1. multiprocessing像執行緒一樣管理行程
multiprocessing模塊包含一個API,它基于threadingAPI,可以把作業劃分到多個行程,有些情況下,multiprocessing可以作為臨時替換取代threading來利用多個CPU內核,相應地避免Python全域解釋器鎖所帶來的計算瓶頸,
由于multiprocessing與threading模塊的這種相似性,這里的前幾個例子都是從threading例子修改得來,后面會介紹multiprocessing中有但threading未提供的特性,
1.1 multiprocessing基礎
要創建第二個行程,最簡單的方法是用一個目標函式實體化一個Process物件,然后呼叫start()讓它開始作業,
import multiprocessing def worker(): """worker function""" print('Worker') if __name__ == '__main__': jobs = [] for i in range(5): p = multiprocessing.Process(target=worker) jobs.append(p) p.start()
輸出中單詞“Worker”將列印5次,不過取決于具體的執行順序,無法清楚地看出孰先孰后,這是因為每個行程都在競爭訪問輸出流,

大多數情況下,更有用的做法是,在創建一個行程時提供引數來告訴它要做什么,與threading不同,要向一個multiprocessing Process傳遞引數,這個引數必須能夠用pickle串行化,下面這個例子向各個作業行程傳遞一個要列印的數,
import multiprocessing def worker(num): """thread worker function""" print('Worker:', num) if __name__ == '__main__': jobs = [] for i in range(5): p = multiprocessing.Process(target=worker, args=(i,)) jobs.append(p) p.start()
現在整數引數會包含在各個作業行程列印的訊息中,

1.2 可匯入的目標函式
threading與multiprocessing例子之間有一個區別,multiprocessing例子中對main使用了額外的保護,基于啟動新行程的方式,要求子行程能夠匯入包含目標函式的腳本,可以把應用的主要部分包裝在一個__main_檢查中,確保模塊匯入時不會在各個子行程中遞回地運行,另一種方法是從一個單獨的腳本匯入目標函式,
import multiprocessing def worker(): """worker function""" print('Worker') return if __name__ == '__main__': jobs = [] for i in range(5): p = multiprocessing.Process( target=worker, ) jobs.append(p) p.start()
呼叫主程式會生成與第一個例子類似的輸出,

1.3 確定當前行程
通過傳遞引數來標識或命名行程很麻煩,也沒有必要,每個Process實體都有一個名,可以在創建行程時改變它的默認值,對行程命名對于跟蹤行程很有用,特別是如果應用中有多種型別的行程在同時運行,
import multiprocessing import time def worker(): name = multiprocessing.current_process().name print(name, 'Starting') time.sleep(2) print(name, 'Exiting') def my_service(): name = multiprocessing.current_process().name print(name, 'Starting') time.sleep(3) print(name, 'Exiting') if __name__ == '__main__': service = multiprocessing.Process( name='my_service', target=my_service, ) worker_1 = multiprocessing.Process( name='worker 1', target=worker, ) worker_2 = multiprocessing.Process( # default name target=worker, ) worker_1.start() worker_2.start() service.start()
除錯輸出中,每行都包含當前行程的名,行程名列為Process-3的行對應未命名的
行程worker_1,

1.4 守護行程
默認地,在所有子行程退出之前主程式不會退出,有些情況下,可能需要啟動一個后臺行程,它可以一直運行而不阻塞主程式退出,如果一個服務無法用一種容易的方法中斷行程,或者希望行程作業到一半時中止而不損失或破壞資料(例如為一個服務監控工具生成“心跳”的任務),那么對于這些服務,使用守護行程就很有用,
要標志一個行程為守護行程,可以將其daemon屬性設定為True,默認情況下行程不作為守護行程,
import multiprocessing import time import sys def daemon(): p = multiprocessing.current_process() print('Starting:', p.name, p.pid) sys.stdout.flush() time.sleep(2) print('Exiting :', p.name, p.pid) sys.stdout.flush() def non_daemon(): p = multiprocessing.current_process() print('Starting:', p.name, p.pid) sys.stdout.flush() print('Exiting :', p.name, p.pid) sys.stdout.flush() if __name__ == '__main__': d = multiprocessing.Process( name='daemon', target=daemon, ) d.daemon = True n = multiprocessing.Process( name='non-daemon', target=non_daemon, ) n.daemon = False d.start() time.sleep(1) n.start()
輸出中沒有守護行程的“Exiting”訊息,因為在守護行程從其2秒的睡眠時間喚醒之前,所有非守護行程(包括主程式)已經退出,

守護行程會在主程式退出之前自動終止,以避免留下“孤”行程繼續運行,要驗證這一點,可以查找程式運行時列印的行程ID值,然后用一個類似ps的命令檢查該行程,
1.5 等待行程
要等待一共行程完成作業并退出,可以使用join()方法,
import multiprocessing import time def daemon(): name = multiprocessing.current_process().name print('Starting:', name) time.sleep(2) print('Exiting :', name) def non_daemon(): name = multiprocessing.current_process().name print('Starting:', name) print('Exiting :', name) if __name__ == '__main__': d = multiprocessing.Process( name='daemon', target=daemon, ) d.daemon = True n = multiprocessing.Process( name='non-daemon', target=non_daemon, ) n.daemon = False d.start() time.sleep(1) n.start() d.join() n.join()
由于主行程使用join()等待守護行程退出,所以這一次會列印“Exiting”訊息,

默認地,join()會無限阻塞,可以向這個模塊傳入一個超時引數(這是一個浮點數,表示在行程變為不活動之前所等待的秒數),即使行程在這個超時期限內沒有完成,join()也會回傳,
import multiprocessing import time def daemon(): name = multiprocessing.current_process().name print('Starting:', name) time.sleep(2) print('Exiting :', name) def non_daemon(): name = multiprocessing.current_process().name print('Starting:', name) print('Exiting :', name) if __name__ == '__main__': d = multiprocessing.Process( name='daemon', target=daemon, ) d.daemon = True n = multiprocessing.Process( name='non-daemon', target=non_daemon, ) n.daemon = False d.start() n.start() d.join(1) print('d.is_alive()', d.is_alive()) n.join()
由于傳入的超時值小于守護行程睡眠的時間,所以join()回傳之后這個行程仍"活著",

1.6 終止行程
盡管最好使用“毒藥”(poison pill)方法向行程發出信號,告訴它應當退出,但是如果一個行程看起來經掛起或陷入死鎖,那么能夠強制性地將其結束會很有用,對一個行程物件呼叫terminate()會結束子行程,
import multiprocessing import time def slow_worker(): print('Starting worker') time.sleep(0.1) print('Finished worker') if __name__ == '__main__': p = multiprocessing.Process(target=slow_worker) print('BEFORE:', p, p.is_alive()) p.start() print('DURING:', p, p.is_alive()) p.terminate() print('TERMINATED:', p, p.is_alive()) p.join() print('JOINED:', p, p.is_alive())

1.7 行程退出狀態
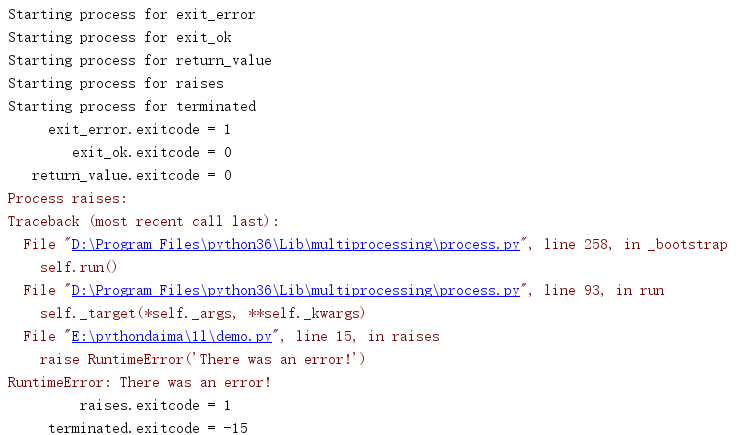
行程退出時生成的狀態碼可以通過exitcode屬性訪問,下表列出了這個屬性的可取值范圍,
| 退出碼 | 含義 |
|---|---|
== 0 |
沒有產生錯誤 |
> 0 |
行程有一個錯誤,并以該錯誤碼退出 |
< 0 |
行程以一個-1 * exitcode |
import multiprocessing import sys import time def exit_error(): sys.exit(1) def exit_ok(): return def return_value(): return 1 def raises(): raise RuntimeError('There was an error!') def terminated(): time.sleep(3) if __name__ == '__main__': jobs = [] funcs = [ exit_error, exit_ok, return_value, raises, terminated, ] for f in funcs: print('Starting process for', f.__name__) j = multiprocessing.Process(target=f, name=f.__name__) jobs.append(j) j.start() jobs[-1].terminate() for j in jobs: j.join() print('{:>15}.exitcode = {}'.format(j.name, j.exitcode))
產生例外的行程會自動得到exitcode為1,
1.8 日志
除錯并發問題時,如果能夠訪問multiprocessing所提供物件的內部狀態,那么這會很有用,可以使用一個方便的模塊級函式啟用日志記錄,名為log_to_stderr(),它使用logging建立一個日志記錄器物件,并增加一個處理器,使日志訊息被發送到標準錯誤通道,
import multiprocessing import logging import sys def worker(): print('Doing some work') sys.stdout.flush() if __name__ == '__main__': multiprocessing.log_to_stderr(logging.DEBUG) p = multiprocessing.Process(target=worker) p.start() p.join()
默認的,日志級別被設定為NOTSET,即不產生任何訊息,通過傳入一個不同的日志級別,可以初始化日志記錄器并指定所需的詳細程度,

若要直接處理日志記錄器(修改其日志級別或增加處理器),可以使用get_logger(),
import multiprocessing import logging import sys def worker(): print('Doing some work') sys.stdout.flush() if __name__ == '__main__': multiprocessing.log_to_stderr() logger = multiprocessing.get_logger() logger.setLevel(logging.INFO) p = multiprocessing.Process(target=worker) p.start() p.join()
使用名multiprocessing,還可以通過logging組態檔API來配置日志記錄器,

1.9 派生行程
要在一個單獨的行程中開始作業,盡管最簡單的方法是使用Process并傳人一個目標函式,但也可以使用一個定制子類,
import multiprocessing class Worker(multiprocessing.Process): def run(self): print('In {}'.format(self.name)) return if __name__ == '__main__': jobs = [] for i in range(5): p = Worker() jobs.append(p) p.start() for j in jobs: j.join()
派生類應當覆寫run()以完成作業,

1.10 向行程傳遞訊息
類似于執行緒,對于多個行程,一種常見的使用模式是將一個作業劃分到多個作業行程中并行地運行,要想有效地使用多個行程,通常要求它們之間有某種通信,這樣才能分解作業,并完成結果的聚集,利用multiprocessing完成行程間通信的一種簡單方法是使用一個Queue來回傳遞訊息,能夠用pickle串行化的任何物件都可以通過Queue傳遞,
import multiprocessing class MyFancyClass: def __init__(self, name): self.name = name def do_something(self): proc_name = multiprocessing.current_process().name print('Doing something fancy in {} for {}!'.format( proc_name, self.name)) def worker(q): obj = q.get() obj.do_something() if __name__ == '__main__': queue = multiprocessing.Queue() p = multiprocessing.Process(target=worker, args=(queue,)) p.start() queue.put(MyFancyClass('Fancy Dan')) # Wait for the worker to finish queue.close() queue.join_thread() p.join()
這個小例子只是向一個作業行程傳遞一個訊息,然后主行程等待這個作業行程完成,
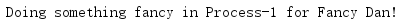
來看一個更復雜的例子,這里展示了如何管理多個作業行程,它們都消費一個JoinableQueue的資料,并把結果傳遞回父行程,這里使用“毒藥”技術來停止作業行程,建立具體任務后,主程式會在作業佇列中為每個作業行程增加一個“stop”值,當一個作業行程遇到這個特定值時,就會退出其處理回圈,主行程使用任務佇列的join()方法等待所有任務都完成后才開始處理結果,
import multiprocessing import time class Consumer(multiprocessing.Process): def __init__(self, task_queue, result_queue): multiprocessing.Process.__init__(self) self.task_queue = task_queue self.result_queue = result_queue def run(self): proc_name = self.name while True: next_task = self.task_queue.get() if next_task is None: # Poison pill means shutdown print('{}: Exiting'.format(proc_name)) self.task_queue.task_done() break print('{}: {}'.format(proc_name, next_task)) answer = next_task() self.task_queue.task_done() self.result_queue.put(answer) class Task: def __init__(self, a, b): self.a = a self.b = b def __call__(self): time.sleep(0.1) # pretend to take time to do the work return '{self.a} * {self.b} = {product}'.format( self=self, product=self.a * self.b) def __str__(self): return '{self.a} * {self.b}'.format(self=self) if __name__ == '__main__': # Establish communication queues tasks = multiprocessing.JoinableQueue() results = multiprocessing.Queue() # Start consumers num_consumers = multiprocessing.cpu_count() * 2 print('Creating {} consumers'.format(num_consumers)) consumers = [ Consumer(tasks, results) for i in range(num_consumers) ] for w in consumers: w.start() # Enqueue jobs num_jobs = 10 for i in range(num_jobs): tasks.put(Task(i, i)) # Add a poison pill for each consumer for i in range(num_consumers): tasks.put(None) # Wait for all of the tasks to finish tasks.join() # Start printing results while num_jobs: result = results.get() print('Result:', result) num_jobs -= 1
盡管作業按順序進入佇列,但它們的執行卻是并行的,所以不能保證它們完成的順序,


1.11 行程間信號傳輸
Event類提供了一種簡單的方法,可以在行程之間傳遞狀態資訊,事件可以在設定狀態和未設定狀態之間切換,通過使用一個可選的超時值,事件物件的用戶可以等待其狀態從未設定變為設定,
import multiprocessing import time def wait_for_event(e): """Wait for the event to be set before doing anything""" print('wait_for_event: starting') e.wait() print('wait_for_event: e.is_set()->', e.is_set()) def wait_for_event_timeout(e, t): """Wait t seconds and then timeout""" print('wait_for_event_timeout: starting') e.wait(t) print('wait_for_event_timeout: e.is_set()->', e.is_set()) if __name__ == '__main__': e = multiprocessing.Event() w1 = multiprocessing.Process( name='block', target=wait_for_event, args=(e,), ) w1.start() w2 = multiprocessing.Process( name='nonblock', target=wait_for_event_timeout, args=(e, 2), ) w2.start() print('main: waiting before calling Event.set()') time.sleep(3) e.set() print('main: event is set')
wait()到時間時就會回傳,而且沒有任何錯誤,呼叫者負責使用is_set()檢查事件的狀態,

1.12 控制資源訪問
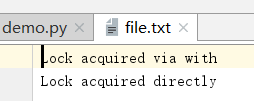
如果需要在多個行程間共享一個資源,那么在這種情況下,可以使用一個Lock來避免訪問沖突,
import multiprocessing def worker_with(lock, f): with lock: fs = open(f, "a+") fs.write('Lock acquired via with\n') fs.close() def worker_no_with(lock, f): lock.acquire() try: fs = open(f, "a+") fs.write('Lock acquired directly\n') fs.close() finally: lock.release() if __name__ == "__main__": f = "file.txt" lock = multiprocessing.Lock() w = multiprocessing.Process(target=worker_with, args=(lock, f)) nw = multiprocessing.Process(target=worker_no_with, args=(lock, f)) w.start() nw.start() w.join() nw.join()
在這個例子中,如果這兩個行程沒有用鎖同步其輸出流訪問,那么列印到控制臺的訊息可能會糾結在一起,
1.13 同步操作
可以用Condition物件來同步一個作業流的各個部分,使其中一些部分并行運行,而另外一些順序運行,即使它們在不同的行程中,
import multiprocessing import time def stage_1(cond): """perform first stage of work, then notify stage_2 to continue """ name = multiprocessing.current_process().name print('Starting', name) with cond: print('{} done and ready for stage 2'.format(name)) cond.notify_all() def stage_2(cond): """wait for the condition telling us stage_1 is done""" name = multiprocessing.current_process().name print('Starting', name) with cond: cond.wait() print('{} running'.format(name)) if __name__ == '__main__': condition = multiprocessing.Condition() s1 = multiprocessing.Process(name='s1', target=stage_1, args=(condition,)) s2_clients = [ multiprocessing.Process( name='stage_2[{}]'.format(i), target=stage_2, args=(condition,), ) for i in range(1, 3) ] for c in s2_clients: c.start() time.sleep(1) s1.start() s1.join() for c in s2_clients: c.join()
在這個例子,兩個行程并行的運行一個作業的第二階段,但前提是第一階段已經完成,

1.14 控制資源的并發訪問
有時可能需要允許多個作業行程同時訪問一個資源,但要限制總數,這時候我們就可以使用Semaphore來管理,
import multiprocessing import time def worker(s, i): s.acquire() print(multiprocessing.current_process().name + " acquire") time.sleep(i) print(multiprocessing.current_process().name + " release") s.release() if __name__ == "__main__": s = multiprocessing.Semaphore(2) for i in range(5): p = multiprocessing.Process(target=worker, args=(s, i * 2)) p.start()

1.15 管理共享狀態
Manager負責協調其所有用戶之間共享的資訊狀態,
import multiprocessing def worker(d, key, value): d[key] = value if __name__ == '__main__': mgr = multiprocessing.Manager() d = mgr.dict() jobs = [ multiprocessing.Process( target=worker, args=(d, i, i * 2), ) for i in range(10) ] for j in jobs: j.start() for j in jobs: j.join() print('Results:', d)
因為這個串列是通過管理器創建的,所以它會由所有行程共享,所有行程都能看到這個串列的更新,除了串列,管理器還支持字典,
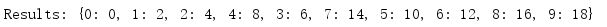
1.16 共享命名空間
除了字典和串列,Manager還可以創建一個共享Namespace,
import multiprocessing def producer(ns, event): ns.value = 'This is the value' event.set() def consumer(ns, event): try: print('Before event: {}'.format(ns.value)) except Exception as err: print('Before event, error:', str(err)) event.wait() print('After event:', ns.value) if __name__ == '__main__': mgr = multiprocessing.Manager() namespace = mgr.Namespace() event = multiprocessing.Event() p = multiprocessing.Process( target=producer, args=(namespace, event), ) c = multiprocessing.Process( target=consumer, args=(namespace, event), ) c.start() p.start() c.join() p.join()
增加到Namespace的所有命名值對所有接收Namespace實體的客戶都可見,
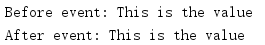
對命名空間中可變值內容的更新不會自動傳播,
import multiprocessing def producer(ns, event): # DOES NOT UPDATE GLOBAL VALUE! ns.my_list.append('This is the value') event.set() def consumer(ns, event): print('Before event:', ns.my_list) event.wait() print('After event :', ns.my_list) if __name__ == '__main__': mgr = multiprocessing.Manager() namespace = mgr.Namespace() namespace.my_list = [] event = multiprocessing.Event() p = multiprocessing.Process( target=producer, args=(namespace, event), ) c = multiprocessing.Process( target=consumer, args=(namespace, event), ) c.start() p.start() c.join() p.join()
要更新這個串列,需要將它再次關聯到命名空間物件,

1.17 行程池
有些情況下,所要完成的作業可以分解并獨立地分布到多個作業行程,對于這種簡單的情況,可以用Pool類來管理固定數目的作業行程,會收集各個作業的回傳值并作為一個串列回傳,池(pool)引數包括行程數以及啟動任務行程時要運行的函式(對每個子行程呼叫一次),
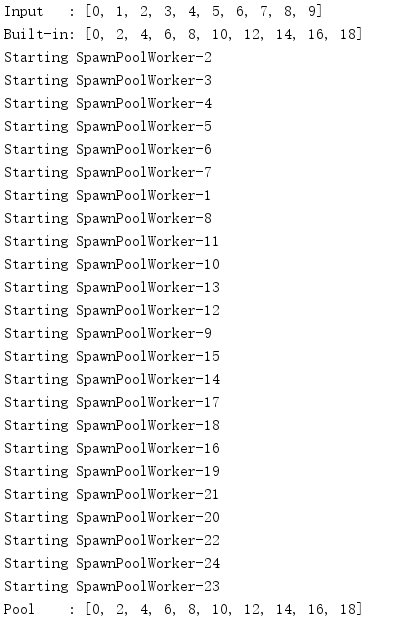
import multiprocessing def do_calculation(data): return data * 2 def start_process(): print('Starting', multiprocessing.current_process().name) if __name__ == '__main__': inputs = list(range(10)) print('Input :', inputs) builtin_outputs = list(map(do_calculation, inputs)) print('Built-in:', builtin_outputs) pool_size = multiprocessing.cpu_count() * 2 pool = multiprocessing.Pool( processes=pool_size, initializer=start_process, ) pool_outputs = pool.map(do_calculation, inputs) pool.close() # no more tasks pool.join() # wrap up current tasks print('Pool :', pool_outputs)
map()方法的結果在功能上等價于內置map()的結果,只不過各個任務會并行運行,由于行程池并行地處理輸入,可以用close()和join()使任務行程與主行程同步,以確保完成適當的清理,
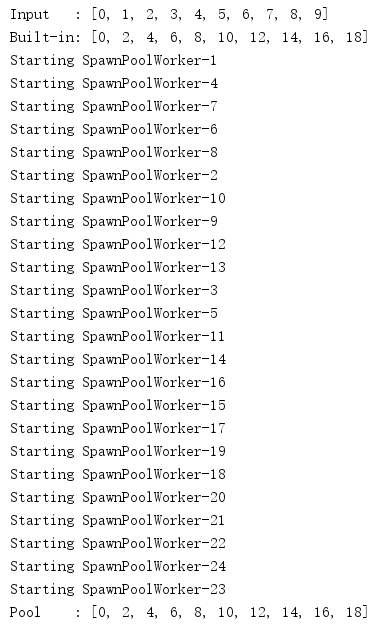
默認的,Pool會創建固定數目的作業行程,并向這些作業行程傳遞作業,直到再沒有更多作業為止,設定maxtasksperchild引數可以告訴池在完成一些任務之后要重新啟動一個作業行程,來避免長時間運行的作業行程消耗更多的系統資源,
import multiprocessing def do_calculation(data): return data * 2 def start_process(): print('Starting', multiprocessing.current_process().name) if __name__ == '__main__': inputs = list(range(10)) print('Input :', inputs) builtin_outputs = list(map(do_calculation, inputs)) print('Built-in:', builtin_outputs) pool_size = multiprocessing.cpu_count() * 2 pool = multiprocessing.Pool( processes=pool_size, initializer=start_process, maxtasksperchild=2, ) pool_outputs = pool.map(do_calculation, inputs) pool.close() # no more tasks pool.join() # wrap up current tasks print('Pool :', pool_outputs)
池完成其分配的任務時,即使并沒有更多作業要做,也會重新啟動作業行程,從下面的輸出可以看到,盡管只有10個任務,而且每個作業行程一次可以完成兩個任務,但是這里創建了8個作業行程,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/162493.html
標籤:Python