集成學習之bagging回顧
在之前的集成學習中我們提到有兩個流派,一個是boosting派系,它的特點是各個弱學習器之間有依賴關系;另一種是bagging流派,它的特點是各個弱學習器之間沒有依賴關系,可以并行擬合,決策樹模型中盡管有剪枝等等方法,一棵樹的生成肯定還是不如多棵樹,因此就有了隨機森林,解決決策樹泛化能力弱的缺點,隨機森林是基于bagging框架下的決策樹模型,集成學習中可以和梯度提升樹GBDT分庭抗禮的演算法,尤其是它可以很方便的并行訓練,在如今大資料大樣本的的時代很有傭訓力,隨機森林是一種靈活的、便于使用的機器學習演算法,即使沒有超引數調整,大多數情況下也會帶來好的結果,它可以用來進行分類和回歸任務,
在同一批資料中,用同樣的演算法只能產生一棵樹,這時Bagging策略可以幫助我們產生不同的資料集,Bagging策略來源于bootstrap aggregation:從樣本集(假設樣本集N個資料點)中重采樣選出n個樣本(有放回的采樣,樣本資料點個數仍然不變為N),在所有樣本上,對這n個樣本建立分類器(ID3\C4.5\CART\SVM\LOGISTIC),重復以上兩步m次,獲得m個分類器,最后根據這m個分類器的投票結果,決定資料屬于哪一類,
隨機采樣:
隨機采樣(bootsrap)就是從我們的訓練集里面采集固定個數的樣本,但是每采集一個樣本后,都將樣本放回,也就是說,之前采集到的樣本在放回后有可能繼續被采集到,對于我們的Bagging演算法,一般會隨機采集和訓練集樣本數m一樣個數的樣本,這樣得到的采樣集和訓練集樣本的個數相同,但是樣本內容不同,如果我們對有m個樣本訓練集做T次的隨機采樣,,則由于隨機性,T個采樣集各不相同,注意這和GBDT的子采樣是不同的,GBDT的子采樣是無放回采樣,而Bagging的子采樣是放回采樣,
對于一個樣本,它在某一次含m個樣本的訓練集的隨機采樣中,每次被采集到的概率是$\frac{1}{m}$,不被采集到的概率為$1-\frac{1}{m}$,如果m次采樣都沒有被采集中的概率是$(1-\frac{1}{m})^m$,當$m \to \infty$時,$(1-\frac{1}{m})^m \to \frac{1}{e} \simeq 0.368$,也就是說,在bagging的每輪隨機采樣中,訓練集中大約有36.8%的資料沒有被采樣集采集中,對于這部分大約36.8%的沒有被采樣到的資料,我們常常稱之為袋外資料(Out Of Bag, 簡稱OOB),這些資料沒有參與訓練集模型的擬合,因此可以用來檢測模型的泛化能力,
隨機森林是bagging的一個特化進階版,所謂的特化是因為隨機森林的弱學習器都是決策樹,所謂的進階是隨機森林在bagging的樣本隨機采樣基礎上,又加上了特征的隨機選擇,其基本思想沒有脫離bagging的范疇,
bagging的集合策略:
bagging的集合策略也比較簡單,對于分類問題,通常使用簡單投票法,得到最多票數的類別或者類別之一為最終的模型輸出,對于回歸問題,通常使用簡單平均法,對T個弱學習器得到的回歸結果進行算術平均得到最終的模型輸出,
bagging演算法步驟:
相對于Boosting系列的Adaboost和GBDT,bagging演算法要簡單的多,
輸入為樣本集$D=\{(x_,y_1),(x_2,y_2), ...(x_m,y_m)\}$,弱學習器演算法, 弱分類器迭代次數T,
輸出為最終的強分類器$f(x)$
1)對于t=1,2...,T:
(a) 對訓練集進行第t次隨機采樣,共采集m次,得到包含m個樣本的采樣集$D_t$
(b) 用采樣集$D_t$訓練第t個弱學習器$G_t(x)$
2) 如果是分類演算法預測,則T個弱學習器投出最多票數的類別或者類別之一為最終類別,如果是回歸演算法,T個弱學習器得到的回歸結果進行算術平均得到的值為最終的模型輸出,
集成學習之隨機森林演算法
隨機森林是基于bagging框架下的決策樹模型(在bagging的基礎上更進一步),隨機森林包含了很多樹,每棵樹給出分類結果,每棵樹的生成規則如下:
(1)樣本的隨機:如果訓練集大小為N,對于每棵樹而言,從訓練樣本集中用Bootstrap隨機且有放回地抽取n個訓練樣本,作為該樹的訓練集,重復K次,生成K組子訓練樣本集;
(2)特征的隨機:如果每個特征的樣本維度為M,指定一個常數m<<M,隨機地從M個特征中選取m個特征;
(3) 利用m個特征對每個子資料集構建最優學習模型,即建立了K棵CART決策樹,每棵樹盡最大程度的生長,并且沒有剪枝程序;
(4) 對于新的輸入資料,根據這K個CART形成的隨機森林模型,通過投票表決結果,決定資料屬于哪一類(投票機制有一票否決制、少數服從多數、加權多數)
隨機森林的演算法流程如下圖:
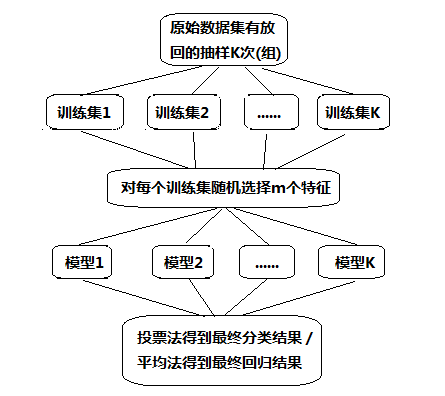
隨機森林(Random Forest)是Bagging演算法的進化版,思想仍然是bagging,但是進行了獨有的改進,首先,Random Forest使用了CART決策樹作為弱學習器,這讓我們想到了梯度提示樹GBDT,第二,在使用決策樹的基礎上,Random Forest對決策樹的建立做了改進,對于普通的決策樹,我們會在節點上所有的n個樣本特征中選擇一個最優的特征來做決策樹的左右子樹劃分,但是RF通過隨機選擇節點上的一部分樣本特征,這個數字小于n,假設為$n_{sub}$,然后在這些隨機選擇的$n_{sub}$個樣本特征中,選擇一個最優的特征來做決策樹的左右子樹劃分,這樣進一步增強了模型的泛化能力,
如果$n_{sub} =n $,則此時RF的CART決策樹和普通的CART決策樹沒有區別,$n_{sub}$越小,則模型約健壯,當然此時對于訓練集的擬合程度會變差,也就是說$n_{sub}$越小,模型的方差會減小,但是偏倚會增大,在實際案例中,一般會通過交叉驗證調參獲取一個合適的$n_{sub}$的值,
隨機森林演算法步驟:
輸入為樣本集$D=\{(x_,y_1),(x_2,y_2), ...(x_m,y_m)\}$,弱分類器迭代次數T,
輸出為最終的強分類器$f(x)$,
1)對于t=1,2...,T:
(a) 對訓練集進行第t次隨機采樣,共采集m次,得到包含m個樣本的采樣集$D_t$
(b) 用采樣集$D_t$訓練第t個決策樹模型$G_t(x)$,在訓練決策樹模型的節點的時候, 在節點上所有的樣本特征中選擇一部分樣本特征, 在這些隨機選擇的部分樣本特征中選擇一個最優的特征來做決策樹的左右子樹劃分
2) 如果是分類演算法預測,則T個弱學習器投出最多票數的類別或者類別之一為最終類別,如果是回歸演算法,T個弱學習器得到的回歸結果進行算術平均得到的值為最終的模型輸出,
隨機森林演算法優點:
1. 訓練可以高度并行化,對于大資料時代的大樣本訓練速度有優勢;
2. 在資料集上表現良好,兩個隨機性的引入,使得隨機森林不容易陷入過擬合;
3. 兩個隨機性的引入,使得隨機森林具有很好的抗噪聲能力,對部分特征缺失不敏感;
4.(能夠評估各個特征的重要性)在訓練后,可以給出各個特征對于輸出的重要性;
5. 由于采用了隨機采樣,訓練出的模型的方差小,泛化能力強;
6. 相對于Boosting系列的Adaboost和GBDT, 隨機森林演算法實作比較簡單;
7. 對資料集的適應能力強,既能處理離散型資料,也能處理連續型資料,資料集無需規范化;
8.(能夠處理具有高維特征的輸入樣本,而且不需要降維)由于可以隨機選擇決策樹節點劃分特征,這樣在樣本特征維度很高的時候,仍然能高效的訓練模型;
9. 只有在半數以上的基分類器出現差錯時才會做出錯誤的預測:隨機森林非常穩定,即使資料集中出現了一個新的資料點,整個演算法也不會受到過多影響,它只會影響到一顆決策樹,很難對所有決策樹產生影響,
隨機森林演算法缺點:
1. 在某些噪音比較大的樣本集上,Random Forest模型容易陷入過擬合;
2. 比決策樹演算法更復雜,計算成本更高;
3. 由于其本身的復雜性,它們比其他類似的演算法需要更多的時間來訓練;
4. 取值劃分比較多的特征容易對Random Forest的決策產生更大的影響,從而影響擬合的模型的效果,
【補充】:
(1)為什么要隨機抽樣訓練集?
如果不進行隨機抽樣,每棵樹的訓練集都一樣,那么最終訓練出的樹分類結果也是完全一樣的,這樣的話完全沒有bagging的必要;
(2)為什么要有放回地抽樣?
因為bagging的子資料集既不是相互獨立的,也不是完全一樣的,子資料集間存在一定的相似性,如果不是有放回的抽樣,那么每棵樹的訓練樣本都是不同的,都是沒有交集的,這樣每棵樹都是"有偏的",也就是說每棵樹訓練出來都是有很大的差異的;而隨機森林最后分類取決于多棵樹(弱分類器)的投票表決,這種表決應該是"求同",因此使用完全不同的訓練集來訓練每棵樹這樣對最終分類結果是沒有幫助的,
(3)特征的隨機抽樣的結果是子資料集間有不同的子特征,
(4)隨機森林分類效果(錯誤率)與兩個因素有關:
森林中任意兩棵樹的相關性:相關性越大,錯誤率越大;
森林中每棵樹的分類能力:每棵樹的分類能力越強,整個森林的錯誤率越低,
隨機森林的相關性包括子資料集間的相關性和子資料集間特征的相關性,相關性在這里可以理解成相似度,若子資料集間重復的樣本或子資料集間重復的特征越多,則相關性越大,減小子資料間的特征選擇個數,樹的相關性和分類能力也會相應的降低;增大特征個數,樹的相關性和分類能力會相應的提高,
參考文章:
https://www.stat.berkeley.edu/~breiman/randomforest2001.pdf
https://www.cnblogs.com/pinard/p/6156009.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/158900.html
標籤:Python
下一篇:python學習筆記(三)