集成學習(ensemble learning)
在機器學習的有監督學習演算法中,我們的目標是學習出一個穩定的且在各個方面表現都較好的模型,但實際情況往往不這么理想,有時我們只能得到多個有偏好的模型(弱監督模型,在某些方面表現的比較好),集成學習就是組合這里的多個弱監督模型以期得到一個更好更全面的強監督模型,集成學習潛在的思想是即便某一個弱分類器得到了錯誤的預測,其他的弱分類器也可以將錯誤糾正回來,單個學習器我們稱為弱學習器,相對的集成學習則是強學習器,
- 弱學習器:常指泛化性能略優于隨機猜測的學習器:例如在二分類問題桑精度略高于50%的分類器,
- 強學習器:通過一定的方式集成一些弱學習器,達到了超過所有弱學習器的準確度的分類器,
集成學習本身不是一個單獨的機器學習演算法,而是通過構建并結合多個機器學習器來完成學習任務,集成學習可以用于分類問題集成,回歸問題集成,特征選取集成,例外點檢測集成等等,可以說所有的機器學習領域都可以看到集成學習的身影,
1. 什么是集成學習?
從下圖,對集成學習的思想做一個概括,對于訓練集資料,通過訓練若干個個體學習器,通過一定的結合策略,來完成學習任務,(常常可以獲得比單一學習顯著優越的學習器)就可以最終形成一個強學習器,
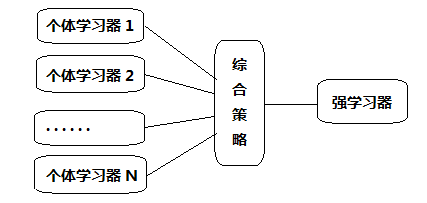
集成學習是一種技術框架,其按照不同的思路來組合基礎模型,從而達到更好的目的,集成學習有兩個主要的問題需要解決,第一是如何得到若干個個體學習器,第二是如何選擇一種結合策略,將這些個體學習器集合成一個強學習器,
2. 如何得到若干個個體學習器?
對于如何得到若干個個體學習器,這里有兩種選擇,
第一種是所有的個體學習器都是一個種類的,或者說是同質的,比如都是決策樹個體學習器,或者都是神經網路個體學習器,比如bagging和boosting系列,
第二種是所有的個體學習器不全是一個種類的,或者說是異質的,比如我們有一個分類問題,對訓練集采用支持向量機個體學習器,邏輯回歸個體學習器和樸素貝葉斯個體學習器來學習,再通過某種結合策略來確定最終的分類強學習器,這種集成學習成為Stacking,
同質個體學習器按照個體學習器之間是否存在依賴關系可以分為兩類,
第一種是個體學習器之間存在強依賴關系,一系列個體學習器基本都需要串行生成,代表演算法是Boosting系列演算法,
第二種是個體學習器之間不存在強依賴關系,一系列個體學習器可以并行生成,代表演算法是Bagging系列演算法,
(1). 集成學習之Bagging
代表演算法:隨機森林(Random Forest)
Bagging(訓練多個分類器取平均):從訓練集從進行子抽樣組成每個基模型所需要的子訓練集,對所有基模型預測的結果進行綜合產生最終的預測結果:
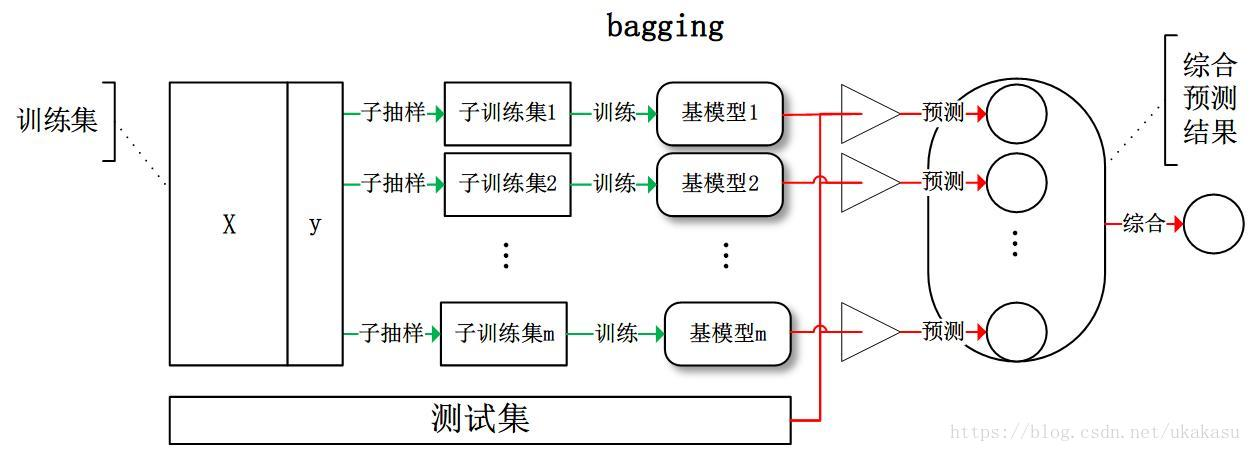
Bagging作業機制:
- 從原始樣本集中抽取訓練集,每輪從原始樣本集中使用Bootstraping的方法抽取n個訓練樣本(在訓練集中,有些樣本可能被多次抽取到,而有些樣本可能一次都沒有被抽中),共進行k輪抽取,得到k個訓練集,(k個訓練集之間是相互獨立的);
- 每次使用一個訓練集得到一個模型,k個訓練集共得到k個模型,(注:這里并沒有具體的分類演算法或回歸方法,我們可以根據具體問題采用不同的分類或回歸方法,如決策樹、感知器等);
- 對分類問題:將上步得到的k個模型采用投票的方式得到分類結果;對回歸問題,計算上述模型的均值作為最后的結果,(所有模型的重要性相同),
Bagging的個體弱學習器的訓練集是通過隨機采樣得到的,通過T次的隨機采樣,我們就可以得到T個采樣集,對于這T個采樣集,我們可以分別獨立的訓練出T個弱學習器,再對這T個弱學習器通過集合策略來得到最終的強學習器,對于這里的隨機采樣,一般采用的是自助采樣法(Bootstrap sampling),即對于m個樣本的原始訓練集,我們每次先隨機采集一個樣本放入采樣集,接著把該樣本放回,也就是說下次采樣時該樣本仍有可能被采集到,這樣采集m次,最終可以得到m個樣本的采樣集,由于是隨機采樣,這樣每次的采樣集是和原始訓練集不同的,和其他采樣集也是不同的,這樣得到多個不同的弱學習器,
隨機森林(很多個決策樹并行放在一起,資料采樣隨機,特征選擇隨機,都是有放回的隨機選取)是bagging的一個特化進階版,所謂的特化是因為隨機森林的弱學習器都是決策樹,所謂的進階是隨機森林在bagging的樣本隨機采樣基礎上,又加上了特征的隨機選擇,其基本思想沒有脫離bagging的范疇,bagging和隨機森林演算法的原理在后面的文章中會專門來講,
(2). 集成學習之Boosting
代表演算法:AdaBoost, Xgboost,GBDT
Boosting(提升演算法,從弱學習器開始加強,通過加權來進行訓練):訓練程序為階梯狀,基模型按次序一一進行訓練(實作上可以做到并行),基模型的訓練集按照某種策略每次都進行一定的轉化,如果某一個資料在這次分錯了,那么在下一次我就會給它更大的權重,對所有基模型預測的結果進行線性綜合產生最終的預測結果:
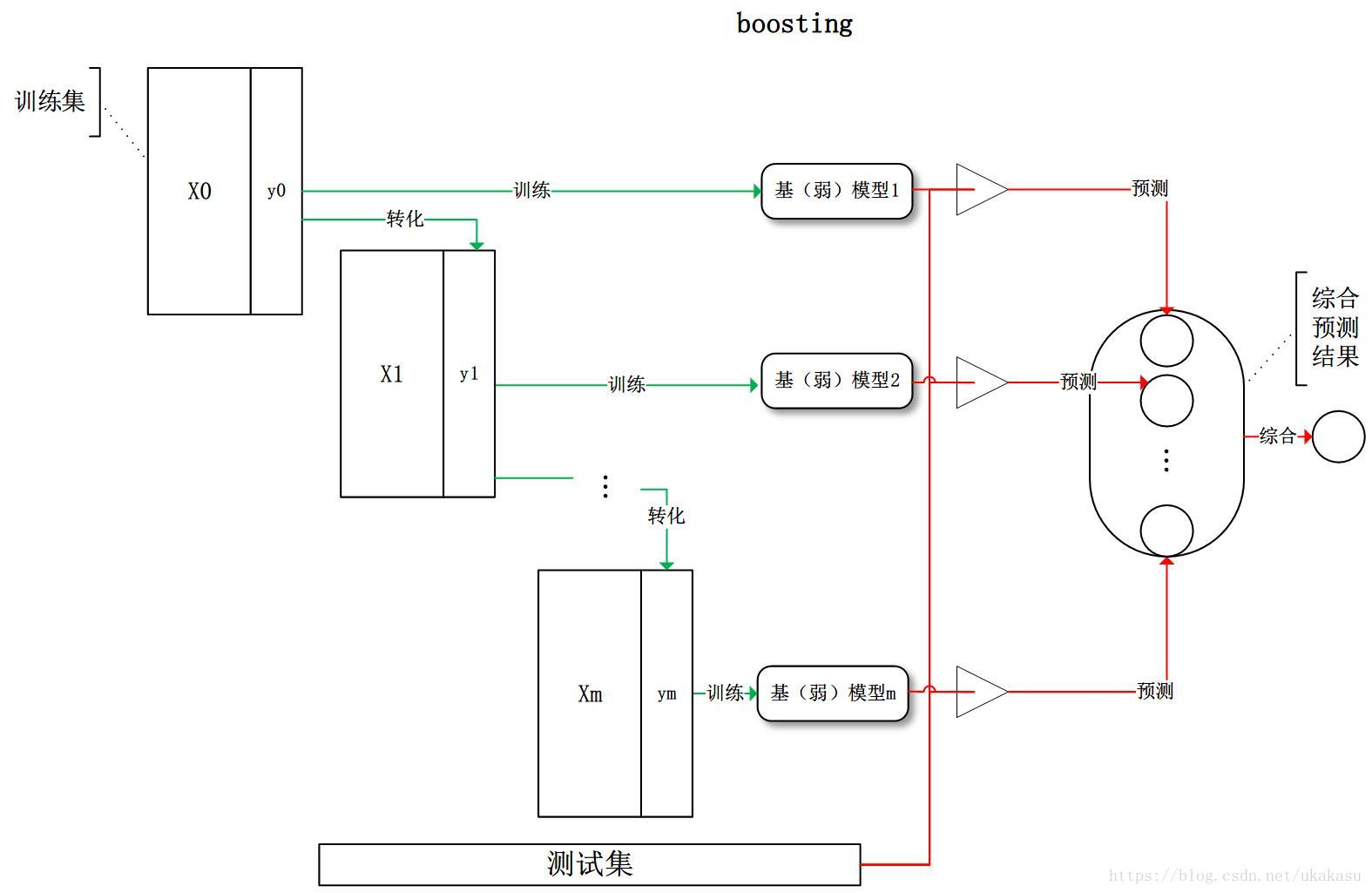
Boosting作業機制:
- 首先從訓練集用初始權重訓練出一個弱學習器1;
- 根據弱學習的學習誤差率表現來更新訓練樣本的權重,使之前弱學習器1學習誤差率高的訓練樣本點的權重變高,即讓誤差率高的點在后面的弱學習器2中得到更多的重視;
- 然后基于調整權重后的訓練集來訓練弱學習器2;
- 如此重復進行,直到弱學習器數達到事先指定的數目T;
- 最終將這T個弱學習器通過集合策略進行整合,得到最終的強學習器,
關于Boosting的兩個核心問題:
1)在每一輪如何改變訓練資料的權值或概率分布?
通過提高那些在前一輪被弱分類器分錯樣例的權值,減小前一輪分對樣例的權值,來使得分類器對誤分的資料有較好的效果,
2)通過什么方式來組合弱分類器?
通過加法模型將弱分類器進行線性組合,比如:AdaBoost(Adaptive boosting)演算法:剛開始訓練時對每一個訓練例賦相等的權重,然后用該演算法對訓練集訓練t輪,每次訓練后,對訓練失敗的訓練例賦以較大的權重,也就是讓學習演算法在每次學習以后更注意學錯的樣本,從而得到多個預測函式,通過擬合殘差的方式逐步減小殘差,將每一步生成的模型疊加得到最終模型,GBDT(Gradient Boost Decision Tree),每一次的計算是為了減少上一次的殘差,GBDT在殘差減少(負梯度)的方向上建立一個新的模型,
(3). 集成學習之Stacking
stacking(堆疊各種各樣的分類器(KNN,SVM,RF等等),分階段操作:第一階段輸入資料特征得出各自結果,第二階段再用前一階段結果訓練得到分類結果,訓練一個模型用于組合其他各個模型): 將訓練好的所有基模型對訓練基進行預測,第j個基模型對第i個訓練樣本的預測值將作為新的訓練集中第i個樣本的第j個特征值,最后基于新的訓練集進行訓練,同理,預測的程序也要先經過所有基模型的預測形成新的測驗集,最后再對測驗集進行預測:
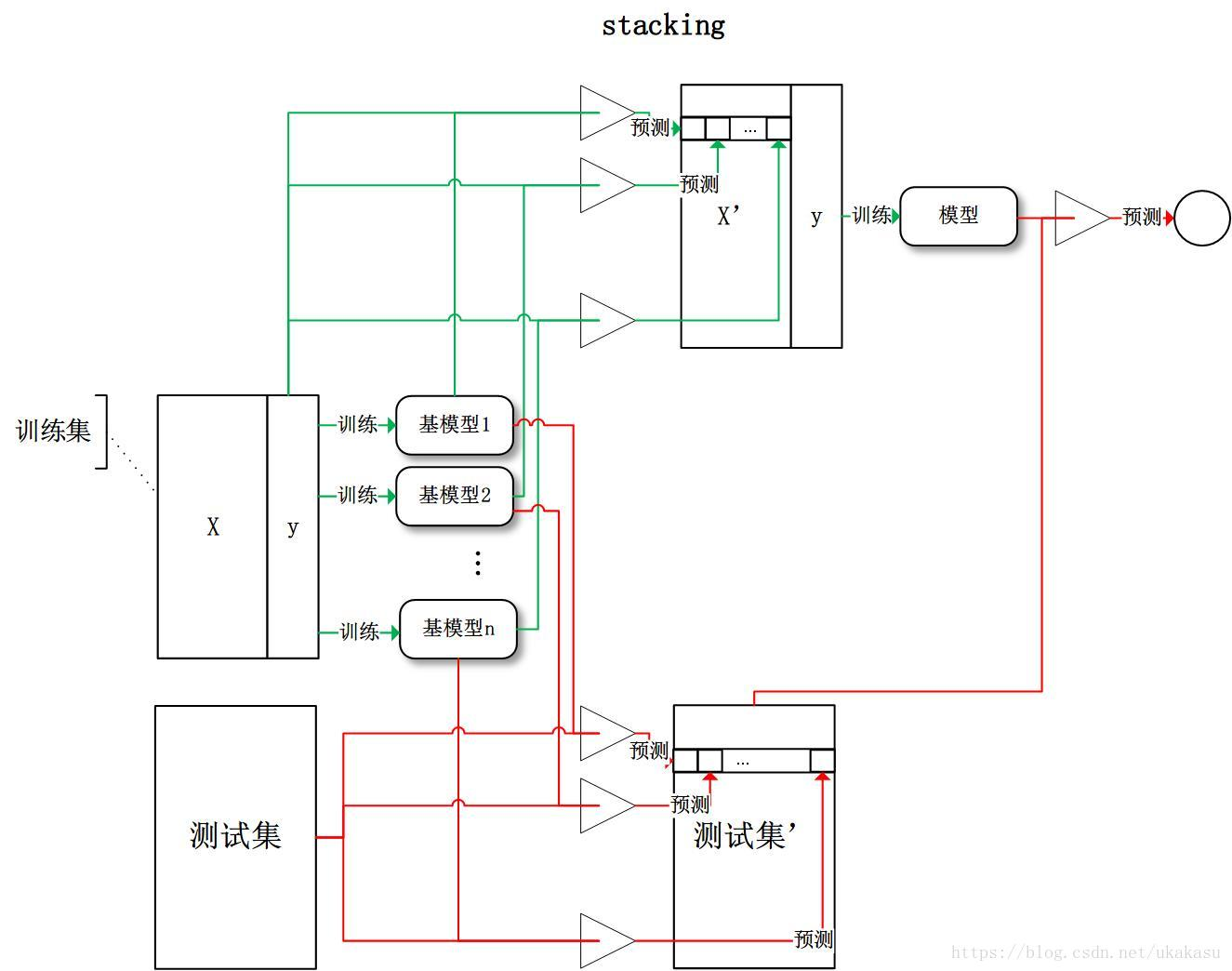
Stacking作業機制:
- 首先先訓練多個不同的模型;
- 然后把之前訓練的各個模型的輸出為輸入來訓練一個模型,以得到一個最終的輸出,
綜上按照個體學習器之間的關系,集成學習一般分為Bagging、Boosting、Stacking三大類(我們可以把它簡單地看成并行,串行和樹型),Bagging是把各個基模型的結果組織起來,取一個折中的結果;Boosting是根據舊模型中的錯誤來訓練新模型,層層改進;Stacking是把基模型組織起來,注意不是組織結果,而是組織基模型本身,該方法看起來更靈活,也更復雜,
3. 如何選擇一種結合策略,將這些個體學習器集合成一個強學習器?假設我們得到的T個弱學習器是$\{h_1,h_2,...h_T\}$
(1). 平均法
對于數值類的回歸預測問題,通常使用的結合策略是平均法,也就是說,對于若干個弱學習器的輸出進行平均得到最終的預測輸出,
最簡單的平均是算術平均,也就是說最終預測是:$H(x) = \frac{1}{T}\sum\limits_{1}^{T}h_i(x)$,
如果每個個體學習器有一個權重$w$,則最終預測是:$H(x) = \sum\limits_{i=1}^{T}w_ih_i(x)$,
其中$w_i$是個體學習器$h_i$的權重,通常有:$w_i \geq 0 ,\;\;\; \sum\limits_{i=1}^{T}w_i = 1$,
(2). 投票法
對于分類問題的預測,我們通常使用的是投票法,假設我們的預測類別是$\{c_1,c_2,...c_K\}$,對于任意一個預測樣本x,我們的T個弱學習器的預測結果分別是$(h_1(x),h_2(x)...h_T(x))$,
最簡單的投票法是相對多數投票法,也就是我們常說的少數服從多數,也就是T個弱學習器的對樣本x的預測結果中,數量最多的類別$c_i$為最終的分類類別,如果不止一個類別獲得最高票,則隨機選擇一個做最終類別,
稍微復雜的投票法是絕對多數投票法,也就是我們常說的要票過半數,在相對多數投票法的基礎上,不光要求獲得最高票,還要求票過半數,否則會拒絕預測,
更加復雜的是加權投票法,和加權平均法一樣,每個弱學習器的分類票數要乘以一個權重,最終將各個類別的加權票數求和,最大的值對應的類別為最終類別,
(3). 學習法
上面兩類方法都是對弱學習器的結果做平均或者投票,相對比較簡單,但是可能學習誤差較大,于是就有了學習法這種方法,對于學習法,代表方法是stacking,當使用stacking的結合策略時, 我們不是對弱學習器的結果做簡單的邏輯處理,而是再加上一層學習器,也就是說,我們將訓練集弱學習器的學習結果作為輸入,將訓練集的輸出作為輸出,重新訓練一個學習器來得到最終結果,在這種情況下,我們將弱學習器稱為初級學習器,將用于結合的學習器稱為次級學習器,對于測驗集,我們首先用初級學習器預測一次,得到次級學習器的輸入樣本,再用次級學習器預測一次,得到最終的預測結果,
4. 總結
集成方法是將幾種機器學習技術組合成一個預測模型的元演算法,以達到減小方差(bagging)、偏差(boosting)或改進預測(stacking)的效果,
集成學習法的特點:
① 將多個分類方法聚集在一起,以提高分類的準確率,(這些演算法可以是不同的演算法,也可以是相同的演算法,)
② 集成學習法由訓練資料構建一組基分類器,然后通過對每個基分類器的預測進行投票來進行分類
③ 嚴格來說,集成學習并不算是一種分類器,而是一種分類器結合的方法,
④ 通常一個集成分類器的分類性能會好于單個分類器
⑤ 如果把單個分類器比作一個決策者的話,集成學習的方法就相當于多個決策者共同進行一項決策,
5. 補充
(1). Bagging,Boosting二者之間的區別
1)樣本選擇上:
Bagging:訓練集是在原始集中有放回選取的,從原始集中選出的各輪訓練集之間是獨立的,
Boosting:每一輪的訓練集不變,只是訓練集中每個樣例在分類器中的權重發生變化,而權值是根據上一輪的分類結果進行調整,
2)樣例權重:
Bagging:使用均勻取樣,每個樣例的權重相等
Boosting:根據錯誤率不斷調整樣例的權值,錯誤率越大則權重越大,
3)預測函式:
Bagging:所有預測函式的權重相等,
Boosting:每個弱分類器都有相應的權重,對于分類誤差小的分類器會有更大的權重,
4)并行計算:
Bagging:各個預測函式可以并行生成
Boosting:各個預測函式只能順序生成,因為后一個模型引數需要前一輪模型的結果,
(2). 決策樹與這些演算法框架進行結合所得到的新的演算法:
1)Bagging + 決策樹 = 隨機森林
2)AdaBoost + 決策樹 = 提升樹
3)Gradient Boosting + 決策樹 = GBDT
參考文章:
https://www.cnblogs.com/zongfa/p/9304353.htmlhttps://www.cnblogs.com/pinard/p/6131423.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/161036.html
標籤:Python