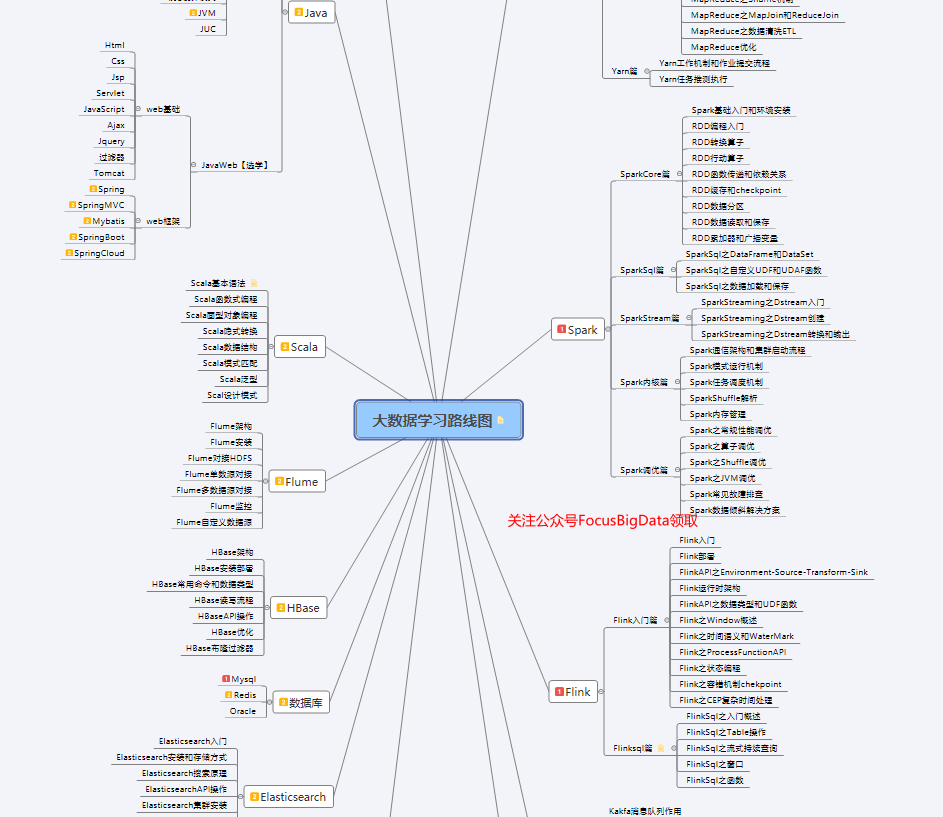
大資料學習路線
? 下面和大家講一下大資料學習的路線,幫助大家快速進入大資料行業,我會結合自己的實際經歷還說明學習路線,該路線針對的物件是零基礎小白,目標是到初中級大資料工程師,要求掌握資料建模,資料存盤,資料存盤,資料傳輸,資料分析等能力達到大資料崗位的應聘標準,
(一)Java基礎和web開發
? 很多人問過我,學大資料要不要學Java,我的答案是肯定的,首先Java是一門面向物件的編程語言,也是一門應用非常之廣的語言,對于零基礎的小白必須先有一些基本的編碼能力和面向物件編程的思想,其次很多框架的底層就是用Java進行開發的,比如Hadoop,如果想要更近一步,原始碼是要看的,所以學習Java基礎是十分必要的,Java基礎重點包括:
- Java常用類【特別是字串處理相關的類】
- 例外處理
- 集合泛型
- IO流
- 多執行緒
- 反射
- 網路編程
- 常見設計模式
- JVM【難點+重點,但比較花時間】
? 那么JavaWeb開發要不要會呢?我的建議是了解就行,了解常見的SSM框架,了解Web專案大致的開發流程,對整個軟體的開發有一個感性的認識,這樣就足夠了,當然學有余力請繼續深入,
(二)工具類
軟體開發都繞不開使用別人的輪子,好的工具讓我們開發效率大大提升,下面工具必須掌握:
編輯器:Eclipse + IDEA
專案構建工具:Maven + Gradle(有余力)
資料庫:Mysql【初期先了解增刪改查,后面有時間能多深入就多深入】
作業系統:Linux【常見命令會就行】
腳本語言:Shell【看得懂就行】
虛擬機:VMware 創建-克隆虛擬機,拍攝-還原快照【操作過就行】
(三)Hadoop生態系統
- HDFS:學會搭建完全分布式集群,知道如何根據業務撰寫MapReduce程式,并放到集群上運行
- YARN:知道它是個資源管理器和k8s一樣,熟悉Job提交的程序
- Mapreduce:撰寫業務程式【熟悉一些資料傾斜的解決方案和底層Shuffle程序】
- Zookeeper:分布式協調框架【知道Zookeeper選舉機制和常用命令】
- Hive:資料倉庫,底層是MapReduce【重點掌握:HQL陳述句書寫,視窗函式,多做一些案例總結自己的套路,優化也要了解一下】
- HBase:超大型分布式資料庫,經常用來做實時查詢【了解HBase架構,RowKey設計原則,后面開發用到再來深入】
- Flume:資料傳輸框架【知道Flume組成,攔截器和選擇器使用】
- Kafka:訊息快取框架【Kafka架構-壓測-監控-ISR同步佇列-事務-高效讀取】
- Sqoop:關系型資料庫和HDFS,HBase之間資料的傳輸框架
- Ambari: 用于配置、管理和監視Hadoop集群,基于Web,界面友好
- Impala: 對存盤在Apache Hadoop的HDFS,HBase的資料提供直接查詢互動的SQL

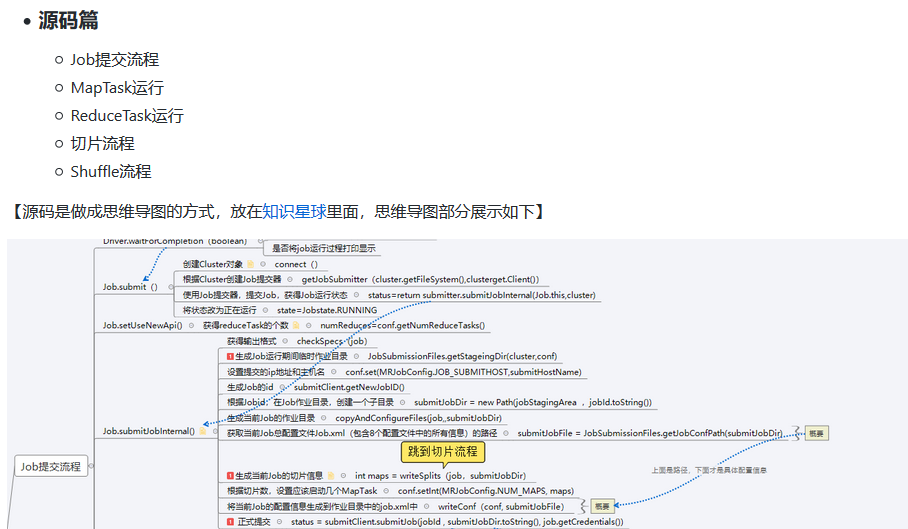
(四)Spark生態
? 到這里又要學習一門新的編程語言Scala,初入Scala可能會對它的語法結構產生不習慣,熟悉之后你會發現Java代碼是很繁瑣的,編程語言是什么不重要,關鍵是背后的思想和邏輯才重要,
Scala:了解基礎語法、函式式編程和隱式轉換就行
Spark:可以看作是對Hadoop框架的優化,它是基于記憶體進行計算的,性能提高很多,【熟悉Spark部署方式-提交流程-引數設定-RDD血統-寬窄依賴-轉換和行動算子-廣播變數和累加器-性能調優】
Spark-Sql:spark中負責和資料庫互動的模塊【熟悉DataFrame-DataSet,SQL陳述句書寫,UDF和UDTF函式使用】
Spark-Streaming:spark中負責流式計算的模塊【了解流式計算的原理,背壓機制,視窗函式】

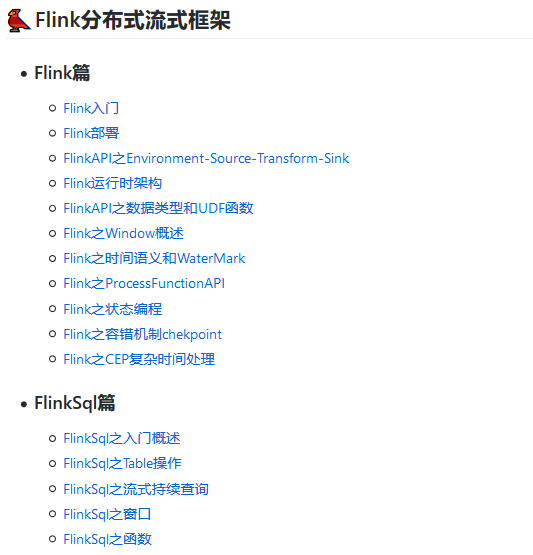
(五)Flink框架
Flink是目前最火的處理流式資料的框架應掌握一下內容
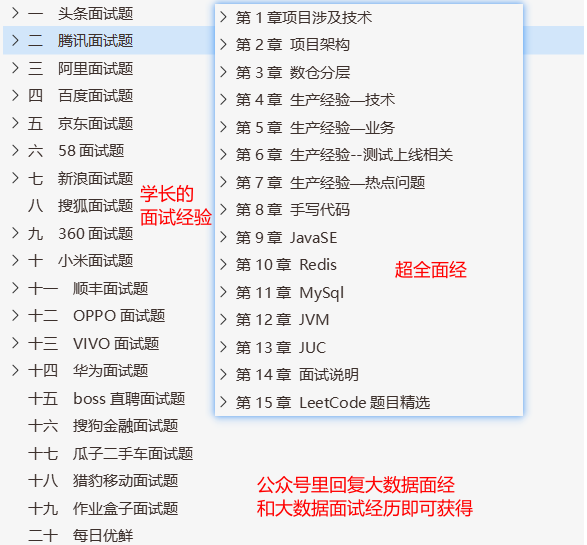
相關資料
本文配套GitHub:https://github.com/zhutiansama/FocusBigData
本文配套公眾號:FocusBigData
回復【大資料面經】【大資料面試經驗】【大資料學習路線圖】會有驚喜哦
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/155284.html
標籤:Java
下一篇:檔案的操作