IPFS
什么是IPFS?
星際檔案系統是一個旨在創建持久且分布式存盤和共享檔案的網路傳輸協議,它是一種內容可尋址的對等、點到點 的超媒體分發協議,在IPFS網路中的節點將構成一個分布式檔案系統,它嘗試為所有計算設備連接同一個檔案系統,可以讓我們的互聯網速度更快,更加安全,并且更加開放,IPFS協議的目標是取代傳統的互聯網協議HTTP,

什么是超媒體?超媒體對應之前的超文本,超文本意思就是我們建立文本與文本之間的連接,超媒體的意思是它要建立的是文本、圖片、視頻之間的連接,http這個協議就是一個超文本協議,
IPFS(InterPlanetary File System,星際檔案系統)是一個將分布式哈希表(Distributed Hash Tables (DHTs))、BitTorrent、版本控制系統Git、自認證檔案系統(Self-Certified Filesystems - SFS)與區塊鏈相結合的檔案存盤和內容分發網路協議,這些系統的綜合優勢給它帶來的顯著特性:
- 永久的、去中心化保存和共享檔案 (區塊鏈模式下的存盤DHTs)
- 點對點超媒體:P2P 保存各種各樣型別的資料(BitTorrent)
- 版本化:可追溯檔案修改歷史(Git - Merkle DAG默克爾有向無環圖))
- 內容可尋址:通過檔案內容生成獨立哈希值來標識檔案,而不是通過檔案保存位置來標識,相同內容的檔案在系統中只會存在一份,節約存盤空間,
在某些方面,IPFS類似于萬維網,但它也可以被視作一個獨立的BitTorrent群、在同一個Git倉庫中交換物件,換種說法,IPFS提供了一個高吞吐量、按內容尋址的塊存盤模型,及與內容相關超鏈接,這形成了一個廣義的Merkle有向無環圖(DAG),IPFS結合了分布式散串列、鼓勵塊交換和一個自我認證的名字空間,IPFS沒有單點故障,并且節點不需要相互信任,分布式內容傳遞可以節約帶寬,和防止HTTP方案可能遇到的DDoS攻擊,
IPFS基于什么產生的呢?為什么會有IPFS?
大家都知道互聯網是建立在HTTP協議上的. HTTP協議是個偉大的發明,讓我們的互聯網得以快速發展.但是互聯網發展到了今天HTTP逐漸出現了不足:
-
現在http協議的效率非常低,并且成本還很高,一旦使用HTTP協議每次需要從中心化的服務器下載完整的檔案(網頁,視頻,圖片等),速度慢,效率低,如果改用P2P的方式下載,可以節省近60%的帶寬,P2P將檔案分割為小的塊,從多個服務器同時下載,速度非常快.
-
web檔案經常被洗掉,我們可能在上網的程序中會遇到,收藏某個網頁,在使用的時候瀏覽器網頁會顯示404,原因有很多,有可能是服務器停了,有可能是服務器受到一些外部的干擾壞掉,所以會發現web檔案經常被洗掉,IPFS提供了檔案的歷史版本回溯功能(就像git版本控制工具一樣),可以很容易的查看檔案的歷史版本,資料可以得到永久保存,
-
互聯網的中心化會抑制了web的成長,我們的現有互聯網是一個高度中心化的網路,互聯網是人類的偉大發明,也是科技創新的加速器,各種管制將對這互聯網的功能造成威脅,例如: 互聯網封鎖,管制,監控等等,這些都源于互聯網的中心化,
-
互聯網非常依賴于其他網路,如果說因為一些不可抗拒的因素,比如說自然災害這些,把主干網路給破壞了,那一切真的就完了,起碼說互聯網會損失很多,當然這種幾率是比較小的,還會受到各種病毒網路的攻擊,會造成中心化服務器的斷機,
怎么解決HTTP的缺點?
那么為了解決以上問題,ipfs就出來了,它怎么解決的呢,當我們利用ipfs上傳檔案的時候,系統會先對檔案進行一個加密,得到一個數值,這個數值很重要,我們叫做哈希值,它是唯一的,一個檔案對應一個哈希值,隨后系統會將檔案進行分割,分割成很多份,然后復制,最后分布式地存到若干區塊當中,
在未來,使用ipfs網訪問東西或者下載東西的時候,系統會從離我們最近的距離的一個節點傳輸資料,或者說檔案的碎片來給到我,最終呈現的是整個檔案,
上面講到的【哈希值】:在ipfs網路里的檔案會被賦予一個哈希值,那么這個哈希值就類似于我們的身份證,獨一無二的,一個檔案一個哈希值,這個哈希值是從檔案內容中計算出來的,即使說檔案里面它有一個標點符號被改動計算出的哈希值也完全不一樣,所以就像我們說的一個人對應一個身份證,一個檔案就對應一個哈希值,沒辦法改動,所以說ipfs網路中的檔案只存在獨一無二的一份,檔案自然不會重復地去存盤,不會被惡意篡改,大大降低了存盤的成本,減少了存盤的資源浪費,這也是為什么說ipfs的目標是補充http的不足或者是完全取代http,
IPFS如何存盤檔案?
我們將一個檔案放到IPFS系統中,會得到根據內容計算出的加密哈希值,哈希值直接反映檔案的內容,哪怕只修改1位元組,哈希值也會完全不同,當使用IPFS訪問一個檔案的哈希值時,它會使用一個分布式哈希表找到檔案實際存盤節點,同時訪問多個位元組來提高訪問速度,下載檔案并校對檔案的哈希,由于每個檔案的哈希值全網唯一,查詢(訪問)將很容易進行,如果被存盤過,直接從其它節點讀取它,不需要重復存盤,
存盤塊
資訊可以存盤進IPFS系統中的物件(塊)里,這些塊可以存盤至多256KB的資料,它們還可以鏈接其他IPFS物件,
存盤小于256KB的檔案時,只需將這個檔案放進一個物件內就可以了,而大于256KB的檔案會被分成多個256KB然后放進物件中,之后IPFS將創建一個空物件,該物件將鏈接到檔案的所有其他部分,這個空塊就類似于一個大信封,里面會涵蓋整個檔案的所有部分,
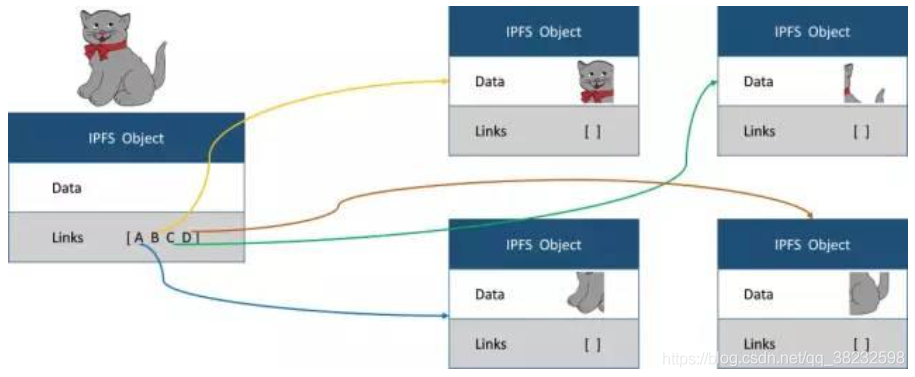
系統會給同一個檔案的每一個塊計算一次哈希值一,所有物件的哈希值一計算完畢之后,會將所有的哈希值一拼湊成一個陣列B,再計算一次哈希值,從而得到最終的哈希值下進行,最后把最終的哈希值和原檔案捆綁起來,組成一個物件,從而形成一個索引結構d,把塊和最終的索引結構d上傳至IPFS節點,檔案便同步到網路了,
如何訪問IPFS?
IPFS的做法只關注檔案中可能出現的內容,比如,我們把照片檔案cat.jpg放到IPFS節點,它會得到一個新名字Qjhash23jhJhjhf56j65h,這是一個由檔案內容計算出的加密哈希值,當IPFS被請求一個檔案哈希時,它會使用一個分布式哈希表找到檔案所在的節點,取回檔案并驗證檔案資料,
如果僅僅使用哈希值來區分檔案的話,會給傳播造成困難,因為哈希值不容易記憶,就像IP地址一樣不容易記憶,于是人類便發明了域名,與之類似,IPFS使用一個叫強脈沖中子源的分布式命名系統,將難于記憶的資料哈希值映射為易于記憶的字串,這可以類比于域名與IP地址的映射關系,
舉個具體場景的例子,假設我想要看“碟中諜6”這部電影,A同學之前下載過這部電影,他啟動了IPFS節點,將這個視頻檔案加入了IPFS網路,他會得到一個哈希指紋b,同時發布到公共網關,通過IPNS映射得到了一個/IPFS/b的路徑名,
他把哈希指紋和路徑名都告訴我,我要做的事情是啟動一個本地節點,對該網關發一個尋址PIN的請求,IPFS自動索引分布式哈希表的哈希值,找到指紋b所對應的節點串列,
如何解決無人保種的問題?
針對問題的解決方案:Filecoin
分布式存盤就意味著需要在全球都有足夠多的節點,上面提出的問題,實際就是如何才能讓這些節點愿意貢獻自己的硬碟和帶寬,這當然少不了一套合理的獎勵機制,此時就需要Filecoin出場了,
通過使用代幣(FileCoin)的激勵作用,讓各例程有動力去存盤資料,按照各節點的貢獻大小,它們會獲得相應數量的Filecoin作為獎勵,即礦工(存盤資源貢獻者)通過為網路提供開放的硬碟空間獲得Filecoin,其他用戶想在IPFS里存盤檔案時,也需要支付Filecoin作為成本,

存盤礦工的挖礦行為可以理解為是共享出自己的硬碟資源并獲得酬勞,
通過Filecoin的獎勵機制,IPFS激勵公眾參與進來貢獻出自己的存盤資源,這就在全球范圍內極大的增加了網路的節點數量,讓整個分布式存盤網路變成了一個巨大的存盤空間,在整套機制的配合下,IPFS在跟HTTP的競爭中擁有了更強的發展優勢,
參考資料
https://baijiahao.baidu.com/s?id=1647038148693057911&wfr=spider&for=pc
https://zhuanlan.zhihu.com/p/92895578?utm_source=wechat_session
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/159663.html
標籤:java
上一篇:Linux相關,小白求助帖