結合一些文章閱讀原始碼后整理的Java容器常見知識點,對于一些代碼細節,本文不展開來講,有興趣可以自行閱讀參考文獻,
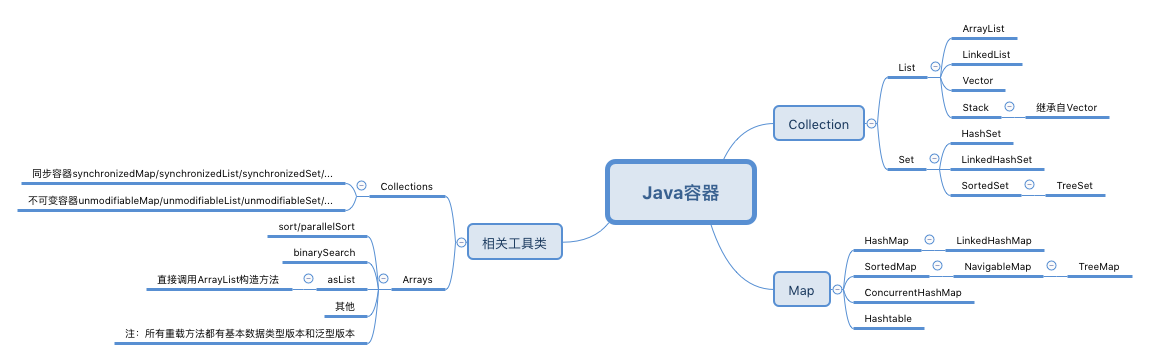
1. 思維導圖
各個容器的知識點比較分散,沒有在思維導圖上體現,因此看上去右半部分很像類的繼承關系,
2. 容器對比
| 類名 | 底層實作 | 特征 | 執行緒安全性 | 默認迭代器實作(Itr) |
|---|---|---|---|---|
| ArrayList | Object陣列 | 查詢快,增刪慢 | 不安全,有modCount | 陣列下標 |
| LinkedList | 雙向鏈表 | 查詢慢,增刪快 | 不安全,有modCount | 當前遍歷的節點 |
| Vector | Object陣列 | 查詢快,增刪慢 | 方法使用synchronized確保安全(注1);有modCount | 陣列下標 |
| Stack | Vector | 同Vector | 同Vector | 同Vector |
| HashSet | HashMap (使用帶特殊引數的構造方法則為LinkedHashMap) | 和HashMap一致 | 和HashMap一致 | 和HashMap一致 |
| LinkedHashSet | LinkedHashMap | 和LinkedHashMap一致 | 和LinkedHashMap一致 | 和LinkedHashMap一致 |
| TreeSet | TreeMap | 和TreeMap一致 | 和TreeMap一致 | 和TreeMap一致 |
| TreeMap | 紅黑樹和Comparator(注2) | key和value可以為null(注2),key必須實作Comparable介面 | 非執行緒安全,有modCount | 當前節點在中序遍歷的后繼 |
| HashMap | 見第3節 | key和value可以為null | 非執行緒安全,有modCount | HashIterator按陣列索引遍歷,在此基礎上按Node遍歷 |
| LinkedHashMap | extends HahsMap (注3), Node有前驅和后繼 | 可以按照插入順序或訪問順序遍歷(注4) | 非執行緒安全,有modCount | 同HshMap |
| ConcurrentHashMap | 見第3節 | key和value不能為null | 執行緒安全(注1) | 基于Traverser(注5) |
| Hashtable | Entry陣列 + Object.hashCode() + 同key的Entry形成鏈表 | key和value不允許為null | 執行緒安全, 有modCount | 列舉類或通過KeySet/EntrySet |
操作的時間復雜度
- ArrayList下標查找O(1),插入O(n)
- 涉及到樹,查找和插入都可以看做log(n)
- 鏈表查找O(n),插入O(1)
- Hash直接查找hash值為 O(1)
注1:關于容器的執行緒安全
復合操作
無論是Vetcor還是SynchronizedCollection甚至是ConcurrentHashMap,復合操作都不是執行緒安全的,如下面的代碼[1]在并發環境中可能會不符合預期:
if (!vector.contains(element))
vector.add(element);
...
}
ConcurrentHashMap<String, Integer> map = new ConcurrentHashMap();
map.put("key", 1);
// 多執行緒環境下執行
Integer currentVal = map.get("key");
map.put("key", currentVal + 1);
在復合操作的場景下,通用解法是對容器加鎖,但這樣會大幅降低性能,根據具體的場景來解決效果更好,如第二段代碼的場景,可以改寫為[1]
ConcurrentHashMap<String, AtomicInteger> map = new ConcurrentHashMap();
// 多執行緒環境下執行
map.get("key").incrementAndGet();
modCount和迭代器Iterator問題
modCount是大多數容器(比如ConcurrentHashMap就沒有)用來檢測是否發生了并發操作,從而判斷是否需要拋出例外通知程式員去處理的一個簡單的變數,也被稱為fast-fail,
一開始我注意到,Vector也有modCount這個屬性,這個欄位用來檢測對于容器的操作期間是否并發地進行了其他操作,如果有會拋出并發例外,既然Vector是執行緒安全的,為什么還會有modCount?順藤摸瓜,我發現雖然Vector的Iterator()方法是synchronized的,但是迭代器本身的方法并不是synchronized的,這就意味著在使用迭代器操作時,對Vector的增刪等操作可能導致并發例外,
為了避免這個問題,應該在使用Iterator時對Vector加鎖,
同理可以推廣到Collecitons.synchronizedCollection()方法,可以看到這個方法創建的容器,對于迭代器和stream方法,都有一行// Must be manually synched by user!的注釋,
注2:TreeMap的comparator和key
comparator是可以為空的,此時使用key的compare介面比較,因此,這種情況下如果key==null會拋NPE,
注3:
JDK8的HashMap中有afterNodeAccess()、afterNodeInsertion()、afterNodeRemoval()三個空方法,在LinkedHashMap中覆寫,用于回呼,
注4:LinkedHashMap插入順序和訪問順序
插入順序不必解釋,訪問順序指的是,每次訪問一個節點,都將它插入到雙向鏈表的末尾,
注5:Traverser
其實作類EntryIterator的構造方法實際上是有bug的[5]:它與子類的引數表順序不一致,
它能確保在擴容期間,每個節點只訪問一次,這個原理比較復雜,我沒有深入去看,可以參考本小節的參考文獻,
3. Hashtable & HashMap & ConcurrentHashMap
這是一個老生常談的話題了,但是涉及面比較廣,本節好好總結一下,
本節不列出具體的原始碼,大部分直接給出結論,原始碼部分分析可以參考文獻[7][8],
table表示Map的hash值桶,即每一個元素對應所有同一個hash值的key-value對,
相同點
- keySet、values、entrySet()首次使用時初始化
差異點
| 容器型別 | 底層實作(見說明4) | key的hash方法 | table下標計算 | 擴容后table容量(見說明1、5) | 插入 | clone | hash桶的最大容量 |
|---|---|---|---|---|---|---|---|
| Hashtable | hash值桶陣列 + 鏈表 | hashCode() | (hashCode & MAX_INT) % table.length | origin*2+1 | 頭部插入 | 淺拷貝 | MAXINT- 8 |
| HashMap(1.7) | hash值桶陣列 + 鏈表 | String使用sun.misc.Hashing.stringHash32,其他用hashCode()后多次異或折疊(見說明2) | (length-1) & hashCode | origin*2 | 頭部插入(見說明6) | 淺拷貝 | 2^30 |
| HashMap(1.8) | hash值桶陣列 + 鏈表/紅黑樹(見說明3) | hashCode()高低16位異或 | (length-1) & hashCode | origin*2(見說明7) | 尾部插入 | 淺拷貝 | 2^30 |
| ConcurrentHashMap(1.7) | hash值桶陣列 + Segment extends ReentrantLock(見說明9) + 陣列 | String使用sun.misc.Hashing.stringHash32,其他用hashCode()后多次異或折疊和加法操作(見說明8) | (length-1) & hashCode | origin*2 | 頭部插入 | 不支持 | 2^30 |
| ConcurrentHashMap(1.8) | hash值桶陣列 + 鏈表/紅黑樹(見說明10) | hashCode()高低16位異或 % MAX_INT | (length-1) & hashCode | origin*2 | 尾部插入 | 不支持 | 2^30 |
說明
- HashMap和ConcurrentHashMap的key桶大小都是2的冪,便于將計算下標的取模操作轉化為按位與操作
- Map的key建議使用不可變類如String、Integer等包裝型別,其值是final的,這樣可以防止key的hash發生變化
- 1.8以后,鏈表轉紅黑樹的閾值為8,紅黑樹轉回鏈表的閾值位6,8是鏈表和紅黑樹平均查找時間(n/2和logn)的閾值,不在7轉回是為了防止反復轉換,
- 1.7的HashMap的Entry和1.8中的Node幾乎是一樣的,區別在于:后者的equals()使用了Objects.equals()做了封裝,而不是物件本身的equals(),另外鏈表節點Node和紅黑樹節點TreeNode沒有關系,后者是extends LinkedHashMap的Node,通過紅黑樹查找演算法找value,1.7的ConcurrentHashMap的Node中value、next是用volatile修飾的,但是,1.8的ConcurrentHashMap有TreeNode<K,V> extends Node<K,V>,遍歷查找值時是用Node的next進行的,
- 擴容的依據是k-v容量>=擴容閾值threshold,而threshold= table陣列大小 * 裝載因子,擴容前后hash值沒有變,但是取模(^length)變了,所以在新的table中所在桶的下標可能會變
- HashMap1.7的頭插法在并發場景下reszie()容易導致鏈表回圈,具體的執行場景見文獻[7][9],這一步不太好理解,我個人是用[9]的示意圖自己完整在紙上推演了一遍才理解,關鍵點在于,被中斷的執行緒,對同一個節點遍歷了兩次,雖然1.8改用了尾插法,仍然有回圈參考的可能[10][11],
- 1.8的HashMap在resize()時,要將節點分開,根據擴容后多計算hash的那一位是0還是1來決定放在原來的桶[i]還是桶[i+原始length]中,
- 1.7中計算出hash值后,還會使用它計算所在的Segement
- put(key,value)時鎖定分段鎖,先用非阻塞tryLock()自旋,超過次數上限后升級為阻塞Lock(),
- 1.8的ConcurrentHashMap拋棄了Segement,使用synchronized+CAS(使用tabAt()計算所在桶的下標,實際是用UNSAFE類計算記憶體偏移量)[12]進行寫入,具體來說,當桶[i]為空時,CAS寫值;非空則對桶[i]加鎖[13],
ConcurrentHashMap的死鎖問題
1.7場景
對于跨段操作,如size()、containsValue(),是需要按Segement的下標遞增逐段加鎖、統計,然后按原先順序解鎖的,這樣就有一個很嚴重的隱患:如果執行緒A在跨段操作時,中間的Segement[i]被
執行緒B鎖定,B又要去鎖定Segement[j] (i>j),此時就發生了死鎖,
1.8場景
由于沒有段,也就沒有了跨段,但是size()還是要統計各個桶的數目,仍然有跨桶的可能,如何計算?如果沒有沖突發生,只將 size 的變化寫入 baseCount,一旦發生沖突,就用一個陣列(counterCells)來存盤后續所有 size 的變化[14],
而containsValue()則借助了Traverser(見第2節注5及參考文獻[15]),但是回傳值不是最新的
參考文獻
沒有在文中特殊標注的文章,是參考了其結構或部分內容,進行了重新組織,
- Vector 是執行緒安全的?
- 使用ConcurrentHashMap一定執行緒安全?
- TreeMap原理實作及常用方法
- Java容器常見面試題
- Java高級程式員必備ConcurrentHashMap實作原理:擴容遍歷與計數
- Java容器面試總結
- Java:手把手帶你原始碼分析 HashMap 1.7
- Java原始碼分析:關于 HashMap 1.8 的重大更新 注:本篇的resize()原始碼和我本地JDK8的不一致!
- HashMap底層詳解-003-resize、并發下的安全問題
- JDK8中HashMap依然會死回圈!
- HashMap在jdk1.8中也會死回圈
- ConcurrentHashMap中tabAt方法分析
- HashMap?ConcurrentHashMap?相信看完這篇沒人能難住你!
- ConcurrentHashMap 1.8 計算 size 的方式
- Java集合類框架學習 5.3—— ConcurrentHashMap(JDK1.8)
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/161005.html
標籤:Java