前言
之前,我們已經在HashMap上面暴打了面試官,沒看過的讀者可以看看哦HashMap 怎么聊出花來?,今天!,輝先森帶讀者一起解讀ConcurrentHashMap!
一、為什么有CurrentHashMap?
通過前章的學習哦,我們有了解到,HashMap做的優化以及其遺留的執行緒安全的問題,
那為什么要多執行緒呢?
1. 更好的利用處理器
在多核場景下,使用多執行緒技術,將計算邏輯分配搭配多個處理器核心,就會顯著減少程式的處理時間,并且隨核數的加入而變得更加的有效率,
2. 更快的相應時間
在多執行緒下,可將資料一致性不強的操作派給其他執行緒處理,好處:相應用戶請求執行緒能更快的處理完成,縮短回應時間,提高用戶體驗,
二、解決HashMap執行緒不安全
1.HashTable
hashtable對 get/put所有相關的操作都加上synchronized標志,雖然實作了執行緒安全,但是代價太大了,相當于對整個哈希表加了一把大鎖,這樣在競爭激烈的并發場景性能太差了,(不推薦考慮)
2.ConcurrentHashMap
- 使用Segment分段鎖技術,將資料分成一段一段的存盤,然后給每一段資料配一把鎖,當一個執行緒占用鎖訪問其中一段資料時,不阻塞訪問其他段的資料,可以看成是有多個hashtable,好處:使用Segment分段鎖技術減少了鎖的粒度提高了并發的能力,
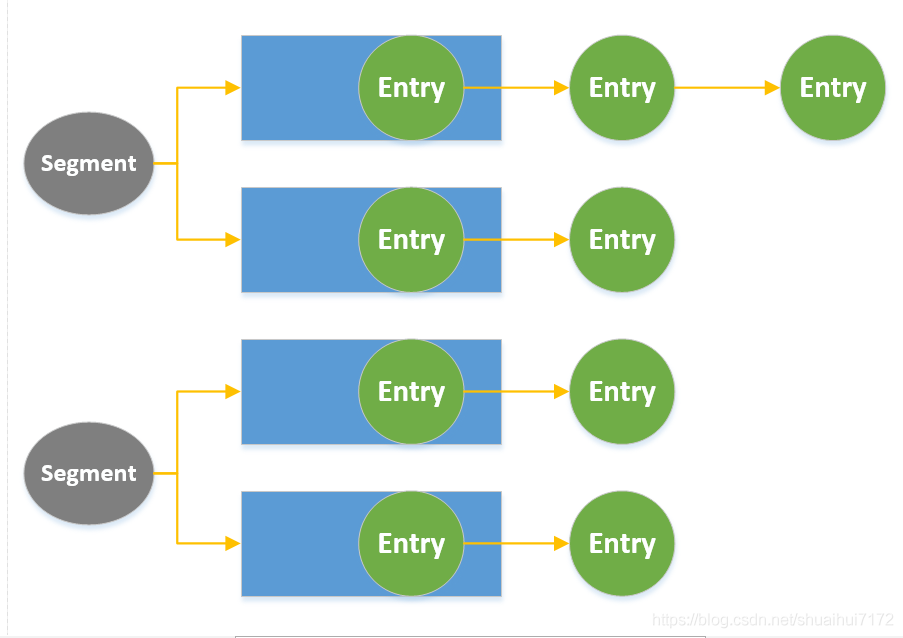
- JDK1.8升級:在JDK1.8的HashMap的基礎上套一個安全措施,采用CAS+Synchronize來保障執行緒的安全,使得性能進一步的提高,
我們來看看put()與get()的流程吧,
put()的流程
1. 如果沒有初始化就先去呼叫initTable()方法進行初始化的程序,
2. 如果有其他執行緒在擴容,就將當前執行緒加入到擴容任務中,幫助正在擴容的執行緒移動資料,提高效率,
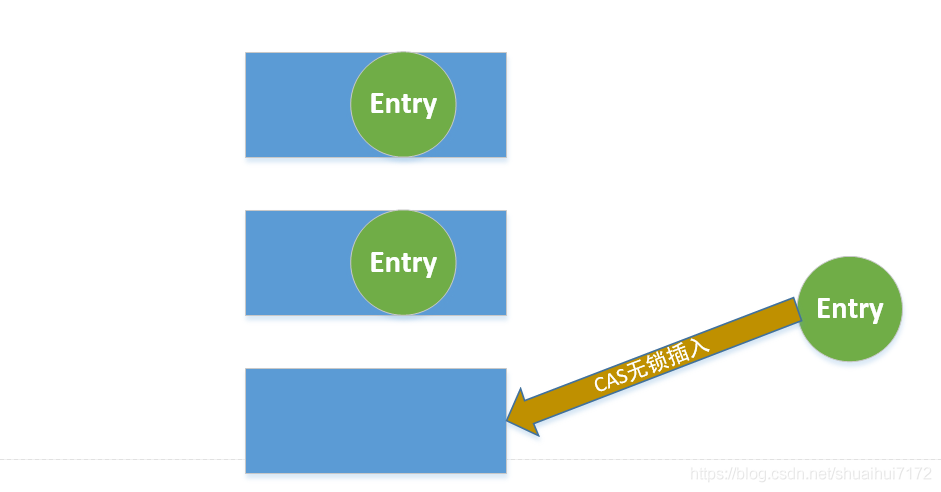
3. 無hash沖突就進行CAS插入,
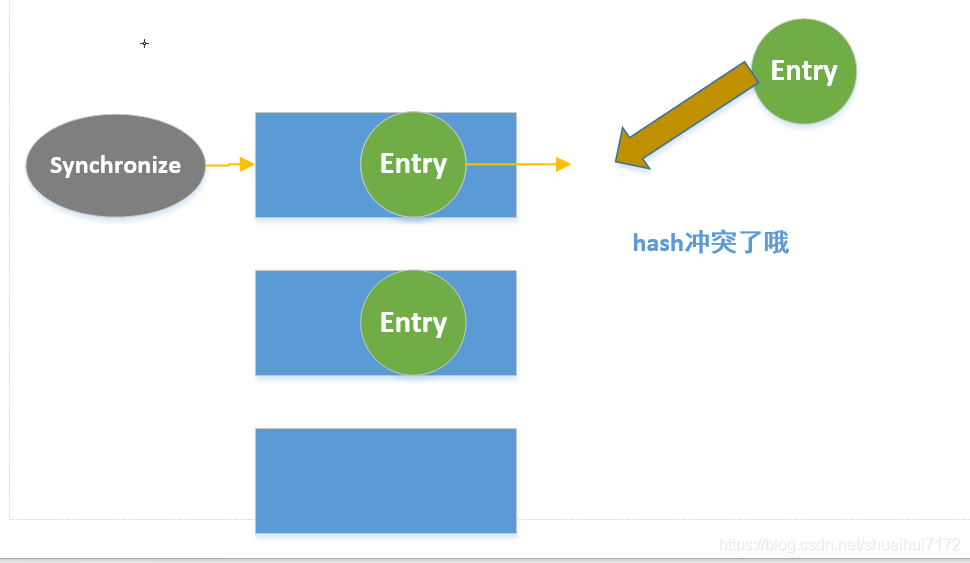
4. 有hash沖突,就呼叫Synchronize標記鎖住當前的位桶,然后在進行插入-->(Entry過8就變紅黑樹),
5. 在檢查是否需要擴容,
/**put方法主要是呼叫putVal方法*/
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
//資料不合法,拋出例外
if (key == null || value == null) throw new NullPointerException();
//計算索引的第一步,傳入鍵值的hash值
int hash = spread(key.hashCode());
int binCount = 0; //保存當前節點的長度
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
if (tab == null || (n = tab.length) == 0)
tab = initTable(); //初始化Hash表
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//利用CAS操作將元素插入到Hash表中
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin(插入null的節點,無需加鎖)
}
else if ((fh = f.hash) == MOVED) //f.hash == -1
//正在擴容,當前執行緒加入擴容
tab = helpTransfer(tab, f);
else if (onlyIfAbsent && fh == hash && // check first node
((fk = f.key) == key || fk != null && key.equals(fk)) &&
(fv = f.val) != null)
return fv;
else {
V oldVal = null;
//當前節點加鎖
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
//插入的元素鍵值的hash值有節點中元素的hash值相同,替換當前元素的值
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
//替換當前元素的值
e.val = value;
break;
}
Node<K,V> pred = e;
//沒有相同的值,直接插入到節點中
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
//節點為樹
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
//替換舊值
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
}
if (binCount != 0) {
//如果節點長度大于8,轉化為樹
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}get()的流程
1. 通過鍵值的hash計算索引位置,如果滿足條件,直接回傳對應的值;
2. 如果相應節點的hash值小于0 ,即該節點在進行擴容,直接在呼叫ForwardingNodes節點的find方法進行查找,
3. 否則不在擴容的話,遍歷當前節點直到找到對應的元素,
ConcurrentHashMap的get方法就是從Hash表中讀取資料,而且與擴容不沖突,該方法沒有同步鎖,
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
//滿足條件直接回傳對應的值
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//e.hash<0,正在擴容
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
//遍歷當前節點
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}三、當被問到怎么設計一個哈希表,我們應該考慮哪些,
- 先把HashMap的原理一股腦砸給他,因為java1.8的HashMap設計是真的精妙,種種的優化都可以砸,
- 接著引申到執行緒安全的問題,把ConcurrentHashMap的原理丟給他,
- 殺手锏,解決高并發的問題,通過上面分析ConcurrentHashMap的原理,我們可以發現,put()操作是帶鎖的而get()操作是不需要帶鎖的,我們可以在這里搞搞事情,我們可以在ConcurrentHashMap的基礎上在加一個位桶陣列去解決高并發的問題,我們看看怎么操作吧,
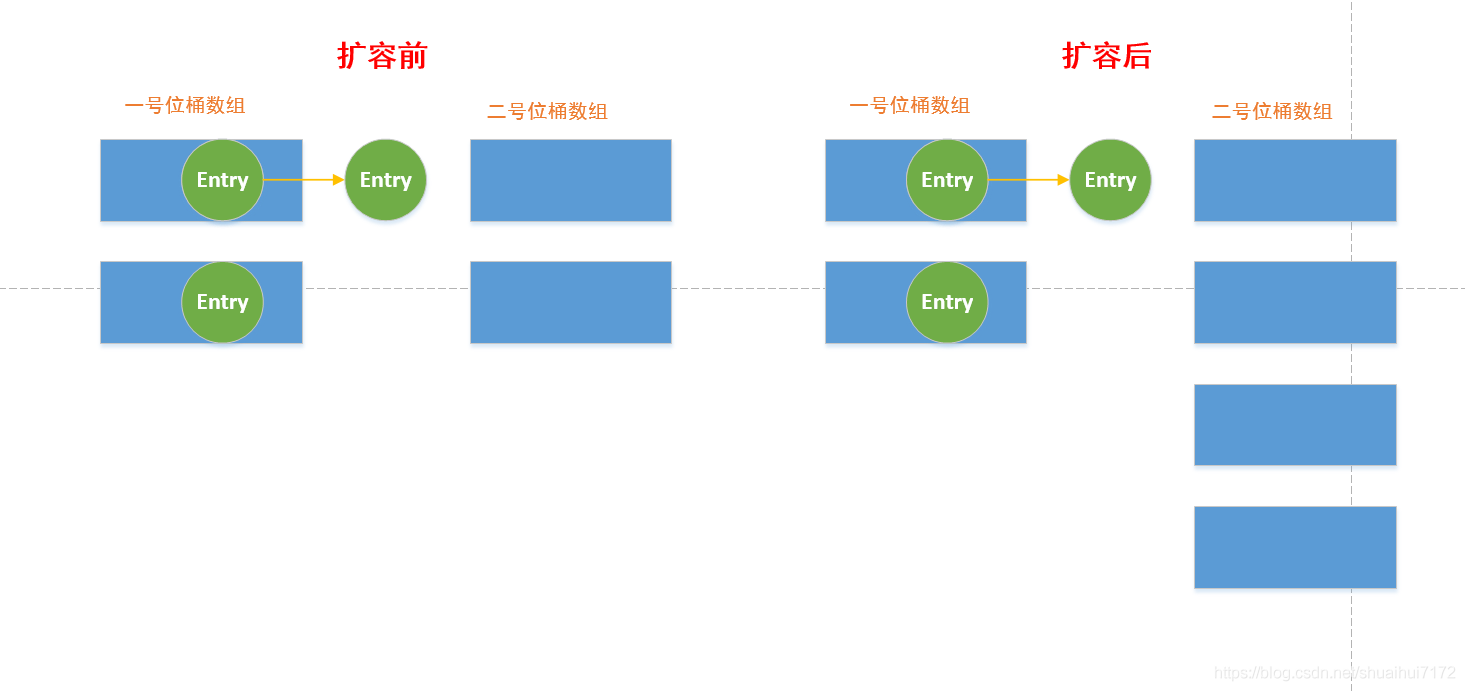
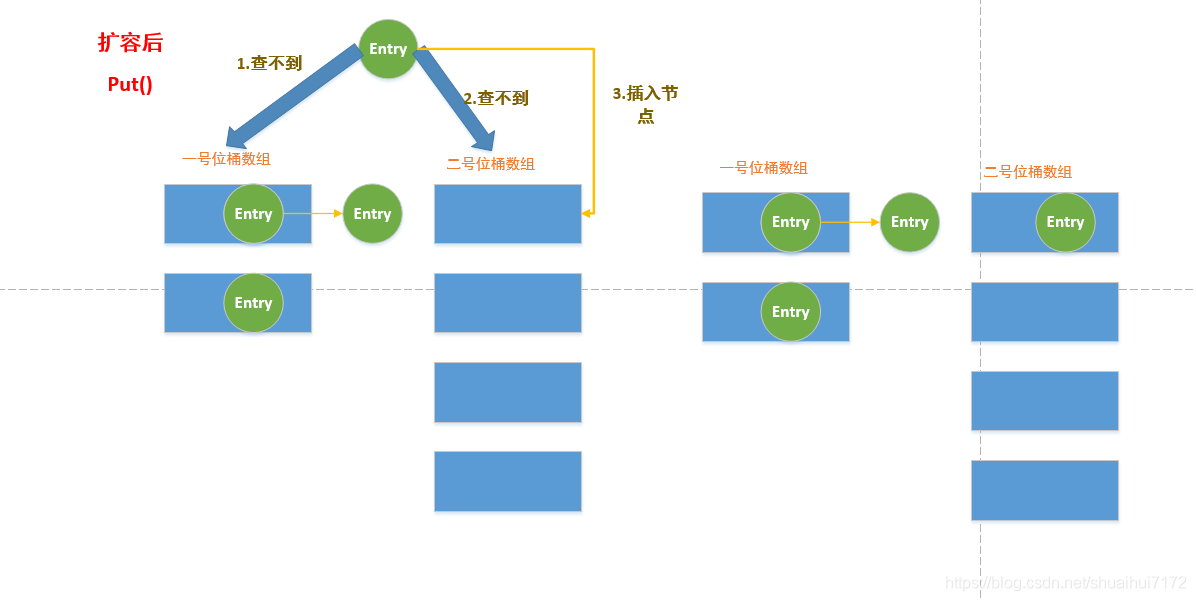
1. 假如當前的一號位桶陣列需要擴容了,一般我們是重新創建一個2倍長度的陣列地址去擴容,當此時是不能進行put()操作的,現在我們改變策略,將二號位桶陣列進行長度的增加,
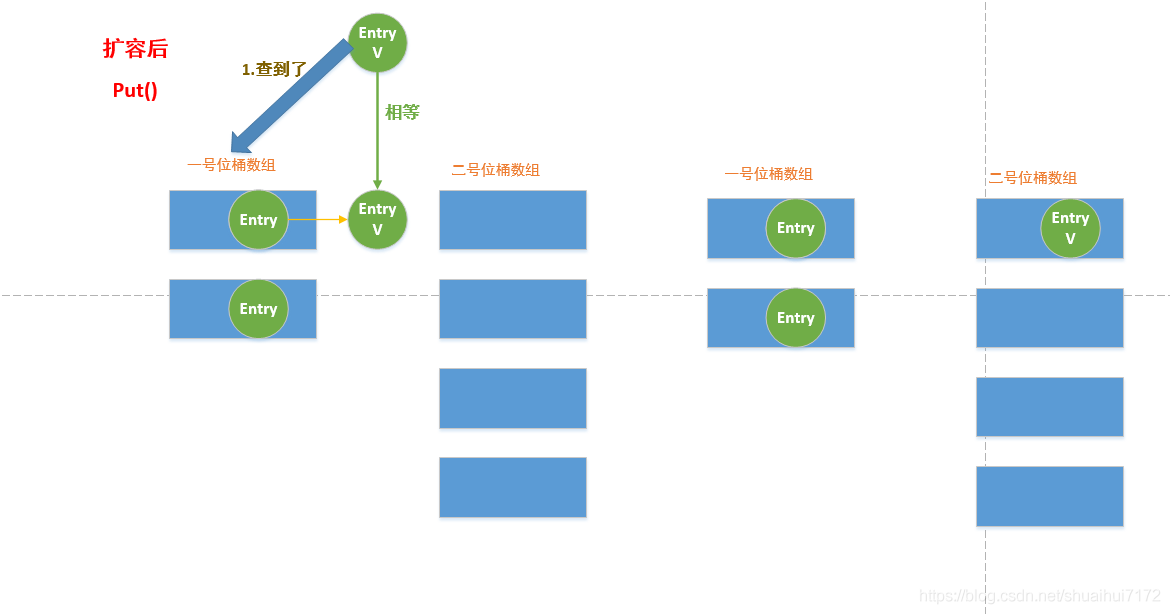
2. 接下來如果遇到put()操作,就先去一號位桶陣列查找是否存在相同的Entry和二號位桶陣列查找是否存在相同的Entry,如果都沒有就將這個要插入進來的節點放在二號位桶陣列里面,在一號位桶陣列查到,就移動節點到二號陣列里面,
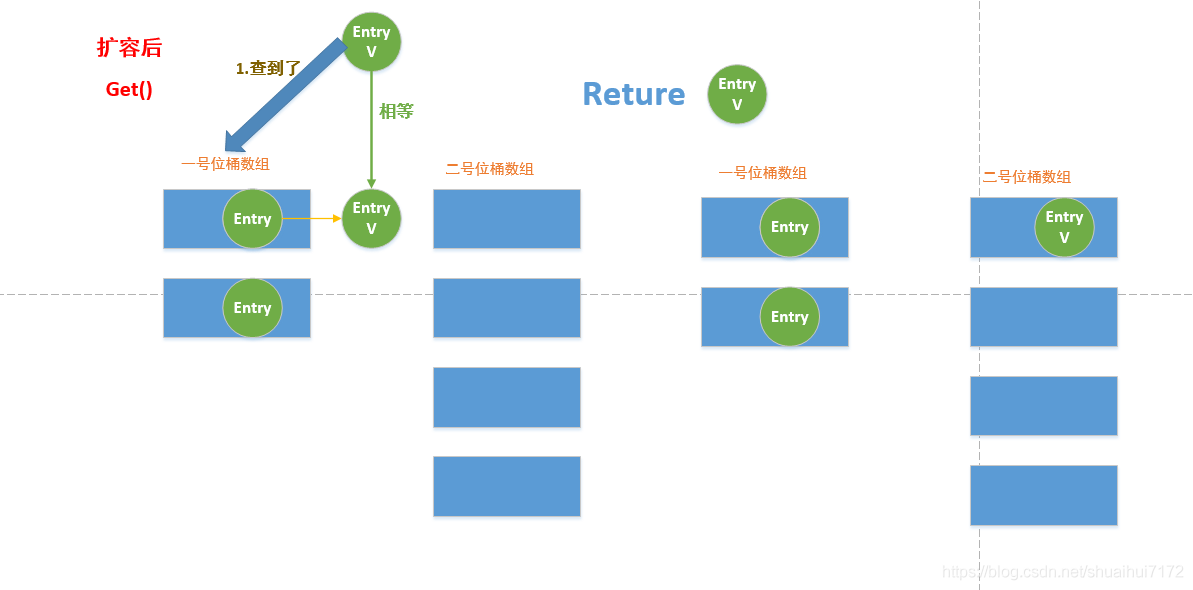
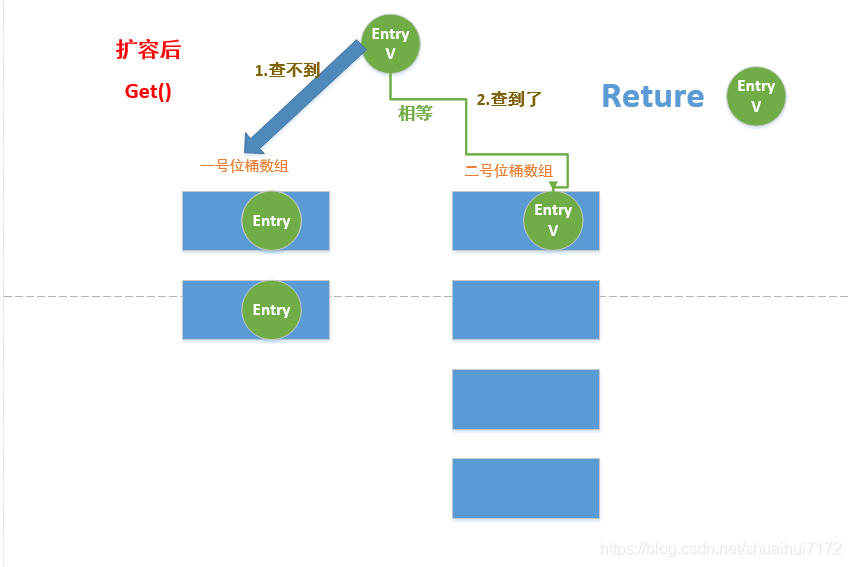
3. 如果是遇到get()操作,先去一號陣列里面查找時候是否存在該節點,如果有該節點,就將這節點從一號位桶陣列移到二號位桶陣列,然后回傳該節點;如果在一號位桶陣列找不到,就去二號位桶陣列找找看有沒有,沒有就沒有了,有就有,
4. 我們可以運用Mysql資料庫在設計redo log的思想,當空閑的時候將一號位桶陣列的資料搬去二號位桶資料里面,
5. 當一號位桶陣列為空時,我們在進行長度*2的擴張,
總結
我們分析了ConcurrentHashMap原理和如何設計一個哈希表,我們來看看如何回答可以暴打面試官,
1. 先來個預熱hashtable,(面試官:只知道hashtable,這么菜,這人沒了)
2. 整一個分段鎖的JDK1.7 的ConcurrentHashMap,(面試官:喲,知道這個資料結構,還行,就是優化沒有說,)
3. 暴擊JDK1.8的ConcurrentHashMap,(面試官:這個靚仔可以啊,)
4. 說出在高并發怎么優化的ConcurrentHashMap猜想,(面試官:輸了輸了,我輸了,)
喜歡的點贊關注,轉發記得貼出處哦,一起加油,YEP!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/156616.html
標籤:python