1. hmac密碼資訊簽名與驗證
HMAC演算法可以用于驗證資訊的完整性,這些資訊可能在應用之間傳遞,或者存盤在一個可能有安全威脅的地方,基本思想是生成實際資料的一個密碼散列,并提供一個共享的秘密密鑰,然后使用得到的散列檢查所傳輸或存盤的資訊,以確定一個信任級別,而不是傳輸秘密密鑰,
1.1 訊息簽名
new()函式會創建一個新物件來計算訊息簽名,下面這個例子使用了默認的MD5散列演算法,
import hmac digest_maker = hmac.new(b'secret-shared-key-goes-here') with open('lorem.txt', 'rb') as f: while True: block = f.read(1024) if not block: break digest_maker.update(block) digest = digest_maker.hexdigest() print(digest)
運行這段代碼時,會讀取一個資料檔案,并為它計算一個HMAC簽名,
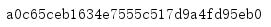
1.2 候選摘要型別
盡管hmac的默認密碼演算法是MD5,但這并不是最安全的方法,MD5散列有一些缺點,如沖突(兩個不同的訊息生成相同的散列),一般認為SHA1演算法更健壯,更建議使用,
import hmac import hashlib digest_maker = hmac.new( b'secret-shared-key-goes-here', b'', hashlib.sha1, ) with open('demo.py', 'rb') as f: while True: block = f.read(1024) if not block: break digest_maker.update(block) digest = digest_maker.hexdigest() print(digest)
new()函式有3個引數,第1個引數是秘密密鑰,這個密鑰會在通信雙方之間共享,使兩端都可以使用相同的值,第2個值是一個初始訊息,如果需要認證的訊息內容很小,如一個時間戳或一個HTTP POST,則把整個訊息體都傳遞到new()而不是使用update()方法,最后一個引數是要使用的摘要模塊,默認為hashlib.md5,不過這個例子傳入了'sha1',其會讓hmac使用hashlib.sha1,
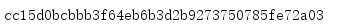
1.3 二進制摘要
前面的例子使用hexdigest()方法來生成可列印的摘要,hexdigest是digest()方法計算的值的一個不同表示,這是一個二進制值,可以包括不可列印的字符(包括NUL),有些Web服務(Google checkout、Amazon S3)會使用base64編碼版本的二進制摘要而不是hexdigest,
import base64 import hmac import hashlib with open('lorem.txt', 'rb') as f: body = f.read() hash = hmac.new( b'secret-shared-key-goes-here', body, hashlib.sha1, ) digest = hash.digest() print(base64.encodebytes(digest))
base64編碼串以一個換行符結束,在HTTP首部或其他格式敏感的背景關系中嵌入這個串時,通常需要去除這個換行符,
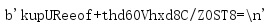
1.4 訊息簽名的應用
對于所有公共網路服務,在安全性要求很高的地方存盤資料,就應當使用HMAC認證,例如,通過一個管道或套接字發送資料時,應當對資料進行簽名,然后在使用這個資料之前要檢查這個簽名,檔案hmac_pickle.py中給出了一個擴展例子,
第一步是建立一個函式,計算一個串的摘要,另外實體化一個簡單的類,并通過一個通信通道傳遞,
import hashlib import hmac import io import pickle import pprint def make_digest(message): "Return a digest for the message." hash = hmac.new( b'secret-shared-key-goes-here', message, hashlib.sha1, ) return hash.hexdigest().encode('utf-8') class SimpleObject: """Demonstrate checking digests before unpickling. """ def __init__(self, name): self.name = name def __str__(self): return self.name
接下來,創建一個ByteIO緩沖區表示這個套接字或管道,這個例子對資料流使用了一種易于決議的原生格式,首先寫出摘要以及資料長度,后面是一個換行符,接下來是物件的串行化表示(由pickle生成),實際的系統可能不希望依賴于一個長度值,畢竟如果摘要不正確,這個長度可能也是錯誤的,更適合的做法是使用真實資料中不太可能出現的某個終止符序列,
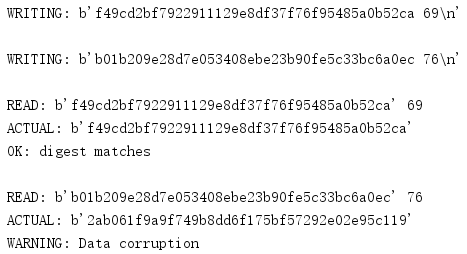
然后示例程式向流寫兩個物件,寫第一個物件時使用了正確的摘要值,
# Simulate a writable socket or pipe with a buffer out_s = io.BytesIO() # Write a valid object to the stream: # digest\nlength\npickle o = SimpleObject('digest matches') pickled_data = pickle.dumps(o) digest = make_digest(pickled_data) header = b'%s %d\n' % (digest, len(pickled_data)) print('WRITING: {}'.format(header)) out_s.write(header) out_s.write(pickled_data)
再用一個不正確的摘要將第二個物件寫入流,這個摘要是為其他資料計算的,而并非由pickle生成,
# Write an invalid object to the stream o = SimpleObject('digest does not match') pickled_data = pickle.dumps(o) digest = make_digest(b'not the pickled data at all') header = b'%s %d\n' % (digest, len(pickled_data)) print('\nWRITING: {}'.format(header)) out_s.write(header) out_s.write(pickled_data) out_s.flush()
既然資料在BytesIO緩沖區中,那么可以將它再次讀出,首先讀取包含摘要和資料長度的資料行,然后使用得到的長度值讀取其余的資料,pickle.load()可以直接從流讀資料,不過這種策略有一個假設,認為它是一個可信的資料流,但這個資料還不能保證足夠可信到可以解除pickled,可以將pickle作為一個串從流讀取,而不是真正將物件解除pickled,這樣會更為安全,
# Simulate a readable socket or pipe with a buffer in_s = io.BytesIO(out_s.getvalue()) # Read the data while True: first_line = in_s.readline() if not first_line: break incoming_digest, incoming_length = first_line.split(b' ') incoming_length = int(incoming_length.decode('utf-8')) print('\nREAD:', incoming_digest, incoming_length)
一旦pickled資料在記憶體中,那么可以重新計算摘要值,并使用compare_digest()與所讀取的資料進行比較,如果摘要匹配,就可以信任這個資料,并對其解除pickled,
incoming_pickled_data =https://www.cnblogs.com/liuhui0308/p/ in_s.read(incoming_length) actual_digest = make_digest(incoming_pickled_data) print('ACTUAL:', actual_digest) if hmac.compare_digest(actual_digest, incoming_digest): obj = pickle.loads(incoming_pickled_data) print('OK:', obj) else: print('WARNING: Data corruption')
輸出顯示第一個物件通過驗證,不出所料,認為第二個物件“已被破壞”,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/162705.html
標籤:Python
上一篇:Python 課程成績分析
下一篇:實體012:100到200的素數