python中的串列
# 串列
# list 類,串列
# 中括號括起來 ,逗號分隔每個元素,串列中的元素可以是數字,字串,串列,布林值等等,
# 串列還可以嵌套串列
=========串列的基本操作=========
(1)串列的常用操作
list1 = [11,22,33,44,55] # len 查看串列的元素的個數 print(len(list1)) # 通過索引取值 print(list1[3]) # 對串列進行切片 print(list1[0:2]) print(list1[:])
# for回圈操作
for i in list1:
print(i)
(2)串列元素,可以被修改
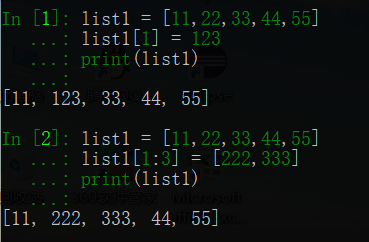
# 1.通過串列索引修改元素 list1 = [11,22,33,44,55] list1[1] = 123 print(list1) # 2.通過串列切片修改元素 list1 = [11,22,33,44,55] list1[1:3] = [222,333] print(list1)
以上的運行結果為:
(3)串列轉換成字串的注意事項:
1.如果串列中既有數字又有字串時,需要用for回圈轉換,
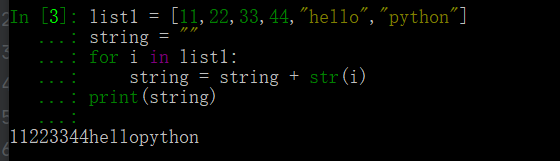
# 串列中既有數字又有字串 list1 = [11,22,33,44,"hello","python"] string = "" for i in list1: string = string + str(i) print(string)
運行結果為:
2.如果串列中只有字串,串列轉換成字串可以用join方法
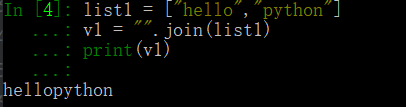
list1 = ["hello","python"] v1 = "".join(list1) print(v1)
運行結果為:
============串列的常用方法=========
list1 = [11,22,33,44,55] # 1.append 追加元素到串列,也可追加串列 v1 = list1.append(235) print(list1) # 2.clear 清空串列 list1.clear() print(list1) # 3.copy 拷貝,淺拷貝 list1 = [11, 22, 33, 44] v1 = list1.copy() print(v1) # 4.計算元素出現的次數 v1 = list1.count(11)
print(v1) # 5.insert 在指定索引位置插入元素,有兩個引數,引數一指定插入的索引,引數二參入的元素 list2 = [11, 22, 33, 44, "hello", "python"] list2.insert(1, 99) print(list2) # 6.串列的洗掉操作 # remove 洗掉串列中指定的元素 list2.remove(22) del list2[1] # 通過索引洗掉 del list2[1:5] # 通過切片洗掉 # pop() 洗掉某個值,并獲取洗掉值,沒有指定索引,默認洗掉最后一個元素 # v1 = list2.pop(1) # print(list2) # print(v1) # 7.extend 擴展原來的串列,必須是可迭代物件(內部執行了for回圈) list2 = [11, 22, 33, 44, "hello", "python"] list2.extend([111, 222]) list2.extend("hello") print(list2) # 8.reverse,對當前串列進行翻轉 li = [11, 22, 33, 44, 55] li.reverse() print(li) # 9.sort 排序(默認升序排列)sort(reverse=False) li = [11, 23, 10, 24, 26, 39, 73, 55] li.sort(reverse=True) # 降序排列 print(li)
第七題運行的結果:

python中的元組
# 元組,元組不可被修改,不能被增加或者洗掉
# 一般寫元組的時候,推薦在最后加上逗號
# 元組的一級元素不可修改/洗掉或增加
# 元組用法同串列,切片,成員運算in / not in
# 索引 age = (11, 22, 33, 44, 55) v = age[2] # 切片 v1 = age[0:3] print(v, v1) # for回圈 for i in age: print(i) # in or not in print(22 in age) print(123 not in age)
python中的字典
# 字典的value可以是任意值,字典、串列、元組、字串等,
# 串列和字典不能作為字典的key,元組可以作為字典的key,
# 布林值可以作為key,但是當有字典的鍵為1/0時,哪一個在前面,后面的鍵值對就不顯示,
# 字典是無序的
info = {'name': 'egon', 'age': '18', 'sex': 'male'}
# 字典的取值
print(info['name'])
# 字典的洗掉
del info['name']
print(info)
# 字典的for回圈,默認回圈輸出所有的key
for i in info:
print(i)
# 通過values()方法可以得到字典的values info = {'name': 'egon', 'age': '18', 'sex': 'male'} for i in info.values(): print(i) # for 回圈得到key和value for k, v in info.items(): print(k, v)
以上運行結果為: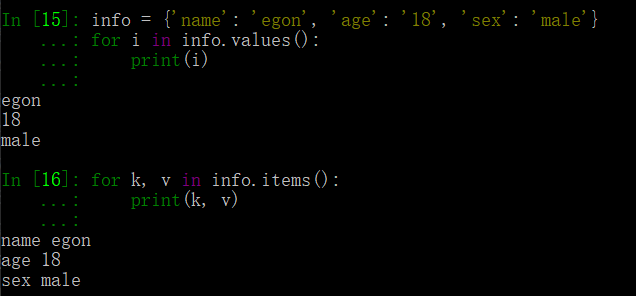
=============字典的常用方法========
dict1 = {'hello': "python", "world": "java"}
# 1.fromkeys() 根據序列,創建字典,并指定統一的值
v1 = dict.fromkeys(["k1", "999", 123], 111)
print(v1)
# 2.get() 根據key獲取值,key不存在時,可以指定默認值(None)
dict1 = {'hello': "python", "world": "java"}
v = dict1.get('hello', 'hadoop')
print(v)
# 3.pop() 洗掉并獲取值
dict1 = {'hello': "python", "world": "java"}
v = dict1.pop('hello')
print(v)
# 洗掉字典所有元素
v1 = dict1.popitem()
print(v1)
# 4.setdefault() 設定值,已存在不設定,不存在設定,獲取當前key對應的值
dict1 = {'hello': "python", "world": "java"}
v1 = dict1.setdefault('hello', 123)
print(dict1, v1)
v2 = dict1.setdefault('jsddd', 'jjshhd')
print(dict1, v2)
# 5.update() 更新
dict1 = {'hello': "python", "world": "java"}
dict1.update({'k1': 1111, 'k2': 999})
print(dict1)
dict1.update(k1=234, k2=3344, k3=9988)
print(dict1)
第四題運行結果為:
python中的集合
# 集合中是由一組無序的可hash值,可以作為字典的key
# 集合由不同的元素組成,并且無序,集合中的元素必須是不可變型別
# 不可變型別:數字,字串,元組
# 集合也是可迭代型別,可迭代型別還有字串,串列,元組,集合,字典
# set 定義 s = {11, 22, 33, 44, 55} # add() 添加元素 s.add('hello') print(s) # clear() 清除集合 s.clear() # 集合洗掉元素 # 1.s.pop() 隨機洗掉元素 s.pop() print(s) # 2.s.remove() # 指定洗掉集合元素 s.remove(11) print(s) # 3.s.discard() # 洗掉元素,如果元素不存在,不會報錯 s.discard('hello') print(s) print("========================")
# 4.update() 更行多個值 s1 = {1, 2, 3, 4} s2 = {1, 3, 5, 7, 8} s1.update(s2) s1.update((5,6,7,8,9)) update 后面跟的數必須是可迭代型別 s1.add((2, 3, 4, 5, 6, 7, 8, 9)) # add后面跟的數必須是不可變型別 s1.add("hello world") # add() 只能更新一個值 s1.union(s2) print(s1)
# union() 求交集操作,原集合資料不變,update()更新操作,源集合發生變化,
# 5.for回圈 for i in s1: print(i)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/154836.html
標籤:Python