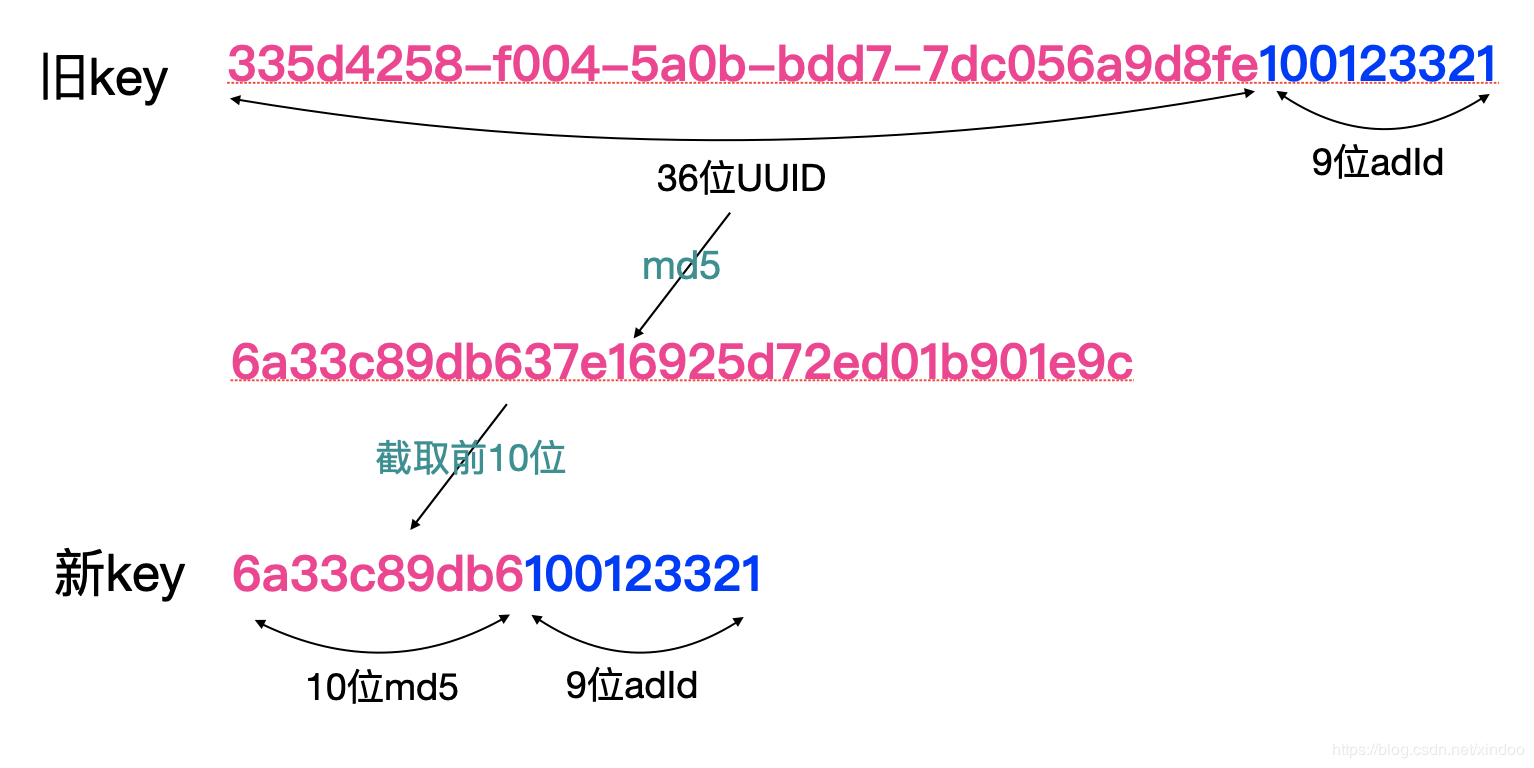
明顯看出,key的長度縮小了一半,總體上能節省至少50%的存盤空間,備注:但其實我們redis的具體存盤實作和上文描述略有差異,為了不喧賓奪主上文特意對實際實作做了簡化描述,所以最終實際沒有省一半以上的記憶體,只省了35%左右,
如何進一步優化?
實際優化就到這了,但其實還是不夠極致,其實adId中也包含大量的冗余資訊也可以截取,其實我們可以承受更高的重復率,其實我們可以把redis資料存盤時間設的更短一些……
上面幾種方法都可以進一步優化,但存盤空間不會有量級級別的減少,而下面一種方式,可以將存盤空間減小99%以上,
布隆過濾器(BloomFilter)
關于布隆過濾器的原理,可以參考我之前寫的一篇文章布隆過濾器(BloomFilter)原理 實作和性能測驗, 布隆過濾器完全就是為了去重場景設計的,保守估計我們廣告去重的場景切到布隆過濾器,至少節省90%的記憶體,
那為什么我沒有用布隆過濾器,其實還是因為實作復雜,redis在4.0后支持模塊,其中有人就開發設計了布隆過濾器的模塊RedisBloom,但無奈我們用的redis 還是3.x版本 !我也考慮過應用端基于redis去實作布隆過濾器,但我們應用端是個集群,需要解決一些分布式資料一致性的問題,作罷,
結語
其實我們redis的具體存盤實作和上文描述略有差異,為了不喧賓奪主上文特意對實際實作做了簡化描述,所以最終實際沒有省一半以上的記憶體,只省了35%左右,
最終400G+優化后能減少100多G的記憶體,其實也就是一臺服務器,即便放到未來也就是少擴容幾臺服務器,對公司而言就是每個月節省幾千的成本,我司這種大廠其實是不會在乎這點錢的,不過即便這幾千的成本最終不會轉化成我的工資或者獎金,但像這種優化該做還是得做,如果每個人都本著 用最低的成本做同樣事 的原則去做好每一件事,就我司這體量,一個月上千萬的成本還是能省下來的,
參考資料
- 百度百科 生日悖論
- 百度百科 UUID
- 布隆過濾器(BloomFilter)原理 實作和性能測驗
- RedisBloom 基于redis的布隆過濾器實作
本文來自https://blog.csdn.net/xindoo
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/151708.html
標籤:Java