環境資訊
在K8S環境通過helm部署了Jenkins(namespace為helm-jenkins),用于日常Java專案構建:
- kubernetes:1.15
- jenkins:2.190.2
- helm版本:2.16.1
如果您想了解helm部署Jenkins的詳情,請參考《》
問題描述
在Jenkins任務密集時,Jenkins頁面回應緩慢,偶爾有白屏情況發生(稍后自動回復),而且構建速度也明顯變緩,查看具體的資料:
- K8S環境已裝了metrics-server,用命令kubectl top pod --all-namespaces可以看到Jenkins所占記憶體僅有410兆,如下圖:

- Jenkins是Java應用,在處理大量任務的時候,410兆的記憶體應該是不夠的,JVM記憶體不足會導致頻繁的垃圾回收,接下來順著這個思路去看JVM記憶體情況;
- 由上圖可知pod名為my-jenkins-74bcdfc566-lmhnw,通過kubectl describe pod my-jenkins-74bcdfc566-lmhnw -n helm-jenkins查看此pod詳情:
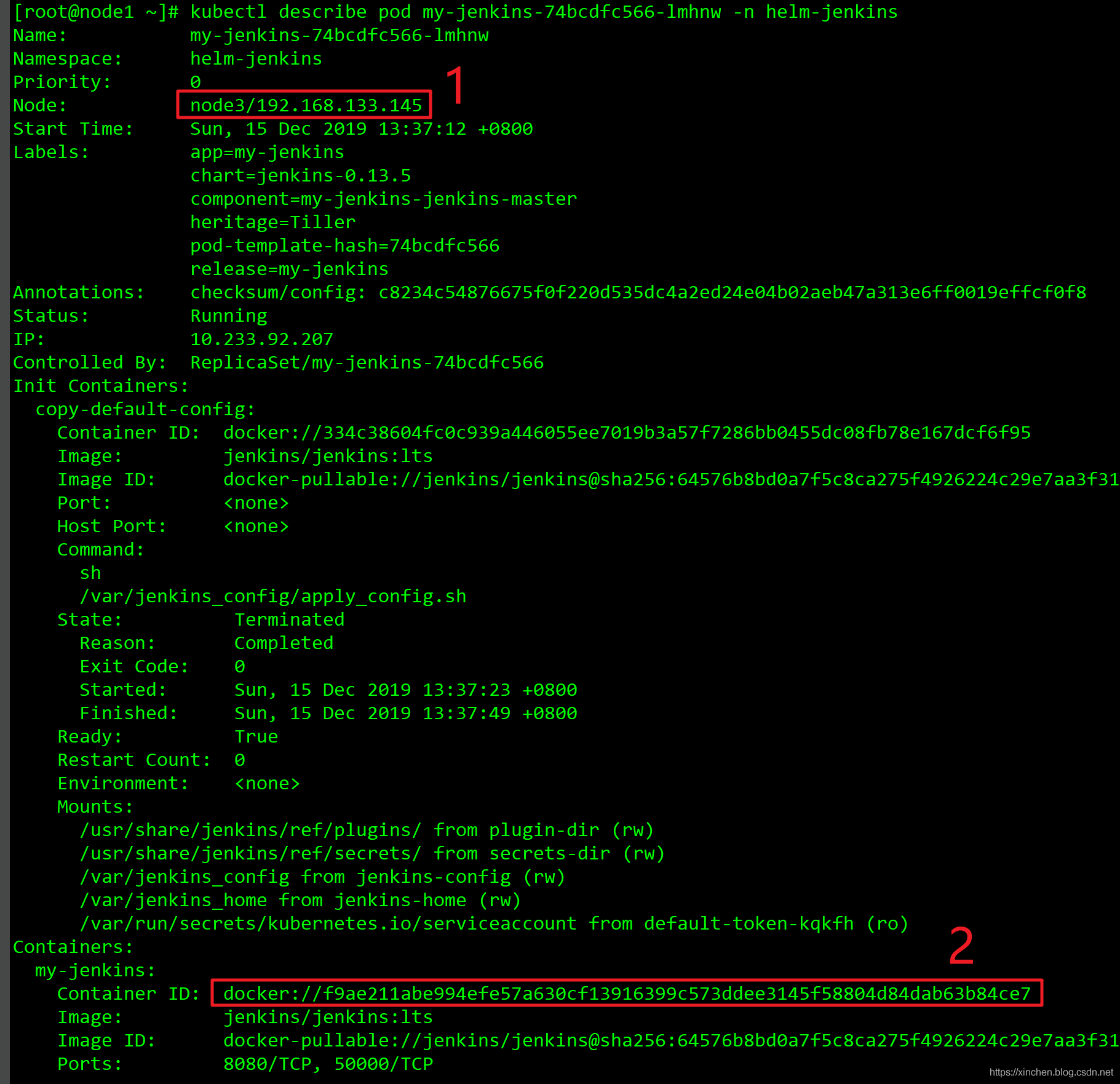
- 由上圖紅框1可知此pod運行在node3節點,紅框2顯示對應的docker容器ID為f9ae211abe99(前12位);
- 去node3機器上執行docker ps,果然發現了ID為f9ae211abe99的容器,如下圖:

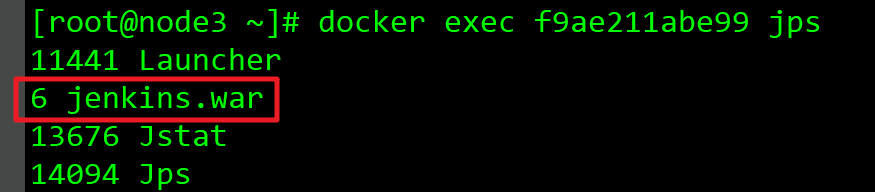
- 執行命令docker exec f9ae211abe99 jps查看容器內所有java行程的PID,如下圖,可見Jenkins服務在容器內的PID等于6:
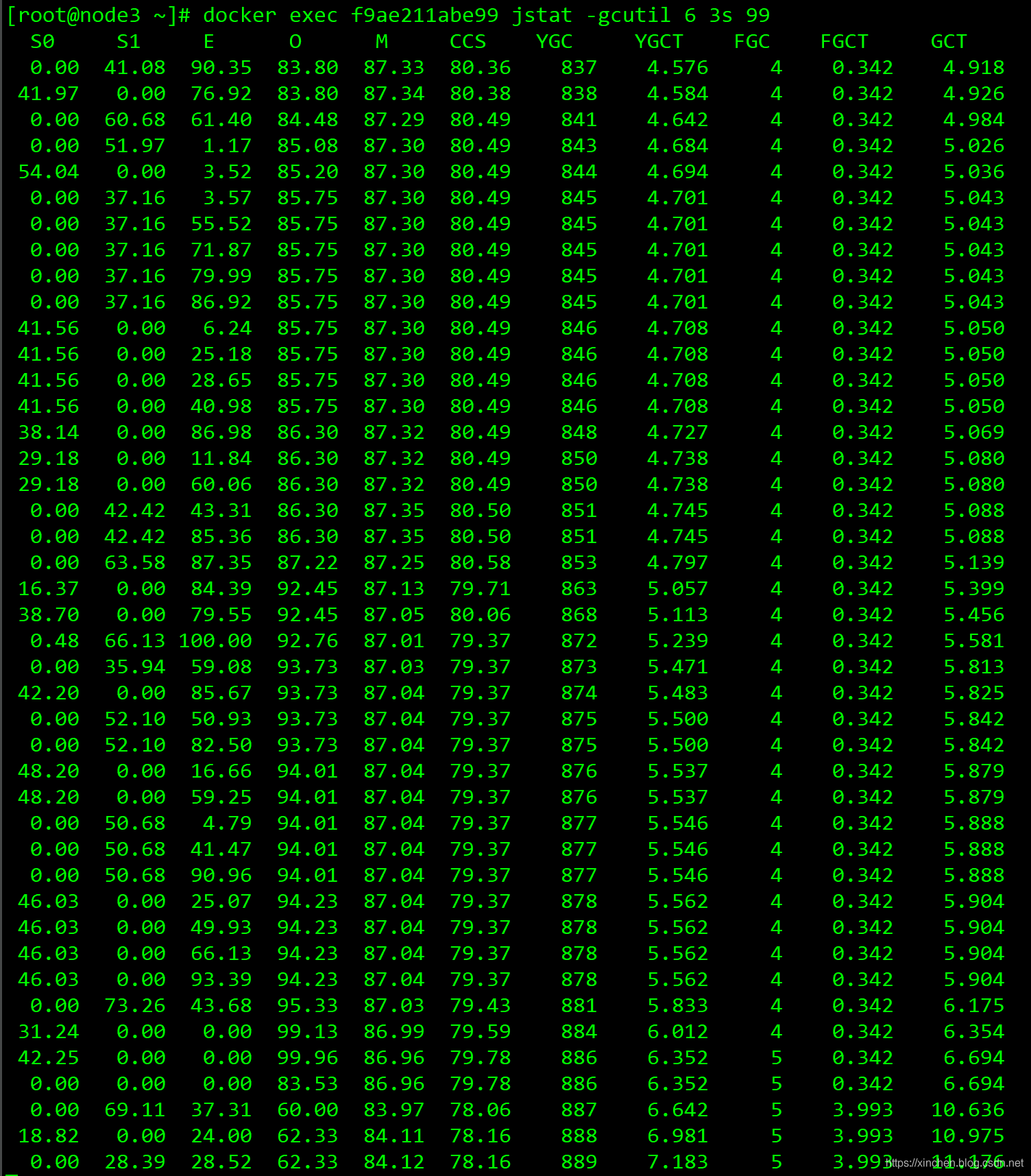
- 知道了容器ID和java行程的PID,就可以查看JVM資訊了,執行命令docker exec f9ae211abe99 jstat -gcutil 6 3s 99查看GC情況,如下圖,除了YGC頻繁,還出現了FGC:
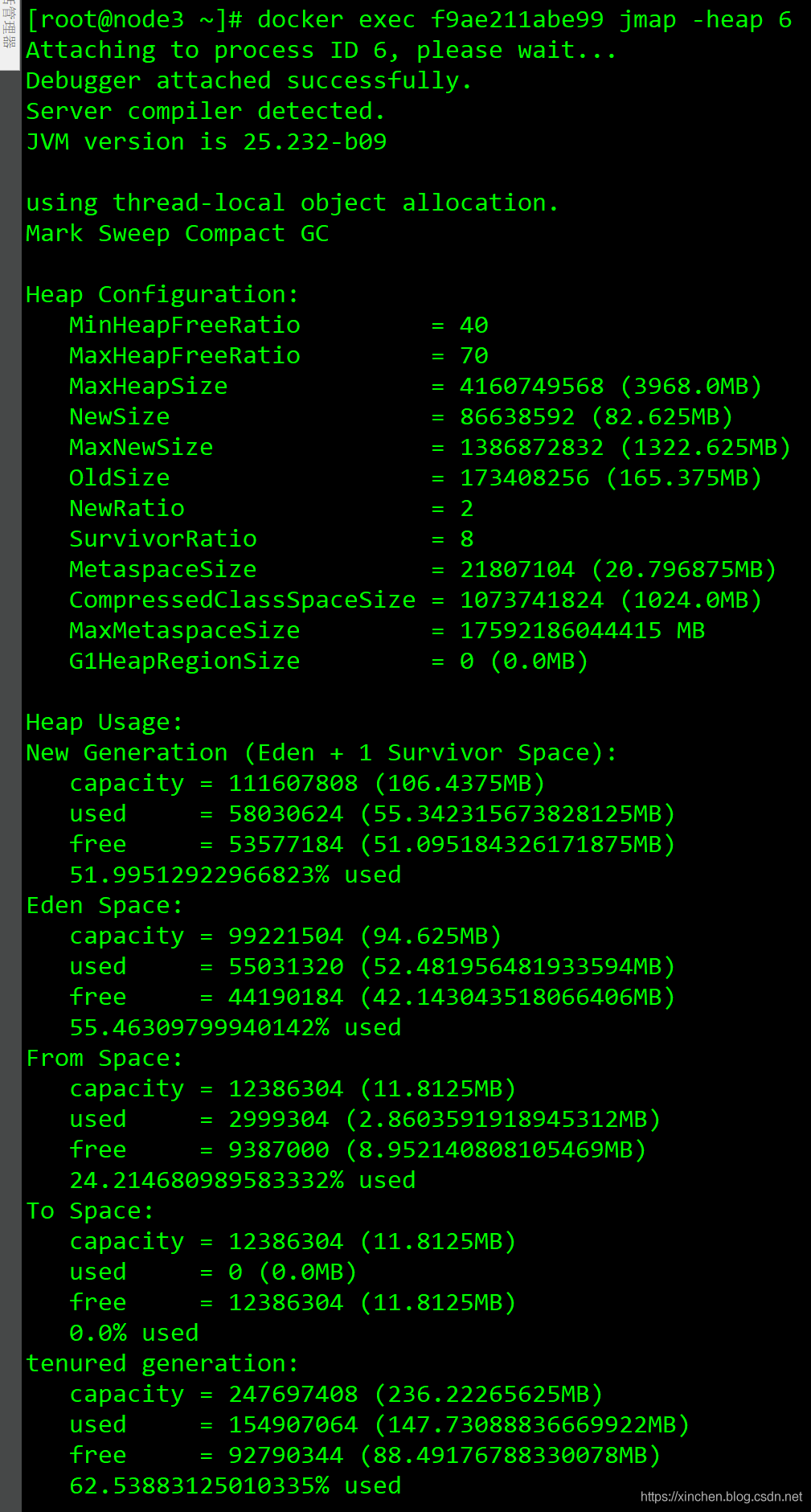
- 再用命令docker exec f9ae211abe99 jmap -heap 6查看JVM記憶體情況,如下圖,年輕代太小了,只有100兆:
- 最后用命令docker exec f9ae211abe99 ps -ef | grep java查看該行程的啟動命令,如下圖,可見啟動該java行程時并有指定記憶體引數:

- 在觀察記憶體引數的程序中,ID為f9ae211abe99的容器突然不見了,取而代之的是一個ID為7f1f94d79e46新容器,如下圖所示:
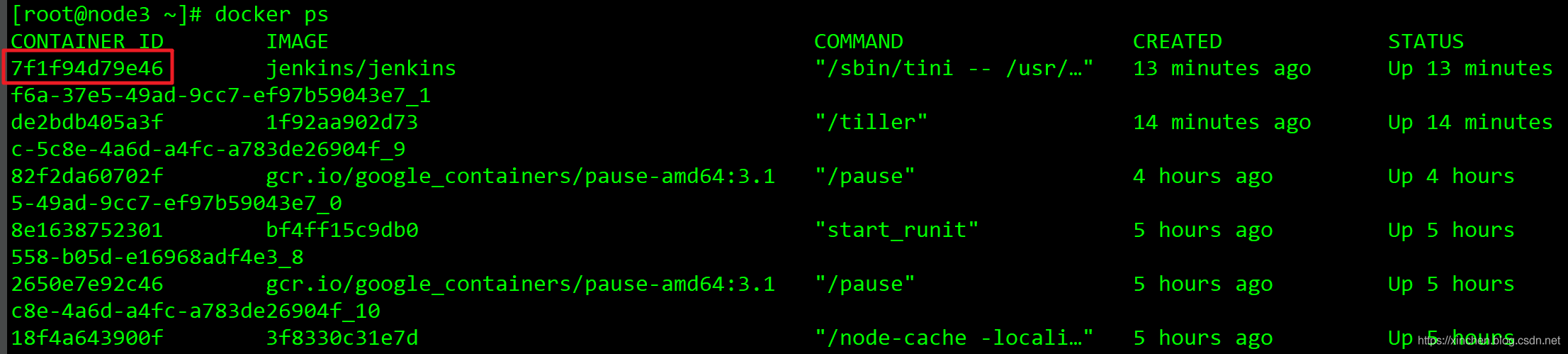 11. 執行命令kubectl get event -n helm-jenkins查看該命名空間的所有事件,如下圖紅框所示,發現原來是探針不回應迫使K8S重啟該pod:
11. 執行命令kubectl get event -n helm-jenkins查看該命名空間的所有事件,如下圖紅框所示,發現原來是探針不回應迫使K8S重啟該pod:
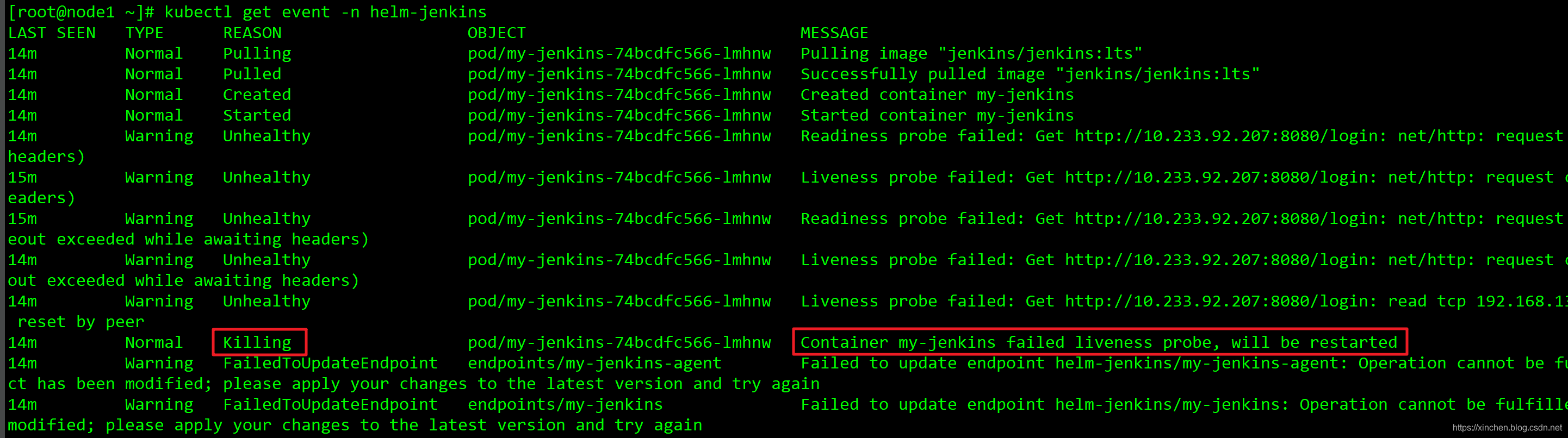
對當前系統的診斷已經完成,根據前面的資訊可以推測:JVM記憶體太小,YGC頻繁,甚至會有FGC出現,系統回應過慢還可能導致K8S探針判斷容器不健康,引發docker容器被洗掉后重新創建,接下來就調整JVM引數,驗證推測是否正確;
調整引數
- 宿主機節點有16G物理記憶體,沒有其他業務,因此打算劃分8G記憶體給Jenkins;
- 執行命令kubectl edit deployment my-jenkins -n helm-jenkins,編輯jenkins的deployment,找到JAVA_OPTS引數的位置,在下面增加value,如下圖紅框所示:
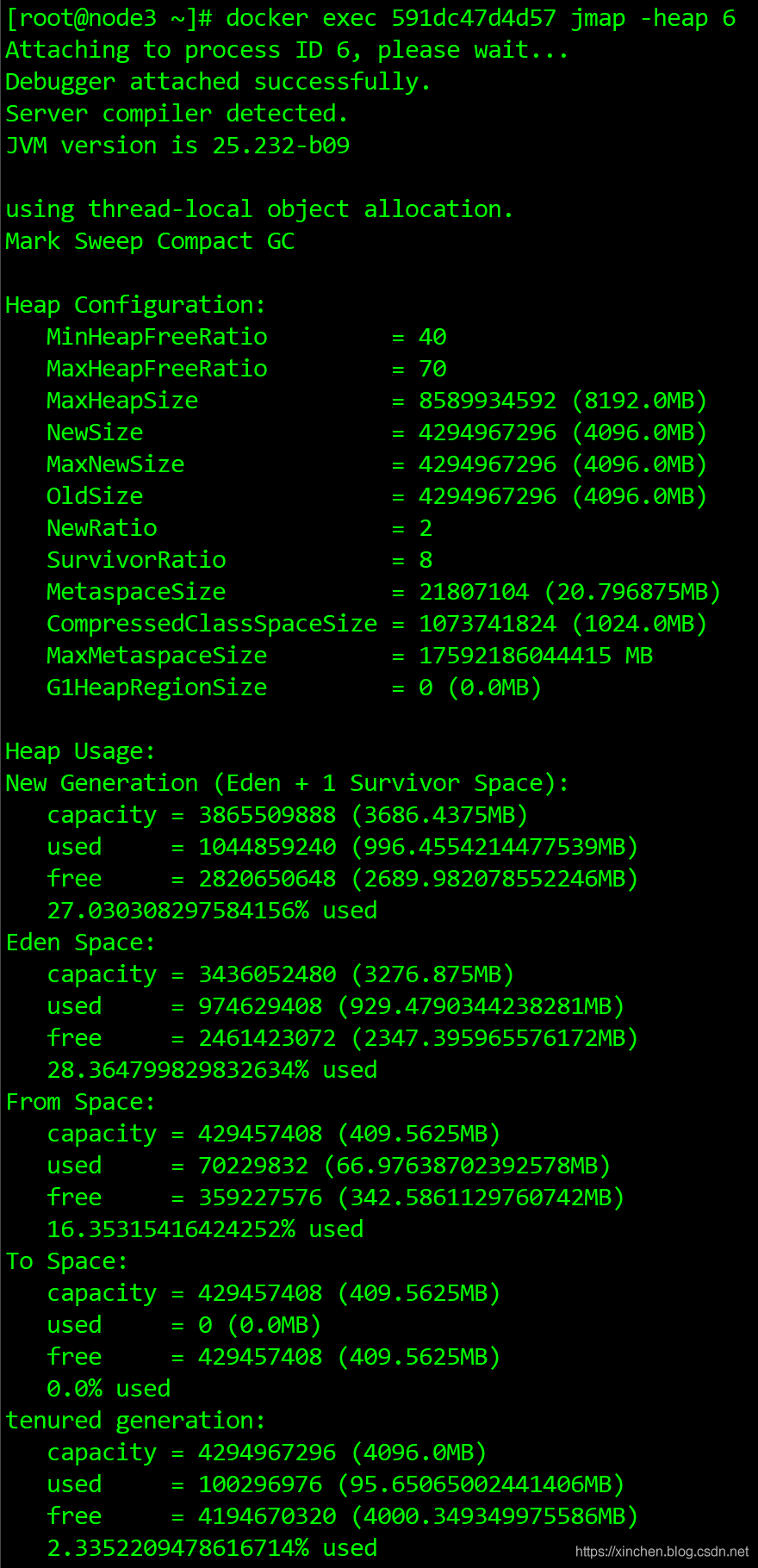
- 找到docker容器ID后,執行命令docker exec 591dc47d4d57 jmap -heap 6查看JVM記憶體,如下圖所示,堆上限已經達到8G,年輕代是3686兆(調整前只有106兆)
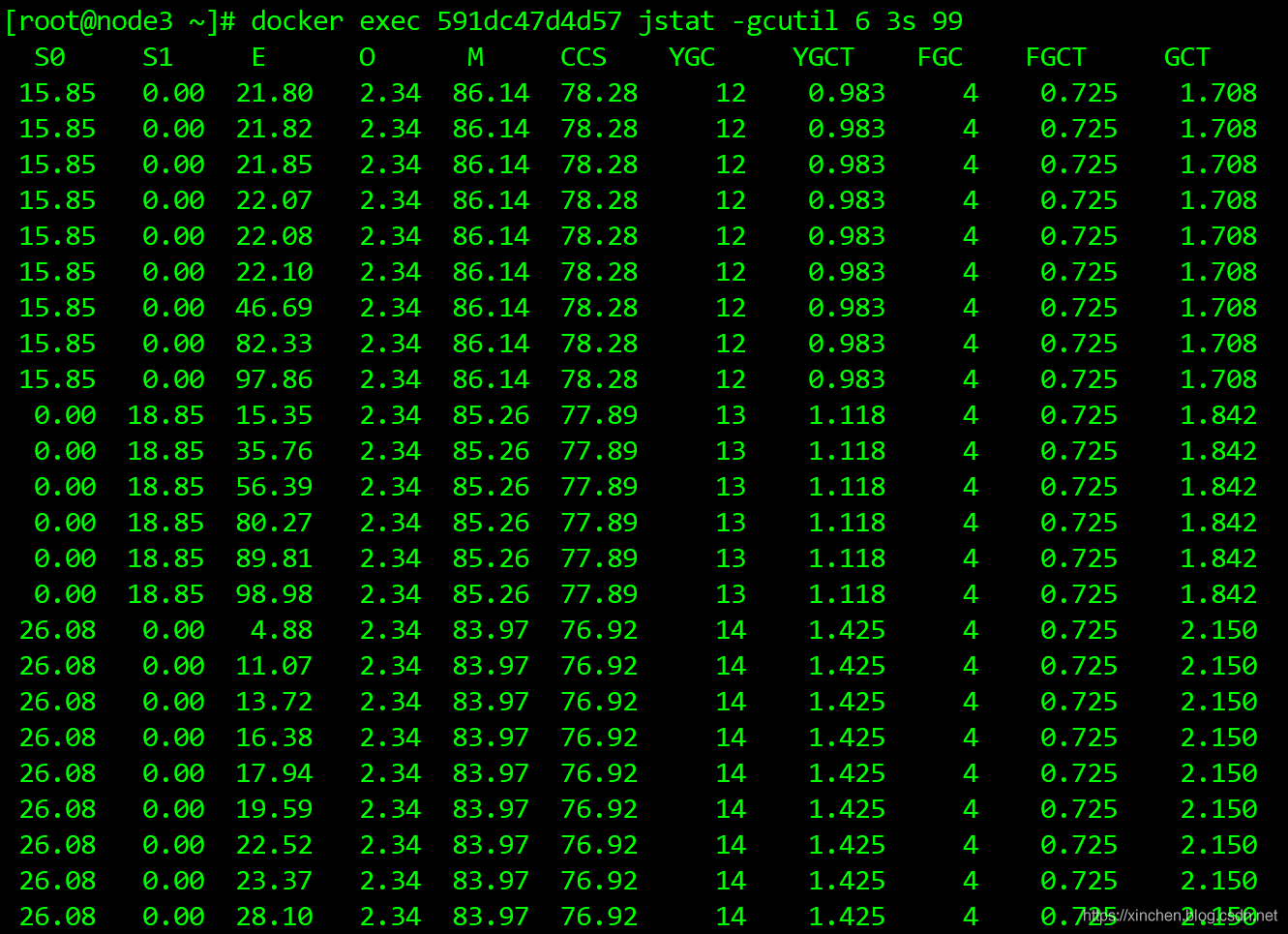
- 并發執行任務一段時間后,觀察GC情況發現并不頻繁:
- 再來看看該行程的啟動命令,執行命令docker exec 591dc47d4d57 ps -ef|grep java,如下圖紅框所示 ,剛才設定的記憶體引數已經被用在啟動命令中了:

- 運行一段時間,確認任務可正常執行,頁面操作也比較流暢,查看K8S事件,再也沒有出現pod重啟的事件;
關于修改引數的方法
除了kubectl edit命令,還可以將helm的Jenkins配置資訊全部下載到本地,修改配置后再部署Jenkins服務,如果您想了解更多,請參考《》
至此,K8S環境下Jenkins性能問題處理已經完成,希望能給您帶來一些參考;
https://github.com/zq2599/blog_demos
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/157937.html
標籤:其他