1. sklearn特征抽取
1.1 安裝sklearn
pip install Scikit-learn -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
沒有報錯,匯入命令查看是否可用:
import sklearn
注:安裝scikit-learn需要Numpy,pandas等庫,
1.2 特征抽取
例子:
# 特征抽取 # 匯入包 from sklearn.feature_extraction.text import CountVectorizer # 實體化CountVectorizer vector = CountVectorizer() # 呼叫fit_transform輸入并轉換資料 res = vector.fit_transform(["life is short,i like python","life is too long,i dislike python"]) # 列印結果 print(vector.get_feature_names()) print(res.toarray())
運行結果:
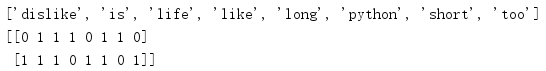
通過例子我們可以得出結論,特征抽取對文本等資料進行特征值化,
1.3 字典特征抽取
作用:對字典資料進行特征值化,
類:sklearn.feature_extraction.DictVectorizer
DictVectorizer語法:
DictVectorizer(sparse=True,…)
- DictVectorizer.fit_transform(X)
- X:字典或者包含字典的迭代器
- 回傳值:回傳sparse矩陣
- DictVectorizer.inverse_transform(X)
- X:array陣列或者sparse矩陣
- 回傳值:轉換之前資料格式
- DictVectorizer.get_feature_names()
- 回傳類別名稱
- DictVectorizer.transform(X)
- 按照原先的標準轉換
from sklearn.feature_extraction import DictVectorizer def dictvec(): """ 字典資料抽取 :return: None """ # 實體化 dict = DictVectorizer() # 呼叫fit_transform data = https://www.cnblogs.com/liuhui0308/p/dict.fit_transform([{'city': '北京','temperature': 100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature': 30}]) print(dict.get_feature_names()) print(dict.inverse_transform(data)) print(data) return None if __name__ == "__main__": dictvec()
運行結果:

修改屬性,讓資料更直觀,
from sklearn.feature_extraction import DictVectorizer def dictvec(): """ 字典資料抽取 :return: None """ # 實體化 dict = DictVectorizer(sparse=False) # 呼叫fit_transform data = https://www.cnblogs.com/liuhui0308/p/dict.fit_transform([{'city': '北京','temperature': 100}, {'city': '上海','temperature':60}, {'city': '深圳','temperature': 30}]) print(dict.get_feature_names()) print(dict.inverse_transform(data)) print(data) return None if __name__ == "__main__": dictvec()
運行結果:

1.4 文本特征抽取
作用:對文本資料進行特征值化,
類:sklearn.feature_extraction.text.CountVectorizer
CountVectorizer語法:
CountVectorizer(max_df=1.0,min_df=1,…)
- 回傳詞頻矩陣
- CountVectorizer.fit_transform(X,y)
- X:文本或者包含文本字串的可迭代物件
- 回傳值:回傳sparse矩陣
- CountVectorizer.inverse_transform(X)
- X:array陣列或者sparse矩陣
- 回傳值:轉換之前資料格式
- CountVectorizer.get_feature_names()
- 回傳值:單詞串列
from sklearn.feature_extraction.text import CountVectorizer def countvec(): """ 對文本進行特征值化 :return: None """ cv = CountVectorizer() data = cv.fit_transform(["人生 苦短,我 喜歡 python", "人生漫長,不用 python"]) print(cv.get_feature_names()) print(data.toarray()) return None if __name__ == "__main__": countvec()
運行結果:
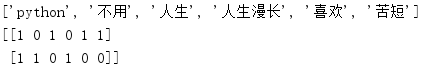
我們在處理文本的時候,不可能自己一個一個去分詞吧,所以我們就要使用一個工具jieba,
pip install jieba -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
from sklearn.feature_extraction.text import CountVectorizer import jieba def cutword(): con1 = jieba.cut("今天很殘酷,明天更殘酷,后天很美好,但絕對大部分是死在明天晚上,所以每個人不要放棄今天,") con2 = jieba.cut("我們看到的從很遠星系來的光是在幾百萬年之前發出的,這樣當我們看到宇宙時,我們是在看它的過去,") con3 = jieba.cut("如果只用一種方式了解某樣事物,你就不會真正了解它,了解事物真正含義的秘密取決于如何將其與我們所了解的事物相聯系,") # 轉換成串列 content1 = list(con1) content2 = list(con2) content3 = list(con3) # 吧串列轉換成字串 c1 = ' '.join(content1) c2 = ' '.join(content2) c3 = ' '.join(content3) return c1, c2, c3 def hanzivec(): """ 中文特征值化 :return: None """ c1, c2, c3 = cutword() print(c1, c2, c3) cv = CountVectorizer() data = cv.fit_transform([c1, c2, c3]) print(cv.get_feature_names()) print(data.toarray()) return None if __name__ == "__main__": hanzivec()
運行結果:
Building prefix dict from the default dictionary ... Dumping model to file cache C:\Users\ACER\AppData\Local\Temp\jieba.cache Loading model cost 0.839 seconds. Prefix dict has been built successfully. 今天 很 殘酷 , 明天 更 殘酷 , 后天 很 美好 , 但 絕對 大部分 是 死 在 明天 晚上 , 所以 每個 人 不要 放棄 今天 , 我們 看到 的 從 很 遠 星系 來 的 光是在 幾百萬年 之前 發出 的 , 這樣 當 我們 看到 宇宙 時 , 我們 是 在 看 它 的 過去 , 如果 只用 一種 方式 了解 某樣 事物 , 你 就 不會 真正 了解 它 , 了解 事物 真正 含義 的 秘密 取決于 如何 將 其 與 我們 所 了解 的 事物 相 聯系 , ['一種', '不會', '不要', '之前', '了解', '事物', '今天', '光是在', '幾百萬年', '發出', '取決于', '只用', '后天', '含義', '大部分', '如何', '如果', '宇宙', '我們', '所以', '放棄', '方式', '明天', '星系', '晚上', '某樣', '殘酷', '每個', '看到', '真正', '秘密', '絕對', '美好', '聯系', '過去', '這樣'] [[0 0 1 0 0 0 2 0 0 0 0 0 1 0 1 0 0 0 0 1 1 0 2 0 1 0 2 1 0 0 0 1 1 0 0 0] [0 0 0 1 0 0 0 1 1 1 0 0 0 0 0 0 0 1 3 0 0 0 0 1 0 0 0 0 2 0 0 0 0 0 1 1] [1 1 0 0 4 3 0 0 0 0 1 1 0 1 0 1 1 0 1 0 0 1 0 0 0 1 0 0 0 2 1 0 0 1 0 0]]
1.5 TF-IDF
TF-IDF的主要思想是:如果某個詞或短語在一篇文章中出現的概率高,并且在其他文章中很少出現,則認為此詞或者短語具有很好的類別區分能力,適合用來分類,
TF-IDF作用:用以評估一字詞對于一個檔案集或一個語料庫中的其中一份檔案的重要程度,
類:sklearn.feature_extraction.text.TfidfVectorizer
TfidfVectorizer語法:
TfidfVectorizer(stop_words=None,…)
- 回傳詞的權重矩陣
- TfidfVectorizer.fit_transform(X,y)
- X:文本或者包含文本字串的可迭代物件
- 回傳值:回傳sparse矩陣
- TfidfVectorizer.inverse_transform(X)
- X:array陣列或者sparse矩陣
- 回傳值:轉換之前資料格式
- TfidfVectorizer.get_feature_names()
- 回傳值:單詞串列
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer import jieba def cutword(): con1 = jieba.cut("今天很殘酷,明天更殘酷,后天很美好,但絕對大部分是死在明天晚上,所以每個人不要放棄今天,") con2 = jieba.cut("我們看到的從很遠星系來的光是在幾百萬年之前發出的,這樣當我們看到宇宙時,我們是在看它的過去,") con3 = jieba.cut("如果只用一種方式了解某樣事物,你就不會真正了解它,了解事物真正含義的秘密取決于如何將其與我們所了解的事物相聯系,") # 轉換成串列 content1 = list(con1) content2 = list(con2) content3 = list(con3) # 把串列轉換成字串 c1 = ' '.join(content1) c2 = ' '.join(content2) c3 = ' '.join(content3) return c1, c2, c3 def tfidfvec(): """ 中文特征值化 :return: None """ c1, c2, c3 = cutword() print(c1, c2, c3) tf = TfidfVectorizer() data = tf.fit_transform([c1, c2, c3]) print(tf.get_feature_names()) print(data.toarray()) return None if __name__ == "__main__": tfidfvec()
運行結果:
Building prefix dict from the default dictionary ... Loading model from cache C:\Users\ACER\AppData\Local\Temp\jieba.cache Loading model cost 0.633 seconds. Prefix dict has been built successfully. 今天 很 殘酷 , 明天 更 殘酷 , 后天 很 美好 , 但 絕對 大部分 是 死 在 明天 晚上 , 所以 每個 人 不要 放棄 今天 , 我們 看到 的 從 很 遠 星系 來 的 光是在 幾百萬年 之前 發出 的 , 這樣 當 我們 看到 宇宙 時 , 我們 是 在 看 它 的 過去 , 如果 只用 一種 方式 了解 某樣 事物 , 你 就 不會 真正 了解 它 , 了解 事物 真正 含義 的 秘密 取決于 如何 將 其 與 我們 所 了解 的 事物 相 聯系 , ['一種', '不會', '不要', '之前', '了解', '事物', '今天', '光是在', '幾百萬年', '發出', '取決于', '只用', '后天', '含義', '大部分', '如何', '如果', '宇宙', '我們', '所以', '放棄', '方式', '明天', '星系', '晚上', '某樣', '殘酷', '每個', '看到', '真正', '秘密', '絕對', '美好', '聯系', '過去', '這樣'] [[0. 0. 0.21821789 0. 0. 0. 0.43643578 0. 0. 0. 0. 0. 0.21821789 0. 0.21821789 0. 0. 0. 0. 0.21821789 0.21821789 0. 0.43643578 0. 0.21821789 0. 0.43643578 0.21821789 0. 0. 0. 0.21821789 0.21821789 0. 0. 0. ] [0. 0. 0. 0.2410822 0. 0. 0. 0.2410822 0.2410822 0.2410822 0. 0. 0. 0. 0. 0. 0. 0.2410822 0.55004769 0. 0. 0. 0. 0.2410822 0. 0. 0. 0. 0.48216441 0. 0. 0. 0. 0. 0.2410822 0.2410822 ] [0.15698297 0.15698297 0. 0. 0.62793188 0.47094891 0. 0. 0. 0. 0.15698297 0.15698297 0. 0.15698297 0. 0.15698297 0.15698297 0. 0.1193896 0. 0. 0.15698297 0. 0. 0. 0.15698297 0. 0. 0. 0.31396594 0.15698297 0. 0. 0.15698297 0. 0. ]]
通過對比,我們就可以看出哪些詞在文本中的權重高了,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/158283.html
標籤:Python
上一篇:【代碼修煉系列分享】改掉這些壞習慣,還怕寫不出健壯的代碼?(一)
下一篇:Python - 密碼學編程