認識爬蟲
爬蟲是什么:
爬取互聯網上的資訊
資料挖掘->資料清洗(得到有效的資訊)
爬蟲分類:
通用爬蟲:是搜索引擎抓取系統(百度,谷歌)的重要組成,主要目的是將互聯網上的網頁下載到本地,形成一個互聯網內容的鏡像備份
抓取網頁 -> 資料存盤 -> 預處理 -> 提供檢索,網站排名
聚焦爬蟲:是"面向特定主體需求"的一種網路爬蟲程式,它與通用搜索引擎爬蟲的區別在于:聚焦爬蟲在實施網頁抓取時會對內容進行處理篩選,盡量保證只抓取與需求相關的網頁資訊
請求和回應
前端:網頁展現
中間層:資料處理
資料庫:資料存盤
服務器(回應)客戶端(請求)
URL
(Uniform/Universal Resource Locator):統一資源定位符,是用于完整地描述Internet上網頁和其他資源的地址的一種標識方法
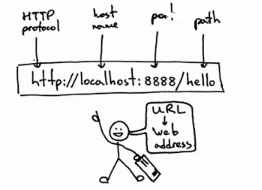
基本格式:scheme://host[:port#]/path/.../[?query-string][#anchor]
scheme:協議
host:服務器的IP地址或者域名
port#:服務器的埠(如果是走協議默認埠,預設埠80)
query-string:引數,發送給http服務器的資料
anchor:錨(跳轉到網頁的指定錨點位置)
GET請求和POST請求
Get是從服務器上獲取資料,Post是向服務器傳輸資料,Post更加安全
Get請求:引數顯示都顯示在瀏覽器網址上,HTTP服務器根據該請求所包含的URL中的引數來產生回應內容,即"Get"請求的引數是URL的一部分
Post請求:引數在請求體當中,訊息長度沒有限制而且以隱式的方式進行發送,通常用來向HTTP服務器提交量比較大的資料,請求引數包含在"Content-Type"訊息頭里,指明該訊息體的媒體型別和編碼
瀏覽器開發者工具
按下F12,進入開發者模式;
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/156191.html
標籤:Python