論文鏈接:https://arxiv.org/pdf/1710.10196.pdf
前言
這是一種針對GANs的訓練優化方法,從低解析度影像開始,通過向網路添加層來逐步提高解析度,如圖1,這種遞增的特性允許訓練首先發現影像分布的大尺度結構,然后將注意力轉移到越來越細的尺度細節上,而不必同時學習所有的尺度,
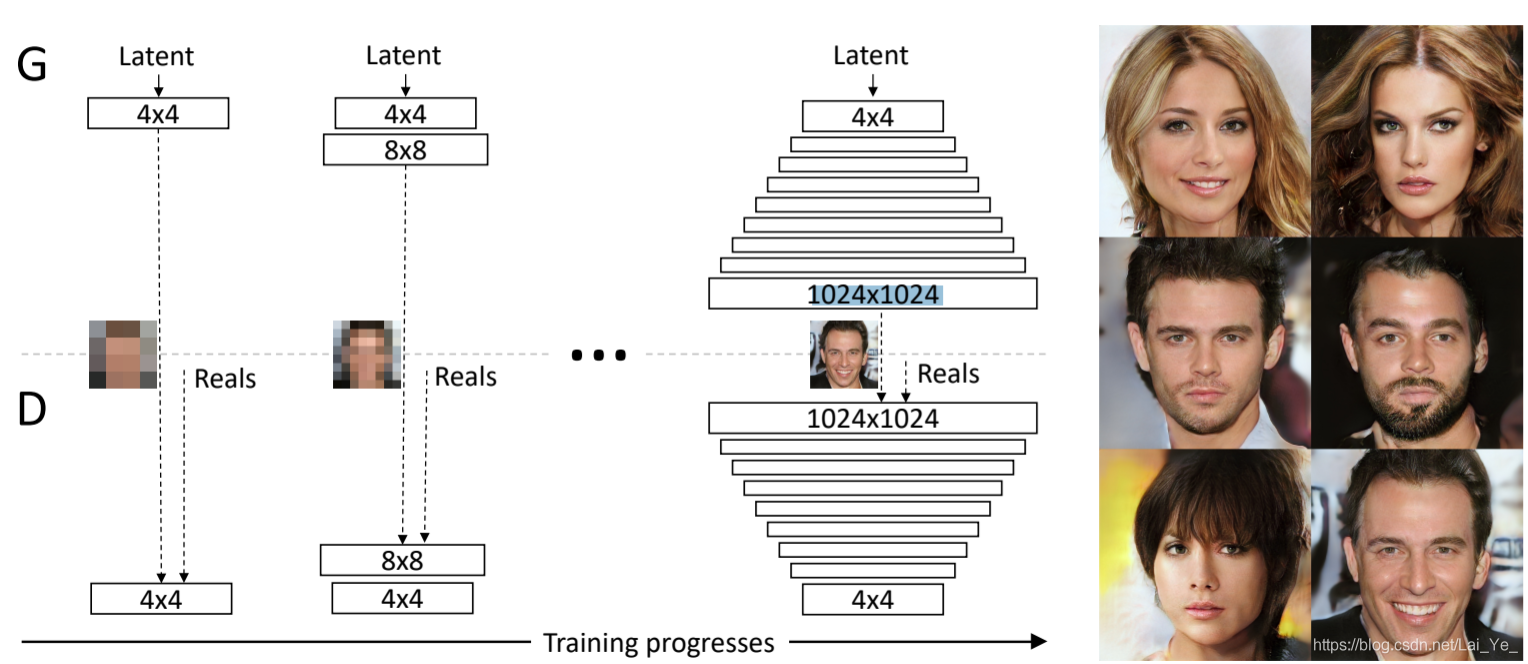 圖1: 初始訓練時,生成器(G)和鑒別器(D)的空間解析度都很低,即4x4像素,隨著訓練的進行,我們逐漸在G和D上增加層,從而提高了生成影像的空間解析度,在整個程序中,所有現有層都是可訓練的,這里N x N是指在N x N空間解析度下的卷積層,這允許在高解析度下穩定的擬合,也能夠極大地加快訓練速度,右邊展示了使用漸進式增長生成的6個1024 x 1024像素示例影像,
圖1: 初始訓練時,生成器(G)和鑒別器(D)的空間解析度都很低,即4x4像素,隨著訓練的進行,我們逐漸在G和D上增加層,從而提高了生成影像的空間解析度,在整個程序中,所有現有層都是可訓練的,這里N x N是指在N x N空間解析度下的卷積層,這允許在高解析度下穩定的擬合,也能夠極大地加快訓練速度,右邊展示了使用漸進式增長生成的6個1024 x 1024像素示例影像,
我們使用生成器和鑒別器網路,它們彼此鏡像,同步發展,在整個訓練程序中,兩個網路中的所有現有層在訓練階段都是可訓練的,當新層被添加到網路中時,我們平滑地淡出現有網路,如圖2所示,這避免了對已經訓練良好的小解析度層的突然沖擊,
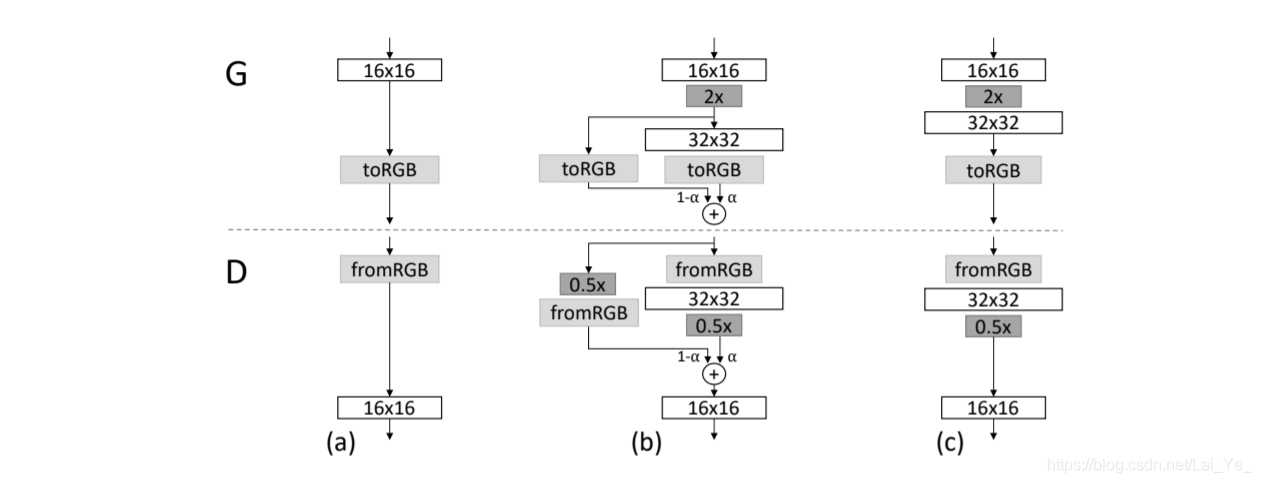 圖2:當加倍生成器(G)和鑒別器(D)的解析度時,我們“平滑”地添加新圖層,該例子說明了從16×16影像
(
a
)
(a)
(a)到32×32影像
(
c
)
(c)
(c)的轉換程序,在轉換
(
b
)
(b)
(b)程序中,我們將操作在更高解析度上的層類似殘差塊一樣處理,其權重
a
a
a從0到1線性增加,這里
2
x
2x
2x和
0.5
x
0.5x
0.5x分別表示使用最鄰近鄰濾波和平均池化將影像解析度加倍和減半,
t
o
R
G
B
toRGB
toRGB表示將特征向量投影到RGB顏色層,
f
r
o
m
R
G
B
fromRGB
fromRGB做相反操作; 都使用1 x 1卷積,在訓練鑒別器時,我們輸入經過縮小的真實影像,以匹配當前網路的解析度,在解析度轉換期間,類似于生成器輸出組合兩種解析度的方式,我們在真實影像的兩種解析度之間插入,
圖2:當加倍生成器(G)和鑒別器(D)的解析度時,我們“平滑”地添加新圖層,該例子說明了從16×16影像
(
a
)
(a)
(a)到32×32影像
(
c
)
(c)
(c)的轉換程序,在轉換
(
b
)
(b)
(b)程序中,我們將操作在更高解析度上的層類似殘差塊一樣處理,其權重
a
a
a從0到1線性增加,這里
2
x
2x
2x和
0.5
x
0.5x
0.5x分別表示使用最鄰近鄰濾波和平均池化將影像解析度加倍和減半,
t
o
R
G
B
toRGB
toRGB表示將特征向量投影到RGB顏色層,
f
r
o
m
R
G
B
fromRGB
fromRGB做相反操作; 都使用1 x 1卷積,在訓練鑒別器時,我們輸入經過縮小的真實影像,以匹配當前網路的解析度,在解析度轉換期間,類似于生成器輸出組合兩種解析度的方式,我們在真實影像的兩種解析度之間插入,
漸進式訓練有幾個好處,
在早期,由于類別資訊和模式較少,小影像的生成實質上更穩定(Odena et al.,2017):通過一點一點地提高解析度,通過重復一個簡化問題,而非直接解決從隱向量直接找到1024
2
^2
2的影像,實際上,它穩定了訓練,使我們能夠使用WGAN-GP或者LSGANs (Gulrajani et al., 2017)損失可靠地合成百萬像素級的影像 (Mao et al., 2016b),
減少了訓練時間:隨著GANs的逐漸增長,大多數迭代程序都是在較低的解析度下完成的,根據最終輸出的解析度,一般可以快2-6倍地獲得相近結果質量,
逐步構建GANs的想法與Wang等人(2017)的作業有關,他們使用多種鑒別器對不同的空間解析度進行操作,Durugkar等(2016)同時使用一個生成器和多個鑒別器進行作業,而Ghosh等(2017)使用多個生成器和一個鑒別器來做相反model作業,分級GANs (Denton. 等,2015; Huang等,2016; Zhang等,2017)為一個影像金字塔的每一層定義一個生成器和鑒別器,這些方法建立在與我們的作業相同的觀察基礎上——從隱變數到高解析度影像的復雜映射通過逐步學習會更加容易——但關鍵的區別在于我們只著眼于單個GAN,而非它們的廣義結構體系,與早期自適應增長網路的研究相比,如GNG(Fritzke, 1995)和NeuroEvolution of Augmenting Topologies (NEAT)(Stanley & Mikkulainen, 2002),它們無節制地增加網路,而我們只是逐步引入預置的層,在此意義上,我們的方法類似于自動編碼器的分層訓練(Bengio等人,2007),
正文部分將描述一些tricks,
文章目錄
- 前言
- 一、基于 ‘批標準差’ 增加多樣性(INCREASING VARIATION USING MINIBATCH STANDARD DEVIATION)
- 二、歸一化處理生成器和鑒別器(NORMALIZATION IN GENERATOR AND DISCRIMINATOR)
- 1. 平衡學習率(EQUALIZED LEARNING RATE)
- 2. 生成器的像素歸一化(PIXELWISE FEATURE VECTOR NORMALIZATION IN GENERATOR)
- 三、構造漸增型網路(PROGRESSIVE NETWORK)
- 1. 上采樣(UPSAMPLE)和下采樣(DOWNSAMPLE)
- 2. 設計不同level的生成器和判別器 (level = log 2 _2 2?(res), res:當前解析度)
- (1)建立level=2的初始卷積層
- (2)建立拓撲卷積層
- (3)生成器輸出(整合特征圖:toRGB)
- 四、訓練配置(TRAINING CONFIGURATION)
- 1. Adam演算法
- 2. mini_batch設定
- 3. Cost Function WGAN-GP
- 五、生成結果的質量評價 -- 多尺度統計相似度( MULTI-SCALE STATISTICAL SIMILARITY)
- 總結
以下是本篇文章正文內容
一、基于 ‘批標準差’ 增加多樣性(INCREASING VARIATION USING MINIBATCH STANDARD DEVIATION)
由于GAN網路傾向于學習資料集的子分部,由此2016年Salimans提出‘minibatch discrimination’即‘批判別’作為解決方案,它們不僅從單個影像中更是在整個minibatch中計算特征統計資料,從而激勵生成影像和訓練影像的minibatch顯示類似的統計資料或分布,
這是通過在鑒別器的末尾添加一個minibatch層來實作的,該層將學習一個大型張量,該張量將輸入量激活并映射到一組統計陣列中,在一個minibatch中,為每個示例生成一組單獨的統計資訊組,并將其拼接到層的輸出,以便鑒別器可以在內部使用統計資訊,我們大大簡化了這種方法,同時也改進了多樣性,
在簡化方案中既沒有可學習引數也沒有新的超引數,我們首先計算每個minibatch空間位置上每個特征圖的標準差,然后,我們將這些估計值平均到所有特征圖和空間位置,得到單一值,我們復制擴張該值,將其連接到所有空間位置,并覆寫整個minibatch,從而產生一個額外的(常量)特征圖,計算方法簡述如下:
input:[N,H,W,fmaps];獲取批大小s=nhwf.shape;
(1) 先計算N個特征圖的標準差得到特征圖fmap1:[1,H,W,fmaps]
(2) 對fmap1求均值,得到值M1:[1,1,1,1]
(3) 復制擴張M1得到N個特征圖fmap2:[N,H,W,1]
(4) 將fmap2添加至每個樣本的特征圖中
理論上,這一層可以插入到鑒別器的任何地方,但是我們發現最好是在接近微端插入,
二、歸一化處理生成器和鑒別器(NORMALIZATION IN GENERATOR AND DISCRIMINATOR)
由于兩種網路之間的不健康競爭,GANs傾向于信號強度的升級,GANs的實際需要是限制信號的大小和競爭,我們使用一種方法,它包含了兩個成分,而這兩個成分都不包含可學習引數,
PGGAN使用兩種不同的方式來限制梯度和不健康博弈,而且方法均采用非訓練的處理方式.
1. 平衡學習率(EQUALIZED LEARNING RATE)
使用簡單的 N ( 0 , 1 ) N(0,1) N(0,1)初始化,然后在運行時顯式地縮放權重,詳細解釋就是:Initialization權重后設定 W i = W i / c W_i = W_i /c Wi?=Wi?/c,其中 W i W_i Wi?是權重, c c c是He的初始化方法的每層歸一化常數(He,2015),
動態地進行而非在初始化做有些許好處,與常用的自適應隨機梯度下降方法(如RMSProp (Tieleman & Hinton, 2012)和Adam (Kingma & Ba, 2015))中的尺度不變性有關,這些方法通過預估的標準差對梯度更新進行標準化,從而使更新不依賴于引數的尺度,如果某些引數的動態范圍比其他引數大,則需要更長的時間來調整,初始化導致的結果會使學習率過大或過小,我們的方法確保了動態范圍,因此學習速度對所有權值而言是相同的,
He的初始化方法能夠確保網路初始化的時候,隨機初始化的引數不會大幅度地改變輸入信號的強度,然而PGGAN中不僅限初始狀態scale而是實時scale,其中He公式如下:
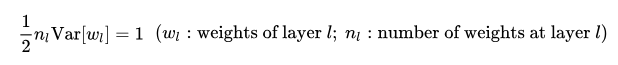
2. 生成器的像素歸一化(PIXELWISE FEATURE VECTOR NORMALIZATION IN GENERATOR)
為了避免由于競爭導致生成器和鑒別器的大小交替失控的情況(生成器的梯度崩潰),我們在每個卷積層之后將生成器中每個像素的特征向量歸一化為單位長度,我們使用一種變體的“區域回應歸一化”(Krizhevsky,2012)來實作這一點,公式如下:
b
x
,
y
=
a
x
,
y
1
N
∑
j
=
0
N
?
1
(
a
x
,
y
j
)
2
+
?
b_{x,y}=\frac{a_{x,y}}{\sqrt{\frac{1}{N}\sum_{j=0}^{N-1}(a_{x,y}^j)^2+\epsilon}}
bx,y?=N1?∑j=0N?1?(ax,yj?)2+?
?ax,y??其中:
?
=
1
0
?
8
\epsilon=10^{-8}
?=10?8,
N
N
N是feature map的個數,
b
x
,
y
b_{x,y}
bx,y?和
a
x
,
y
a_{x,y}
ax,y?則分別是像素
(
x
,
y
)
(x,y)
(x,y)中的初始和歸一化特征向量,
Pixel norm(像素規范),它是local response normalization的變種,Pixel norm沿著channel維度做歸一化,這樣歸一化的一個好處在于,feature map的每個位置都具有單位長度,這個歸一化策略與作者設計的Generator輸出有較大關系,Generator的輸出層并沒有Tanh或者Sigmoid激活函式,
三、構造漸增型網路(PROGRESSIVE NETWORK)
在遞增的訓練階段,生成器和判別器的型號也是在逐步拓展的,比如訓練128x128影像,我們從4x4開始訓練,訓練階段有:
stage 1 4x4 穩定 level2-net
stage 2 8x8 過渡 level3-net
stage 3 8x8 穩定 level3-net
stage 4 16x16 過渡 level4-net
stage 5 16x16 穩定 level4-net
stage 6 32x32 過渡 level5-net
stage 7 32x32 穩定 level5-net
stage 8 64x64 過渡 level6-net
stage 9 64x64 穩定 level6-net
stage 10 128x128 過渡 level7-net
stage 11 128x128 穩定 level7-net
生成器和鑒別器的網路架構主要由復制的3層塊組成,我們在訓練程序中逐一引入,生成器的最后一個Conv 1 x 1層對應于圖2中的toRGB,鑒別器的第一個Conv 1 x 1層對應于fromRGB,我們從4×4解析度開始訓練網路,直到鑒別器已經處理了規定數目的真實影像,然后在兩個階段交替進行: 在同數量影像組中在第一個3層塊中進行影像淡入處理,為這些影像中定網路,在接下來的3層塊中再進行淡入處理,以此類推,
我們的隱向量對應于512維超球面上的隨機點,并且我們在 [ ? 1 , 1 ] [-1,1] [?1,1]中表示訓練和生成的影像,除了最后一層使用線性激活之外,我們在兩個網路的所有層中都使用 leakiness為0.2的leaky ReLU,在GANs的兩種網路中不使用批處理歸一化、層歸一化或權值歸一化,但我們在生成器中每個Conv 3 x 3層之后對特征向量進行像素歸一化,如2.2節所述,我們根據帶有單位方差的正態分布將所有的權值初始化,并將偏差引數初始化為0,在運行時,使用特定于層的常數來縮放權重,如2.1節所述,我們將跨小批(cross-minibatch)標準偏差作為4 x 4解析度的附加特征圖加入鑒別器的末端,如第1節所述,
1. 上采樣(UPSAMPLE)和下采樣(DOWNSAMPLE)
論文中上采樣由近鄰插值方法,下采樣由平均池化方法實作,
同時在卷積程序中,考慮到deconv會讓生成模型遭受checkerboard效應,PGGAN移除了deconv 方式,改用了conv + upsample,
以下論文給出的生成器和判別器中的卷積塊:
生成器卷積塊:

判別器卷積塊:

2. 設計不同level的生成器和判別器 (level = log 2 _2 2?(res), res:當前解析度)
GAN網路從最低解析度4x4慢慢向最高解析度1024x1024學習,其中G&D網路也是逐階段遞增的, 以生成器為例,描述生成器的不同階段的搭建方式:
(1)建立level=2的初始卷積層
 如圖構造了一個CONV4x4+CONV3x3的二級初始結構,
如圖構造了一個CONV4x4+CONV3x3的二級初始結構,
(2)建立拓撲卷積層
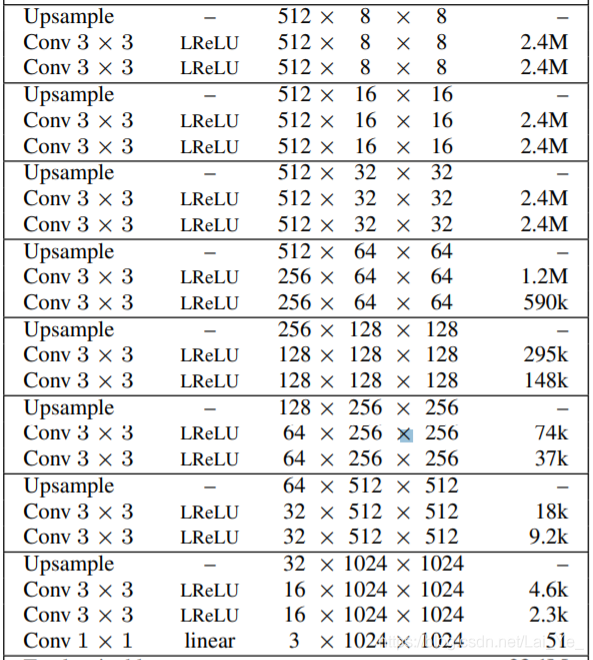 網路拓撲結構如上圖,通過卷積塊拼接成更高級網路,其中每個卷積塊的特征圖數量是指定的,PGGAN在論文里指定為:
網路拓撲結構如上圖,通過卷積塊拼接成更高級網路,其中每個卷積塊的特征圖數量是指定的,PGGAN在論文里指定為:
feats_map_num = [512,512,512,512,256,128,64,32,16]
(3)生成器輸出(整合特征圖:toRGB)
經過多層卷積之后,我們獲得了特征圖,輸出端則需要將這些特征圖整合為3通道的RGB影像,具體而言就是要構造一個toRGB函式,并考慮特征圖整合程序中的過渡階段,
四、訓練配置(TRAINING CONFIGURATION)
1. Adam演算法
在訓練網路時采用Adam優化演算法 (Kingma & Ba, 2015) :
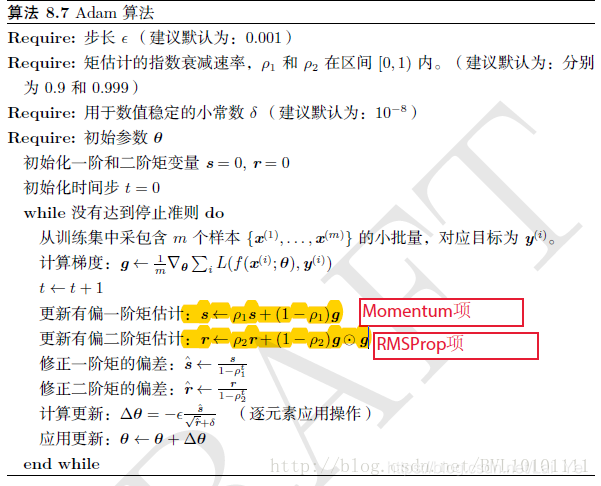 從while回圈往下看:
從while回圈往下看:
第一行是更新step,訓練集采樣,
第二行是計算梯度,
第三行計算一階矩的估計,即mean均值
第四行計算二階距的估計,即variance,是二階距的一種,
第五、六行則是對mean和var進行校正,因為mean和var的初始值為0,所以它們會向0偏置,這樣處理后會減少這種偏置影響,
第七行梯度下降,
?
\epsilon
?后的梯度是用一階距和二階距估計的,
由上圖演算法顯示,Adam演算法可描述為兩種隨機梯度下降擴展式的集合,即:
適應性梯度演算法(AdaGrad)為每一個引數保留一個學習率以提升在稀疏梯度(即自然語言和計算機視覺問題)上的性能,
均方根傳播(RMSProp)基于權重梯度最近量級的均值為每一個引數適應性地保留學習率,這意味著演算法在非穩態和在線問題上有很有優秀的性能,
按照吳恩達博士的理論分析,使用Adam演算法,可以方便設定 ? \epsilon ?的同時,能夠起到天然退火(annealing)的效果,
論文中設定步長0.001,一階矩估計的指數衰減率0.9,二階矩估計的指數衰減率0.99,解析度10E-8,
2. mini_batch設定
為了節省記憶體預算,在解析度較大(
>
=
12
8
2
>=128^2
>=1282)的情況下逐次降低minibatch size,比如:
4
2
=
12
8
2
∽
s
i
z
e
=
16
4^2=128^2\backsim size=16
42=1282∽size=16
25
6
2
∽
s
i
z
e
=
14
256^2\backsim size=14
2562∽size=14
51
2
2
∽
s
i
z
e
=
6
512^2\backsim size=6
5122∽size=6
102
4
2
∽
s
i
z
e
=
3
1024^2\backsim size=3
10242∽size=3
3. Cost Function WGAN-GP
論文中使用了WGAN-GP loss(基于WGAN的改進函式模型,加入gradient penalty——一種聯系了閾值K和原距離函式的loss function,它實作了將引數與限制聯系起來達到真實的Lipschitz限制條件,),在此基礎上進行了進一步的改進,首先設定了
n
c
r
i
t
i
c
=
1
n_{critic}=1
ncritic?=1,在每批樣本進行了生成器與鑒別器的交替訓練,此外,為了解決鑒別器的零漂問題,將loss修正入如下:
L
′
=
L
+
?
d
r
i
f
t
E
x
∈
P
r
[
D
(
x
)
2
]
,
?
d
r
i
f
t
=
1
L'=L+\epsilon_{drift}E_{x\in P_r}[D(x)^2], \ \ \epsilon_{drift}=1
L′=L+?drift?Ex∈Pr??[D(x)2], ?drift?=1
五、生成結果的質量評價 – 多尺度統計相似度( MULTI-SCALE STATISTICAL SIMILARITY)
總體思想:生成器可以基于所有尺度,產生區域影像結構和訓練集是相似的樣例,通過收集和評估一些指示性指標,可以對結果影像進行一些比較可信的評價,
具體策略:從 1 6 2 16^2 162像素開始學習生成影像和目標影像的Laplacian金字塔(Burt&Adelson,1987),并通過它表示區域圖片匹配分布的多尺度統計相似性,其中單個拉普拉斯金字塔等級對應于一個特定的空間頻帶,隨機采樣特定數目的結果影像,并從拉普拉斯Laplacian金字塔的每一級中提取描述符,在論文中每個描述符都是具有3個顏色通道的 7 × 7 7\times7 7×7的相鄰像素點,記為 x ∈ R 147 x\in R^{147} x∈R147,根據訓練集和生成集中的 l l l級的patch匹配分別求得每個顏色通道的均值和標準差,然后通過計算它們的SWD(sliced Wasserstein distance)值來評估統計相似性,
總結
PGGAN在生成高解析度影像上具有著相當杰出的能力,而它在人臉影像生成上所展示的優良表現,是否說明它在資料擴展和場景生成領域同樣能夠提高其效能?這里可以多做一些嘗試和研究,
參考:
https://blog.csdn.net/liujunru2013/article/details/78545882
https://blog.csdn.net/weixin_41024483/article/details/83116856
https://blog.csdn.net/u013412904/article/details/79045473
https://blog.csdn.net/u013139259/article/details/78885815
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/157785.html
標籤:python