1:特征歸一化
場景描述:
為了消除資料特征之間的量綱影響,我們需要對特征進行歸一化處理,使得不同指標之間具有可比性,例如,分析一個人的身高和體重對健康的影響,如果使用米(m )和千克(kg)作為單位,那么身高特征會在 1.6 1.8m 的數值范圍內,體重特征會在50 100kg 的范圍內,分析出來的結果顯然會傾向于數值差別比較大的體重特征,想要得到更為準確的結果,就需要進行特征歸一化 (Normalization)處理,使各指標處于同一數值量級,以便進行分析,
問題1:為什么需要對數值型別的特征做 歸一化?
對數值型別的特征做歸一化可以將所有的特征都統一到一個大致相同的數值區間內,最常用的方法主要有以下兩種,
(1)線性函式歸一化(Min-Max Scalling ),它對原始資料進行
線性變換,使結果映射到 [0,1] 的范圍,實作對原始資料的等比縮放,
歸一化公式如下
X
norm
=
X
?
X
min
?
X
max
?
?
X
min
?
X_{\text {norm }}=\frac{X-X_{\min }}{X_{\max }-X_{\min }}
Xnorm ?=Xmax??Xmin?X?Xmin??
其中 X 為原始資料,X_max、X_min 分別為資料最大值和最小值,
(2)零均值歸一化(Z-Score Normalization),它會將原始數
據映射到均值為 0、標準差為 1 的分布上,具體來說,假設原始特征的
均值為
μ
\mu
μ 、標準差為
σ
,
\sigma,
σ, 那么歸一化公式定義為
z
=
x
?
μ
σ
z=\frac{x-\mu}{\sigma}
z=σx?μ?
為什么需要對數值型特征做歸一化呢?我們不妨借助隨機梯度下降的實體來說明歸一化的重要性,假設有兩種數值型特征, x, 的取值范圍
[
0
,
10
]
,
x
2
[0,10], x_{2}
[0,10],x2? 的取值范圍為
[
0
,
3
]
,
[0,3],
[0,3], 于是可以構造一個目標函式符合圖 1.1(a)中的等值圖,在學習速率相同的情況下,x, 的更新速度會大于
x
2
,
x_{2},
x2?, 需要較多的迭代才能找到最優解,如果將
x
1
x_{1}
x1? 和
x
2
x_{2}
x2? 歸一化到相同的數值區間后,優化目標的等值圖會變成圖 1.1(b)中的圓形,x_和
x
2
x_{2}
x2? 的更新速度變得更為一致,容易更快地通過梯度下降找到最優解,
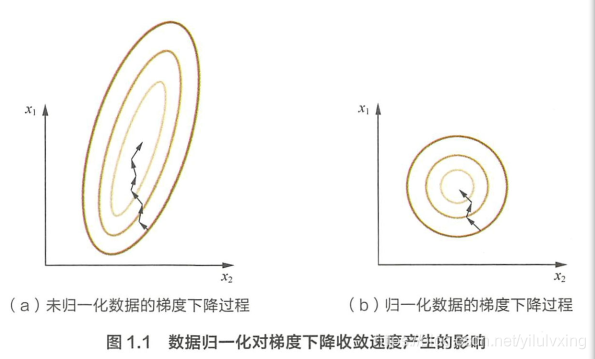
當然,資料歸一化并不是萬能的,在實際應用中,通過梯度下降法求解的模型通常是需要歸一化的,包括線性回歸、邏輯回歸、支持向量機、神經網路等模型,但對于決策樹模型則并不適用,以 C4.5 為例,決策樹在進行節點分裂時主要依據資料集 D 關于特征
x
x
x 的資訊增益比,而資訊增益比跟特征是否經過歸一化是無關的,因為歸一化并不會改變樣本在特征 x 上的資訊增益,
2:類別型特征
場景描述
類別型特征(Categorical Feature ) 主要是指性別(男、女)、血型(A、B、AB、O)等只在有限選項內取值的特征,類別型特征原始輸入通常是字串形式,除了決策樹等少數模型能直接處理字串形式的輸入,對于邏輯回歸、支持向量機等模型來說,類別型特征必須經過處理轉換成數值型特征才能正確作業,
涉及到的知識點:
- 序號編碼(Ordinal Encoding)
- 獨熱編碼(One-hot Encoding)
- 二進制編碼(Binary Encoding )
問題:在對資料迦行預處理時,應該怎樣處理類別型特征?
序號編碼
序號編碼通常用于處理類別間具有大小關系的資料,例如成績,可以分為低、中、高三檔,并且存在“高>中>低”的排序關系,序號編碼會按照大小關系對類別型特征賦予一個數值 ID,例如高表示為 3、中表示為 2、低表示為 1,轉換后依然保留了大小關系,
獨熱編碼
獨熱編碼通常用于處理類別間不具有大小關系的特征,例如血型,一共有 4 個取值(A 型血、B 型血、AB 型血、O 型血),獨熱編碼會把血型變成一個 4 維稀疏向量,A 型血表示為(1, 0, 0, 0 ),B 型血表示為
(
0
,
1
,
0
,
0
)
,
(0,1,0,0),
(0,1,0,0), AB 型表示為
(
0
,
0
,
1
,
0
)
,
(0,0,1,0),
(0,0,1,0), O 型血表示為(
0
,
0
,
0,0,
0,0, 0, 1 ) ,對于類別取值較多的情況下使用獨熱編碼需要注意以下問題,
(1)使用稀疏向量來節省空間,在獨熱編碼下,特征向量只有某
一維取值為 1,其他位置取值均為 0,因此可以利用向量的稀疏表示有效地節省空間,并且目前大部分的演算法均接受稀疏向量形式的輸入,
(2)配合特征選擇來降低維度,高維度特征會帶來幾方面的問題,
一是在 K 近鄰演算法中,高維空間下兩點之間的距離很難得到有效的衡量;
二是在邏輯回歸模型中,引數的數量會隨著維度的增高而增加,容易引起過擬合問題; 三是通常只有部分維度是對分類、預測有幫助,因此可以考慮配合特征選擇來降低維度,
二進制編碼
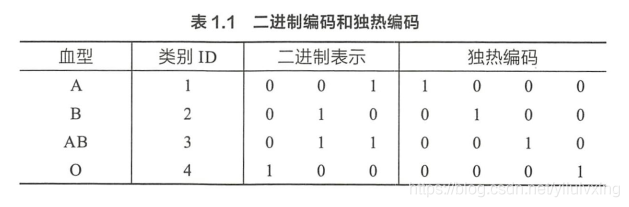
二進制編碼主要分為兩步,先用序號編碼給每個類別賦予一個類別ID,然后將類別 ID 對應的二進制編碼作為結果,以 A、B、AB、O血型為例,表 1.1 是二進制編碼的程序,A 型血的 ID 為 1,二進制表示為 001 ; B 型血的 ID 為 2,二進制表示為 010; 以此類推可以得到AB 型血和 O 型血的二進制表示,可以看出,二進制編碼本質上是利用二進制對 ID 進行哈希映射,最終得到 0/1 特征向量,且維數少于獨熱編碼,節省了存盤空間,
除上述幾種編碼方式外,還可以進一步了解真他的編碼方式,比如 Helmert Contrast 、 Sum Contrast 、 PolynomialContrast 、 Backward Difference Contrast 等 ,
3:高維組合特征的處理
問題:什么是組合特征?如何處理高維 難度:食食 會食食
組合特征?
為了提高復雜關系的擬合能力,在特征工程中經常會把一階離散特
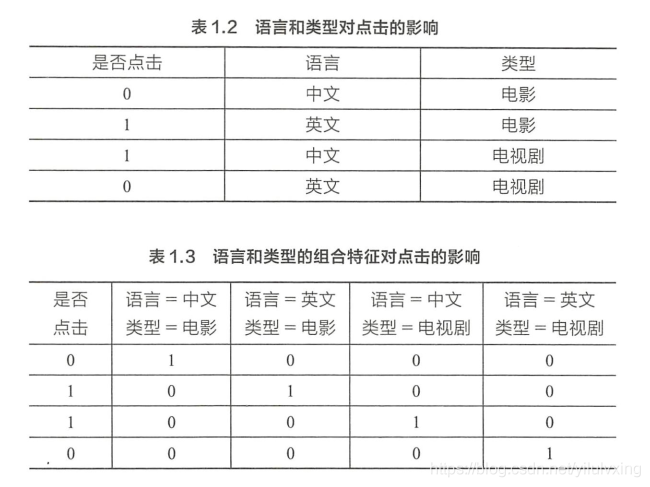
征兩兩組合,構成高階組合特征,以廣告點擊預估問題為例,原始資料有語言和型別兩種離散特征,表 1.2 是語言和型別對點擊的影響,為了提高擬合能力,語言和型別可以組成二階特征,表 1.3 是語言和型別的組合特征對點擊的影響,
以邏輯回歸為例,假設資料的特征向量為
X
=
(
x
1
,
x
2
,
…
,
x
k
)
,
X=\left(x_{1}, x_{2}, \ldots, x_{k}\right),
X=(x1?,x2?,…,xk?), 則有
Y
=
sigmoid
?
(
∑
i
∑
j
w
i
j
<
x
i
,
x
j
>
)
Y=\operatorname{sigmoid}\left(\sum_{i} \sum_{j} w_{i j}<x_{i}, x_{j}>\right)
Y=sigmoid(i∑?j∑?wij?<xi?,xj?>)
其中
<
x
i
,
x
j
>
<x_{i}, x_{j}>
<xi?,xj?> 表示
x
i
x_{i}
xi? 和
x
j
x_{j}
xj? 的組合特征,
w
i
j
w_{i j}
wij? 的維度等于
∣
x
i
∣
?
∣
x
j
∣
,
∣
x
i
∣
\left|x_{i}\right| \cdot\left|x_{j}\right|,\left|x_{i}\right|
∣xi?∣?∣xj?∣,∣xi?∣ 和
∣
x
j
∣
\left|x_{j}\right|
∣xj?∣ 分別代表第
i
i
i 個特征和第
j
j
j 個特征不同取值的個數,在表 1.3 的廣告點擊預測問題中,
w
w
w 的維度是 2 * 2=4(語言取值為中文或英文兩種、型別的取值為電影或電視劇兩種 ),這種特征組合看起來是沒有任何問題的,但當引入 ID 型別的特征時,問題就出現了,以推薦問題為例,表1.4 是用戶 ID 和物品 ID 對點擊的影響,表 1.5 是用戶 ID 和物品 ID的組合特征對點擊的影響,
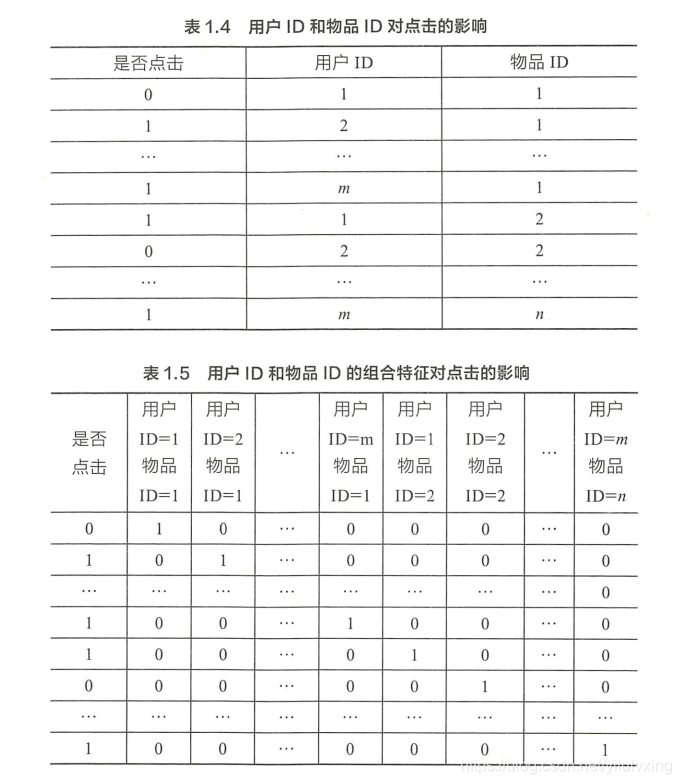
若用戶的數量為 m、物品的數量為 n,那么需要學習的引數的規模為
m
×
n
°
m \times n_{\circ}
m×n°? 在互聯網環境下,用戶數量和物品數量都可以達到千萬量級,幾乎無法學習
m
×
n
m \times n
m×n 規模的引數,在這種情況下,一種行之有效的方法是將用戶和物品分別用
k
k
k 維的低維向量表示(
k
?
m
,
k
?
n
k \ll m, k \ll n
k?m,k?n )
Y
=
sigmoid
?
(
∑
i
∑
j
w
i
j
<
x
i
,
x
j
>
)
Y=\operatorname{sigmoid}\left(\sum_{i} \sum_{j} w_{i j}<x_{i}, x_{j}>\right)
Y=sigmoid(i∑?j∑?wij?<xi?,xj?>)
其中
w
i
j
=
x
i
′
?
x
j
′
,
x
i
′
w_{i j}=x_{i}^{\prime} \cdot x_{j}^{\prime}, \quad x_{i}^{\prime}
wij?=xi′??xj′?,xi′? 和
x
j
′
x_{j}^{\prime}
xj′? 分別表示
x
i
x_{i}
xi? 和
x
j
x_{j}
xj? 對應的低維向量,在表 1.5 的推薦問題中,需要學習的引數的規模變為
m
×
k
+
n
×
k
,
m \times k+n \times k ,
m×k+n×k, 熟悉推薦演算法的很快可以看出來,這其實等價于矩陣分解,所以,這里也提供了另一個理解推薦系統中矩陣分解的思路,
4:組合特征
場景描述:
上一節介紹了如何利用降維方法來減少兩個高維特征組合后需要學習的引數,但是在很多實際問題中,我們常常需要面對多種高維特征,如果簡單地兩兩組合,依然容易存在引數過多、過擬合等問題,而且并不是所有的特征組合都是有意義的,因此,需要一種有效的方法來幫助我們找到應該對哪些特征進行組合,
問題:怎樣有效地找到組合特征?
以下介紹一種基于決策樹的特征組合尋找方法,以點擊預測問題為例,假設原始輸入特征包含年齡、性別、用戶型別(試用期、付費)、物品型別(護膚、食品等)4 個方面的資訊,并且根據原始輸入和標簽(點擊 / 未點擊)構造 出了決策樹,如圖1.2所示,于是,每一條從根節點到葉節點的路徑都可以看成一種特征組合的方式,具體來說,就有以下 4 種特征組合的方式,
(1 ) “年齡
<
=
35
"
<=35 "
<=35"
且“性別 = 女”,
(2)“年齡
<
=
3
5
′
′
<=35^{\prime \prime}
<=35′′ 且“物品類別
=
=
= 護膚"
(3)“用戶型別 = 付費”且“物品型別
=
=
= 食品”
(4)“用戶型別 = 付費”且“年齡
<
=
40
"
<=40 "
<=40"
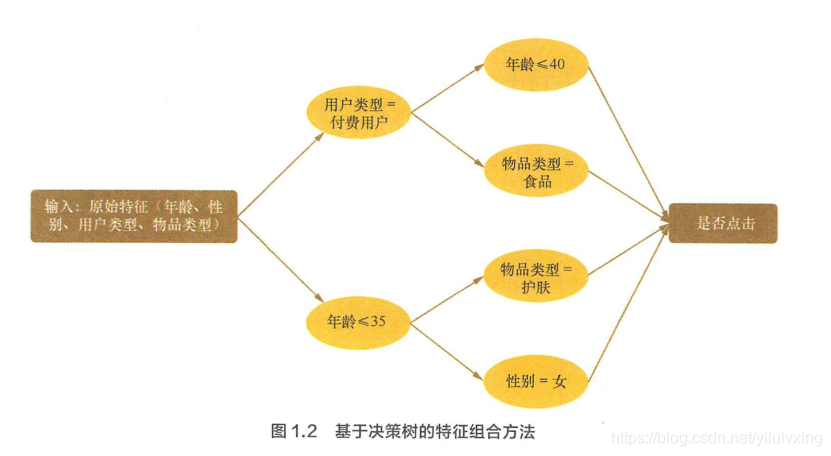
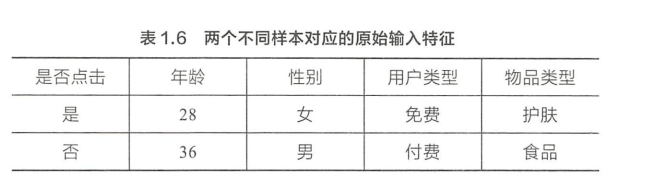
表 1. 6 是兩個樣本資訊,那么第 l 個樣本按照上述 4 個特征組合就
可以編碼為(1,1,0,0) 因為 同時滿足(1) (2),但不滿足(3)(4),同理 1 第 2 個樣本可以編碼為(0,0,1,1),因為它同時滿足(3)(4),但不滿足(1) (2)
給定原始輸入該如何有效地構造決策樹呢?可以采用梯度提升決策樹,該方法的思想是每次都在之前構建的決策樹的殘差上構建下一棵決策樹,
文本表示模型
場影描述
文本是一類非常重要的非結構化資料,如何表示文本資料一直是機器學習領域的一個重要研究方向,
涉及到的知識點:詞袋模型(Bag of Words ),TF-IDF(Term Frequency-Inverse Document Frequency ),主題模型(Topic Model),詞嵌入模型(Word Embedding )
問題:有哪些文本表示模型?什么優缺點?
- 詞袋模型
最基礎的文本表示模型是詞袋模型,顧名思義,就是將每篇文章看成一袋子詞,并忽略每個詞出現的順序,具體地說,就是將整段文本以維代表一個單詞,而該維對應的權重則反映了這個詞在原文章中的重要程度,常用 TF-IDF 來計算權重,公式為
T F ? I D F ( t , d ) = T F ( t , d ) × IDF ? ( t ) \mathrm{TF}-\mathrm{IDF}(t, d)=\mathrm{TF}(t, d) \times \operatorname{IDF}(t) TF?IDF(t,d)=TF(t,d)×IDF(t)
其中 TF ( t , d ) (t, d) (t,d) 為單詞 t t t 在檔案 d d d 中出現的頻率,IDF( t t t ) 是逆檔案頻率,用來衡量單詞 t t t 對表達語意所起的重要性,表示為
IDF ? ( t ) = log ? 文章總數 包含單詞 t 的文章總數 + 1 \operatorname{IDF}(t)=\log \frac{\text { 文章總數 }}{\text { 包含單詞}_{t} \text {的文章總數}+1} IDF(t)=log 包含單詞t?的文章總數+1 文章總數 ?
直觀的解釋是,如果一個單詞在非常多的文章里面都出現,那么它可能是一個比較通用的詞匯,對于區分某篇文章特殊語意的貢獻較小,因此對權重做一定懲罰,
將文章進行單詞級別的劃分有時候并不是一種好的做法,比如英文中的 natural language processing(自然語言處理)一詞,如果將 natural,language,processing 這 3 個詞拆分開來,所表達的含義與三個詞連續出現時大相徑庭,通常,可以將連續出現的 n 個詞 ( n ? N ) (n \leqslant N) (n?N) 組成的詞組(N-gram )也作為一個單獨的特征放到向量表示中去,構成 N-gram 模型,另外,同一個詞可能有多種詞性變化,卻具有相似的含義,在實際應用中,一般會對單詞進行詞干抽取(Word Stemming )處理,即將不同詞性的單詞統一成為同一詞干的形式,
-
主題模型
主題模型用于從文本庫中發現有代表性的主題(得到每個主題上面詞的分布特性 ),并且能夠計算出每篇文章的主題分布, -
詞嵌入與深度學習模型
詞嵌入是一類將詞向量化的模型的統稱,核心思想是將每個詞都映射成低維空間(通常 K = 50 ~ 300 K=50 \sim 300 K=50~300 維 ) 上的一個稠密向量(DenseVector ) ,K維空間的每一維也可以看作一個隱含的主題,只不過不像主題模型中的主題那樣直觀,由于詞嵌入將每個詞映射成一個 K 維的向量,如果一篇檔案有 N 個詞,就可以用一個 N * K 維的矩陣來表示這篇檔案,但是這樣的表示過于底層,在實際應用中,如果僅僅把這個矩陣作為原文本的表示特征輸入到機器學習模型中,通常很難得到令人滿意的結果,因此,還需要在此基礎之上加工出更高層的特征,在傳統的淺層機器學習模型中,一個好的特征工程往往可以帶來演算法效果的顯著提升,而深度學習模型正好為我們提供了一種自動地進行特征工程的方式,模型中的每個隱層都可以認為對應著不同抽象層次的特征,從這個角度來講,深度學習模型能夠打敗淺層模型也就順理成章了,卷積神經網路和回圈神經網路的結構在文本表示中取得了很好的效果,主要是由于它們能夠更好地對文本進行建模,抽取出一些高層的語意特征,與全連接的網路結構相比,卷積神經網路和回圈神經網路一方面很好地抓住了文本的特性,另一方面又減少了網路中待學習的引數,提高了訓練速度,并且降低了過擬合的風險,
6:Word2Vec
場景描述
谷歌 2013 年提出的 Word2Vec 是目前最常用的詞嵌入模型之一,Word2Vec 實際是一種淺層的神經網路模型,它有兩種網路結構,分別是 CBOW(Continues Bag of Words )和 Skip-gram,
涉及到的知識點:Word2Vec ,隱狄利克雷模型( LDA) , CBOW, Skip-gram
問題:Word2Vec 是如何作業的?芭 難度:食食食 會食
和 LOA 有什么區別與聯系?
CBOW 的目標是恨據上下艾出現的詞語來預測當前i司的生成慨率,如圖 1.3 ( a )所示 ; 而 Skip-gram 是根據當前詞來預測背景關系中詞的生成概率, 如圄 1.3 ( b ) 所示
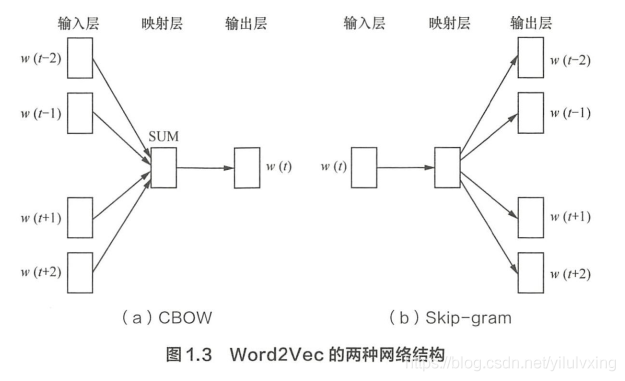
其中
w
(
t
)
w(t)
w(t) 是當前所關注的詞,
w
(
t
?
2
)
,
w
(
t
?
1
)
,
w
(
t
+
1
)
,
w
(
t
+
2
)
w(t-2), w(t-1), w(t+1), w(t+2)
w(t?2),w(t?1),w(t+1),w(t+2)
是背景關系中出現的詞,這里前后滑動視窗大小均設為 2,
CBOW 和 Skip-gram 都可以表示成由輸入層(Input)、映射層(Projection)和輸出層(Output)組成的神經網路,輸入層中的每個詞由獨熱編碼方式表示,即所有詞均表示成一個 N維向量,其中 N 為詞匯表中單詞的總數,在向量中,每個詞都將與之對應的維度置為 1,其余維度的值均設為 0,
在映射層(又稱隱含層)中,K 個隱含單元(Hidden Units)的取 值可以由 N 維輸入向量以及連接輸入和隱含單元之間的
N
×
K
N \times K
N×K 維權重矩陣計算得到,在 CBOW 中,還需要將各個輸入詞所計算出的隱含單元求和,同理,輸出層向量的值可以通過隱含層向量(K 維),以及連接隱含層和輸出層之間的
K
×
N
K \times N
K×N 維權重矩陣計算得到,輸出層也是一個
N
N
N 維向量,每維與詞匯表中的一個單詞相對應,最后,對輸出層向量應用Softmax 激活函式,可以計算出每個單詞的生成概率,Softmax 激活函式的定義為
P
(
y
=
w
n
∣
x
)
=
e
x
n
∑
k
=
1
N
e
x
k
P\left(y=w_{n} \mid x\right)=\frac{\mathrm{e}^{x_{n}}}{\sum_{k=1}^{N} \mathrm{e}^{x_{k}}}
P(y=wn?∣x)=∑k=1N?exk?exn??
其中 x 代表
N
N
N 維的原始輸出向量,x_為在原始輸出向量中,與單詞
w
n
w_{n}
wn?所對應維度的取值,
其中 x 代表 N N N 維的原始輸出向量, x n x_{n} xn? 為在原始輸出向量中,與單詞 w n w_{n} wn?所對應維度的取值,接下來的任務就是訓練神經網路的權重,使得語料庫中所有單詞的整體生成概率最大化,從輸入層到隱含層需要一個維度為 N\timesK 的權重矩陣,從隱含層到輸出層又需要一個維度為 K\timesN 的權重矩陣,學習權重可以用反向傳播演算法實作,每次迭代時將權重沿梯度更優的方向進行一小步更新,但是由于 Softmax 激活函式中存在歸一化項的緣故,推匯出來的迭代公式需要對詞匯表中的所有單詞進行遍歷,使得每次迭代程序非常緩慢,由此產生了 Hierarchical Softmax 和 Negative Sampling 兩種改進方法,有興趣的讀者可以參考 Word2Vec 的原論文,訓練得到維度為 N × K N \times K N×K 和 K × N K \times N K×N 的兩個權重矩陣之后,可以選擇其中一個作為 N N N 個詞的 K K K 維向量表示,
談到 Word2Vec 與 LDA 的區別和聯系,首先,LDA 是利用檔案中單詞的共現關系來對單詞按主題聚類,也可以理解為對“檔案 - 單詞”矩陣進行分解,得到“檔案 - 主題”和“主題 - 單詞”兩個概率分布,而 Word2Vec 其實是對“背景關系 - 單詞”矩陣進行學習,其中背景關系由周圍的幾個單詞組成,由此得到的詞向量表示更多地融入了背景關系共現的特征,也就是說,如果兩個單詞所對應的 Word2Vec 向量相似度較高,那么它們很可能經常在同樣的背景關系中出現,需要說明的是,上述分析的是 LDA 與 Word2Vec 的不同,不應該作為主題模型和詞嵌入兩類方法的主要差異,主題模型通過一定的結構調整可以基于“背景關系 - 單詞”"矩陣進行主題推理,同樣地,詞嵌入方法也可以根據“檔案 - 單詞”矩陣學習出詞的隱含向量表示,主題模型和詞嵌入兩類方法最大的不同其實在于模型本身,主題模型是一種基于概率圖模型的生成式模型,其似然函式可以寫成若干條件概率連耕的形式,其中包括需要推測的隱含變數(即主題); 而詞嵌入模型一般表達為神經網路的形式,似然函式定義在網路的輸出之上,需要通過學習網路的權重以得到單詞的稠密向量表示,
7:影像資料不足時的處理方法
場景描述
在機器學習中,絕大部分模型都需要大量的資料進行訓練和學習(包括有監督學習和無監督學習),然而在實際應用中經常會遇到訓練資料不足的問題,比如影像分類,作為計算機視覺最基本的任務之一,其目標是將每幅影像劃分到指定類別集合中的一個或多個類別中,當訓練一個影像分類模型時,如果訓練樣本比較少,該如何處理呢?
涉及到的知識點:遷移學習( Transfer Learning ),生成對抗網路,影像處理,上采樣技術,資料擴充
問題:在影像分類任務中,訓練資料不足會帶來什么問題?如何緩解資料量不足帶來的問題?
一個模型所能提供的資訊一般來源于兩個方面,一是訓練資料中蘊含的資訊; 二是在模型的形成程序中(包括構造、學習、推理等),人們提供的先驗資訊,當訓練資料不足時,說明模型從原始資料中獲取的資訊比較少,這種情況下要想保證模型的效果,就需要更多先驗資訊,先驗資訊可以作用在模型上,例如讓模型采用特定的內在結構、條件假設或添加其他一些約束條件; 先驗資訊也可以直接施加在資料集上,即根據特定的先驗假設去調整、變換或擴展訓練資料,讓其展現出更多的、更有用的資訊,以利于后續模型的訓練和學習,
具體到影像分類任務上,訓練資料不足帶來的問題主要表現在過擬合方面,即模型在訓練樣本上的效果可能不錯,但在測驗集上的泛化效果不佳,根據上述討論,對應的處理方法大致也可以分兩類,一是基于模型的方法,主要是采用降低過擬合風險的措施,包括簡化模型(如將非線性模型簡化為線性模型)、添加約束項以縮小假設空間(如 L1/L2正則項)、集成學習、Dropout 超引數等; 二是基于資料的方法,主要通過資料擴充(Data Augmentation),即根據一些先驗知識,在保持特定資訊的前提下,對原始資料進行適當變換以達到擴充資料集的效果,具體到影像分類任務中,在保持影像類別不變的前提下,可以對訓練集中的每幅影像進行以下變換,
(1)一定程度內的隨機旋轉、平移、縮放、裁剪、填充、左右翻
轉等,這些變換對應著同一個目標在不同角度的觀察結果,
(2)對影像中的像素添加噪聲擾動,比如椒鹽噪聲、高斯白噪聲等,
(3)顏色變換,例如,在影像的 RGB 顏色空間上進行主成分分
析,得到 3 個主成分的特征向量
p
1
,
p
2
,
p
3
p_{1}, p_{2}, p_{3}
p1?,p2?,p3? 及其對應的特征值
λ
1
,
λ
2
,
λ
3
,
\lambda_{1}, \lambda_{2}, \lambda_{3},
λ1?,λ2?,λ3?, 然后在每個像素的 RGB 值上添加增量
[
p
1
,
p
2
,
p
3
]
?
[
α
1
λ
1
,
α
2
λ
2
,
α
3
λ
3
]
T
,
\left[p_{1}, p_{2}, p_{3}\right] \cdot\left[\alpha_{1} \lambda_{1}, \alpha_{2} \lambda_{2}, \alpha_{3} \lambda_{3}\right]^{\mathrm{T}},
[p1?,p2?,p3?]?[α1?λ1?,α2?λ2?,α3?λ3?]T, 其中
α
1
,
α
2
,
α
3
\alpha_{1}, \alpha_{2}, \alpha_{3}
α1?,α2?,α3? 是均值為 0 、方差較小的高斯分布亂數,
(4)改變影像的亮度、清晰度、對比度、銳度等,

除了直接在影像空間進行變換,還可以先對影像進行特征提取,然后在影像的特征空間內進行變換,利用一些通用的資料擴充或上采樣技術,例如 SMOTE(Synthetic Minority Over-sampling Technique )演算法,拋開上述這些啟發式的變換方法,使用生成模型也可以合成一些新樣本,例如當今非常流行的生成式對抗網路模型,此外,借助已有的其他模型或資料來進行遷移學習在深度學習中也十分常見,例如,對于大部分影像分類任務,并不需要從頭開始訓練模型,而是借用一個在大規模資料集上預訓練好的通用模型,并在針對目標任務的小資料集上進行微調(fine-tune),這種微調操作就可以看成是一種簡單的遷移學習,
參考書籍
參考書籍:《百面機器學習》
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/159955.html
標籤:python
上一篇:大資料的簡要介紹
下一篇:初學C語言之小技巧