1. 前言
首先自我介紹一下,我是一個做 Java 的開發人員,從今年下半年開始,一直在各大技術博客網站發表自己的一些技術文章,差不多有幾個月了,之前在 cnblog 博客園加了網站統計代碼,看到每天的訪問量逐漸多了起來,國慶正好事情不多,就想著寫一個爬蟲,看下具體閱讀量增加了多少,這也就成了本文的由來,
這里注意:不管你是為了Python就業還是興趣愛好,記住:專案開發經驗永遠是核心,如果你缺新專案練習或者沒有python精講教程,可以去小編的Python交流.裙 :七衣衣九七七巴而五(數字的諧音)轉換下可以找到了,里面很多新python教程專案,還可以跟老司機交流討教!
2. 技術選型
爬蟲這個功能,我個人理解是什么語言都能寫的,只要能正常發送 HTTP 請求,將回應回來的靜態頁面模版 HTML 上把我們所需要的資料提取出來就可以了,原理很簡單,這個東西當然可以手動去統計收集,但是網路平臺畢竟還是很多的,還是畫點時間,寫個爬蟲把資料爬取下來,存到資料庫里,然后寫一個統計報表的 SQL 陳述句比較方便,后續如果有時間的話,我會寫一個簡單的前后端分離的報表樣例分享出來,
網上現在 Python 爬蟲的課程非常的火爆,其實我心里也有點小九九,想玩點騷操作,不想用老本行去寫這個爬蟲,當然最后的事實是證明確實用 Python 寫爬蟲要比用 Java 來寫爬蟲要簡單的多,
3. 環境準備
首先筆者的電腦是 Win10 的,Python 選用的是 3.7.4 ,貌似現在網上 Python3 的爬蟲教程并不多,其中還是遇到不少的問題,下面也會分享給大家,
開發工具筆者選用的是 VSCode ,在這里推薦一下微軟這個開源的產品,非常的輕量化,需要什么插件自己安裝就好,不用的插件一律不要,自主性非常高,如果感覺搞不定的朋友可以選擇 JetBrains 提供的 Pycharm ,分為社區版和付費版,一般而言,我們使用社區版足矣,
筆者這里直接新建了一個檔案夾,創建了一個名為 spider-demo.py 的檔案,這個就是我們一會要寫的爬蟲的檔案了,可以給大家看下筆者的開發環境,如下:
這其實是一個除錯成功的截圖,從下面列印的日志中可以看到,筆者這里抓取了三個平臺的資料,
4. 資料庫
筆者使用的資料是 Mysql 5.7.19 版本,資料庫的字符集是使用的 utf8mb4 ,至于為什么使用 utf8mb4 而不是 utf8 ,各位百度一下吧,很多人講的都比我講的好,我簡單說一句就是 Mysql 的 utf8 其實是一個假的 utf8 ,而后面增加的字符集 utf8mb4 才是真正的 utf8 ,
而 Python 連接 Mysql 也是需要驅動的,和在 Java 中連接資料庫需要驅動一樣,這里使用的是 pymysql ,安裝命令:
pip install pymysql
復制代碼有沒有感覺很簡單, pip 是 Python 的一個包管理工具,我的個人理解是類似于一個 Maven 的東西,所有的我們需要的第三方的包都能在這個上面下載到,
當然,這里可能會出現 timeout 的情況,視大家的網路情況而定,我在晚上執行這個命令的時候真的是各種 timeout ,當然 Maven 會有國內的鏡像戰, pip 顯然肯定也會有么,這里都列給大家:
- 阿里云 mirrors.aliyun.com/pypi/simple…
- 中國科技大學 pypi.mirrors.ustc.edu.cn/simple/
- 豆瓣(douban) pypi.douban.com/simple/
- 清華大學 pypi.tuna.tsinghua.edu.cn/simple/
- 中國科學技術大學 pypi.mirrors.ustc.edu.cn/simple/
具體使用方式命令如下:
pip install -i https://mirrors.aliyun.com/pypi/simple/ 庫名
復制代碼筆者這里僅僅嘗試過阿里云和清華大學的鏡像站,其余未做嘗試,以上內容來自于網路,
表結構,設計如下圖,這里設計很粗糙的,簡簡單單的只做了一張表,多余話我也不說,大家看圖吧,欄位后面都有注釋了:
建表陳述句提交至 Github 倉庫,有需要的同學可以去查看,
5. 實戰
整體思路分以下這么幾步:
- 通過 GET 請求將整個頁面的 HTML 靜態資源請求回來
- 通過一些匹配規則匹配到我們需要的資料
- 存入資料庫
5.1 請求 HTML 靜態資源
Python3 為我們提供了 urllib 這個標準庫,無需我們額外的安裝,使用的時候需要先引入:
from urllib import request
復制代碼接下來我們使用 urllib 發送 GET 請求,如下:
req_csdn = request.Request('https://blog.csdn.net/meteor_93')
req_csdn.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36')
html_csdn = request.urlopen(req_csdn).read().decode('utf-8')
復制代碼User Agent中文名為用戶代理,簡稱 UA,它是一個特殊字串頭,使得服務器能夠識別客戶使用的作業系統及版本、CPU 型別、瀏覽器及版本、瀏覽器渲染引擎、瀏覽器語言、瀏覽器插件等,
這里在請求頭中添加這個是為了模擬瀏覽器正常請求,很多服務器都會做檢測,發現不是正常瀏覽器的請求會直接拒絕,雖然后面實測筆者爬取的這幾個平臺都沒有這項檢測,但是能加就加一下么,當然真實的瀏覽器發送的請求頭里面不僅僅只有一個 UA ,還會有一些其他的資訊,如下圖: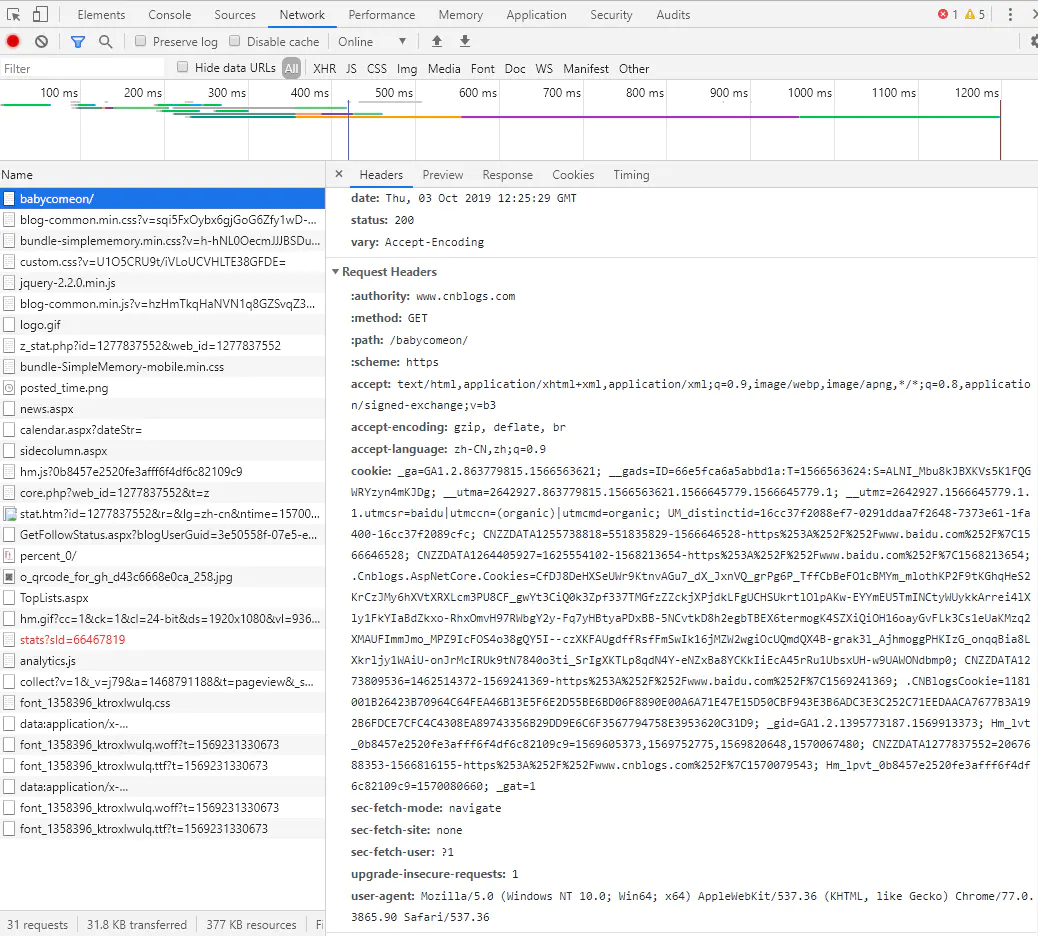
筆者這里的 UA 資訊是直接從這里 Copy 出來的,代碼寫到這里,我們已經拿到了頁面靜態資源 html_csdn ,接下來我們就是要決議這個資源,從中匹配出來我們需要的資訊,
5.2 xpath 資料匹配
xpath 是什么?
XPath 是一門在 XML 檔案中查找資訊的語言,XPath 可用來在 XML 檔案中對元素和屬性進行遍歷, XPath 是 W3C XSLT 標準的主要元素,并且 XQuery 和 XPointer 都構建于 XPath 表達之上,
從上面這句話我們可以看出來, xpath 是用來查找 XML ,而我們的 HTML 可以認為是語法不標準的 XML 檔案,恰巧我們可以通過這種方式來決議 HTML 檔案,
我們在使用 xpath 之前,需要先安裝 xpath 的依賴庫,這個庫并不是 Python 提供的標準庫,安裝陳述句如下:
pip install lxml
復制代碼如果網路不給力的同學可以使用上面的鏡像站進行安裝,
而 xpath 的運算式非常簡單,具體的語法大家可以參考 W3school 提供的教程(www.w3school.com.cn/xpath/xpath… ),筆者這里不多介紹,具體使用方式如下:
read_num_csdn = etree.HTML(html_csdn).xpath('//*[@id="asideProfile"]/div[3]/dl[2]/dd/@title')[0]
fans_num_csdn = etree.HTML(html_csdn).xpath('//*[@id="fan"]/text()')[0]
rank_num_csdn = etree.HTML(html_csdn).xpath('//*[@id="asideProfile"]/div[3]/dl[4]/@title')[0]
like_num_csdn = etree.HTML(html_csdn).xpath('//*[@id="asideProfile"]/div[2]/dl[3]/dd/span/text()')[0]
復制代碼這里筆者主要獲取了總閱讀數、總粉絲數、排名和總點贊數,
這里列舉幾個最基礎的使用,這幾個使用在本示例中已經完全夠用:
| 運算式 | 描述 |
|---|---|
nodename |
選取此節點的所有子節點, |
/ |
從根節點選取, |
// |
從匹配選擇的當前節點選擇檔案中的節點,而不考慮它們的位置, |
. |
選取當前節點, |
.. |
選取當前節點的父節點, |
@ |
選取屬性, |
text |
選取當前節點內容, |
還有一種簡單的方式,我們可以通過 Chrome 瀏覽器獲取 xpath 運算式,具體操作見截圖:
打開 F12 ,滑鼠右鍵需要生成 xpath 運算式的內容,點擊 Copy -> Copy XPath 即可,
這里有一點需要注意,我們直接通過 xpath 取出來的資料資料型別并不是基礎資料型別,如果要做運算或者字串拼接,需要做型別強轉,否則會報錯,如下:
req_cnblog = request.Request('https://www.cnblogs.com/babycomeon/default.html?page=2')
req_cnblog.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36')
html_cnblog = request.urlopen(req_cnblog).read().decode('utf-8')
max_page_num = etree.HTML(html_cnblog).xpath('//*[@id="homepage_top_pager"]/div/text()')
# 最大頁數
max_page_num = re.findall(r"\d+\.?\d*", str(max_page_num))[0]
復制代碼這里需要獲取 cnblog 的博客最大頁數,首先取到了 max_page_num ,這里直接做 print 的話是可以正常列印一個字串出來的,但是如果直接去做正則匹配,就會型別錯誤,
5.3 寫入資料庫
資料庫的操作我就不多做介紹了,有寫過 Java 的同學應該都很清楚 jdbc 是怎么寫的,先使用 ip 、 port 、 用戶名、密碼、資料庫名稱、字符集等資訊獲取連接,然后開啟連接,寫一句 sql ,把 sql 拼好,執行 sql ,然后提交資料,然后關閉連接,代碼如下:
def connect():
conn = pymysql.connect(host='localhost',
port=3306,
user='root',
password='123456',
database='test',
charset='utf8mb4')
# 獲取操作游標
cursor = conn.cursor()
return {"conn": conn, "cursor": cursor}
connection = connect()
conn, cursor = connection['conn'], connection['cursor']
sql_insert = "insert into spider_data(id, plantform, read_num, fans_num, rank_num, like_num, create_date) values (UUID(), %(plantform)s, %(read_num)s, %(fans_num)s, %(rank_num)s, %(like_num)s, now())"
復制代碼在本示例中,爬蟲只負責一個資料爬取作業,所以只需要一句 insert 陳述句就夠了,然后在每個平臺爬取完成后,將這句 sql 中的占位符替換掉,執行 sql 后 commit 操作即可,示例代碼如下:
csdn_data = https://www.cnblogs.com/chengxuyuanaa/p/{
"plantform": 'csdn',
"read_num": read_num_csdn,
"fans_num": fans_num_csdn,
"rank_num": rank_num_csdn,
"like_num": like_num_csdn
}
cursor.execute(sql_insert, csdn_data)
conn.commit()
復制代碼6. 小結
經過這么一次 Python 爬蟲的實際體驗后,確實感覺使用 Python 寫程式語法非常的簡單,整體程式使用 130+ 行,大致估算一下,如果使用 Java 書寫同樣的功能,可能會需要 200+ 行,使用 httpClient 發送 GET 請求再決議回應就不是這么 Python 這種簡簡單單的 2~3 行代碼搞的定的,本示例的爬蟲其實還非常的不完善,目前只能爬取不需要登錄的平臺的資料,有的平臺需要登錄后才能看到統計資料,這就要和 Cookies 相結合才能完成模擬登陸的程序,后續有空我會接著完善這只小爬蟲的,
最后注意:不管你是為了Python就業還是興趣愛好,記住:專案開發經驗永遠是核心,如果你缺新專案練習或者沒有python精講教程,可以去小編的Python交流.裙 :七衣衣九七七巴而五(數字的諧音)轉換下可以找到了,里面很多新python教程專案,還可以跟老司機交流討教!
本文的文字及圖片來源于網路加上自己的想法,僅供學習、交流使用,不具有任何商業用途,著作權歸原作者所有,如有問題請及時聯系我們以作處理,
,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/158667.html
標籤:Python