冒泡,選擇,插入都屬于原地排序就是指在排序程序中不申請多余的存盤空間,只利用原來存盤待排資料的存盤空間進行比較和交換的資料排序,
1.冒泡排序
時間復雜度:O(n2)
原地排序(不需要額外空間來存放資料,所以空間復雜度是O(1))
思路:
一個串列有n個數字就回圈n-1次,回圈一次就會將最大數字放到了最后(相鄰數字進行比較,大的就放在右邊,每次對比后數字大的都放右邊,這樣一行數字每兩個相鄰的數字都進行一次比較下來后,最大的數字就放到了最右邊,
也就是本串列的-1索引位置,這樣做n-1次,就把整個串列排序做好了,n是整個串列長度,因為最后一次就剩最左邊一個元素了就不用再比較了.)
#冒泡排序完整代碼 #上述代碼操作需要作用n-1才可以將整個序列變成有序的 def sort(alist): length = len(alist) for j in range(length-1): #有幾個數字就回圈幾次,確保每一個數字都移動到對應的位置 #讓兩兩元素進行比較(n-1) for i in range(length-1-j):#每相鄰兩個數字都做比較,大的就放到最后,依次下去, 直到對應的位置,這里減j是要省去每次回圈都對比7個元素 (回圈一次就有一個數字已經找到對應的位置,接下來再回圈時相鄰數字作比較就少一個就好了), 第一次對比7個數字,第二次減去一個上依次回圈已經定位好的第7個數字,就只對6個數字最相鄰數字比較 #指標,先指0然后索引0和1的比較大小,直到指標直到n-2,還要留最后一個,用j+1來表示最后一個索引. if alist[i] > alist[i+1]:#第一個元素大于第二個元素,換成小于號就是降序排列 #兩個元素交換位置 alist[i],alist[i+1] = alist[i+1],alist[i] return alist alist = [3,8,5,2,0,7,6] print(sort(alist))
#代碼優化:
如果某一次回圈中,沒有做過alist[i],alist[i+1] = alist[i+1],alist[i]這樣的交換,就證明序列已經排好了,就不用在繼續回圈下去了. def sort(alist): length = len(alist) for j in range(length - 1): # 有幾個數字就回圈幾次,確保每一個數字都移動到對應的位置 # 讓兩兩元素進行比較(n-1) exchange=False#做個標記,只要這次回圈,有過交換,就置為True,沒有過交換就還是False for i in range(length - 1 - j): # 每相鄰兩個數字都做比較,大的就放到最后,依次下去, if alist[i] > alist[i + 1]: # 第一個元素大于第二個元素,換成小于號就是降序排列 # 兩個元素交換位置 alist[i], alist[i + 1] = alist[i + 1], alist[i] exchange=True print(alist)#將每次回圈的結果列印出來 if not exchange: return alist alist = [3, 8, 2, 0, 5, 6, 7] print('這是函式return的串列:',sort(alist))
2.選擇排序
時間復雜度:O(n2)
原地排序(不需要額外空間來存放資料,所以空間復雜度是O(1))
思路:
先回圈換找到最大的數字(并且獲取到對應的索引),再將最后一個數字和最大數字交換位置,這樣省去了每相鄰兩個數字做比較大小.
選擇排序改進了冒泡排序,每次遍歷串列只做一次交換,為了做到這一點,一個選擇排序在他遍歷時尋找最大的值,并在完成遍歷后,將其放置在正確的位置,
如圖:

思路一:選最大的,先放到最后
#選擇排序完整代碼 def sort(alist): for j in range(0,len(alist)-1): max_index = 0 #表示的是最大值的下標,一開始我們假設串列中的第0個元素為最大值 for i in range(len(alist)-1-j):#控制比較的次數 if alist[max_index] < alist[i+1]: max_index = i+1 #將最大值和最后一個元素交換位置,就可以將最大值放置到序列的最后位置 alist[max_index],alist[len(alist)-1-j] = alist[len(alist)-1-j],alist[max_index] return alist alist = [3,8,5,2,0,7,6] print(sort(alist))
思路二:選擇最小的,先放到最前
# 思路:分兩半,左邊有序,右邊無序,先把最左邊的定義為最小的數字, # 然后每回圈一次都定位好一個最小數字,i表示的是無序數列的第一個數字的索引 alist = [3, 8, 2, 0, 5, 6, 7] n=len(alist) def xuanze(li): for i in range(n-1): min_num=i for j in range(i+1,n): if li[j]<li[min_num]: min_num=j li[i],li[min_num]=li[min_num],li[i] print( li) return li print('最終結果:',xuanze(alist))
#這個代碼暫時無法優化,必需全程走完.
3.插入排序
時間復雜度:O(n2)
原地排序(不需要額外空間來存放資料,所以空間復雜度是O(1))
分析:
-
需要將原始的序列假裝拆分成兩部分
-
有序部分:默認為序列中的第一個元素
-
無序部分:默認為序列中除了第一個元素剩下的元素
-
關鍵:將無序部分的元素逐一插入到有序部分中即可
-
-
定義一個變數叫做i
-
i表示的是有序部分元素的個數
-
i還可以表示無序部分中第一個元素的下標
-
-
原始序列:[3,8,5,2,6,10,1]
-
[3, 8,5,2,6,10,1] ==》i=1
-
[3,8, 5,2,6,10,1] ==》i=2
思路:
插入排序的主要思想是每次取一個串列元素與串列中已經排序好的串列段進行比較,然后插入從而得到新的排序好的串列段,最侄訓得排序好的串列,比如,待排序串列為[49,38,65,97,76,13,27,49],則比較的步驟和得到的新串列如下:(帶有背景顏色的串列段是已經排序好的,紅色背景標記的是執行插入并且進行過交換的元素)

#插入排序完整代碼 def sort(alist): #i的取值范圍是1-(n-1) for i in range(1,len(alist)):#假設左起第一個數字已經是排序好了的,然后就要拿左起第二個數字和這個數字作比較,
比第一個大,位置就不動,如果比第一個數字小就要放到第一個數字的左邊,然后繼續回圈
(注意這里的range是顧頭不顧尾,會比len(alist)少1) #i = 2 #有序部分有兩個元素 while i > 0: if alist[i] < alist[i-1]: alist[i],alist[i-1] = alist[i-1],alist[i] i -= 1 #i是不可以為負數,減一之后就是剛才的數字向左移了一位,這里你繼續和他左邊的數字作對比,
對比大了就不動了,小了就繼續移動有可能會直到移動到最左邊. else: break return alist alist = [3,8,5,2,0,7,6] print(sort(alist))
思路二:
想象成摸撲克牌,手里的牌你要排好序,從下面摸上來的牌要一個一個按順序插入你手里的撲克牌中(從左到右是升序或者降序都可以)
alist = [3, 8, 2, 0, 5, 6, 7] n=len(alist) def insert_sort(li): for i in range(1,n):#i是摸到的牌的索引 tmp=li[i] #把摸到的數字留住做對比用 j=i-1 #j是你手里牌最后一張(或者說是最大或最小的一張) while j>=0 and li[j]>tmp:#j=0時就是最左端的數字和摸來的牌比大小,這里是升序排列, # 你摸到的牌比你手里最大的要小,就得重新插入,如果比你手里最大的牌都大, # 那就繼續往下走,不用再往前面插入了
li[j+1]=li[j]#將j這個手里最后一張牌向右挪一個位置,
# 這時候把原來li[i]的排頂掉了,如果沒有tmp接著li[i]的話就少個數字了
j-=1#將tmp繼續和原來j左邊的數字繼續比較大小,直到到了最后一位索引為0的或者是找到一個比tmp數字小的就停下了 # 當while回圈完后,j位置是沒有數字的,j為空位,而tmp還在外邊,因為最后j減了1,所以j+1就是空位了,這個是給tmp這個數字留的 li[j+1]=tmp insert_sort(alist) print(alist)
4.快速排序
時間復雜度:O(nlogn)如果出現特殊情況就是O(n2)
原地排序(不需要額外空間來存放資料,所以空間復雜度是0)
最壞情況(這種情況會非常少,但是并不是不會出現):
當你升序快排時如果,給你一個串列是逆序的例如:[9,8,7,6,5,4,3,2,1,0],你選擇的中間值數字,默認一般是第一個,也就是索引為0的數字,這樣,你往下走,
每次找的數字不是剩下的串列中最大的數字,就是最小的數字,每次都只能分出一堆的數字,而不是像快排要求的左邊一半,
右邊一半(全部在左邊或者全部在右邊),這樣,你的時間復雜度就變成了O(n2)而不是O(nlogn),
解決的辦法是每次選中間值時,都隨機挑選一個數字做中間值,而不是每次都招最左邊的數字,但是這樣也不是100%能避免上面的問題.
注意:快排用的是遞回,它會消耗電腦資源,而且遞回次數有限制(1000以內吧)
修改遞回最大次數:
#在遞回前插入這兩行 import sys sys.setrecursionlimit(1500) # 修改最大遞回次數為 1500
分析:
-
alist = [66,13,51,76,81,26,57,69,23]
-
基數:
-
默認情況下序列中第一個元素作為基數
-
原始序列中比基數大的值放置到基數右側,比基數小的值放置到基數左側
-
-
將串列中第一個元素設定為基準數字,賦值給mid變數,然后將整個串列中比基準小的數值放在基準的左側,比基準大的數字放在基準右側,然后將基準數字左右兩側的序列在根據此方法進行排放,
-
定義兩個指標,low指向最左側,high指向最右側
-
然后對最右側指標進行向左移動,移動法則是,如果指標指向的數值比基準小,則將指標指向的數字移動到基準數字原始的位置,否則繼續移動指標,
-
如果最右側指標指向的數值移動到基準位置時,開始移動最左側指標,將其向右移動,如果該指標指向的數值大于基準則將該數值移動到最右側指標指向的位置,然后停止移動,
-
如果左右側指標重復則,將基準放入左右指標重復的位置,則基準左側為比其小的數值,右側為比其大的數值,
思路:
-
一排數字(這些數字最好不要隨便拿因為有時候會出bug),快排是所有排序演算法里面速度最快的.
-
一排數字,先取第一個數字作為基數,這樣第一個位置就空了,然后定義兩個變數low和high,low暫時定義為0,high暫時為串列的長度(其實low和high就是索引)
-
先從右邊起,將high對應的數字與基數比大小,如果high比基數大,那么high對應的數字的位置就不動,將high重新賦值(向左挪一個數字),如果high比基數小,那么就將這個數字賦值給low,而這里的high對應的數字就算是空了,再往下,就從low這邊開始算,剛賦值給了low一個數字(從右邊第二個數字移動到了最左端第一個數字),現在再將low向右移動一個數字,將最左端第二個數字賦值給low,再把low和基數對比,如果low小于基數,就繼續將low向左移動,如果low大于基數,就將low對應的數字移動到剛才high對應的數字的位置上去,移動之后,再從high向左推算,后面依次繼續.
-
直到low等于了high,這倆索引最終就指向了基數,基數左邊都比基數小,右邊都比基數大,但是左邊一半(可能左右數字個數不一樣多)和右邊一半還沒排序,左邊一半繼續用剛才的方法,左端low定為0,右端high定為基數左邊的第一個數字的索引(就是剛才low和high),右邊一半也像剛才的方法,左邊的low數字定位為基數右邊第一個數字的索引,high就用串列總長度,和最初的一樣,再繼續下去迭代.直到出現low>high,迭代才停止.
#加入遞回后完整的快速排序代碼 def sort(alist,left,right): #low&hight表示的序列的起始位置的下標 low = left high = right #結束遞回的條件 #這里有點難理解,只要記住到了極點出現low小于high就是遞回結束的時候,不加他就會無限回圈 if low > high: return mid = alist[low] #基數 while low < high: #將原始序列中比基數小的值放置在基數的左側,比基數大的值放置在基數的右側 #注意:一開始的時候先將high向左偏移 #向左偏移 while low < high: if alist[high] < mid: #high小于基數 alist[low] = alist[high] break else:#基數如果小于了high,將high向左偏移 high -= 1 #high想左偏移了以為 #low向右偏移 while low <high: if alist[low] < mid:#如果low小于mid則讓low想右偏移 low += 1#讓low向右偏移一位 else: alist[high] = alist[low] break if low == high:#low和high重復,將基數賦值到low或者high的位置, alist[low] = mid #alist[high] = mid,每回圈一次(將mid值左半部分和右半部分已經區分開了,low索引左邊的比mid小,low索引右邊的比mid大,注意此時low和high相等,這時候就要把low索引對應的值寫成mid最早的值,即是中間值) #指定操作作用到基數左側的子序列中 sort(alist,left,low-1) #指定操作作用到基數右側的子序列中 sort(alist,high+1,right) return alist alist = [66,13,51,76,81,26,57,69,23] print(sort(alist,0,len(alist)-1))
代碼二:
#你選擇串列的第一個數字,就是索引為left的數字為中間值,你現在要找他排序后正確的索引位置
def partition(li, left, right):#求出中間值的索引,最終就是left=right時的索引 tmp = li[left] while left < right: while left < right and li[right] >= tmp: #從右面找比tmp小的數 right -= 1 # 往左走一步 li[left] = li[right] #把右邊的值寫到左邊空位上 # print(li, 'right') while left < right and li[left] <= tmp: left += 1 li[right] = li[left] #把左邊的值寫到右邊空位上 # print(li, 'left') li[left] = tmp # 把tmp歸位 return left def quick_sort(li, left, right):#把索引帶進遞回進行計算 if left<right: # 至少兩個元素 mid = partition(li, left, right) quick_sort(li, left, mid-1) quick_sort(li, mid+1, right) lst=[3,5,7,8,9,10,6,1,2,4,0] quick_sort(lst,0,len(lst)-1) print(lst)
5.希爾排序
時間復雜度:有很多種情況,直到現在也沒有具體的一種結論,像咱們這種一直除2的話:O(n/(2?)),如果遇到特殊情況那么時間復雜度就是O(n2)
思路:
希爾排序(Shell Sort)是插入排序的一種,也稱縮小增量排序,是直接插入排序演算法的一種更高效的改進版本,該方法的基本思想是:先將整個待排元素序列分割成若干個子序列(由相隔某個“增量(gap)”的元素組成的)分別進行直接插入排序,然后依次縮減增量再進行排序,待整個序列中的元素基本有序(增量足夠小)時,再對全體元素進行一次直接插入排序,因為直接插入排序在元素基本有序的情況下(接近最好情況),效率是很高的,因此希爾排序在時間效率比直接插入排序有較大提高,下面借用一下網上找的圖:
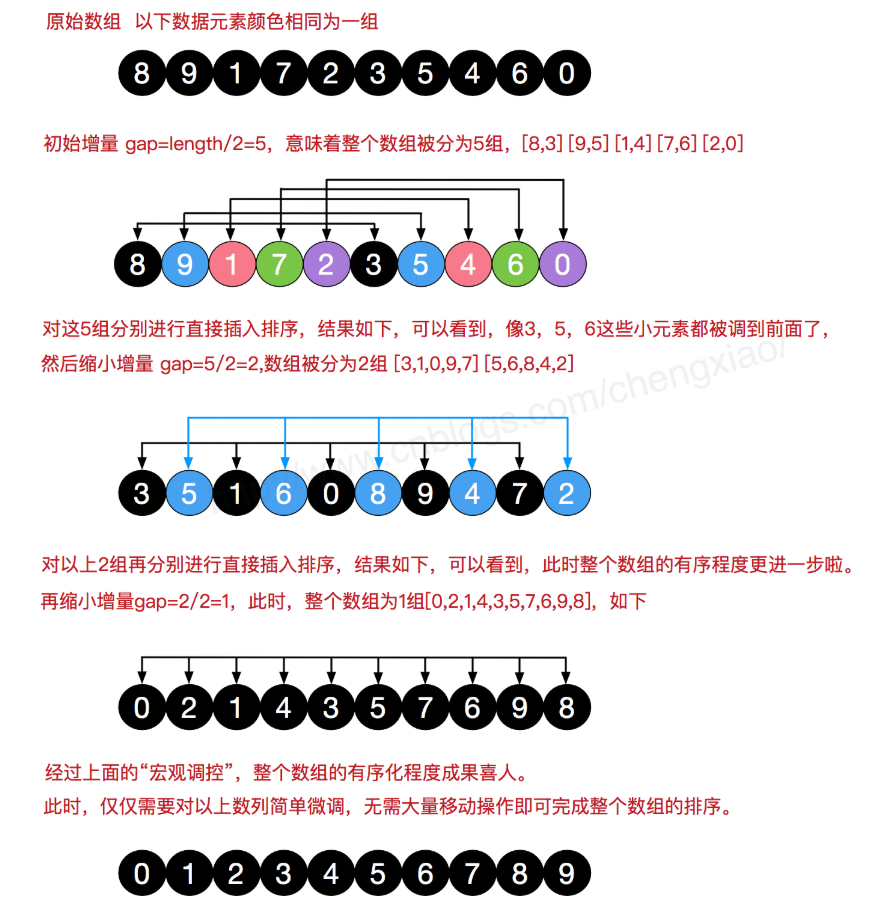
#希爾排序:插入排序是一種特殊的希爾排序 def sort(alist): gap = len(alist) // 2 while gap >= 1: #將增量設定成gap for i in range(gap,len(alist)): while i > 0 : if alist[i] < alist[i-gap]: alist[i],alist[i-gap] = alist[i-gap],alist[i] i -= gap else: break gap //= 2 return alist alist = [4,3,6,1,9,2] print(sort(alist))
6.歸并排序
python中的sort方法內部是基于歸并排序和插入排序的,并做了一些優化,用C寫的
時間復雜度:O(nlogn),每次都要分層,一層分成2組,2組分4組,...這些層就是logn(雖說分解是一個logn,合并是一個logn,但是這里只算一個),每一層,都需要遍歷所有元素,這就是n
空間復雜度:O(n),它是指你除了本身串列占用的記憶體外,你另外開辟的記憶體就是空間復雜度,你開個串列裝原來的串列整體所有元素,這就是n的長度,所以是O(n)
寫法一:
- 歸并排序采用分而治之的原理:
- 將一個序列從中間位置分成兩個序列;
- 在將這兩個子序列按照第一步繼續二分下去;
- 直到所有子序列的長度都為1,也就是不可以再二分截止,這時候再兩兩合并成一個有序序列即可,
如何合并?
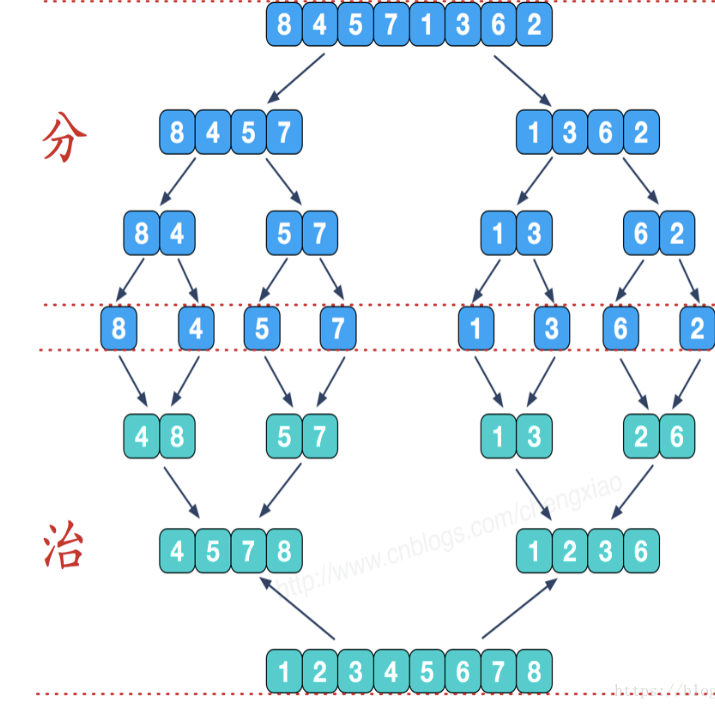
下圖中的倒數第三行表示為第一次合并后的資料,其中一組資料為 4 8 , 5 7,該兩組資料合并方式為:每一小組資料中指定一個指標,指標指向每小組資料的第一個元素,通過指標的偏移指定資料進行有序排列,排列情況如下:
1. p1指向4,p2指向5,p1和p2指向的元素4和5進行比較,較小的資料歸并到一個新的串列中,經過比較p1指向的4會被添加到新的串列中,則p1向后偏移一位,指向了8,p2不變,
2.p1和p2指向的元素8,5繼續比較,則p2指向的5較小,添加到新串列中,p2向后偏移一位,指向了7,
3.p1和p2指向的元素8,7繼續比較,7添加到新串列中,p2偏移指向NULL,比較結束,
4.最后剩下的指標指向的資料(包含該指標指向資料后面所有的資料)直接添加到新串列中即可,
借用一下網上找的圖:
def merge_sort(alist): n = len(alist) #結束遞回的條件 if n <= 1: return alist #中間索引 mid = n//2 left_li = merge_sort(alist[:mid]) right_li = merge_sort(alist[mid:]) #指向左右表中第一個元素的指標 left_pointer,right_pointer = 0,0 #合并資料對應的串列:該表中存盤的為排序后的資料 result = [] while left_pointer < len(left_li) and right_pointer < len(right_li): #比較最小集合中的元素,將最小元素添加到result串列中 if left_li[left_pointer] < right_li[right_pointer]: result.append(left_li[left_pointer]) left_pointer += 1 else: result.append(right_li[right_pointer]) right_pointer += 1 #當左右表的某一個表的指標偏移到末尾的時候,比較大小結束,將另一張表中的資料(有序)添加到result中 result += left_li[left_pointer:] result += right_li[right_pointer:] return result alist = [3,8,5,7,6] print(merge_sort(alist))
寫法二:
思路:將兩邊分別有序(升序逆序要最好一致),的串列合并成一個有序的串列.
i和mid+1兩個索引對應的值對比大小,誰小就把誰拿出來,然后空了的那一個加1,再繼續比,直到i=mid或者mid+=j就停止,等于之后,那一半的數字就空了,就把另一半的數字添加到剛才新建的串列中就好了.
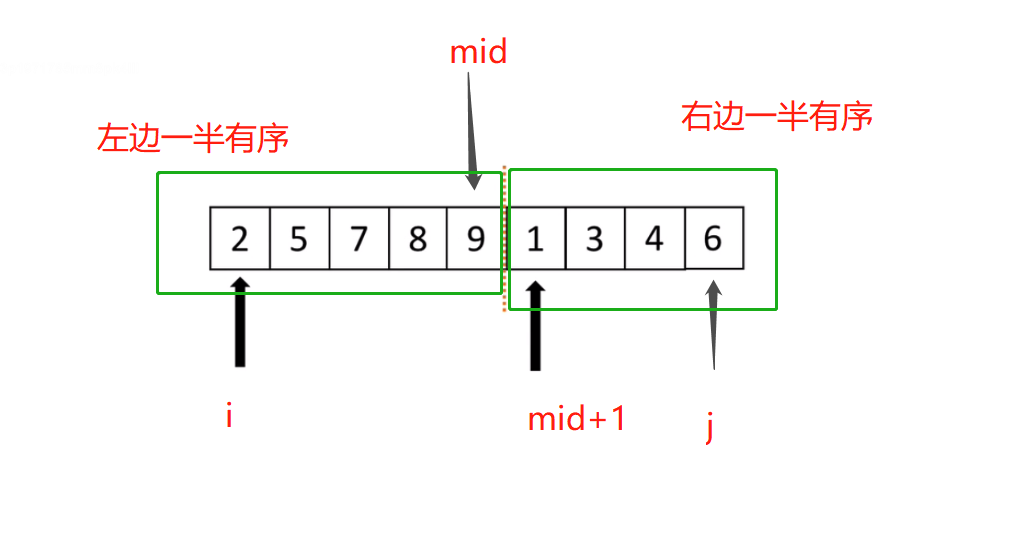
#假設你現在有這樣的串列,兩邊分別都已經排好了順序,執行下面的函式,就能排好序了 def merge(li, low, mid, high): i = low j = mid + 1 ltmp = [] while i<=mid and j<=high: # 只要左右兩邊都有數 if li[i] < li[j]: ltmp.append(li[i]) i += 1 else: ltmp.append(li[j]) j += 1 # while執行完,肯定有一部分沒數了 while i <= mid: ltmp.append(li[i]) i += 1 while j <= high: ltmp.append(li[j]) j += 1 li[low:high+1] = ltmp #用切片,往里面寫值,這里沒用0到n-1是因為后面要用遞回 li = [2,4,5,7,1,3,6,8] merge(li, 0, 3, 7) print(li)
思路:
①分解:將串列越分越小,直到分成生一個元素
②終止條件:一個元素,并且該串列是有序的
③:合并:將兩個只含一個元素的串列進行合并,然后是含兩個元素的串列合并,最終越來越大直至整個串列.
參考下圖:
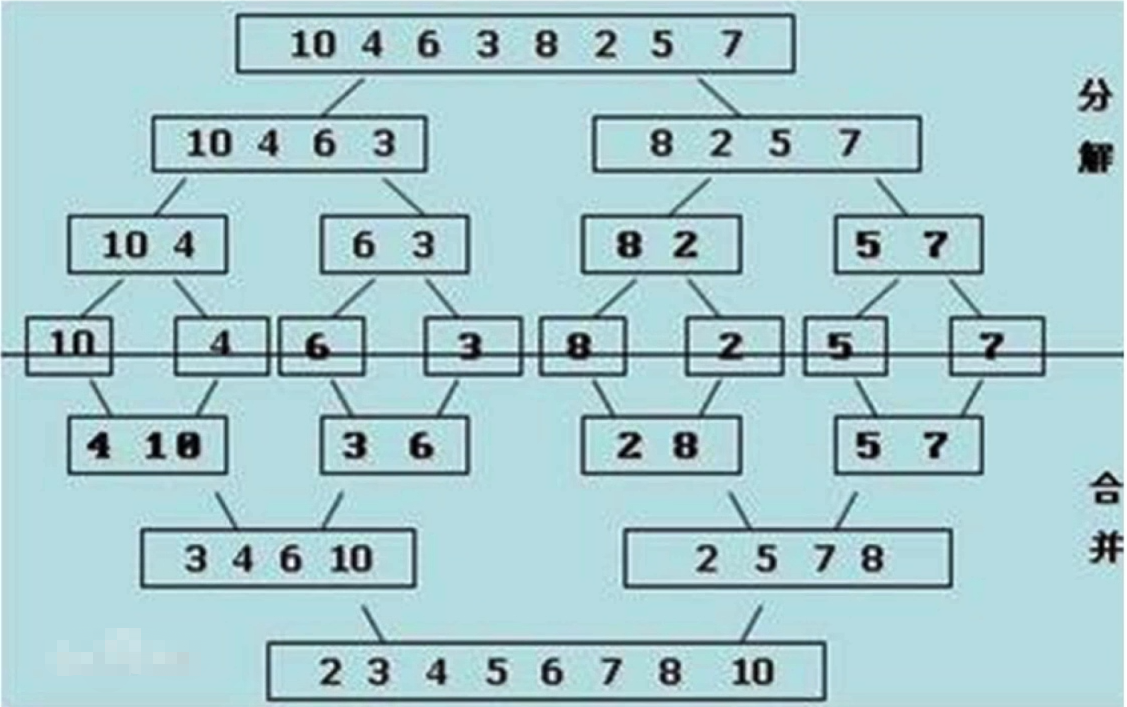
完整代碼:
def merge(li, low, mid, high): i = low j = mid + 1 ltmp = [] while i<=mid and j<=high: # 只要左右兩邊都有數 if li[i] < li[j]: ltmp.append(li[i]) i += 1 else: ltmp.append(li[j]) j += 1 # while執行完,肯定有一部分沒數了 while i <= mid: ltmp.append(li[i]) i += 1 while j <= high: ltmp.append(li[j]) j += 1 li[low:high+1] = ltmp #用切片,往里面寫值,這里沒用0到n-1是因為后面要用遞回 def merge_sort(li, low, high): if low < high: #至少有兩個元素,遞回 mid = (low + high) //2 merge_sort(li, low, mid) merge_sort(li, mid+1, high) merge(li, low, mid, high) li = list(range(1000)) import random random.shuffle(li) print(li) merge_sort(li, 0, len(li)-1) print(li)
7.順序查找
lst=[12,4325345,45,65,3425,76,90,23,434,456,567,56,] def sc(lis,val): #lis是要查的串列,val是要查的元素,看元素在不在這個串列中 for i,v in enumerate(lis): #從頭到尾一個一個找,如果有對應的值,就回傳索引,如果沒有就回傳'沒有' if v==val: return i else: return '沒有' print(sc(lst,90))
8.二分法查找:
時間復雜度:O(logn) 一直除二
前提:必須是有序的序列才能用二分查找
def dichotomy_search(li, val):#li是查找的序列,val是要找的值 left = 0 right = len(li) - 1 while left <= right: # 候選區有值 mid = (left + right) // 2 #mid就是你要找的值所對應的索引,這里每次都等于left和right中間值 if li[mid] == val: return mid elif li[mid] > val: # 待查找的值在mid左側 right = mid - 1 else: # li[mid] < val 待查找的值在mid右側 left = mid + 1 else: return None li = list(range(100000000)) dichotomy_search(li, 38900000)
對比普通查找與二分法查找時間(用了裝飾器):
import time #計算代碼運行時間的裝飾器 def cal_time(func): def wrapper(*args, **kwargs): t1 = time.time() #time.sleep(2) #如果時間太短可能顯示的時間是0.0,暫停2秒,最后在結果中自己減2秒即可 result = func(*args, **kwargs) t2 = time.time() # print(t1) # print(t2) print("%s running time: %s secs." % (func.__name__, t2 - t1)) return result return wrapper #普通查找 @cal_time def linear_search(li, val): for ind, v in enumerate(li): if v == val: return ind else: return None #二分法查找(一定最快) @cal_time def binary_search(li, val): left = 0 right = len(li) - 1 while left <= right: # 候選區有值 mid = (left + right) // 2 if li[mid] == val: return mid elif li[mid] > val: # 待查找的值在mid左側 right = mid - 1 else: # li[mid] < val 待查找的值在mid右側 left = mid + 1 else: return None li = list(range(100000000)) linear_search(li, 38900000) binary_search(li, 38900000)
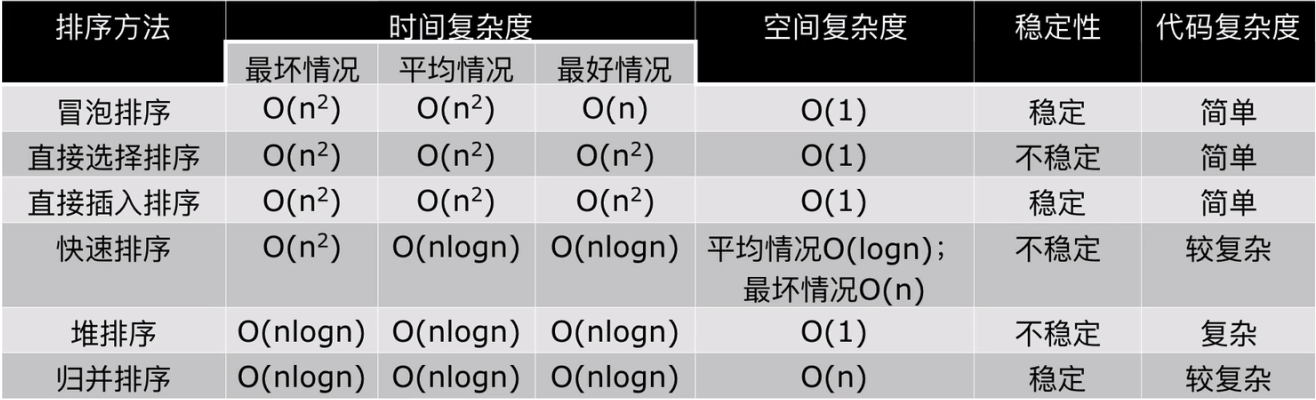
小總結:
low方法:冒泡,插入,選擇
NB方法:快排,堆排,歸并
NB三人組(快排,堆排,歸并):
①時間復雜度都是nlogn
②運行時間:
快排<歸并<堆排
③缺點
快排:極端情況下效率低
歸并:需要額外的記憶體開銷
堆排:再快的排序演算法中相對較慢,運行時間長
注意:
快排中如果用遞回會消耗空間,一層就是1,遞回logn層,空間復雜度就是logn,如果到了最壞情況要走n層,時間復雜度是n2,所以空間復雜度就是n.
9.計數排序
時間復雜度為:O(n) 其實是O(n)+O(n)
注意:
①這種排序方法有前提,必須已知該串列數字的極值(范圍,例如0-100),他的運算時間要比sort短
②它主要處理的數字有很多重復值,例如:該串列中右10個2,23個4,40個8等等
③他消耗記憶體,需要新建個空串列,如果就3個數,范圍是1-1億,那就很麻煩了
代碼:
# 一堆數字,范圍是在100以內,要求從小到大排序 def count_sort(li, max_count=100): count = [0 for _ in range(max_count+1)]#新建個串列與原來的串列最大值等長,并且里面的元素均為0 for val in li: count[val] += 1#有一個對應位置的數,對應位置就加一 li.clear()#清空原來的串列 for ind, val in enumerate(count):#索引ind就是數字,值val就是對應數字的個數 for i in range(val): li.append(ind) import random li = [random.randint(1,100) for _ in range(10000)]#隨機生成1-100的數字10000個 print('原始:',li) count_sort(li) print('排序:',li)
10.桶排序(用的不是很多)
時間復雜度:
取決于原串列中資料的分布,也就是對不同資料排序時采取不同的分桶策略
平均時間復雜度:O(n+k)k是一個小桶的長度
最壞情況時間復雜度:O(n2k)例如n個數字,n-1個數字都在一個桶,其他的桶里只有一個數字
空間復雜度:
O(nk) 你需要新建空串列(像桶一樣里面裝多個小桶)來裝你原來的資料
桶排序是在計數排序之上發展而來,把一堆數字(最好知道大部分數字的所在范圍最好),然后把一個大區間分成多個小區間,每個小區間都當成計數排序那樣來算,小區間都排序后,最后把所有的小區間按照順序加到一起就成了桶排序.
代碼:
# 桶排序 import random def bucket_sort(li, n=100, max_num=10000):#n表示把10000分成幾個桶,max_num是串列中這些元素最大的數是10000 buckets = [[] for _ in range(n)] # 創建桶,一個大串列,里面套著很多空串列 for var in li: i = min(var // (max_num // n), n-1) # i 表示var放到幾號桶里,因為最后一個桶的最后一個數字是9999, # 而10000超了,所以這里取最小,當你到最后一個數字時,也讓你放到最后一個桶里 #這里你再有大于10000的數字也會自然放到最后一個桶里,不會在乎超過范圍而排不了了 buckets[i].append(var) # 把var加到桶里邊 # 保持桶內的順序 for j in range(len(buckets[i])-1, 0, -1): if buckets[i][j] < buckets[i][j-1]: buckets[i][j], buckets[i][j-1] = buckets[i][j-1], buckets[i][j] else: break sorted_li = [] for buc in buckets: sorted_li.extend(buc) return sorted_li li = [random.randint(0,10000) for i in range(100000)] l1=[99080,65432,123123321,55555,666666,10001,2143234,67867,12321] #l1中的幾個數字超了10000,但是也都能放到最后一個桶里面來進行排序, # 因為上面的min內置函式把他們都放到了最后一個桶里面了 li.extend(l1) print('初始:',li) li = bucket_sort(li) print('排序后:',li)
11.基數排序
時間復雜度:O(kn)
他和快排比時間快慢,與k有關或者說是數字分布有關,快排確實快,但這里的k相當于是lgn 是以10為底數,但是快排nlogn,他的log是以2為底,所以,如果k不是很大,或者說串列中最大數字不是很大(數字數量沒關系多少都無所謂),這時基數排列要比快排還要快.
但是基數排序要占空間,快排不占空間.
空間復雜度:O(k+n)
(k是最大數字的位數)
思路:
他的思路類在桶排序基礎之上,給你一個串列,把這些數字按照個位從小到大排序(0,1,2,3...9),然后將排序完的數列拿出來,再按照十位如剛才排序...直到最大數字的最高位也排序過,這樣拿到的串列就是排好序的了
注意:
這里不需要對比某兩個數字的大小關系,只需要按照順序多次排數,就可以把串列順序排好,他的桶本身是有順序的.
代碼:
# 基數排序 def radix_sort(li): max_num = max(li) # 先找到這個串列中的最大值,最大值 9->1, 99->2, 888->3, 10000->5 it = 0 while 10 ** it <=max_num:#其實這里可以用log()函式取10的對數,其實就是判斷你最大數字有幾位 buckets = [[] for _ in range(10)] #每次排序都要減建10個桶,因為是十進制,每一位都要排序排序,每一位上都是0,1,2,3...9 for var in li:#這里是回圈數列中的每一個數字 # 987 it=1 987//10->98 98%10->8; it=2 987//100->9 9%10=9 digit =(var // 10 ** it) % 10 #這里根據it的值來確定這次回圈取的是哪一位的數字,%10就是除以10取余數 buckets[digit].append(var) # 分桶完成 li.clear()#清空原串列 for buc in buckets: li.extend(buc)#安找0,1,2,...9的順序將每個桶的數字都添加到空串列中即可 # 把數重新寫回li,只要沒超過最大數字就一直向下走一位并排序 it += 1 import random li = [random.randint(0,1000) for _ in range(10000)] random.shuffle(li) print('原資料:',li) radix_sort(li) print('排序完的資料:',li)
12.排序練習題:
第一題:
# 給兩個字串:s和t,判斷t是不是s重新排列得到的字串 # s='ana' # t='aan' # 回傳true # s='cat' t='wwe' # 回傳false # 法一: def xx(s,t): ss=list(s) tt=list(t) ss.sort() tt.sort() return ss==tt print(xx(s,t)) # 法一(簡寫): def xx(s,t): return sorted(list(s))==sorted(list(t)) print(xx(s,t)) # 法二: def xx(s,t): dict1={} #記錄樣式: {'a':1,'b':2}某個字母出現的次數用他的值來表示 dict2={} for i in s: dict1[i]=dict1.get(i,0)+1 #get的意思是字典里有i這個鍵就獲取他的值,如果沒有這個鍵(i),就寫個0放進去,再取出來時+1 for i in t: dict2[i]=dict2.get(i,0)+1 return dict1==dict2 print(xx(s,t))
第二題:
# 給一個m*n的二維串列lst,查找一個數k是否在其中 # m*n的串列有以下特性: # ①每一行的串列都已經從左到右順序排好 # ②每一行第一個數都比上一行的最后一個數大 lst=[ [1 , 3, 5, 7], [10,11,16,20], [23,30,34,50] ] k=5 # 法一: def xx(l,k): for l1 in l: if k in l1: return True return False print(xx(lst,k)) # 法二: def xx(l,k): h=len(l)#相當于是m,表示有多少行 if h==0: return False #給的串列是空的,什么也找不到 w=len(l[0])#相當于是n,表示有多少列 if w==0: return False left =0 #第一個索引 right =w*h-1#串列最后一個索引 while left <=right: mid=(left+right)//2 i=mid//w#求行數 j=mid%w if l[i][j]==k: return True elif l[i][j]>k: right=mid-1 else: left=mid+1 else: return False print(xx(lst,k))
第三題:
# 給一個整數k,和一個串列lst(注意:這里的串列不一定是有序的),在串列中找到倆數的和為k,并回傳這倆數的索引[i,j] lst=[1,2,3,4,5,0,9,7] k=3 # 回傳[0,1] # 法一: def xx(l,m): n=len(l) for i in range(n): for j in range(i): #第二個for回圈如果寫range(n),那么會回圈兩次,浪費時間,并且會出現重復的情況 #如回傳[1,2]和[2,1],還有就是[3,3]正好找的數是索引3的樹的二倍 #這里寫i表示第二次只找i之前的數字和i相加,不會重復 #如果寫range(i+1,n)那就是找i后面的數字和i相加,也不會重復 if l[i]+l[j]==m: return sorted([i,j]) print(xx(lst,k)) # 法二: # 用二分查找輔助 def binary_serch(l,left,right,val): while left <= right:#保證查找的地方有值 mid=(left+right)//2 if l[mid][0]==val: return mid elif l[mid][0]>val:#查找的值在mid的左邊 right=mid-1 else: #l[mid][0]<val查找的值在mid的右邊 left=mid+1 else: return '沒有' def xx(l,k): new_list=[[num,i] for i , num in enumerate(l)]#將原來的串列中的元素和他的索引存到一起 new_list.sort(key=lambda x:x[0])#用new_list中的num來排序 for i in range(len(new_list)): a=new_list[i][0]#找到其中一個值 b=k-a #用減法去找b if b>=a:#b大于a,就在a的右邊的部分用二分查找,來找b j=binary_serch(new_list,i+1,len(new_list)-1,b) else:#b小于等于a,就在a的左邊找b j = binary_serch(new_list, 0, i- 1, b) if j: #找到b就結束了 return sorted([new_list[i][1],new_list[j][1]]) print(xx(lst,k))
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/156174.html
標籤:Python
下一篇:使用 PyQt5 實作圖片查看器