1. 分類演算法-K近鄰演算法(KNN)
定義:如果一個樣本在特征空間中的k個最相似(即特征空間中最鄰近)的樣本中的大多數屬于某一個類別,則該樣本也屬于這個類別,
來源:KNN演算法最早是由Cover和Hart提出的一種分類演算法,
1.1 計算距離公式
兩個樣本的距離可以通過如下公式計算,又叫歐式距離,
比如說,a(a1,a2,a3),b(b1,b2,b3)
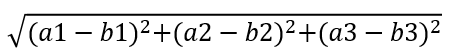
1.2 例子
根據前面幾個電影的資料來判斷最后一個電影是什么型別的電影,
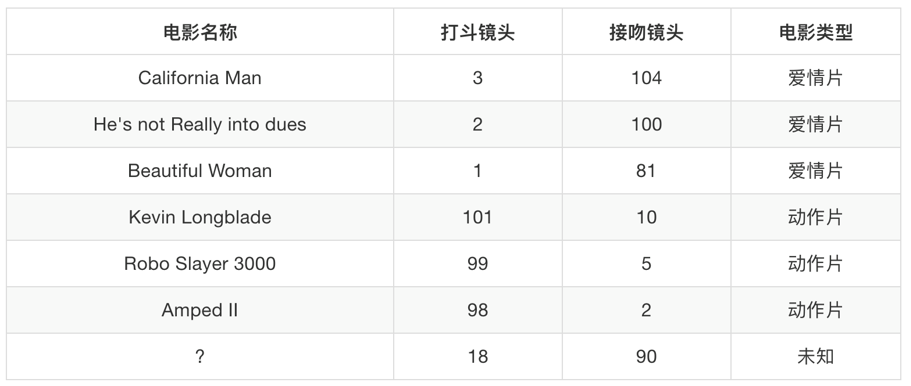
我們可以很容易的看出,最后一個是愛情片,那么程式如何判斷呢?
根據我們前面說的距離公式,套進去,就可以得到前面的電影和最后一部電影的距離,
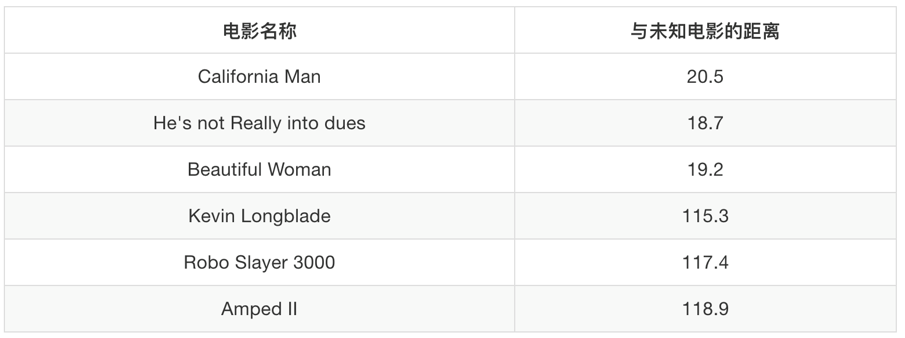
1.3 sklearn K-近鄰演算法API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm='auto')
n_neighbors:int,可選(默認= 5),k_neighbors查詢默認使用的鄰居數
algorithm:{'auto','ball_tree','kd_tree','brute'},可選用于計算最近鄰居的演算法:'ball_tree'將會使用 BallTree,'kd_tree'將使用 KDTree,'auto'將嘗試根據傳遞給fit方法的值來決定最合適的演算法, (不同實作方式影響效率)
1.4 K近鄰演算法-預測入住位置

資料鏈接:https://www.kaggle.com/c/facebook-v-predicting-check-ins/data
檔案說明
- train.csv,test.csv
- row_id:簽到事件的ID
- xy:坐標
- 精度:位置精度
- 時間:時間戳
- place_id:商家的ID,這是您要預測的目標
- sample_submission.csv-帶有隨機預測的正確格式的樣本提交檔案
資料的處理:
1、縮小資料集范圍
DataFrame.query()
2、處理日期資料
pd.to_datetime
pd.DatetimeIndex
3、增加分割的日期資料
4、洗掉沒用的日期資料
pd.drop
5、將簽到位置少于n個用戶的洗掉
place_count =data.groupby('place_id').aggregate(np.count_nonzero)
tf = place_count[place_count.row_id > 3].reset_index()
data = https://www.cnblogs.com/liuhui0308/p/data[data['place_id'].isin(tf.place_id)]
from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.neighbors import KNeighborsClassifier from sklearn.preprocessing import StandardScaler import pandas as pd def knncls(): """ K-近鄰預測用戶簽到位置 :return:None """ # 讀取資料 data = https://www.cnblogs.com/liuhui0308/p/pd.read_csv("./data/FBlocation/train.csv") # print(data.head(10)) # 處理資料 # 1、縮小資料,查詢資料曬訊 data = https://www.cnblogs.com/liuhui0308/p/data.query("x > 1.0 & x < 1.25 & y > 2.5 & y < 2.75") # 處理時間的資料 time_value = https://www.cnblogs.com/liuhui0308/p/pd.to_datetime(data['time'], unit='s') print(time_value) # 把日期格式轉換成 字典格式 time_value =https://www.cnblogs.com/liuhui0308/p/ pd.DatetimeIndex(time_value) # 構造一些特征 data['day'] = time_value.day data['hour'] = time_value.hour data['weekday'] = time_value.weekday # 把時間戳特征洗掉 data = https://www.cnblogs.com/liuhui0308/p/data.drop(['time'], axis=1) print(data) # 把簽到數量少于n個目標位置洗掉 place_count = data.groupby('place_id').count() tf = place_count[place_count.row_id > 3].reset_index() data = data[data['place_id'].isin(tf.place_id)] # 取出資料當中的特征值和目標值 y = data['place_id'] x = data.drop(['place_id'], axis=1) # 進行資料的分割訓練集合測驗集 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25) # 特征工程(標準化) std = StandardScaler() # 對測驗集和訓練集的特征值進行標準化 x_train = std.fit_transform(x_train) x_test = std.transform(x_test) # 進行演算法流程 # 超引數 knn = KNeighborsClassifier() # # fit, predict,score # knn.fit(x_train, y_train) # # # 得出預測結果 # y_predict = knn.predict(x_test) # # print("預測的目標簽到位置為:", y_predict) # # # 得出準確率 # print("預測的準確率:", knn.score(x_test, y_test)) # 構造一些引數的值進行搜索 param = {"n_neighbors": [3, 5, 10]} # 進行網格搜索 gc = GridSearchCV(knn, param_grid=param, cv=2) gc.fit(x_train, y_train) # 預測準確率 print("在測驗集上準確率:", gc.score(x_test, y_test)) print("在交叉驗證當中最好的結果:", gc.best_score_) print("選擇最好的模型是:", gc.best_estimator_) print("每個超引數每次交叉驗證的結果:", gc.cv_results_) return None if __name__ == "__main__": knncls()
1.5 k-近鄰演算法優缺點
優點:
簡單,易于理解,易于實作,無需估計引數,無需訓練
缺點:
懶惰演算法,對測驗樣本分類時的計算量大,記憶體開銷大
必須指定K值,K值選擇不當則分類精度不能保證
使用場景:小資料場景,幾千~幾萬樣本,具體場景具體業務去測驗
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/156502.html
標籤:Python