目錄
- 樸素貝葉斯演算法的中文郵件分類
- 1.樸素貝葉斯演算法原理
- 2.專案簡介
- 3.專案步驟
- 4.代碼
- 5.結果
??我有新開了一個專欄,講解python機器學習的一些實體,本次要學習的是樸素貝葉斯演算法的中文郵件分類,
樸素貝葉斯演算法的中文郵件分類
1.樸素貝葉斯演算法原理
??貝葉斯理論:根據一個已發生事件的概率計算另一個事件發生的概率,
??樸素:在整個程序中只做最原始,最簡單的假設,例如假設特征之間相互獨立并且特征同等重要,
??簡單邏輯:用此演算法進行分類時,計算未知樣本屬于已知類的概率,然后選擇概率最大的樣本作為分類結果,
??簡介:樸素貝葉斯分類器發源于古典數學理論,有著堅實的數學基礎,以及穩定的分類效率,貝葉斯方法是以貝葉斯理論為基礎,使用概率統計的知識對樣本資料集進行分類,誤判率是很低的,貝葉斯方法的特點是結合先驗概率和后驗概率,即避免了只使用先驗概率的主觀偏見,也避免了單獨使用樣本資訊的過擬合現象,在資料集較大的情況下表現出較高的準確率,
??樸素貝葉斯方法是在貝葉斯演算法的基礎上進行了相應的簡化,即假定給定目標值時屬性之間相互條件獨立,屬性變數比重差不多,極大地簡化了貝葉斯方法的復雜性,但分類效果有所降低,
2.專案簡介
??專案是利用樸素貝葉斯演算法對中文郵件進行分類,郵件有垃圾和非垃圾郵件,統計出現最多的有效詞匯,然后統計每個郵件里的有效詞匯分別在這個檔案里出現的次數,構建特征向量,作為訓練集對郵件進行訓練,并分類,
3.專案步驟
(1)從電子郵箱中收集足夠多的垃圾郵件和非垃圾郵件的內容作為訓練集,
(2)讀取全部訓練集,洗掉其中的干擾字符,例如【】*,、,等等,然后分詞,再洗掉長度為1的單個字,這樣的單個字對于文本分類沒有貢獻,剩下的詞匯認為是有效詞匯,
(3)統計全部訓練集中每個有效詞匯的出現次數,截取出現次數最多的前N(可以根據實際情況進行調整)個,
(4)根據每個經過第2步預處理后的垃圾郵件和非垃圾郵件內容生成特征向量,統計第3步中得到的N個詞語分別在該郵件中的出現頻率,每個郵件對應于一個特征向量,特征向量長度為N,每個分量的值表示對應的詞語在本郵件中出現的次數,例如,特征向量[3, 0, 0, 5]表示第一個詞語在本郵件中出現了3次,第二個和第三個詞語沒有出現,第四個詞語出現了5次,
(5)根據第4步中得到特征向量和已知郵件分類創建并訓練樸素貝葉斯模型,
(6)讀取測驗郵件,參考第2步,對郵件文本進行預處理,提取特征向量,
(7)使用第5步中訓練好的模型,根據第6步提取的特征向量對郵件進行分類,
4.代碼
??匯入各種庫:
from re import sub
from os import listdir
from collections import Counter
from itertools import chain
from numpy import array
from jieba import cut
from sklearn.naive_bayes import MultinomialNB
??獲取每一封郵件中的所有有效詞語:
def getWordsFromFile(txtFile):
# 獲取每一封郵件中的所有詞語
words = []
# 所有存盤郵件文本內容的記事本檔案都使用UTF8編碼
with open(txtFile, encoding='utf8') as fp:
for line in fp:
# 遍歷每一行,洗掉兩端的空白字符
line = line.strip()
# 過濾干擾字符或無效字符
line = sub(r'[.【】0-9、—,,!~\*]', '', line)
# 分詞
line = cut(line)
# 過濾長度為1的詞
line = filter(lambda word: len(word)>1, line)
# 把本行文本預處理得到的詞語添加到words串列中
words.extend(line)
# 回傳包含當前郵件文本中所有有效詞語的串列
return words
??訓練并保存結果
# 存放所有檔案中的單詞
# 每個元素是一個子串列,其中存放一個檔案中的所有單詞
allWords = []
def getTopNWords(topN):
# 按檔案編號順序處理當前檔案夾中所有記事本檔案
# 訓練集中共151封郵件內容,0.txt到126.txt是垃圾郵件內容
# 127.txt到150.txt為正常郵件內容
txtFiles = [str(i)+'.txt' for i in range(151)]
# 獲取訓練集中所有郵件中的全部單詞
for txtFile in txtFiles:
allWords.append(getWordsFromFile(txtFile))
# 獲取并回傳出現次數最多的前topN個單詞
freq = Counter(chain(*allWords))
return [w[0] for w in freq.most_common(topN)]
# 全部訓練集中出現次數最多的前600個單詞
topWords = getTopNWords(600)
# 獲取特征向量,前600個單詞的每個單詞在每個郵件中出現的頻率
vectors = []
for words in allWords:
temp = list(map(lambda x: words.count(x), topWords))
vectors.append(temp)
vectors = array(vectors)
# 訓練集中每個郵件的標簽,1表示垃圾郵件,0表示正常郵件
labels = array([1]*127 + [0]*24)
# 創建模型,使用已知訓練集進行訓練
model = MultinomialNB()
model.fit(vectors, labels)
# 下面是保存結果
joblib.dump(model, "垃圾郵件分類器.pkl")
print('保存模型和訓練結果成功,')
with open('topWords.txt', 'w', encoding='utf8') as fp:
fp.write(','.join(topWords))
print('保存topWords成功,')
??加載并使用訓練結果
model = joblib.load("垃圾郵件分類器.pkl")
print('加載模型和訓練結果成功,')
with open('topWords.txt', encoding='utf8') as fp:
topWords = fp.read().split(',')
def predict(txtFile):
# 獲取指定郵件檔案內容,回傳分類結果
words = getWordsFromFile(txtFile)
currentVector = array(tuple(map(lambda x: words.count(x),
topWords)))
result = model.predict(currentVector.reshape(1, -1))[0]
return '垃圾郵件' if result==1 else '正常郵件'
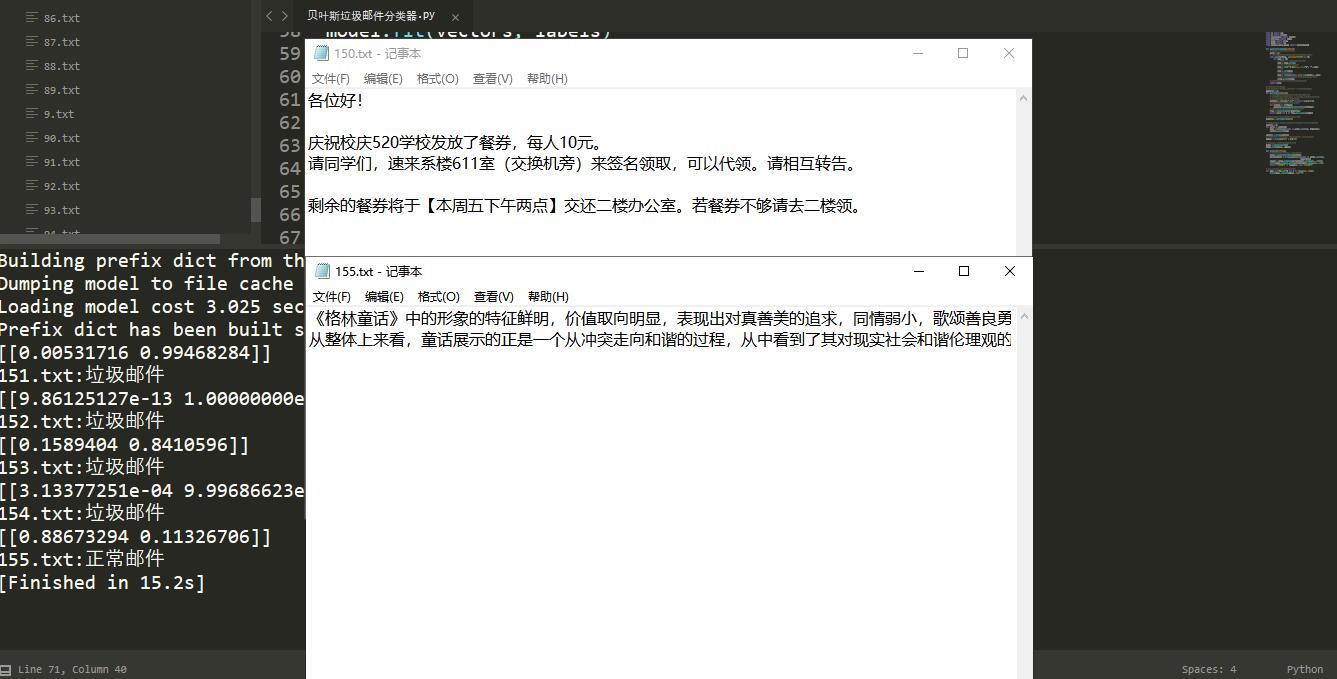
# 151.txt至155.txt為測驗郵件內容
for mail in ('%d.txt'%i for i in range(151, 156)):
print(mail, predict(mail), sep=':')
5.結果
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/156493.html
標籤:Python
上一篇:月考二