1. json JavaScript物件記法
json模塊提供了一個與pickle類似的API,可以行化表示,被稱為JavaScript物件記法(JavaScript Object Notation,JSON),不同于pickle,JSON有一個優點,它有多種語言的實作(特別是JavaScript),JSON對于RESTAPI中Web服務器和客戶之間的通信使用最廣泛,不過也可以用于滿足其他應用間的通信需求,
1.1 編碼和解碼簡單資料型別
默認的,編碼器理解Python的一些內置型別(即str、int、float、list、tuple和dict),
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA:', repr(data)) data_string = json.dumps(data) print('JSON:', data_string)
對值編碼時,表面上類似于Python的repr()輸出,
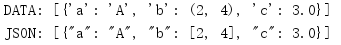
編碼然后再重新解碼時,可能不會得到完全相同的物件型別,
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA :', data) data_string = json.dumps(data) print('ENCODED:', data_string) decoded = json.loads(data_string) print('DECODED:', decoded) print('ORIGINAL:', type(data[0]['b'])) print('DECODED :', type(decoded[0]['b']))
具體的,元組會變成串列,

1.2 人類可讀和緊湊輸出
JSON優于pickle的另一個好處是,JSON會生成人類可讀的結果,dumps()函式接受多個引數從而使輸出更容易理解,例如,sort_keys標志會告訴編碼器按有序順序而不是隨機順序輸出字典的鍵,
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA:', repr(data)) unsorted = json.dumps(data) print('JSON:', json.dumps(data)) print('SORT:', json.dumps(data, sort_keys=True)) first = json.dumps(data, sort_keys=True) second = json.dumps(data, sort_keys=True) print('UNSORTED MATCH:', unsorted == first) print('SORTED MATCH :', first == second)
排序后,會讓人更容易的查看結果,而且還可以在測驗中比較JSON輸出,
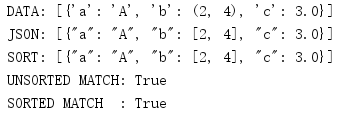
對于高度嵌套的資料結構,還可以指定一個縮進(indent)值來得到格式美觀的輸出,
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA:', repr(data)) print('NORMAL:', json.dumps(data, sort_keys=True)) print('INDENT:', json.dumps(data, sort_keys=True, indent=2))
當縮進是一個非負整數時,輸出更類似于pprint的輸出,資料結構中每一級的前導空格與縮進級別匹配,

這種詳細輸出會增加傳輸等量資料所需的位元組數,所以生產環境中往往不使用這種輸出,實際上,可以調整編碼輸出中分隔資料的設定,從而使其比默認格式更緊湊,
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] print('DATA:', repr(data)) print('repr(data) :', len(repr(data))) plain_dump = json.dumps(data) print('dumps(data) :', len(plain_dump)) small_indent = json.dumps(data, indent=2) print('dumps(data, indent=2) :', len(small_indent)) with_separators = json.dumps(data, separators=(',', ':')) print('dumps(data, separators):', len(with_separators))
dumps()的separators引數應當是一個元組,其中包含用來分隔串列中各項的字串,以及分隔字典中鍵和值的字串,默認為(',',':'),通過去除空白符,可以生成一個更為緊湊的輸出,

1.3 編碼字典
JSON格式要求字典的鍵是字串,如果一個字典以非字串型別作為鍵,那么對這個字典編碼時,便會生成一個TypeError,要想繞開這個限制,一種辦法是使用skipkeys引數告訴編碼器跳過非串的鍵,
import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0, ('d',): 'D tuple'}] print('First attempt') try: print(json.dumps(data)) except TypeError as err: print('ERROR:', err) print() print('Second attempt') print(json.dumps(data, skipkeys=True))
這里不會產生一個例外,而是會忽略非串的鍵,
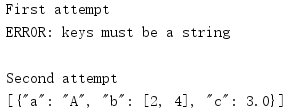
1.4 處理定制型別
目前為止,所有例子都使用Python的內置型別,因為這些型別得到了json的內置支持,通常還需要對定制類編碼,有兩種辦法可以做到,假設以下代碼清單中的類需要進行編碼,
import json
class MyObj: def __init__(self, s): self.s = s def __repr__(self): return '<MyObj({})>'.format(self.s)
要對MyObj實體編碼,一個簡單的方法是定義一個函式,將未知型別轉換為已知型別,這個函式并不需要具體完成編碼,它只是將一個型別的物件轉換為另一個型別,
import json class MyObj: def __init__(self, s): self.s = s def __repr__(self): return '<MyObj({})>'.format(self.s) obj = MyObj('instance value goes here') print('First attempt') try: print(json.dumps(obj)) except TypeError as err: print('ERROR:', err) def convert_to_builtin_type(obj): print('default(', repr(obj), ')') # Convert objects to a dictionary of their representation d = { '__class__': obj.__class__.__name__, '__module__': obj.__module__, } d.update(obj.__dict__) return d print() print('With default') print(json.dumps(obj, default=convert_to_builtin_type))
在convert_to_builtin_ type()中,json無法識別的類實體會被轉換為字典,其中包含足夠多的資訊,如果程式能訪問這個處理所需的Python模塊,就能利用這些資訊重新創建物件,

要對結果解碼并創建一個MyObj()實體,可以使用loads()的objecthook引數關聯解碼器,從而可以從模塊匯入這個類,并將該類用來創建實體,對于從到來資料流解碼的各個字典,都會呼叫object_hook,這就提供了一個機會,可以把字典轉換為另外一種型別的物件,hook函式要回傳呼叫應用要接收的物件而不是字典,
import json def dict_to_object(d): if '__class__' in d: class_name = d.pop('__class__') module_name = d.pop('__module__') module = __import__(module_name) print('MODULE:', module.__name__) class_ = getattr(module, class_name) print('CLASS:', class_) args = { key: value for key, value in d.items() } print('INSTANCE ARGS:', args) inst = class_(**args) else: inst = d return inst encoded_object = ''' [{"s": "instance value goes here", "__module__": "json_myobj", "__class__": "MyObj"}] ''' myobj_instance = json.loads( encoded_object, object_hook=dict_to_object, ) print(myobj_instance)
由于json將串值轉換為Unicode物件,因此,在其被用作類建構式的關鍵字引數之前,需要將它們重新編碼為ASCII串,

內置型別也有類似的hook,如整數(parse_int)、浮點數(parse_float)和常量(parse_constant),
1.5 編碼器和解碼器類
除了之前介紹的便利函式,json模塊還提供了一些類來完成編碼和解碼,直接使用這些類可以訪問另外的API來定制其行為,
JSONEncoder使用一個iterable介面生成編碼資料“塊”,從而更容易將其寫至檔案或網路套接字,而不必在記憶體中表示完整的資料結構,
import json encoder = json.JSONEncoder() data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] for part in encoder.iterencode(data): print('PART:', part)
輸出按邏輯單元輸出,而不是根據某個大小值,

encode()方法基本上等價于''.join(encoder.iterencode()),只不過之前會做一些額外的錯誤檢查,
要對任意的物件編碼,需要用一個實作覆寫default()方法,這個實作類似于convert_to _builtin_type()中的實作,
import json class MyObj: def __init__(self, s): self.s = s def __repr__(self): return '<MyObj({})>'.format(self.s) class MyEncoder(json.JSONEncoder): def default(self, obj): print('default(', repr(obj), ')') # Convert objects to a dictionary of their representation d = { '__class__': obj.__class__.__name__, '__module__': obj.__module__, } d.update(obj.__dict__) return d obj = MyObj('internal data') print(obj) print(MyEncoder().encode(obj))
輸出與前一個實作的輸出相同,
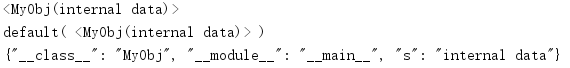
這里要解碼文本,然后將字典轉換為一個物件,與前面的實作相比,這需要多做一些作業,不過不算太多,
import json class MyDecoder(json.JSONDecoder): def __init__(self): json.JSONDecoder.__init__( self, object_hook=self.dict_to_object, ) def dict_to_object(self, d): if '__class__' in d: class_name = d.pop('__class__') module_name = d.pop('__module__') module = __import__(module_name) print('MODULE:', module.__name__) class_ = getattr(module, class_name) print('CLASS:', class_) args = { key: value for key, value in d.items() } print('INSTANCE ARGS:', args) inst = class_(**args) else: inst = d return inst encoded_object = ''' [{"s": "instance value goes here", "__module__": "json_myobj", "__class__": "MyObj"}] ''' myobj_instance = MyDecoder().decode(encoded_object) print(myobj_instance)
輸出與前面的例子相同,

1.6 處理流和檔案
目前為止,所有例子都假設整個資料結構的編碼版本可以一次完全放在記憶體中,對于很大的資料結構,更合適的做法可能是將編碼直接寫至一個類似檔案的物件,便利函式load()和dump()會接收一個類似檔案物件的參考用于讀寫,
import io import json data = [{'a': 'A', 'b': (2, 4), 'c': 3.0}] f = io.StringIO() json.dump(data, f) print(f.getvalue())
類似于這個例子中使用的StringIO緩沖區,也可以使用套接字或常規的檔案句柄,
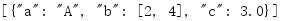
盡管沒有優化,即一次只讀取資料的一部分,但load()函式還提供了一個好處,它封裝了從流輸入生成物件的邏輯,
import io import json f = io.StringIO('[{"a": "A", "c": 3.0, "b": [2, 4]}]') print(json.load(f))
類似于dump(),任何類似檔案物件都可以被傳遞到load(),
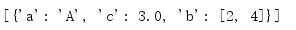
1.7 混合資料流
JS0NDecoder包含一個raw_decode()方法,如果一個資料結構后面跟有更多資料,如帶尾部文本的JSON資料,則可以用這個方法完成解碼,回傳值是對輸入資料解碼創建的物件,以及該資料的一個索引(指示在哪里結束解碼),
import json decoder = json.JSONDecoder() def get_decoded_and_remainder(input_data): obj, end = decoder.raw_decode(input_data) remaining = input_data[end:] return (obj, end, remaining) encoded_object = '[{"a": "A", "c": 3.0, "b": [2, 4]}]' extra_text = 'This text is not JSON.' print('JSON first:') data = ' '.join([encoded_object, extra_text]) obj, end, remaining = get_decoded_and_remainder(data) print('Object :', obj) print('End of parsed input :', end) print('Remaining text :', repr(remaining)) print() print('JSON embedded:') try: data = ' '.join([extra_text, encoded_object, extra_text]) obj, end, remaining = get_decoded_and_remainder(data) except ValueError as err: print('ERROR:', err)
遺憾的是,這種做法只適用于物件出現在輸入起始位置的情況,

1.8 命令列上處理JSON
json.tool模塊實作了一個命令列程式來重新格式化JSON資料,使資料更易讀,
[{"a": "A", "c": 3.0, "b": [2, 4]}]
輸入檔案example.json包含一個映射,其中鍵采用字母表順序,第一個例子顯示了按順序重新格式化的資料,第二個例子使用了--sort-keys在列印輸出之前先對映射鍵排序,
[ { "a": "A", "c": 3.0, "b": [ 2, 4 ] } ]
[ { "a": "A", "b": [ 2, 4 ], "c": 3.0 } ]
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/158670.html
標籤:Python