1.一般的python爬蟲很簡單,直接請求對應網址,決議回傳的資料即可,但是有很多網站的資料的js動態渲染的,你直接請求是得不到對應的資料的
這時就需要其它手段來處理了,
2.以一個例子來說明,整個程序,爬取一個音樂網站的對應歌手的歌曲,
- 目標網址http://tool.liumingye.cn/music/?page=searchPage,在搜索框輸入歌手名字即可得到歌曲,
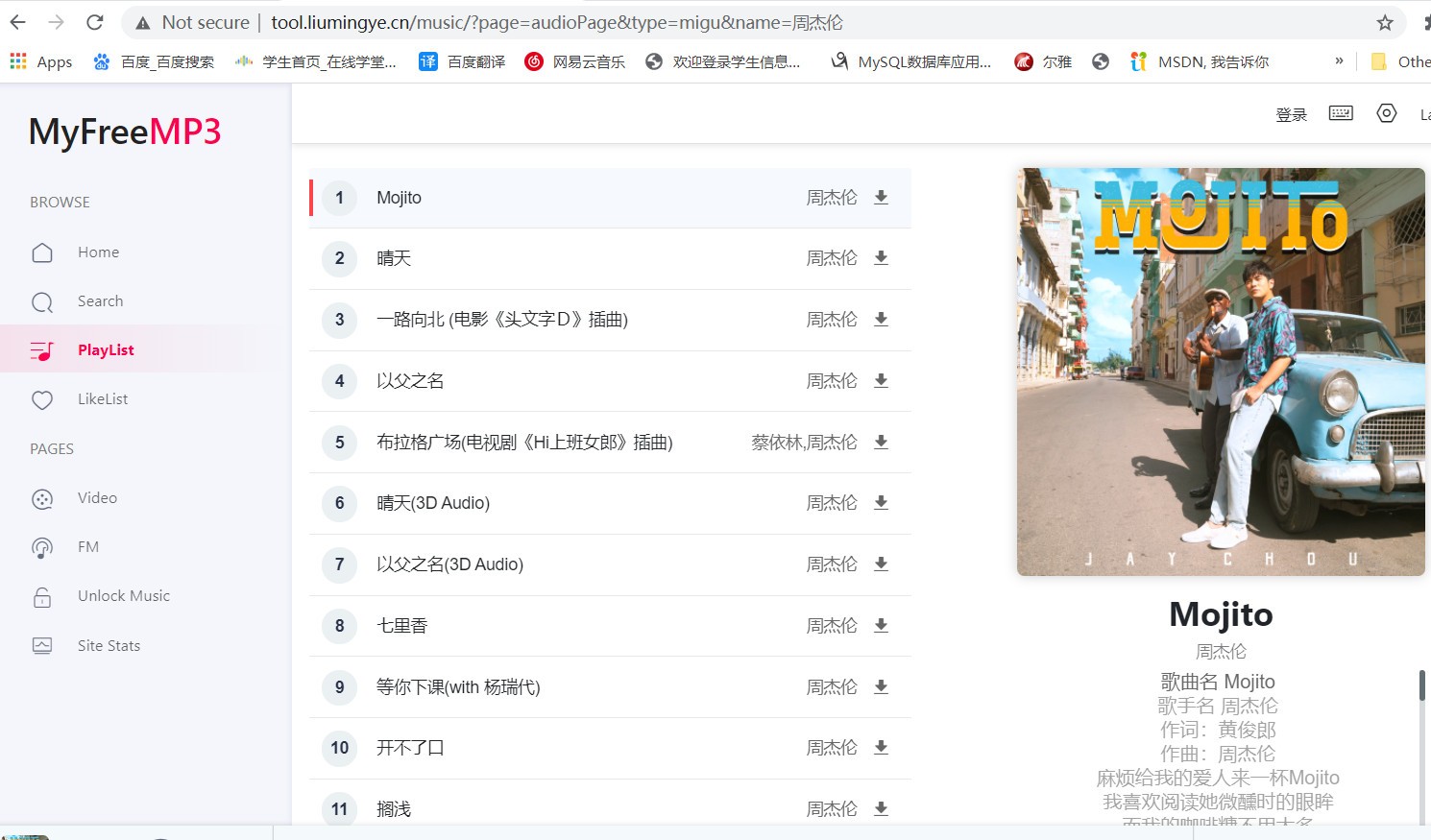
- 如果我們直接請求這個網址:http://tool.liumingye.cn/music/?page=audioPage&type=migu&name=周杰倫,回傳的資料不是我們想要的

- 在inspect里分析js或xhr資料找到真正的網址,可以看到在NetWork下的XHR中找到我們想要的網址,還有POSt請求時發送的資料


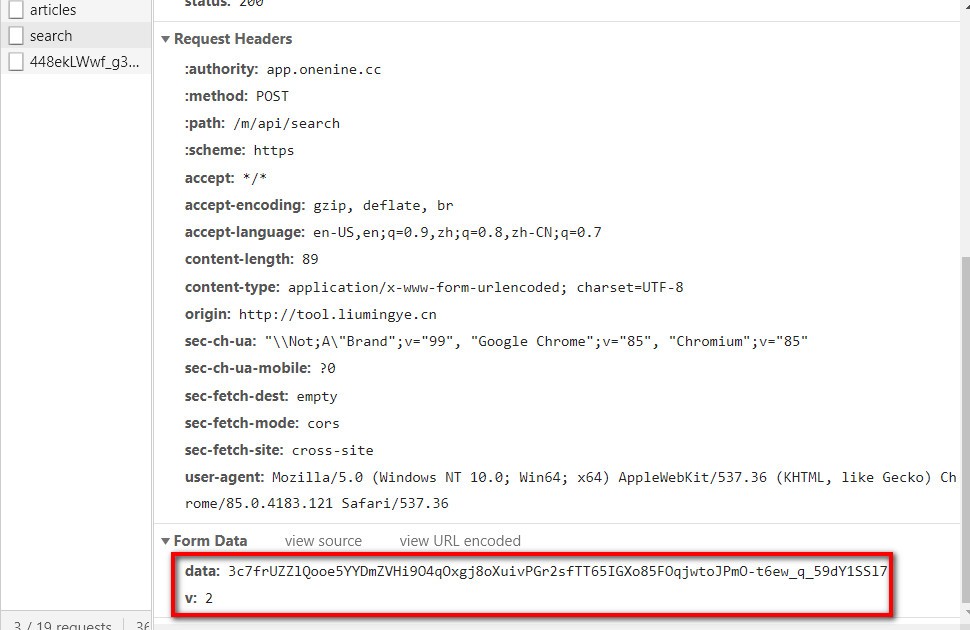
-
我們仿照他發起一個post請求,回傳的資料確實是我們想要的,里面包含歌曲名字,還有下載地址,歌詞等資訊,直接請求歌曲下載地址即可,
import requests headers = { 'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'} data={'data':'3c7frUZZlQooe5YYDmZVHi9O4qOxgj8oXuivPGr2sfTT65IGXo85FOqjwtoJPmO-t6ew_q_59dY1SSl7','v':'2'} r=requests.post('https://app.onenine.cc/m/api/search',headers=headers,data=https://www.cnblogs.com/duichoumian/archive/2020/10/06/data)
data=r.json()#轉為json print(data['data']['list'])
- 大家不要覺得這樣就可以了喔,其實問題還有很多,第一,你要構造POST請求必須要得到data引數的資料,就是那一長串字串,如果沒有data的話,會回傳狀態碼403,禁止訪問
- 而且每一個歌手或歌曲的data引數都是動態生成的,沒有規律的,這樣的話,你每構造一個POST請求就要在游覽器那里看一下data引數是多少,根本不符合爬蟲的要求,
- 第二,回傳的資料只有二十首歌曲,想要得到更多,就必須點擊‘下一頁'按鈕,網站才會去請求下一個二十首,然后渲染到網頁上,所以就算有data引數,也無法爬到更多資料,
3.這時就到了Seleninum和Browsermob-proxy出場了,Seleninum是一個用于測驗網站的自動化測驗工具,支持各種瀏覽器包括Chrome、Firefox、Safari等主流界面瀏覽器,同時也支持phantomJS無界面瀏覽器,它主要得功能就是可以模擬游覽器行為,包括執行js代碼,尋找各種元素,發送點擊,滑動事件等等,這樣我們就可以實作點擊功能了,selenium的教程推薦這個,他寫得不錯,比我寫得好
https://blog.csdn.net/qq_32502511/article/details/101536325
Browsermob-proxy是一個開源的Java撰寫的基于LittleProxy的代理服務,Browsermob-Proxy的具體流程有點類似與Flidder或Charles,即開啟一個埠并作為一個標準代理存在,當HTTP客戶端(瀏覽器等)設定了這個代理,則可以抓取所有的請求細節并獲取回傳內容.簡單來說就是它可以將網站的請求和回傳的資料獲取到,就如游覽器的'inspect'功能,這樣我們就可以獲取到‘seacher’的資料了
Browsermob-proxy的教程推薦這個,不難的,看一下就可以上手了,https://blog.csdn.net/qq_32502511/article/details/101536325
4.我們分析一下獲取到的資料,包含名字和歌詞,封面,下載地址,歌曲的下載地址有四種,url_m4a是流暢,128是標準,320是高品,flac則是無損音樂,url那一欄是在線播放
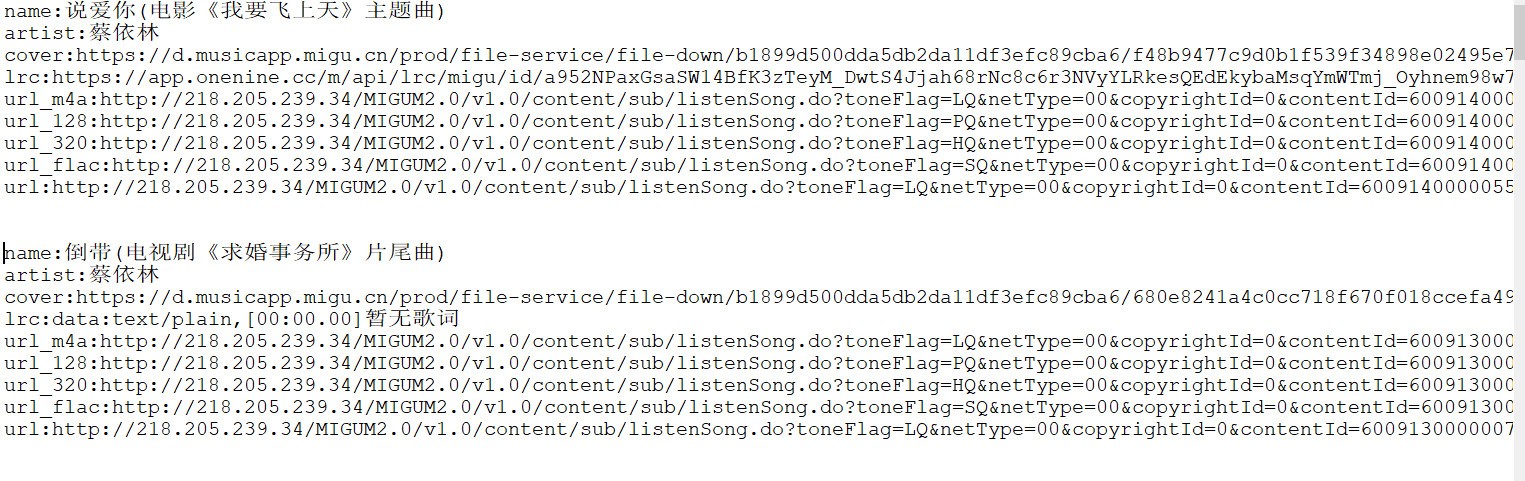
4.有上面這些準備后就可以寫代碼爬取資料了,代碼如下(有詳細注釋)
from selenium import webdriver import time import os import threading import simplejson as json from browsermobproxy import Server import requests from selenium.webdriver.chrome.options import Options #Browsermob-proxy的路徑 server=Server(r"D:\Python3.7\browser-proxy.bat\browsermob-proxy-2.1.4\bin\browsermob-proxy.bat") server.start()#啟動browsermob-proxy proxy=server.create_proxy() chrome_options=Options() #獲取游覽器物件,設定無界面模式 chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy)) chrome_options.add_argument('--headless')#無頭模式,不開啟游覽器界面 chrome_options.add_argument('--disable-gpu') chrome_options.add_argument('--incognito') driver=webdriver.Chrome(chrome_options=chrome_options)#啟用谷歌游覽器 #獲取音樂的資訊 def getDownloadUrls(name): musicUrl='http://tool.liumingye.cn/music/?page=audioPage&type=migu&name='+str(name) proxy.new_har('music',options={'captureHeaders':True,'captureContent':True}) driver.get(musicUrl)#請求網站 time.sleep(3)#等待頁面加載完成,必須要延時,不然獲取不到資料 lists=[] #獲取3頁資料一共60首歌 for i in range(3): index=0 result=proxy.har#獲取所有請求網址 for entry in result['log']['entries']: url=entry['request']['url'] #找對應的網址,我們要的是,search網址的 if "app.onenine.cc/m/api/search" in url: index+=1 ''' 因為每點擊下一頁都會產生一個新的‘search', 而proxy每次都會把所有的請求獲取到,所以上一個的’search‘也會獲取到 所以要判斷排除掉,只獲取最新的’search' ''' if index>i: content = entry['response']['content'] text=content['text'] data=json.loads(text)['data'] lists.extend(data['list']) #這里就是獲取到的json資料.每一次添加20首歌曲的資訊進去 #滑到底部 js="window.scrollTo(0,10000)"#滑動滾動條的js代碼,如果元素不在頁面上顯示,是找不到的,所以滑動,讓下一頁的按鈕顯示出來 driver.execute_script(js)#執行·js代碼 #點擊下一頁,獲取更多歌曲 nextBtn=driver.find_element_by_css_selector('#player>div.aplayer-more')#找到下一頁的按鈕 nextBtn.click()#發送點擊事件 time.sleep(1)#延時1秒等待資料加載 return lists #用于下載音樂代碼 def download(path,musicName,folder,ext): r=requests.get(path) f=open(folder+'/'+musicName+ext,'wb') f.write(r.content) f.close() #在lists例表中提取音樂的下載地址和歌曲名字 def downloadMusic(name,type,lists): ''' name:歌手名字,為每一個歌手都新建一個檔案夾 type:表示要下載何種音質 lists:獲取的音樂資料串列 ''' isExists=os.path.exists(name) if not isExists: os.makedirs(name) musicName='' path='' ext='' for item in lists: for key,value in item.items(): ext='.mp3' key=str(key) if key=='name': musicName=value elif key=='artist': musicName=musicName+'-'+value elif key=='url_m4a' and type==0:#m4a表示流暢 path=value elif key=='url_128' and type==1:#128是標準 path=value elif key=='url_320' and type==2:#320是高品質 path=value elif key=='url_flac'and type==3:#flac表示無損 path=value ext='.flac' if len(path)!=0: #每一首歌開啟一個執行緒去下載 t = threading.Thread(target=download,args=(path,musicName,name,ext)) t.start() t.join() path='' musicName='' if __name__=='__main__': signer=input("輸入歌手名字:") lists=getDownloadUrls(signer) print('獲取完成,開始下載音樂') downloadMusic(signer,0,lists)#0表示下載流暢音質的 print('下載結束')
等待一段時間就爬取成功了,

5.這個網站上還有歌單和各種音樂榜單,我們一樣可以爬取下來,原理都一樣,我就不多解釋了,你只要掌握上面的東西,爬取這些東西,還是很簡單的,只要給點耐心去學一下,

附上完整代碼,包括爬取歌單和榜單
from selenium import webdriver import time import os import threading import simplejson as json from browsermobproxy import Server import requests from selenium.webdriver.chrome.options import Options #Browsermob-proxy的路徑 server=Server(r"D:\Python3.7\browser-proxy.bat\browsermob-proxy-2.1.4\bin\browsermob-proxy.bat") server.start()#啟動browsermob-proxy proxy=server.create_proxy() chrome_options=Options() #獲取游覽器物件,設定無界面模式 chrome_options.add_argument('--proxy-server={0}'.format(proxy.proxy)) chrome_options.add_argument('--headless')#無頭模式,不開啟游覽器界面 chrome_options.add_argument('--disable-gpu') chrome_options.add_argument('--incognito') driver=webdriver.Chrome(chrome_options=chrome_options)#啟用谷歌游覽器 #獲取音樂的資訊 def getDownloadUrls(name): musicUrl='http://tool.liumingye.cn/music/?page=audioPage&type=migu&name='+str(name) proxy.new_har('music',options={'captureHeaders':True,'captureContent':True}) driver.get(musicUrl)#請求網站 time.sleep(3)#等待頁面加載完成,必須要延時,不然獲取不到資料 lists=[] #獲取3頁資料一共60首歌 for i in range(3): index=0 result=proxy.har#獲取所有請求網址 for entry in result['log']['entries']: url=entry['request']['url'] #找對應的網址,我們要的是,search網址的 if "app.onenine.cc/m/api/search" in url: index+=1 ''' 因為每點擊下一頁都會產生一個新的‘search', 而proxy每次都會把所有的請求獲取到,所以上一個的’search‘也會獲取到 所以要判斷排除掉,只獲取最新的’search' ''' if index>i: content = entry['response']['content'] text=content['text'] data=json.loads(text)['data'] lists.extend(data['list']) #這里就是獲取到的json資料.每一次添加20首歌曲的資訊進去 #滑到底部 js="window.scrollTo(0,10000)"#滑動滾動條的js代碼,如果元素不在頁面上顯示,是找不到的,所以滑動,讓下一頁的按鈕顯示出來 driver.execute_script(js)#執行·js代碼 #點擊下一頁,獲取更多歌曲 nextBtn=driver.find_element_by_css_selector('#player>div.aplayer-more')#找到下一頁的按鈕 nextBtn.click()#發送點擊事件 time.sleep(1)#延時1秒等待資料加載 return lists #用于下載音樂代碼 def download(path,musicName,folder,ext): r=requests.get(path) f=open(folder+'/'+musicName+ext,'wb') f.write(r.content) f.close() #在lists例表中提取音樂的下載地址和歌曲名字 def downloadMusic(name,type,lists): ''' name:歌手名字,為每一個歌手都新建一個檔案夾 type:表示要下載何種音質 lists:獲取的音樂資料串列 ''' isExists=os.path.exists(name) if not isExists: os.makedirs(name) musicName='' path='' ext='' for item in lists: for key,value in item.items(): ext='.mp3' key=str(key) if key=='name': musicName=value elif key=='artist': musicName=musicName+'-'+value elif key=='url_m4a' and type==0:#m4a表示流暢 path=value elif key=='url_128' and type==1:#128是標準 path=value elif key=='url_320' and type==2:#320是高品質 path=value elif key=='url_flac'and type==3:#flac表示無損 path=value ext='.flac' if len(path)!=0: #每一首歌開啟一個執行緒去下載 t = threading.Thread(target=download,args=(path,musicName,name,ext)) t.start() t.join() path='' musicName='' #獲取歌單的id和歌單名字 def getSongsSheetId(type): id=[] sheetNames=[] #這里的 limit表示獲取多少個歌單,2表示兩個 url='https://musicapi.leanapp.cn/top/playlist?limit=2&offset=0&order=hot&cat='+str(type) r=requests.get(url); data=r.json() playlist=data['playlists'] for item in playlist: id.append(item['id']) sheetNames.append(item['name']) print(id) return id,sheetNames #下載歌單的歌曲 def getSongsSheetSongs(type): id,sheetNames=getSongsSheetId('日語')#這里可以做成變數,比如華語,歐美,流行.... url='http://tool.liumingye.cn/music/?page=audioPage&type=YQD&name=https%3A%2F%2Fmusic.163.com%2F%23%2Fplaylist%3Fid%3D' lists=[] for i in range(len(id)): reqUrl=url+str(id[i]) proxy.new_har('lists',options={'captureHeaders':True,'captureContent':True}) driver.get(reqUrl) time.sleep(3) result=proxy.har for entry in result['log']['entries']: repUrl=entry['request']['url'] if "app.onenine.cc/m/api/search" in repUrl: content = entry['response']['content'] text=content['text'] data=json.loads(text)['data'] lists=data['list'][:] downloadMusic(sheetNames[i],type,lists) #榜單,榜單比較少所以可以,直接復制data資料然后直接請求 def getMusicListSongs(listType,quality): ''' listType:何種榜單 quality:何種音質 ''' musicLists={'飆升榜':'9a96BCVWtsdySz5JAlEM4ETawT0kPc0PKnwYwhGTCdL_ABeeIChrZMDWVoEkAy8xVORmVw_mS9xE1maSBbzV1ISsUCDTq2_sWMDY2T-KnB7cqYjoRo9EYTROqsURCA', '新歌榜':'0eb8XS226D93TYlB6f0YRLwpd88EElQZglIn4CnZo9CUa8yqKtPDCG-pL3GKi_9UoBxJClL04dhhdgjAh-EAho2EkPBct2PF2tJl3F8p2atv3IwIxgPYE9iDGFKD', '原創':'9cecTgCD-VsNzA2od9fsyX6c2KpOCdI1VfGRMO26vy4XgwyApkwNtsii9u2La2FS1xoBsJL-nPFpORJ1t9Vd3T0aSzg-0R2LWbS8Yj8wJeYsTVlnnbzFdMeO88OV', '熱歌榜':'bfaFw92RlNQ6e3pJQ9tIkNtitPFqTUbXZHDzE8yuiJ-nNo7gpsDldd5R6AQ83eqQCuE9Id2GiS6ycC9Q8wqeB-HNfxC-Q-Mbv-Amdir7AHal8MKsHnZYeiCWKGG', 'ACG音樂榜':'b91b2EKQBotaf_vdDg3ttFZwGBGJ_uFpbSf8oSjga2p7NKAsNCCHFdj_dywOpfalhPUQz78HAwDNqp127vWDFCP5Ie4pKJEbigRXjr0FwVgPcrhyR5A_RvbJibnGlw', '歐美熱歌榜':'10e2UIqDLgcQvg74T9Y6BU0mlxUHvstcHkV5UKHPkSDzyi3TRBORkKAKLtAspirLXvbbTwN4B8Jm_IYzis6kbq1VkFnbcpM28AV54vdGk9Trj1ycEP1FbclVuvxGAXuX', '抖音熱歌榜':'b0758Dllkk2pO4ripW44AWtSVQMHsmPgxNcVsJZmQKtNgoIi4dCd0CVRsKOIt69f6TFRffmQhJKCp6dBO9l1UGyiwUks3T5xlxHndE5oOz0NJogMrE49W6e2S8xc-sZb', '古典音樂榜':'c6540n5sOF11X1eYySdN9elyUeEtSPKAzU0b-Pm41g5Kpt7WGD7E6pEVyNNMEsMb5OL5f5NC-bAt6Prqvesz9xIwYWDrHCbfAsWldzvzMDJCNybErloRvh98iev2oQ' } lists=[] url='https://app.onenine.cc/m/api/search' headers={'content-type':'application/x-www-form-urlencoded; charset=UTF-8','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'} data={'data':'b91b2EKQBotaf_vdDg3ttFZwGBGJ_uFpbSf8oSjga2p7NKAsNCCHFdj_dywOpfalhPUQz78HAwDNqp127vWDFCP5Ie4pKJEbigRXjr0FwVgPcrhyR5A_RvbJibnGlw','v':'2'} r=requests.post(url,headers=headers,data=https://www.cnblogs.com/duichoumian/archive/2020/10/06/data)#構造post請求 data=https://www.cnblogs.com/duichoumian/archive/2020/10/06/r.json() print(len(data)) lists=data['data']['list'] #data=https://www.cnblogs.com/duichoumian/archive/2020/10/06/data['list'] #print(data) downloadMusic(listType,quality,lists) if __name__=='__main__': signer=input("輸入歌手名字:") lists=getDownloadUrls(signer) print('獲取完成,開始下載音樂') downloadMusic(signer,0,lists)#0表示下載流暢音質的 print('下載結束') ''' #這個是下載歌單的 getSongsSheetSongs(0) ''' ''' #這個是下載榜單的 getMusicListSongs('ACG音樂榜',1) ''' # getSongsSheetSongs(1) # getMusicListSongs('ACG音樂榜',1) # print('end') server.stop() driver.quit()
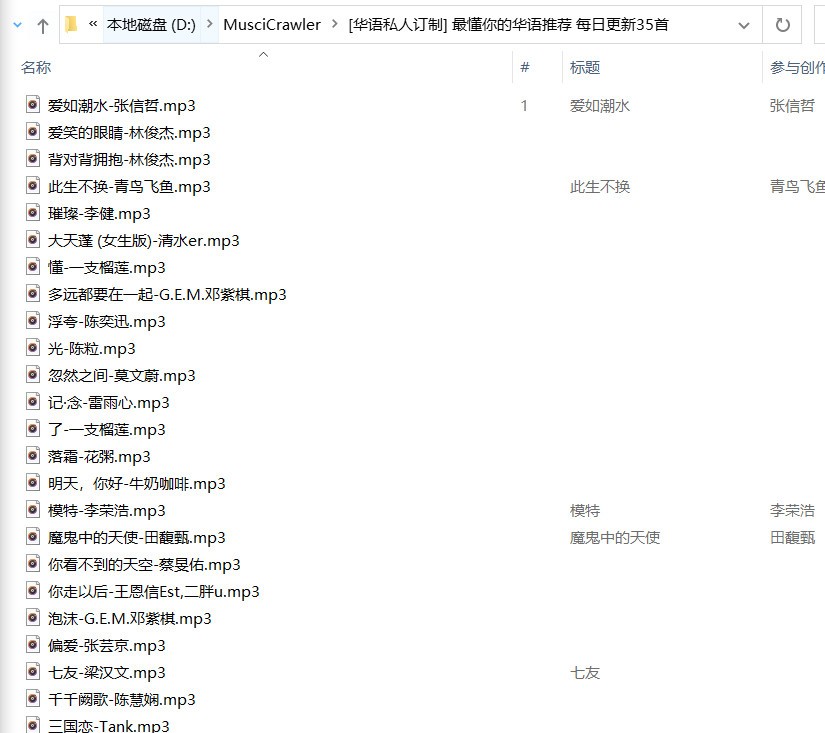
效果
6.在Windows下安裝Browsermob-proxy,可能比較麻煩一點,如果不會,可以找,
有其他問題也可以隨時留言,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/160086.html
標籤:其他