宋紅康老師視頻傳送門ˊ?ˋ
深入理解java虛擬機電子書ˊ?ˋ
提取碼9q24
jvm虛擬機
jvm:跨語言的平臺
jvm位元組碼:我們平時常說的java位元組碼,指的是用java語言編成的位元組碼,準確的說任何能在jvm平臺上執行的位元組碼格式都是一樣的,所以應該統稱為jvm位元組碼
不同的編譯器可以編譯出相同的位元組碼檔案,位元組碼檔案也可以在不同的jvm運行,
Java虛擬機與Java語言并沒有必然的聯系,它只與特定的二進制檔案格式一Class檔案格式所關聯, Class檔案中包含了Java 虛擬機指令集(或者稱為位元組碼、Bytecodes) 和符號表,還有一些其他輔助資訊,
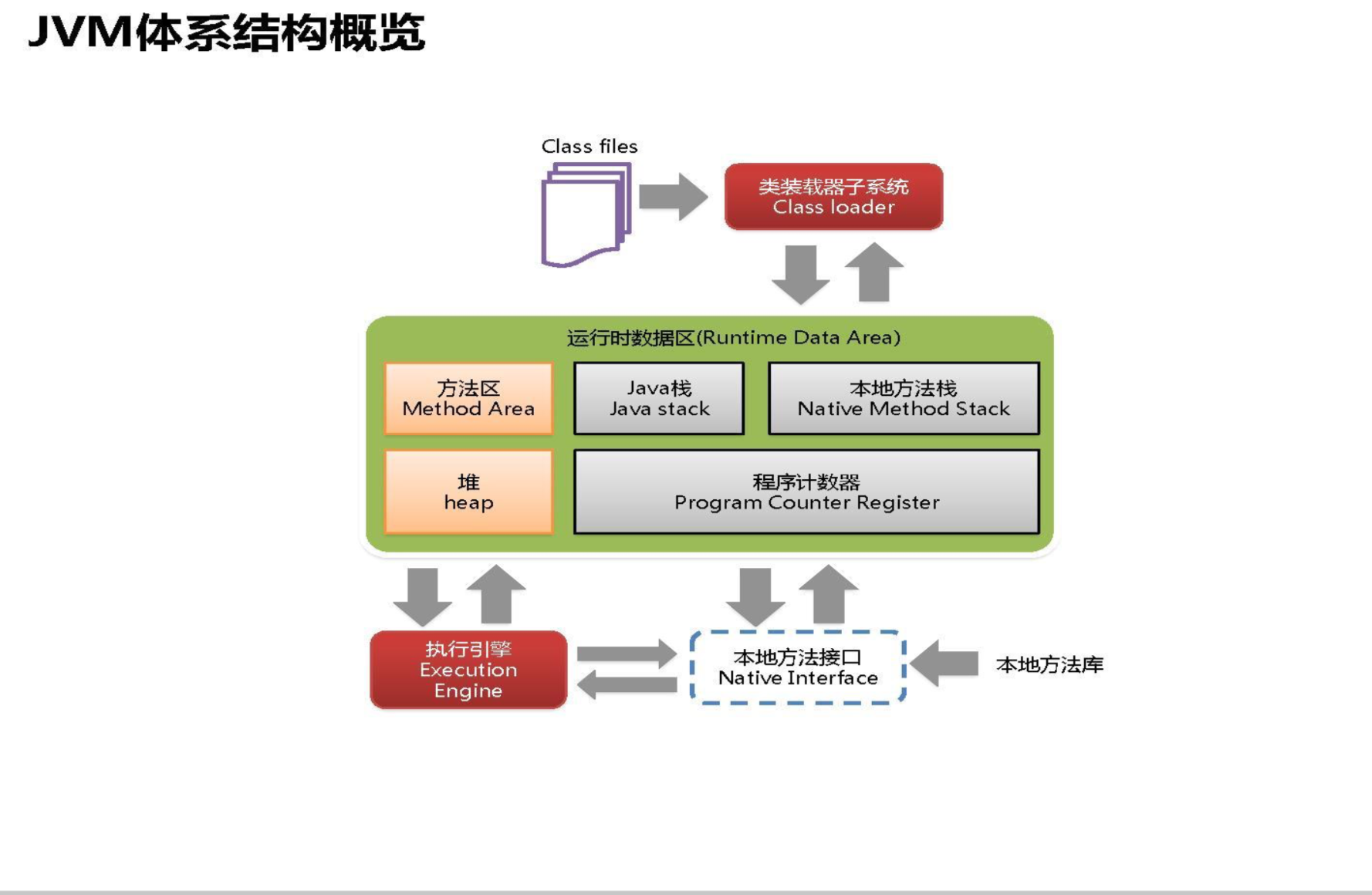
每個行程對應一個jvm虛擬機實體,一個jvm實體就有一個運行時資料區(Runtime Data Area)
jvm的架構模型
java編譯器輸入的指令流基本是一種基于堆疊的指令集架構,另外一種指令集架構則是基于暫存器的指令集架構
基于堆疊式架構的特點(更少的指令集,更多的指令)
設計和實作更簡單,適用于資源受限的系統
避開了暫存器的分配難題,使用零地址指令方式分配
指令流中的指令大部分是零地址指令,其執行程序依賴于操作堆疊,指令集更小,編譯器更容易實作
不需要硬體支持,可移植性更好,更好實作跨平臺
基于暫存器架構的特點(更少的指令,更多的指令集)
典型的應用是X86的二進制指令集,比如傳統的pc以及Anroid的Davlik虛擬機
指令集架構則完全依賴硬體,可移植性差
性能優秀和執行更高效
花費更少的指令去完成一些操作
在大部分情況下,基于暫存器的指令集往往都以一地址指令、二地址指令和三地址指令為主,而基于堆疊式架構的指令集確是以零地址指令為主
jvm的生命周期
java虛擬機的啟動是通過引導類加載器創建引導類加載器創建一個初始類來完成的,這個類是由虛擬機的具體實作指定的
虛擬機的執行
一個運行中的java虛擬機有一個清晰的任務:執行java程式,
程式開始時虛擬機運行,程式結束時他就停止,
執行一個所謂的java程式的時候,真真正正在執行的是一個叫做java虛擬機的行程,
虛擬機的退出
有如下的幾種情況:
程式正常執行結束
程式在執行程序中遇到了例外或錯誤而例外終止
由于作業系統出現錯誤而導致Java虛擬機行程終止:
某執行緒呼叫Runtime類或system類的exit方法,或Runt ime類的halt方法,并且Javll安全管理器也允許這次exit或halt操作,
除此之外,JNI ( Java Native Interface )規范描述了用JNI Invocation API來 加載或卸載Java虛 擬機時,Java虛擬機的退出情況,
Sun Classic VM
- sun公司發布的第一款商用java虛擬機,于jdk1.4被淘汰
- 這款虛擬機只提供解釋器,
- 如果使用JIT編譯器,就需要進行外掛,但是一旦使用了JIT編譯器,JIT就會接管虛擬機的執行系統,解釋器就不再作業,解釋器和編譯器不能配合作業
- 現在hotspot內置了此虛擬機
*理解執行引擎
翻譯機:
解釋器:逐行解釋代碼,回應速度快,執行速度慢,
JIT:尋找熱點代碼,全部編譯,回應速度慢,執行速度快,
類加載子系統
類加載器子系統負責從檔案系統或者網路中加載Class檔案,class檔案開頭有特定的檔案標識(CAFEBABY)
ClassLoader只負責class檔案的加載,至于它是否可以運行,則由ExecutionEngine(執行引擎)決定
加載的類資訊存放于一塊稱為方法區的記憶體空間,除了類的資訊外,方法區中還會存放運行時常量池資訊(當常量池開始運行時就被稱為運行時常量池),可能還包括字串字面量和數字常量(這部分常量資訊是Class檔案中常量池部分的記憶體映射)
類的加載程序
1.通過一個類的全限定名獲取定義此類的二進制位元組流
2.將這個位元組流所代表的靜態存盤結構轉化為方法區的運行時資料結構
3.在記憶體中生成一個代表這個類的java. lang.Class物件,作為方法區這個類的各種資料的訪問入口
加載. class檔案的方式
從本地系統中直接加載
通過網路獲取,典型場景: Web Applet
從zip壓縮包中讀取,成為日后jar、war格式的基礎
運行時計算生成,使用最多的是:動態代理技術
由其他檔案生成,典型場景: JSP應用
從專有資料庫中提取. class檔案,比較少見
從加密檔案中獲取,典型的防Class檔案被反編譯的保護措施
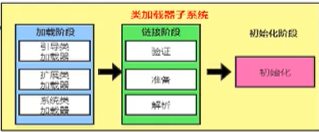
鏈接(link)
驗證(Verify ) :
●目的在于確保class檔案的位元組流中包含資訊符合當前虛擬機要求,保證被加載類的正確性,不會危害虛擬機自身安全,
主要包括四種驗證,檔案格式驗證,元資料驗證,位元組碼驗證,符號參考驗證,準備(Prepare) :
為類變數分配記憶體并且設定該類變數的默認初始值,即零值,
● 這里不包含用final修飾的static, 因為final在編譯的時候就會分配了,準備階段會顯式初始化;這里不會為實體變數分配初始化,類變數會分配在方法區中,而實體變數是會隨著物件一起分配到Java堆中,決議(Resolve) :
●將常量池內的符號參考轉換為直接參考的程序,
事實上,決議操作往往會伴隨著JVM在執行完初始化之后再執行,
符號參考就是一組符號來描述所參考的目標,符號參考的字面量形式明確定義在《java 虛擬機規范》的Class檔案格式中,直接參考就是直接指向目標的指標、相對偏移量或一個間接定位到目標的句柄,
決議動作主要針對類或介面、欄位、類方法、介面方法、方法型別等,對應常量池中的CONSTANT_ Class_ info、 CONSTANT_ Fieldref_ info、CONSTANT_ Methodref_ info等
初始化(initialization)
將代碼中的靜態代碼塊和顯示初始化合并在一起,構成
初始化階段就是執行類構造器方法
此方法不需要定義,是javac編譯器自動收集類中的所有類變數的賦值動作和靜態代碼塊中的陳述句合并而來,
構造器方法中指令按陳述句在源檔案中出現的順序執行,
若該類具有父類,jvm會保證子類的
()執行前,父類的 ()已經執行完畢, 虛擬機必須保證一個類的
()方法在多執行緒下被同步加鎖
public static void main(String args[]){
private static int b = 1;
static{
b = 2;
num = 20;
}
private static int num = 10;//在linking中:num默認初始化零值,之后在initialization中初始化為20,然后覆寫為10
}
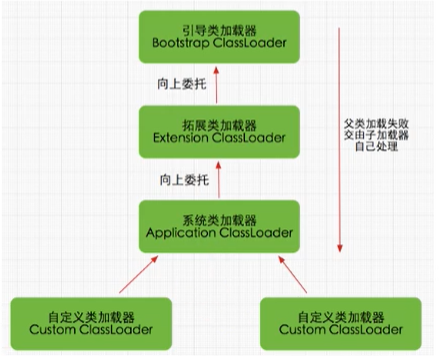
類加載器的分類
分為兩類:引導類加載器和自定義類加載器,直接或間接繼承Class Loader的類加載器都是自定義加載器(java虛擬機規范)
引導類:Bootstrap Class Loader(使用c/c++語言撰寫,只負責加載java的核心類別庫,如String)
自定義類(使用java語言撰寫):Extension Class Loader(擴展類加載器)、System Class Loader(系統類加載器)........
啟動類加載器(引導類加載器,Bootstrap ClassLoader)
這個類加載使用C/C++語言實作的,嵌套在JVM內部,
它用來加載Java的核心庫(JAVA_ HOME/jre/ lib/rt. jar、resources . jar或sun . boot .class. path路徑下的內容) ,用于提供JVM自身需要的類,
并不繼承自java. lang. ClassLoader,沒有父加載器,
加載擴展類和應用程式類加載器,并指定為他們的父類加載器,出于安全考慮、Bootstrap啟動類 加載器只加載包名為java、javax、sun等開頭的類,
擴展類加載器(Extension ClassLoader )
Java語言撰寫,由sun . mi sc. Launcher$ExtClassLoader實作,
派生于ClassLoader類,
父類加載器為啟動類加載器,
從java. ext. dirs系統屬性所指定的目錄中加載類別庫,或從JDK的安裝目錄的jre/lib/ext子目錄(擴展目錄)下加載類別庫,如果用戶創建的JAR放在此目錄下,也會自動由擴展類加載器加載,
應用程式類加載器(系統類加載器,AppClassLoader )
java語言撰寫,由sun . mi sc . Launcher$AppClassLoader實作,
派生于ClassLoader類,
父類加載器為擴展類加載器,
它負責加載環境變數classpath或系統屬性java. class.path指定路徑下的類別庫,
該類加載是程式中默認的類加載器,一- 般來說,Java應用的類都是由它來完成加載,
通過ClassLoader#getSystemClassLoader()方法可以獲取到該類加載器,
用戶自定義類加載器
在Java的日常應用程式開發中,類的加載幾乎是由,上述3種類加載器相互配合執行的,在必要時,我們還可以自定義類加載器,來定制類的加載方式,
為什么要自定義類加載器?
隔離加載類,
修改類加載的方式,
擴展加載源,
防止原始碼泄漏,
用戶自定義類加載器實作步驟:
1.開發人員可以通過繼承抽象類java. lang. ClassLoader類的方式,實作自己的類加載器,以滿足一些特殊的需求,
2.在JDK1.2之前,在自定義類加載器時,總會去繼承ClassLoader類并重寫loadClass ()方法,從而實作自定義的類加載類,但是在JDK1.2之后已不再建議用戶去覆寫loadClass()方法,而是建議把自定義的類加載邏輯寫在findClass()方法中,
3.在撰寫自定義類加載器時,如果沒有太過于復雜的需求,可以直接繼承URLClassLoader類,這樣就可以避免自己去撰寫findClass()方法及其獲取位元組碼流的方式,使自定義類加載器撰寫更加簡潔,
其他要點
1.在JVM中表示兩個class物件是否為同一個類存在兩個必要條件:
類的完整類名必須一致,包括包名,
加載這個類的ClassLoader (指ClassLoader實體物件)必須相同,.
即使兩個類物件來源于同一個Class檔案,被同一個虛擬機所加載,但只要它們的ClassLoader不同,那這兩個類物件也是不一樣的
2.JVM必須知道-一個型別是由啟動加載器加載的還是由用戶類加載器加載的,如果一個型別是由用戶類加載器加載的,那么JVM會將這個類加載器的一個參考作為型別資訊的一部分保存在方法區中,當決議一個型別到另一個型別的參考的時候,JVM需要保證這兩個型別的類加載器是相同的,
雙親委派機制
Java,虛擬機對class檔案采用的是按需加載的方式,也就是說當需要使用該類時才會將它的class檔案加載到記憶體生成class物件,而且加載某個類的class檔案時,Java虛擬機采用的是雙親委派模式,即把請求交由父類處理,它是一種任務委派模式,
作業原理
1)如果一個類加載器收到了類加載請求,它并不會自己先去加載,而是把這個請求委托給父類的加載器去執行;
2)如果父類加載器還存在其父類加.載器,則進一步向上委托,依次遞回,請求最終將到達項層的啟動類加載器;
3)如果父類加載器可以完成類加載任務,就成功回傳,倘若父類加載器無法完成此加載任務,子加載器才會嘗試自己去加載,這就是雙親委派模式,
優勢:
避免類的重復加載
保護程式安全,防止核心API被隨意篡改
沙箱安全機制
自定義String類,但是在加載自定義String類的時候會率先使用引導類加載器加載,而引導類加載器在加載的程序中會先加載jdk自帶的檔案(rt.jar包中java \lang\String.class),報錯資訊說沒有main方法,就是因為加載的是rt. jar包中的String類,這樣可以保證對java核心源代碼的保護,這就是沙箱安全機制,
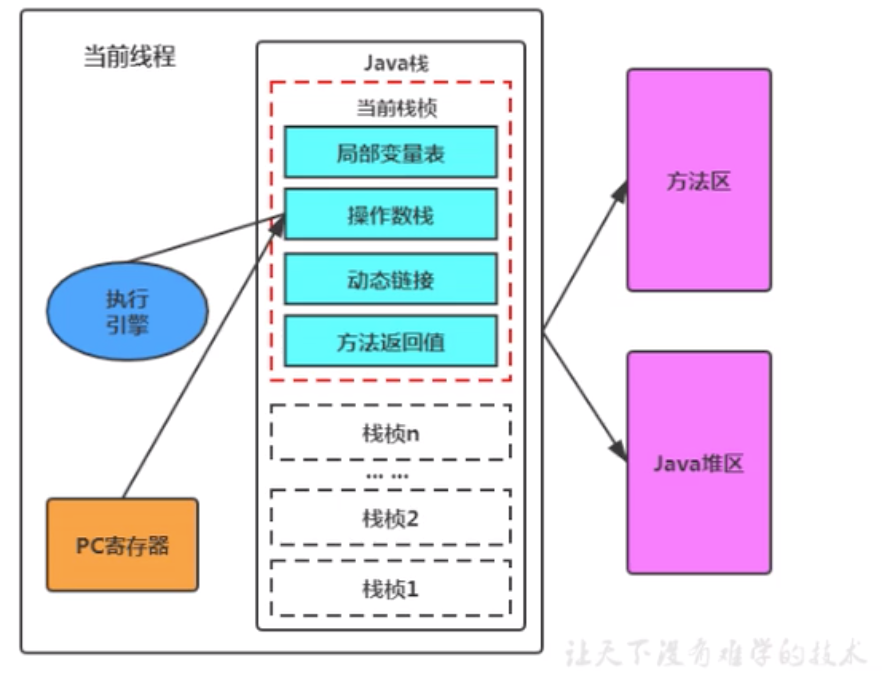
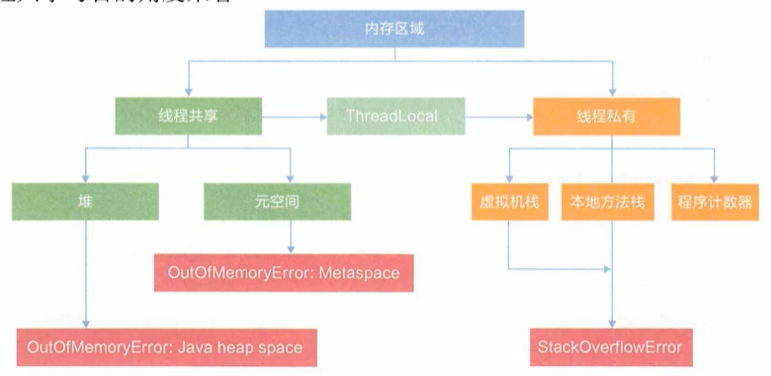
運行時資料區間內部結構
Java虛擬機定義了若千種程式運行期間會使用到的運行時資料區,其中有一些會隨著虛擬機啟動而創建,隨著虛擬機退出而銷毀,另外一些則是與執行緒一 一對應的,這些與執行緒對應的資料區域會隨著執行緒開始和結束而創建和銷毀,
一個運行時資料區間對應一個Runtime Class(可以通過getRuntime()獲取到),所以Runtime Class是單例的,(詳見javaSE api)
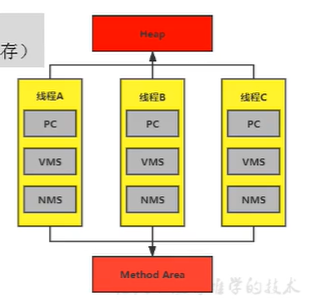
灰色的為單獨執行緒私有的,紅色的為多個執行緒共享的,即:
每個執行緒:獨立包括程式計數器、堆疊、本地堆疊,
執行緒間共享:堆、堆外記憶體(永久代或元空間、代碼快取)

(暫存器/程式計數器)Regist介紹
作用:
PC暫存器用來存盤指向下一條指令的地址,也即將要執行的指令代碼,由執行引擎讀取下一條指令,
任何時間一一個執行緒都只有一個方法在執行,也就是所謂的當前方法,程式計數器會存盤當前執行緒正在執行的Java方法的JVM指令地址,或者,如果是在執行native方法,則是未指定值(undefined) ,

常見問題
使用PC暫存器存盤位元組碼指令地址有什么用呢?
為什么使用PC暫存器記錄當前執行緒的執行地址呢?
因為CPU需要不停的切換各個執行緒,這時候切換回來以后,就得知道接著從哪開始繼續執行,
JVM的位元組碼解釋器就需要通過改變PC暫存器的值來明確下一條應該執行什么樣的位元組碼指令,
PC暫存器為什么會被設定為執行緒私有?
? 我們都知道所謂的多執行緒在一個特定的時間段內只會執行其中某一個執行緒的方法,CPU會不停地做任務切換,這樣必然導致經常中斷或恢復,如何保證分毫無差呢?為了能夠準確地記錄各個執行緒正在執行的當前位元組碼指令地址,最好的辦法自然是為每一個執行緒都分配一個PC暫存器,這樣一來各個執行緒之間便可以進行獨立計算,從而不會出現相互干擾的情況,由于CPU時間片輪限制,眾多執行緒在并發執行程序中,任何一個確定的時刻,一個處理器或者多核處理器中的一個內核,只會執行某個執行緒中的一條指令,這樣必然導致經常中斷或恢復,如何保證分毫無差呢?每個執行緒在創建后,都會產生自己的程式計數器和堆疊幀,程式計數器在各個執行緒之間互不影響,
虛擬機堆疊
Java虛擬機堆疊是什么?
Java虛擬機堆疊(Java Virtual Machine Stack) ,早期也叫Java堆疊,每個執行緒在創建時都會創建一個虛擬機堆疊,其內部保存一個個的堆疊幀(Stack Frame) ,對應著一次次的Java方法呼叫,
是執行緒私有的
生命周期:生命周期和執行緒一致,
作用
主管Java程式的運行,它保存方法的區域變數(8種基本資料型別、物件的參考地址)、部分結果,并參與方法的呼叫和回傳,
區域變數VS成員變數(或屬性)
基本資料變數VS參考型別變數(類、陣列、介面)
可能出現的例外
在這個記憶體區域中,如果執行緒請求的堆疊幀深度大于虛擬機所允許的深度,將拋出StarkOverflowError例外;如果java虛擬機堆疊容量可以動態擴展,當堆疊擴展是無法申請到足夠的記憶體時會拋出OutOfMemoryError例外,
設定堆疊記憶體大小
可以使用引數-Xss選徐來設定執行緒最大堆疊空間,堆疊的大小直接決定了函式呼叫的最大可達深度,
private int count = 0;
public static void main(String args[]){
count++;
main(rgs[]);
}
//最后報出StarkOverflowError
堆疊的存盤單位
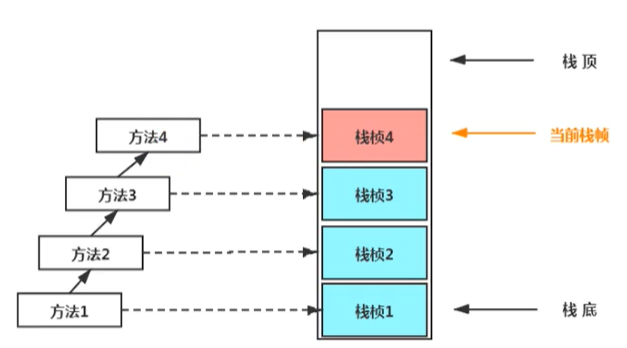
每個執行緒都有自己的堆疊,堆疊中的資料都是以堆疊楨(stack Frame)的格式存在,
在這個執行緒上正在執行的每個方法都各自對應一個堆疊楨(Stack Frame)
堆疊幀是一個記憶體區塊,是一個資料集,維系著方法執行程序中的各種資料資訊,
堆疊運行原理
JVM直接對Java堆疊的操作只有兩個,就是對堆疊幀的壓堆疊和出堆疊,遵循“先進后出”/“后進先出”原則,
在一潭訓動執行緒中,一個時間點上,只會有一個活動的堆疊幀,即只有當前正在執行的方法的堆疊幀(堆疊頂堆疊幀)是有效的,這個堆疊幀被稱為當前堆疊幀(Current Frame) ,與當前堆疊幀相對應的方法就是當前方法(Current Method),定義這個方法的類就是當前類(Current Class),
執行引擎運行的所有位元組碼指令只針對當前堆疊幀進行操作,
如果在該方法中呼叫了其他方法,對應的新的堆疊幀會被創建出來,放在堆疊的頂端,成為新的當前幀,
不同執行緒中所包含的堆疊幀是不允許存在相互參考的,即不可能在一個堆疊幀之中參考另外一個執行緒的堆疊幀,
如果當前方法呼叫 了其他方法,方法回傳之際,當前堆疊幀會傳回此方法的執行結果給前一個堆疊幀,接著,虛擬機會丟棄當前堆疊幀,使得前一個堆疊幀重新成為當前堆疊幀,
Java方法有 兩種回傳函式的方式,一種是正常的函式回傳,使用return指令; 另外一種是拋出例外,不管使用哪種方式,都會導致堆疊幀被彈出,
堆疊楨的內部結構
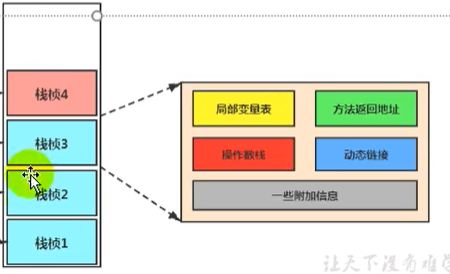
幀資料區
就是指堆疊幀中的方法回傳地址、動態鏈接和附加資訊
每個堆疊楨中存盤著:
區域變數表(Local Variables)
運算元堆疊(operand stack) (或表達 式堆疊)
動態鏈接(Dynamic Linking) ( 或指向運行時常量池的方法參考)
方法回傳地址(Return Address) ( 或方法正常退出或者例外退出的定義)
一些附加資訊
區域變數表(Local Variables)
關于jclasslib操作在視頻的p49
其大小在Class反編譯檔案中以locals查看,在jclasslib中的misc下
區域變數表也被稱之為區域變數陣列或本地變數表,
定義為一個數字陣列,主要用于存盤方法引數和定義在方法體內的區域變數,這些資料型別包括各類基本資料型別、物件參考(reference) ,以及,returnAddress型別,
由于區域變數表是建立在執行緒的堆疊上,是執行緒的私有資料,因此不存在資料安全問題,
區域變數表所需的容量大小是在編譯期確定下來的,并保存在方法的Code屬性的maximum local variables資料項中,在方法運行期間是不會改變區域變數表的大小的,.
方法嵌套呼叫的次數由堆疊的大小決定,一般來說,堆疊越大,方法嵌套呼叫次數越多,對一個函式而言,它的引數和區域變數越多,使得區域變數表膨脹,它的堆疊幀就越大,以滿足方法呼叫所需傳遞的資訊增大的需求,進而函式呼叫就會占用更多的堆疊空間,導致其嵌套呼叫次數就會減少,
區域變數表中的變數只在當前方法呼叫中有效,在方法執行時,虛擬機通過使用區域變數表完成引數值到引數變數串列的傳遞程序,當方法呼叫結束后,隨著方法堆疊幀的銷毀,區域變數表也會隨之銷毀,
Slot(槽)
引數值的存放總是在區域變數陣列的index0開始,到陣列長度-1的索引結束,
區域變數表,最基本的存盤單元是Slot (變數槽)
區域變數表中存放編譯期可知的各種基本資料型別(8種),參考型別(reference),returnAddress型別的變數,
在區域變數表里,32位以內的型別只占用一個slot (包括returnAddress型別),64位的型別(long和double)占用兩個slot,
byte、short、char在存盤前被轉換為int,boolean 也被轉換為int,0表示false,非0表示true,
long和double則占據兩個Slot,
堆疊幀中的區域變數表中的槽位是可以重用的,如果一個區域變數過了其做用域,那么在其作用域之后申明的新的區域變數就很有可能會復用過期局變數的槽位,從而達到節省資源的目的,
靜態變數與區域變數
引數表分配完畢之后,再根據方法體內定義的變數的順序和作用域分配,我們知道類變數表有兩次初始化的機會,第一次是在“準備階段”,執行系統初始化,對類變數設定零值,另一次則是在“初始化”階段,賦予程式員在代碼中定義的初始值,
和類變數初始化不同的是,區域變數表不存在系統初始化的程序,這意味著一旦定義了區域變數則必須人為的初始化,否則無法使用,
ps:變數的分類:
按照資料型別分:基本資料型別 & 參考資料型別
按照類中宣告的位置分:
成員變數
在使用前,都經歷過默認初始化賦值
有static修飾:類變數-->在linking的prepare階段給其默認賦值,在init階段顯示賦值
無static修飾:實體變數-->在物件創建時會在堆中分配記憶體,進行默認賦值
區域變數
在使用時必須進行顯示賦值,否則編譯不通過
如:
public static void mian(String args[]){
int i;
System.out.println(i);//變數i未初始化
}
其他
在堆疊幀中,與性能調優關系最為密切的部分就是前面提到的區域變數表,在方法執行時,虛擬機使用區域變數表完成方法的傳遞,
區域變數表中的變數也是重要的垃圾回收根節點,只要被區域變數表中直接或間接參考的物件都不會被回收,
運算元堆疊(Operand Stack)
運算元堆疊,主要用于保存計算程序的中間結果,同時作為計算程序中變數臨時的存盤空間,
運算元堆疊就是JVM執行引擎的一個 作業區,當一個方法剛開始執行的候,一個新的堆疊幀也會隨之被創建出來,這個方法的運算元堆疊是空的,
每一個運算元堆疊都會擁有一個明確的堆疊深度用于存盤數值,其所需的最大深度在編譯期就定義好了,保存在方法的Code屬性中,為max_ stack的值,
堆疊中的任何一個元素都是可以任意的Java資料型別,
32bit的型別占用一個堆疊單位深度
64bit的型別占用兩個堆疊單位深度運算元堆疊并非采用訪問索引的方式來進行資料訪問的,而是只能通過標準的入堆疊(push) 和出堆疊(pop) 操作來完成一次資料訪問,
如果被呼叫的方法帶有回傳值的話,其回傳值將會被壓入當前堆疊幀的運算元堆疊中,并更新PC暫存器中下一條需要執行的位元組碼指令,
運算元堆疊中元素的資料型別必須與位元組碼指令的序列嚴格匹配,這由編譯器在編譯器期間進行驗證,同時在類加載程序中的類檢驗階段的資料流分析階段要再次驗證,
另外,我們說Java虛擬機的解釋引擎是基于堆疊的執行引擎,其中的堆疊指的就是運算元堆疊,
Public static void main(String args[]){
int i = 1;
int j = 2;
int l = i+j;
System.out.println(l);
}
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=4, args_size=1 //stack即為運算元堆疊深度,如果此方法未用靜態修飾,則區域變數表長度為5,索引0是this,在此方法中,由于是main方法,所以索引0是args
0: iconst_1//int i-->初始化int型別常量,壓入運算元堆疊中<--堆疊頂(深度1)
1: istore_1//出堆疊,存入區域變數表,索引位置為1
2: iconst_2//itn j-->初始化int型別常量,壓入運算元堆疊中<--堆疊頂(深度1)
3: istore_2//出堆疊,存入區域變數表,索引位置為2
4: iload_1//獲得區域變數表中索引為1的值,壓入運算元堆疊中(深度1)
5: iload_2//獲得區域變數表中索引為2的值,壓入運算元堆疊中(深度2)
6: iadd //取出運算元堆疊中的值,交由執行引擎執行求和操作,其求和的值再次壓入運算元堆疊中
7: istore_3//出堆疊,將其存入區域變數表中索引為3的位置
8: getstatic #16 // Field java/lang/System.out:Ljava/io/PrintStream;
11: iload_3//獲得區域變數表中索引為3的值,壓入運算元堆疊中,執行輸出操作
12: invokevirtual #22 // Method java/io/PrintStream.println:(I)V
15: return
堆疊頂快取技術(Top-Of-Stack-Cashing)
前面提過,基于堆疊式架構的虛擬機所使用的零地址指令更加緊湊,但完成一項操作的時候必然需要使用更多的入堆疊和出堆疊指令,這同時也就意味著將需要更多的指令分派(instruction dispatch) 次數和記憶體讀/寫次數,
由于運算元是存盤在記憶體中的,因此頻繁地執行記憶體讀/寫操作必然會影響執行速度,為了解決這個問題,Hotspot JVM的設計者們提出了堆疊頂快取(ToS,Top-of-Stack Cashing) 技術,將堆疊頂元索全部快取在物理CPU的暫存器中,以此降低對記憶體的讀/寫次數,提升執行引擎的執行效率,
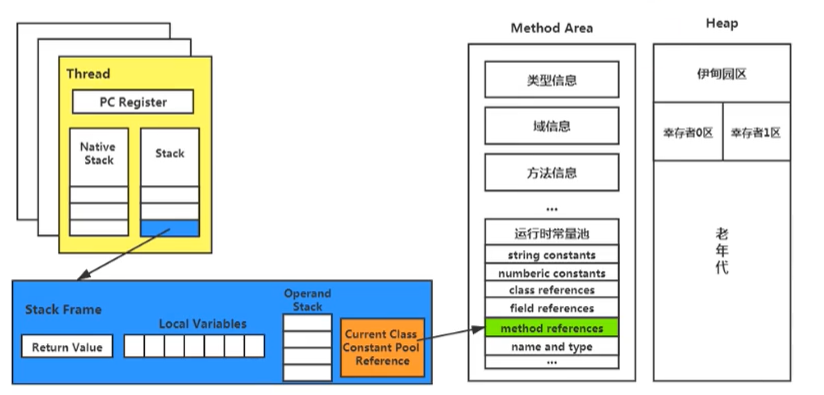
動態鏈接(Dynamic Linking)
每一個堆疊幀內部都包含一個指向運行時常量池中該堆疊幀所屬方法的參考,包含這個參考的目的就是為了支持當前方法的代碼能夠實作動態鏈接(Dynamic Linking) ,比如: invokedynamic指令,
在Java源檔案被編譯到位元組碼檔案中時,所有的變數和方法參考都作為符號參考(Symbolic Reference) 保存在class檔案的常量池里,比如:描述一個方法呼叫了另外的其他方法時,就是通過常量池中指向方法的符號參考來表示的,那么動態鏈接的作用就是為了將這些符號參考轉換為呼叫方法的直接參考,
在堆疊楨中存在有常量池,當執行緒開始運行時,堆疊楨中的常量池會載入到方法區中,也就是其中的運行時常量池,每一個堆疊楨的常量池中的符號參考都可以參考運行時常量池中的方法,這樣一來,就節省了記憶體空間,
方法的呼叫
在JVM中,將符號參考轉換為呼叫方法的直接參考與方法的系結機制相關,
●靜態鏈接:
當一個位元組碼檔案被裝載進JVM內部時,如果被呼叫的目標方法在編譯可知,且運行期保持不變時,這種情況下將呼叫方法的符號參考轉換為直接參考的程序稱之為靜態鏈接,●動態鏈接:
如果被呼叫的方法在編譯期無法被確定下來,也就是說,只能夠在程式運行期將呼叫方法的符號參考轉換為直接參考,由于這種參考轉換程序具備動態性,因此也就被稱之為動態鏈接,
對應的方法的系結機制為:早期系結(Early Binding)和晚期系結(Late Binding) ,系結是一個欄位、方法或者類在符號參考被替換為直接參考的程序,這僅僅發生一次,
●早期系結:
早期系結就是指被呼叫的目標方法如果在編譯期可知,且運行期保持不變時,即可將這個方法與所屬的型別進行系結,這樣一來,由于明確了被呼叫的目標方法究竟是哪-一個,因此也就可以使用靜態鏈接的方式將符號參考轉換為直接參考,●晚期系結:
如果被呼叫的方法在編譯期無法被確定下來,只能夠在程式運行期根據實際的型別系結相關的方法,這種系結方式也就被稱之為晚期系結,
隨著高級語言的橫空出世,類似于Java一樣的基于面向物件的編程語言如今越來越多,盡管這類編程語言在語法風格上存在一定的差別,但是它們彼此之間始終保持著一個共性,那就是都支持封裝、繼承和多型等面向物件特性,既然這一類的編程語言具備多型特性,那么自然也就具備早期系結和晚期系結兩種系結方式,
Java中任何一個普通的方法其實都具備虛函式(晚期系結)的特征,它們相當于C++語言中的虛函式(C++中則需要使用關鍵字virtual來顯式定義),如果在Java程式中不希望某個方法擁有虛函式的特征時,則可以使用關鍵字final來標記這個方法,
虛方法與非虛方法
非虛方法:
●如果方法在編譯期就確定了具體的呼叫版本,這個版本在運行時是不可變的,這樣的方法稱為非虛方法,
●靜態方法、私有方法、final方法、實體構造器、父類方法都是非虛方法,
●其他方法稱為虛方法,
子類物件的多型性的使用前提:①類的繼承關系②方法的重寫
虛擬機中提供了以下幾條方法呼叫指令:
普通呼叫指令:
- invokestatic: 呼叫靜態方法,決議階段確定唯一方法版本
- invokespecial: 呼叫
方法、私有及父類方法,決議階段確定唯一方法版本 - invokevirtual: 呼叫所有虛方法
- invokeinterface:呼叫介面方法
動態呼叫指令:
invokedynamic: 動態決議出需要呼叫的方法,然后執行前四條指令固化在虛擬機內部,方法的呼叫執行不可人為干預,而invokedynamic指令則支持由用戶確定方法版本,其中invokestatic指令和invokespecial指令呼叫的方法稱為非虛方法,其余的(final修飾的除外)稱為虛方法,
關于invokedynamic指令
在class檔案中,若使用了Lambda運算式來定義匿名方法,其在位元組碼中就會以invokedynamic修飾,
JVM位元組碼指令集一直比較穩定,直到Java7中才增加了一個invokedynamic指令,這是Jaya為了實作「動態型別語言」支持而做的一種改進,
但是在Java7中并沒有提供直接生成invokedynamic指令的方法,需要借助ASM這種底層位元組碼工具來產生invokedynamic指令,直到Java8的Lambda運算式的出現,invokedynamic指令的生成,在Java中才有了直接的生成方式,
Java7中增加的動態語言型別支持的本質是對Java虛擬機規范的修改,而不是對Java語言規則的修改,這一塊相對來講比較復雜,增加了虛擬機中的方法呼叫,最直接的受益者就是運行在Java平臺的動態語言的編譯器,
動態型別語言和靜態型別語言兩者的區別就在于對型別的檢查是在編譯期還是在運行期,滿足前者就是靜態型別語言,反之是動態型別語言,
說的再直白一點就是,靜態型別語言是判斷變數自身的型別資訊:動態型別語言是判斷變數值的型別資訊,變數沒有型別資訊,變數值才有型別資訊,這是動態語言的一個重要特征,
靜態型別語言:Java: String info = "abcd";
動態型別語言:Js: var info="abcd" var info=1
動態型別語言:python: info=100.1
方法回傳地址(Return Address)
作用:存放呼叫該方法的pc暫存器的值,(只保存正常退出的方法的pc暫存器的值)
一個方法的結束,有兩種方式:
正常執行完成
出現未處理的例外,非正常退出
無論通過哪種方式退出,在方法退出后都回傳到該方法被呼叫的位置,方法正常退出時,呼叫者的pc計數器的值作為回傳地址,即呼叫該方法的指令的下一條指令的地址,而通過例外退出的,回傳地址是要通過例外表來確定,堆疊幀中一般不會保存這部分資訊,
本質上,方法的退出就是當前堆疊幀出堆疊的程序,此時,需要恢復上層方法的區域變數表、運算元堆疊、將回傳值壓入呼叫者堆疊幀的運算元堆疊、設定PC暫存器值等,讓呼叫者方法繼續執行下去,
正常完成出口和例外完成出口的區別在于:通過例外完成出口退出的不會給他的上層呼叫者產生任何的回傳值,
當一個方法開始執行后,只有兩種方式可以退出這個方法:
執行引擎遇到任意一 一個方法回傳的位元組碼指令(return),會有回傳值傳遞給上層的方法呼叫者,簡稱正常完成出口;
一個方法在正常呼叫完成之后究竟需要使用哪一個回傳指令還需要根據方法回傳值的實際資料型別而定;
在位元組碼指令中,回傳指令包含ireturn (當回傳值是boolean、 byte、char、short和int型別時使用)、lreturn(long型別)、 freturn(float型別)、 dreturn(double型別)以及areturn(參考型別:String、Date),另外還有一個return指令供宣告為void的方法、實體初始化方法、類和介面的初始化方法使用,
- 在方法執行的程序中遇到了例外(Exception),并且這個例外沒有在方法內進行處理,也就是只要在本方法的例外表中沒有搜索到匹配的例外處理器,就會導致方法退出,簡稱例外完成出口,
- 方法執行程序中拋出例外時的例外處理,存盤在一個例外處理表,方便在發生例外的時候找到處理例外的代碼,
class位元組碼中的例外處理表
Exception table
from to target type
4 16 19 any//在4-16行中的任何例外,由19行來處理
19 21 19 any
本質上,方法的退出就是當前堆疊幀出堆疊的程序,此時,需要恢復上層方法的區域變數表、運算元堆疊、將回傳值壓入呼叫者堆疊幀的運算元堆疊、設定PC暫存器值等,讓呼叫者方法繼續執行下去,
正常完成出口和例外完成出口的區別在于:通過例外完成出口退出的不會給他的上層呼叫者產生任何的回傳值,
*一些附加資訊
堆疊幀中還允許攜帶與Java虛擬機實作相關的一些附加資訊,例如,對程式除錯提供支持的資訊,(不一定有)
本地方法堆疊
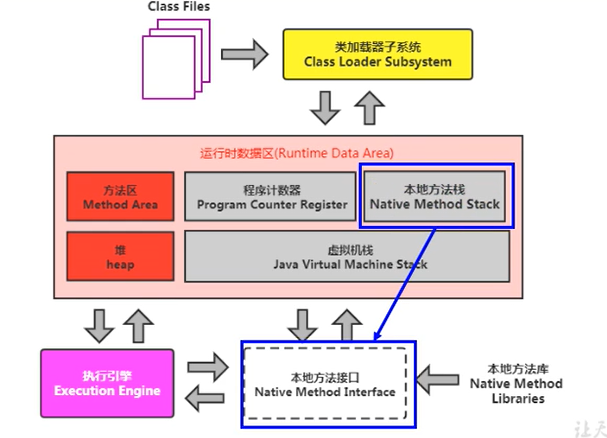
Java虛擬機堆疊用于管理Java方法的呼叫,而本地方法堆疊用于管理本地方法的呼叫,
本地方法堆疊,也是執行緒私有的,
允許被實作成固定或者是可動態擴展的記憶體大小,(在記憶體溢位方面是相同的)
如果執行緒請求分配的堆疊容量超過本地方法堆疊允許的最大容量,Java 虛擬機將會拋出一個stackoverflowError 例外,
如果本地方法堆疊可以動態擴展,并且在嘗試擴展的時候無法申請到足夠的記憶體,或者在創建新的執行緒時沒有足夠的記憶體去創建對應的本地方法堆疊,那么Java虛擬機將會拋出一個outofMemoryError 例外,
本地方法是使用C語言實作的,
它的具體做法是Native Method Stack中 登記native方法,在Execution Engine執行時加載本地方法庫,
當某個執行緒呼叫一一個本地方法時,它就進入了一個全新的并且不再受虛擬機限制的世界,它和虛擬機擁有同樣的權限,
本地方法可以通過本地方法接0來訪問虛擬機內部的運行時資料區,
它甚至可以直接使用本地處理器中的暫存器
直接從本地記憶體的堆中分配任意數量的記憶體,
并不是所有的JVM都支持本地方法,因為Java虛擬機規范并沒有明確要求本地方法堆疊的使用語言、具體實作方式、資料結構等,如果JVM產品不打算支持native方法,也可以無需實作本地方法堆疊,
在Hotspot JVM中,直接將本地方法堆疊和虛擬機堆疊合二為一,
本地方法(Native Method)
本地方法介面&本地方法庫
簡單地講,一個Native Method就是一個Java呼叫非Java代碼的介面,一個Native Method是這樣-一個Java方法:該方法的實作由非Java語言實作,比如C,這個特征并非Java所特有,很多其它的編程語言都有這一機制,比如在C++中,你可以用extern "C"告知C++編譯器去呼叫 一個c的函式,
"A native method is a Java method whose implementation is provided by non-java code."
在定義一個native method時, 并不提供實作體(有些像定義一個Javainterface),因為其實作體是由非java語言在外面實作的,本地介面的作用是融合不同的編程語言為Java所用,它的初衷是融合C/C++程式,
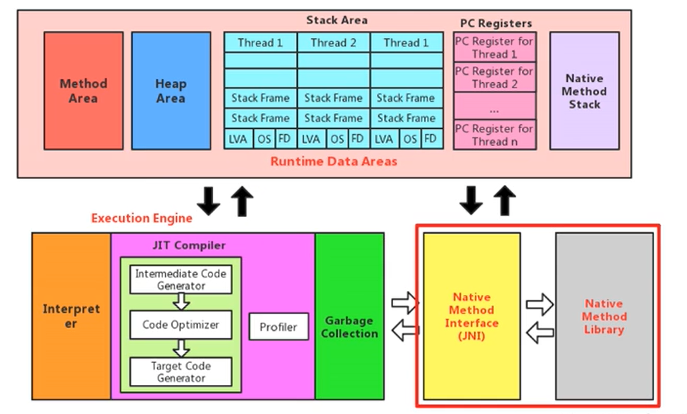
堆(heap)
核心概述
一個JVM實體只存在-一個堆記憶體,堆也是Java記憶體管理的核心區域,Java堆區在JVM啟動的時候即被創建,其空間大小也就確定了,是JVM管理的最大一塊記憶體空間,
堆記憶體的大小是可以調節的,
《Java虛擬機規范》規定,堆可以處于物理上不連續的記憶體空間中,但在邏輯上它應該被視為連續的,
所有的執行緒共享Java堆,在這里還可以劃分執行緒私有的緩沖區(Thread Local Allocation Buffer, TLAB) ,
《Java虛擬機規范》中對Java堆的描述是:所有的物件實體以及陣列都應當在運行時分配在堆上,(The heap is the run-time data area from which memory for all class instances and arrays is allocated )
我要說的是:“幾乎”所有的物件實體都在這里分配記憶體,——從實際使用角度看的,
陣列和物件可能永遠不會存盤在堆疊上,因為堆疊幀中保存參考,這個參考指向物件或者陣列在堆中的位置,
在方法結束后,堆中的物件不會馬上被移除,僅僅在垃圾收集的時候才會被移除,
堆,是GC ( Garbage Collection, 垃圾收集器)執行垃圾回收的重點區域,
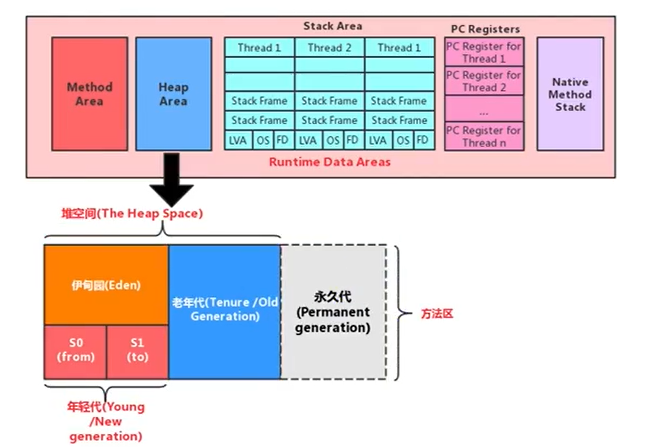
堆的記憶體細分
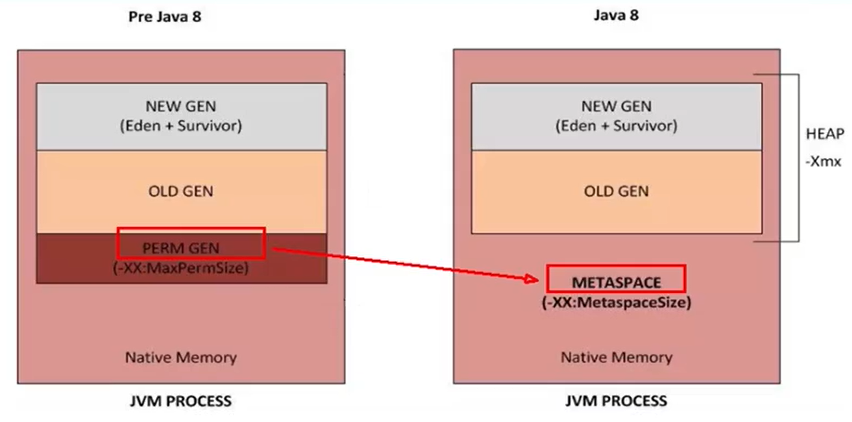
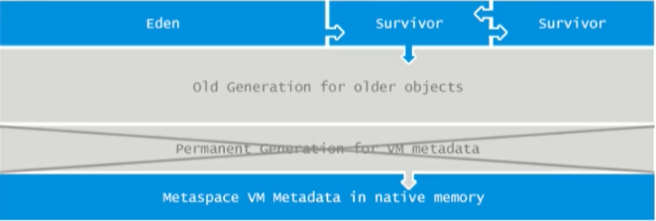
Java 7及之前堆記憶體邏輯上分為三部分:新生區+養老區+永久區
?Young Generation Space 新生區 Young/New
又被劃分為Eden區和Survivor區
?Tenure generation space 養老區 Old/ Tenure
?Permanent Space 永久區 Perm
Java 8及之后堆記憶體邏輯上分為三部分:新生區+養老區+元空間
?Young Generation Space 新生區 Young/New
又被劃分為Eden區和Survivor區
?Tenure generation space 養老區 Old/Tenure
?Meta Space 元空間 Meta
堆記憶體大小的設定與查看
Java堆區用于存盤Java物件實體,那么堆的大小在JVM啟動時就已經設定好了,可以通過選項”-Xmx"和”-Xms"來進行設定,
“-Xms"用于表示堆區的起始記憶體,等價于-XX: InitialHeapSize
“-Xmx" 則用于表示堆區的最大記憶體, 等價于-XX :MaxHeapSize一旦堆區中的記憶體大小超過“-Xmx"所指定的最大記憶體時,將會拋出OutOfMemoryError例外,
通常會將-Xms 和- -Xmx兩個引數配置相同的值,其目的是為了能夠在java垃圾回識訓制清理完堆區后不需要重新分隔計算堆區的大小,從而提高性能,
1.設定堆空間大小的引數
-Xms. 用來設定堆空間(年輕代+老年代)的初始記憶體大小
-X是jvm的運行引數
ms是memory start
-Xmx用來設定堆空間(年輕代+老年代)的最大記憶體大小
2.默認堆空間的大小
初始記憶體大小:物理電腦記憶體大小/ 64
最大記憶體大小:物理電腦記憶體大小/ 4
3.手動設定: -Xms600m -Xmx600m
開發中建議將初始堆記憶體和最大的堆記憶體設定成相同的值,
4.查看設定的引數:
方式一(cmd): jps / jstat -gc行程id
方式二(編譯器中設定): -XX: +PrintGCDetails
*OOM舉例
public class OOMTest{
public static void main(String args[]){
ArrayList<Picture> list = enw ArrayList<>();
while(true){
list.add(new Picture(new Random().nextInt(1026*1024)));
}
}
}
//最后報出OOM
新生代與老年代
存盤在JVM中的Java物件可以被劃分為兩類:
- 一類是生命周期較短的瞬時物件,這類物件的創建和消亡都非常迅速
- 另外一類物件的生命周期卻非常長,在某些極端的情況下還能夠與JVM的生命周期保持一致,
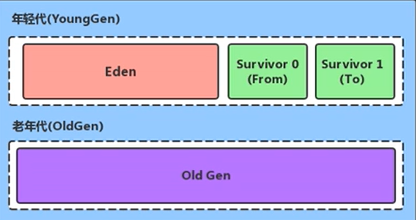
Java堆區進一步細分的話, 可以劃分為年輕代(YoungGen) 和老年代(0ldGen)
其中年輕代又可以劃分為Eden空間、Survivor0空間和Survivor1空間(有時也叫做from區、to區)
配置新生代與老年代在堆結構的占比,

默認-XX: NewRatio=2,表示新生代占1,老年代占2,新生代占整個堆的1/3
可以修改-XX:NewRatio=4,表示新生代占1,老年代占4,新生代占整個堆的1/5
在同樣記憶體下,占比少的部分GC也就更頻繁,
在HotSpot中,Eden空間和另外兩個Survivor空間預設所占的比例是8:1:1
當然開發人員可以通過選項“-XX: SurvivorRatio"調整這個空間比例,比如-XX: SurvivorRatio=8.
幾乎所有的Java物件都是在Eden區被new出來的,
絕大部分的Java物件的銷毀都在新生代進行了,
IBM公司的專門研究表明,新生代中80%的物件都是“朝生夕死”的,
可以使用選項”-Xmn"設定新生代最大記憶體大小
這個引數一般使用默認值就可以了,一般開發中設定好了堆的大小和比例就等于是確定了新生代的大小,
ps:JVM規范中提到,新生代中各記憶體比例是8:1:1,但是實際運行中卻是6:1:1.原因是其有一個自適應的記憶體分配策略(此策略是默認使用的)
可以手動設定"-XX: SurvivorRatio = 8"來實作8:1:1
-XX: -UseAdaptivesizePolicy :關閉自適應的記憶體分配策略( 暫時用不到)
物件分配的一般程序
為新物件分配記憶體是一件非常嚴謹和復雜的任務,JVM的設計者們不僅需要考慮記憶體如何分配、在哪里分配等問題,并且由于記憶體分配演算法與記憶體回收演算法密切相關,所以還需要考慮GC執行完記憶體回收后是否會在記憶體空間中產生記憶體碎片,
- new的物件先放伊甸園區,此區有大小限制,
- 當伊甸園的空間填滿時,程式又需要創建物件,JVM的垃圾回收器將對伊甸園區進行垃圾回收(Minor GC),將伊甸園區中的不再被其他物件所參考的物件進行銷毀,再加載新的物件放到伊甸園區,然后將伊甸園中的剩余物件移動到幸存者0區,
- 如果再次觸發垃圾回收,此時上次幸存下來的放到幸存者0區的,如果沒有回收,就會放到幸存者1區,
- 如果再次經歷垃圾回收,此時會重新放回幸存者0區,接著再去幸存者1區,
- 啥時候能去養老區呢?可以設定次數,默認是15次,
- 可以設定引數: -XX :MaxTenuringThreshold=
進行設定,
針對幸存者s0,s1區的總結:復制之后有交換,誰空誰是to.
關于垃圾回收:頻繁在新生區收集,很少在養老區收集,幾乎不在永久區/元空間收集,
Minor GC、Major GC、Full GC
JVM在進行GC時,并非每次都對,上面三個記憶體區域(指Eden s0 s1 )一起回收的,大部分時候回收的都是指新生代,
針對HotSpotVM的實作,它里面的GC按斬訓收區域又分為兩大種型別:一種是部分收集(Partial GC),一種是整堆收集(Full GC)
部分收集:不是完整收集整個Java堆的垃圾收集,其中又分為:
新生代收集(Minor GC / Young GC) :只是新生代的垃圾收集
老年代收集(MajorGC/0ldGC):只是老年代的垃圾收集,
目前,只有CMS GC會有單獨收集老年代的行為,
注意,很多時候Major GC會和Full GC混淆使用,需要具體分辨是老年代回識訓是整堆回收,
混合收集(Mixed GC):收集整個新生代以及部分老年代的垃圾收集,
目前,只有G1 GC會有這種行為
整堆收集(Fu1l GC): 收集整個java堆和方法區的垃圾收集,
年輕代GC(Minor GC):
觸發機制
當年輕代空間不足時,就會觸發Minor GC,這里的年輕代滿指的是Eden代滿,Survivor滿不會引發GC,(每次 Minor GC會清理年輕代的記憶體,)
因為Java 物件大多都具備朝生夕滅的特性,所以Minor GC非常頻繁,一般回收速度也比較快,這一定義既清晰又易于理解,
Minor GC會引發STW, 暫停其它用戶的執行緒,等垃圾回收結束,用戶執行緒才恢復運行,
老年代GC (Major GC/Fu1l GC)
觸發機制:
指發生在老年代的GC,物件從老年代消失時,我們說“Major GC"或“Fu11 GC”發生了,
出現了Major GC,經常會伴隨至少一次的Minor GC (但非絕對的,在Paral1elScavenge收集器的收集策略里就有直接進行MajorGC的策略選擇程序),
也就是在老年代空間不足時,會先嘗試觸發Minor GC,如果之后空間還不足,則觸發Major GC,
Major GC的速度- °般會比Minor GC慢10倍以上,STW的時間更長,
如果Major GC后,記憶體還不足,就報00M了,
Full GC
觸發機制
(后面細講)
觸發Fu1l GC執行的情況有如下五種:
(1)呼叫System.gc()時,系統建議執行Fu11 GC,但是不必然執行,
(2)老年代空間不足,
(3)方法區空間不足,
(4)通過Minor GC后進入老年代的平均大小大于老年代的可用記憶體,
(5)由Eden區、survivor space0 (From Space)區向survivor space1 (To Space)區復制時,物件大小大于To Space可用記憶體,則把該物件轉存到老年代,且老年代的可用記憶體小于該物件大小,
說明: full gc是開發或調優中盡量要避免的,這樣暫時時間會短一-些,
為什么需要把Java堆分代?
不分代就不能正常作業了嗎?
其實不分代完全可以,分代的唯一理由就是優化Gc性能,如果沒有分代,那所有的物件都在一塊,就如同把一個學校的人都關在一個教室,GC的時候要找到哪些物件沒用,這樣就會對堆的所有區域進行掃描,而很多物件都是朝生夕死的,如果分代的話,把新創建的物件放到某一地方,當GC的時候先把這塊存盤“朝生夕死”物件的區域進行回收,這樣就會騰出很大的空間出來,
記憶體分配策略 or 物件提升(Promotion)規則
一般情況
如果物件在Eden出生并經過第一次MinorGC 后仍然存活,并且能被Survivor容納的話,將被移動到Survivor空間中,并將對 象年齡設為1,物件在Survivor區中每熬過一 次MinorGC ,年齡就增加1歲,當它的年齡增加到一定程度(默認為15歲,其實每個JVM、 每個GC都有所不同)時,就會被晉升到老年代中,
物件晉升老年代的年齡閾值,可以通過選項-XX :MaxTenuringThreshold來設定,
針對不同年齡段的物件分配原則如下所示:
優先分配到Eden
大物件直接分配到老年代
盡量避免程式中出現過多的大物件
長期存活的物件分配到老年代
動態對 象年齡判斷
如果Survivor區中相同年齡的所有物件大小的總和大于Survivor空間的一半,年齡大于或等于該年齡的物件可以直接進入老年代,無須等到MaxTenuringThreshold中要求的年齡,
空間分配擔保
-XX: HandlePromotionFai lure
執行緒私有的緩沖區
why?
堆區是執行緒共享區域,任何執行緒都可以訪問到堆區中的共享資料
由于物件實體的創建在JVM中非常頻繁,因此在并發環境下從堆區中劃分記憶體空間是執行緒不安全的
為避免多個執行緒操作同一地址,需要使用加鎖等機制,進而影響分配速度,
what?
從記憶體模型而不是垃圾收集的角度,對Eden區域繼續進行劃分,JVM為每個執行緒分配了-一個私有快取區域,它包含在Eden空間內,
多執行緒同時分配記憶體時,使用TLAB可以避免一系列的非執行緒安全問題,同時還能夠提升記憶體分配的吞吐量,因此我們可以將這種記憶體分配方式稱之為快速分配策略,
據我所知所有OpenJDK衍生出來的JVM都提供了TLAB的設計,
盡管不是所有的物件實體都能夠在TLAB中成功分配記憶體,但JVM確實是將TLAB作為記憶體分配的首選,
在程式中,開發人員可以通過選項“-XX :UseTLAB”設定是否開啟TLAB空間,
默認情況下,TLAB空間的記憶體非常小,僅占有整個Eden空間的1號,當然我們可以通過選項“-XX:TLABWasteTargetPercent”設定TLAB空間所占用Eden空間的百分比大小,
一旦物件在TLAB空間分配記憶體失敗時,JVM就會嘗試著通過使用加鎖機制確保資料操作的原子性,從而直接在Eden空間中分配記憶體,.
測驗堆空間常用的引數
測驗堆空間常用的jvm引數:
-XX: +PrintFlagsInitial :查看所有的引數的默認初始值
-XX: +PrintFlagsFinal : 查看所有的引數的最終值(可能會存在修改,不再是初始值)
具體查看某個引數的指令: jps: 查看當前運行中的行程
? cmd中查看:jinfo -flag survivorRatio 行程id
-Xms:初始堆空間記憶體(默認為物理記憶體的1/64)
-Xmx:最大堆空間記憶體(默認為物理記憶體的1/4)
-Xmn:設定新生代的大小,(初始值及最大值)
-XX:NewRatio:配置新生代與老年代在堆結構的占比
-XX:SurvivorRatio:設定新生代中Eden和S0/S1空間的比例
-XX:MaxTenuringThreshold:設定新生代垃圾的最大年齡
-Xx: +PrintGCDetails:輸出詳細的GC處理日志
列印gc簡要資訊:⑧-XX:+PrintGC ② - verbose:gc
-XX:HandlePromotionFailure:是否設定空間分配擔保
空間分配擔保
在發生Minor Gc之 前,虛擬機會檢查老年代最大可用的連續空間是否大于新生代所有
物件的總空間,
如果大于,則此次Minor GC是安全的如果小于,則虛擬機會查看-XX : HandlePromot ionFai lure設定值是否允許擔保失敗,
如果HandlePromotionFailure=true, 那么會繼續檢查老年代最大可用連續空間是否大于歷次晉升到老年代的物件的平均大小,
v如果大于,則嘗試進行一次Minor GC, 但這次Minor GC依然是有風險的;
V如果小于,則改為進行一次Full GC,
V如果HandlePromot ionFailure=false,則改為進行一-次Full GC,
在JDK6 Update24之 后(JDK7) ,HandlePromotionFailure引數不會再影響到虛擬機的空間分配擔保策略,觀察OpenJDK中的原始碼變化,雖然原始碼中還定義了HandlePromotionFailure引數,但是在代碼中已經不會再使用它,JDK7之后的規則變為只要老年代的連續空間大于新生代物件總大小或者歷次晉升的平均大小就會進行Minor GC,否則將進行Full GC,
逃逸分析
如何快速的判斷是否發生了逃逸分析, 就看new的物件物體是否有可能在方法外被呼叫,
逃逸分析設定(默認啟用): -XX: -DoEscapeAnalysis
隨著JIT編譯期的發展與逃逸分析技術逐漸成熟,堆疊上分配、標量替換優化技術將會導致一些微妙的變化,所有的物件都分配到堆上也漸漸變得不那么“絕對”了,
在Java虛擬機中,物件是在Java堆中分配記憶體的,這是一個普遍的常識,但是,有一種特殊情況,那就是如果經過逃逸分析(Escape Analysis) 后發現,一個物件并沒有逃逸出方法的話,那么就可能被優化成堆疊上分配,這樣就無需在堆上分配記憶體,也無須進行垃圾回收了,這也是最常見的堆外存盤技術,
此外,前面提到的基于OpenJDK深度定制的TaoBaoVM,其中創新的GCIH (GC invisible heap) 技術實作off - heap,將生命周期較長的Java物件從heap中移至heap外,并且GC不能管理GCIH內部的Java物件,以此達到降低GC的回收頻率和提升GC的回收效率的目的,
如何將堆上的物件分配到堆疊,需要使用逃逸分析手段,
這是一種可以有效減少Java程式中同步負載和記憶體堆分配壓力的跨函式全域資料流分析演算法,
通過逃逸分析,Java Hotspot編 譯器能夠分析出一一個新的物件的參考的使用范圍從而決定是否要將這個物件分配到堆上,
逃逸分析的基本行為就是分析物件動態作用域:
當一個物件在方法中被定義后,物件只在方法內部使用,則認為沒有發生逃逸,
當一個物件在方法中被定 義后,它被外部方法所參考, 則認為發生逃逸,例如作為呼叫引數傳遞到其他地方中,
沒有發生逃逸的物件,則可以分配到堆疊上,隨著方法執行的結束,堆疊空間就被移除,
//此物件的作用空間只在main方法內部,所以沒有發生逃逸
public static void main(){
V v = new v();
v = null;
}
//StringBuffer物件被return出去,可能會被其他方法呼叫,所以此物件發生了逃逸
public StringBuffer strBfer(){
StringBuffer sb = new StringBuffer();
sb.append(s1);
return sb
}
//經過優化后,回傳了一個String的一個新物件,StringBuffer沒有被return出去,所以沒有發生逃逸
public StringBuffer strBfer(){
StringBuffer sb = new StringBuffer();
sb.append(s1);
return sb.toString;
}
代碼優化
使用逃逸分析,編譯器可以對代碼做如下優化:
1.堆疊上分配,將堆分配轉化為堆疊分配,如果一個物件在子程式中被分配,要使指向該物件的指標永遠不會逃逸,物件可能是堆疊分配的候選,而不是堆分配,
2.同步省略,如果一個物件被發現只能從一個執行緒被訪問到,那么對于這個物件的操作可以不考慮同步,
3.分離物件或標量替換,有的物件可能不需要作為一個連續的記憶體結構存在也可以被訪問到,那么物件的部分(或全部)可以不存盤在記憶體,而是存盤在CPU暫存器中,
堆疊上分配
JIT編譯器在編譯期間根據逃逸分析的結果,發現如果一一個物件并沒有逃逸出方法的話,就可能被優化成堆疊.上分配,分配完成后,繼續在呼叫堆疊內執行,最后執行緒結束,堆疊空間被回收,區域變數物件也被回收,這樣就無須進行垃圾回收了,
常見的堆疊上分配的場景
在逃逸分析中,已經說明了,分別是給成員變數賦值、方法回傳值、實體參考傳遞,
//測驗代碼
//-Xms=1G -Xmx=1G -XX:+PrintGCDetails
//-Xms=1G -Xmx=1G -XX: -DoEscapeAnalysis -Xx:+PrintGCDetails
public void main(Strign[] args){
long start = System.currenTimeMillis();
for(int i = 0;i<1000000;i++){
alloc();
}
long end = System.currenTimeMillis();
System.out.println("話費的時間為:"+(end-start));
try{
Thread.sleep(1000000);
}catch(Exception e){
e.pringtSackTrace;
}
}
private static void alloc(){
User user = new User();
}
static class User{
}
同步省略(消除)
執行緒同步的代價是相當高的,同步的后果是降低并發性和性能,
在動態編譯同步塊的時候,JIT編譯器可以借助逃逸分析來判斷同步塊所使用的鎖物件是否只能夠被一個執行緒訪問而沒有被發布到其他執行緒,如果沒有,那么JIT編譯器在編譯這個同步塊的時候就會取消對這部分代碼的同步,這樣就能大大提高并發性和性能,這個取消同步的程序就叫同步省略,也叫鎖消除,
//如下代碼
public void sy(){
Object hollis = new Object();
synchronized(hollis){
System.out.println(hollis);
}
}
//由于物件并沒有發生逃逸,逃逸分析會自動同步省略,需要主意的一點是,同步省略是在加載到記憶體之后發生的,在編譯期間還是可以看見同步(monitorenter&monitorexitr)的位元組碼
分離物件或標量替換
標量替換引數設定:
-XX:+EliminateAllocations:開啟了標量替換(默認打開),允許將物件打散分配在堆疊上,
標量(scalar)是指一個無法再分解成更小的資料的資料,Java中的原始資料型別就是標量,
相對的,那些還可以分解的資料叫做聚合量(Aggregate) ,Java中的物件就是聚合量,因為他可以分解成其他聚合量和標量,
在JIT階段,如果經過逃逸分析,發現-一個物件不會被外界訪問的話,那么經過JIT優化,就會把這個物件拆解成若干個其中包含的若干個成員變數來代替,這個程序就是標量替換,,
//標量抽象概念
class user{//聚合量
String name;//標量
String age;
Accont Acc;
}
class Accont{//聚合量
double balance;//標量
}
//標量替換
public static void main(String[] args){
alloc();
}
public static alloc(){//point物件作用域只在alloc方法內,未發生逃逸
point p = new point(1,2);
System.out.println(p.a+"--"p.b);
}
class point{
private int a;
private int b;
}
//標量替換優化后-------------------------------------
//可以看到,Point這個聚合量經過逃逸分析后,發現他并沒有逃逸,就被替換成兩個聚合量了,那么標量替換有什么好處呢?就是可以大大減少堆記憶體的占用,因為一旦不需要創建物件了, 那么就不再需要分配堆記憶體了 ,
public static alloc(){
int a = 1;
int b = 2;
System.out.println(p.a+"--"p.b);
}
方法區
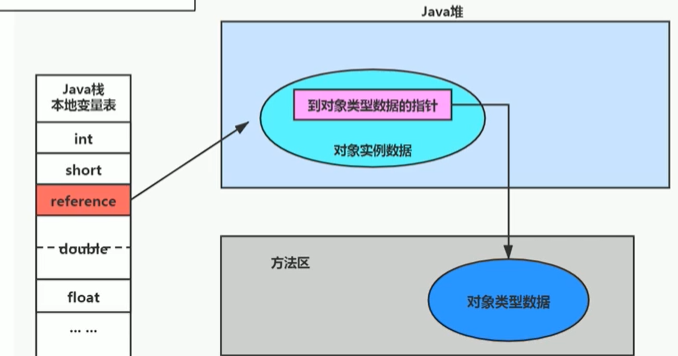
堆、堆疊與方法區的互動關系
Person person = new Person();
方法區 java堆疊 java堆
方法區在哪里?
《Java虛擬機規范》中明確說明:“盡管所有的方法區在邏輯上是屬于堆的一部分,但.一些簡單的實作可能不會選擇去進行垃圾收集或者進行壓縮,”但對于HotspotJVM而言,方法區還有一個別名叫做Non-Heap (非堆),目的就是要和堆分開,
所以,方法區看作是一塊獨立于Java堆的記憶體空間,
方法區基本理解
方法區 (Method Area) 與Java堆一樣,是各個執行緒共享的記憶體區域,
方法區在JVM啟動的時候被創建,并且它的實際的物理記憶體空間中和Java堆區--樣都可以是不連續的,
方法區的大小,跟堆空間一樣,可以選擇固定大小或者可擴展,方法區的大小決定 了系統可以保存多少個類,如果系統定義了太多的類,導致方法區溢位,虛擬機同樣會拋出記憶體溢位錯誤: java. lang . OutOfMemoryError :PermGen space或者java. lang.OutOfMemoryError: Metaspace
加載大量的第三方的jar包; Tomcat部署的工程過多(30-50個) ;大量動態的生成反射類
關閉JVM就會釋放這個區域的記憶體,
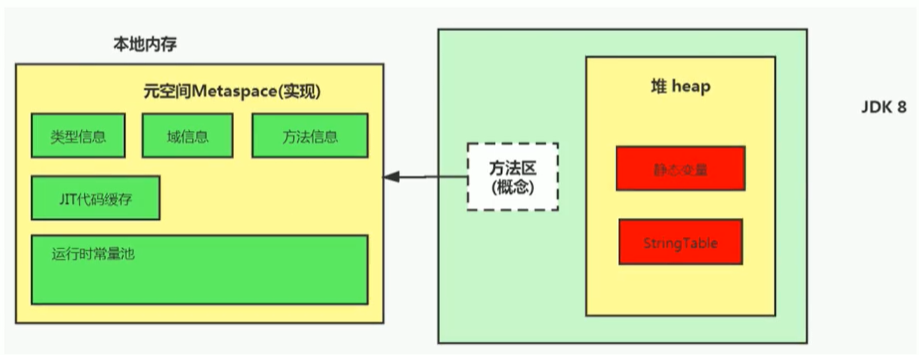
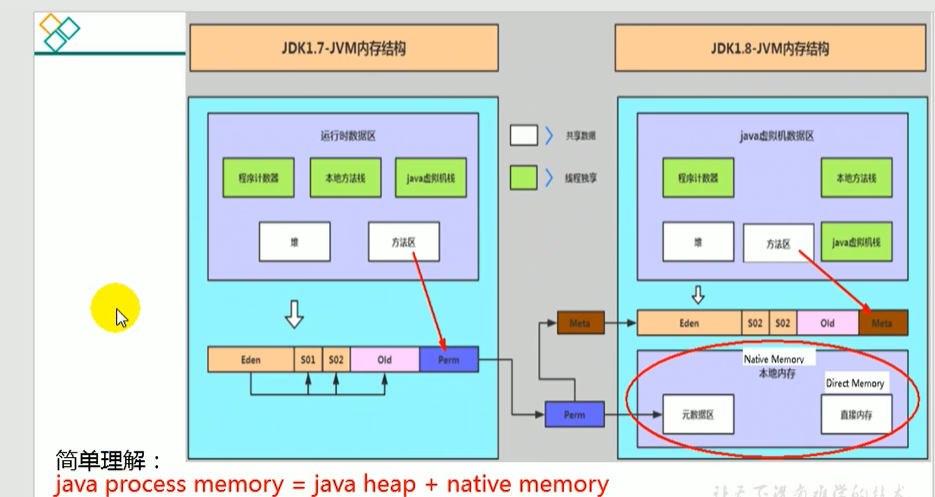
Hostspot中方法區的演進
到了JDK 8, 終于完全廢棄了永久代的概念,改用與JRockit、J9一樣在本地記憶體中實作的元空間(Metaspace) 來代替,
元空間的本質和永久代類似,都是對JVM規范中方法區的實作,不過元空間與永久代最大的區別在于:元空間不在虛擬機設定的記憶體中,而是使用本地記憶體,
永久代、元空間二者并不只是名字變了,內部結構也調整了,
根據《Java虛擬機規范》的規定,如果方法區無法滿足新的記憶體分配需求時,將拋出OOM例外,
方法區大小設定
元資料區大小可以使用引數-XX:MetaspaceSize和-XX: MaxMetaspaceSize指定,替代上述原有的兩個引數,
默認值依賴于平臺,windows下,-XX:MetaspaceSize是21M,-XX :MaxMetaspaceSize的值是-1,即沒有限制,
與永久代不同, 如果不指定大小,默認情況下,虛擬機會耗盡所有的可用系統記憶體,如果元資料區發生溢位,虛擬機一樣會拋出例外OutOfMemoryError: Metaspace
-XX:MetaspaceSize: 設定初始的元空間大小,對于一個64位的服務器端JVM來說,其默認的-XX :MetaspaceSize值為21MB,這就是初始的高水位線,一旦觸及這個水位線,FullGC將會被觸發并卸載沒用的類(即這些類對應的類加載器不再存活),然后這個高水位線將會重置,新的高水位線的值取決于GC后釋放了多少元空間,如果釋放的空間不足,那么在不超過MaxMetaspaceSize時,適當提高該值,如果釋放空間過多,則適當降低該值,
如果初始化的高水位線設定過低,上述高水位線調整情況會發生很多次,通過垃圾回收器的日志可以觀察到Full GC多次呼叫,為了避免頻繁地GC,建議將-XX :MetaspaceSize設定為一個相對較高的值,
如何解決OOM
1、要解決OOM例外或heap space的例外,一 般的手段是首先通過記憶體映像分析工具(如Eclipse Memory Analyzer) 對dump出來的堆轉儲快照進行分析,重點是確認記憶體中的物件是否是必要的,也就是要先分清楚到底是出現了記憶體泄漏(Memory Leak)還是記憶體溢位(Memory Overflow),
2、如果是記憶體泄漏,可進一步通過工具查看泄漏物件到GC Roots的參考鏈,于是就能找到泄漏物件是通過怎樣的路徑與GCRoots相關聯并導致垃圾收集器無法自動回收它們的,掌握了泄漏物件的型別資訊,以及GC Roots參考鏈的資訊,就可以比較準確地定位出泄漏代碼的位置,
3、如果不存在記憶體泄漏,換句話說就是記憶體中的物件確實都還必須存活著,那就應當檢查虛擬機的堆引數(-Xmx 與-Xms) ,與機器物理記憶體對比看是否還可以調大,從代碼上檢查是否存在某些物件生命周期過長、持有狀態時間過長的情況,嘗試減少程式運行期的記憶體消耗,
ps:記憶體泄漏->指在堆中存有被過多被參考的無效記憶體,進而導致記憶體溢位
方法區的內部結構
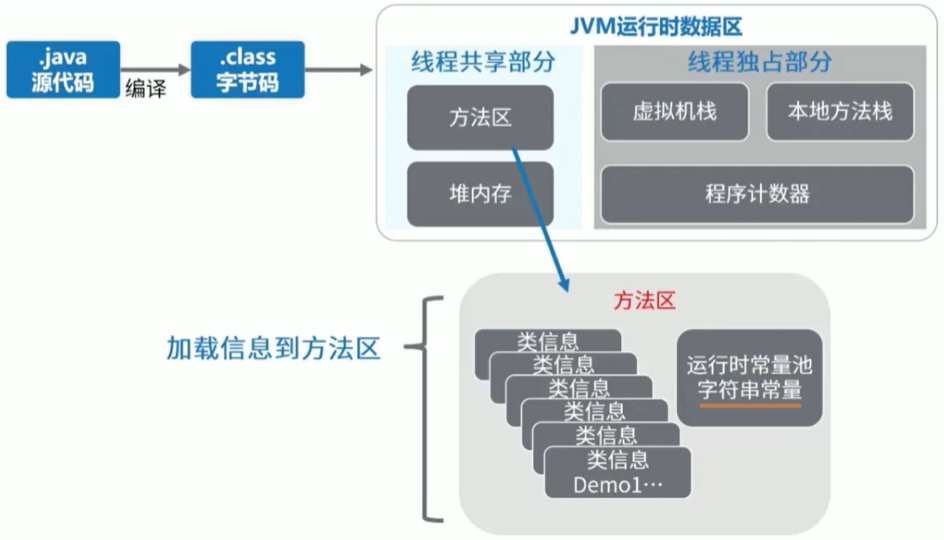
型別資訊
對每個加載的型別( 類clas3、介面interface.列舉enum、注解annotation),JVM必須在方法區中存盤以下型別資訊:
這個型別的完整有效名稱(全名=包名.類名)
這個型別直接父類的完整有效名(對于interface或是java. lang .object, 都沒有父類)
這個型別的修飾符(public, abstract, final的某個子集)
這個型別直接介面的一個有序串列.
域(Field)資訊/屬性/成員變數
JVM必須在方法區中保存型別的所有域的相關資訊以及域的宣告順序,
域的相關資訊包括:
域名稱、域型別、域修飾符(public, private,protected, static, final, volatile, transient的某個子集)
方法資訊
JVM必須保存所有方法的一下資訊,同域資訊一樣包括宣告順序:
方法名稱.
方法的回傳型別(或void)
方法引數的數量和型別(按順序)
方法的修飾符(public, private, protected, static, final,synchronized, native, abstract的- 一個子集)
方法的位元組碼(bytecodes)、運算元堆疊、區域變數表及大小( abstract和native方法除外)
例外表( abstract和native方法除外)
每個例外處理的開始位置、結束位置、代碼處理在程式計數器中的偏移地址、
被捕獲的例外類的常量池索引
常量池&運行時常量池
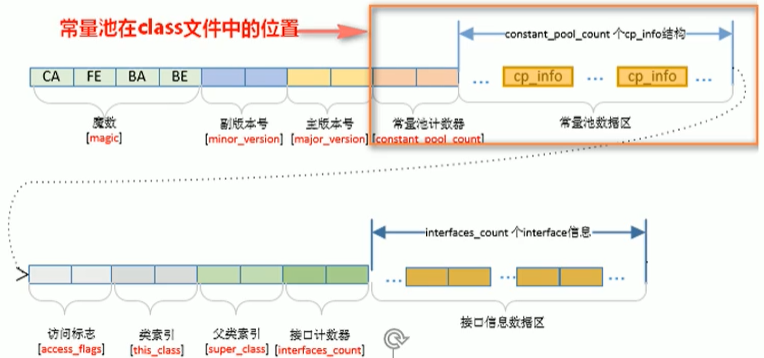
常量池
常量池,可以看做是一張表,虛擬機指令根據這張常量表找到要執行的類名、方法名、引數型別、字面量等型別,
一個有效的位元組碼檔案中除了包含類的版本資訊、欄位、方法以及介面等描述資訊外,還包含一項資訊那就是常量池表(Constant Pool Table) ,包括各種字面量和對型別、域和方法的符號參考,
常量池的作用
一個java源檔案中的類、介面,編譯后產生一個位元組碼檔案,而Java中的位元組碼需要資料支持,通常這種資料會很大以至于不能直接存到位元組碼里,換另一種方式,可以存到常量池,這個位元組碼包含了指向常量池的參考,在動態鏈接的時候會用到運行時常量池,之前有介紹,
public class SimpleClass{
public void test(){
System.out.println("helloword!");
}
}
雖然只有194位元組,但是里面卻使用了String、System、 PrintStream及Object等結構,這里代碼量其實已經很小了,如果代碼多,參考到的結構會更多! 這里就需要常量池了!
常量池里有什么?
數量值、字串值、類參考、欄位參考、方法參考
運行時常量池
運行時常量池( Runtime Constant Pool) 是方法區的一部分,
常量池表(Constant Pool Table) 是Class檔案的一部分,用于存放編譯期生成的各種字面量與符號參考,這部分內容將在類加載后存放到方法區的運行時常量池中,運行時常量池,在加載類和介面到虛擬機后,就會創建對應的運行時常量池,
JVM為每個已加載的型別(類或介面)都維護-一個常量池,池中的資料項像陣列項-一樣,是通過索引訪問的,
運行時常量池中包含多種不同的常量,包括編譯期就已經明確的數值字面量,也包括到運行期決議后才能夠獲得的方法或者欄位參考,此時不再是常量池中的符號地址了,這里換為真實地址,
運行時常量池,相對于Class檔案常量池的另一重要特征是:具備動態性,
String. intern()運行時常量池類似于傳統編程語言中的符號表(symbol table) ,但是它所包含的資料卻比符號表要更加豐富一些,
當創建類或介面的運行時常量池時,如果構造運行時常量池所需的記憶體空間超過了方法區所能提供的最大值,則JVM會拋OutOfMemoryError例外,
方法區的演進

為什么要替換永久代?
1.為永久代設定空間大小是很難確定的,
在某些場景下,如果動態加載類過多,容易產生Perm區的0OM,比如某個實際web.工程中,因為功能點比較多,在運行程序中,要不斷動態加載很多類,經常出現致命錯誤,
而元空間和永久代之間最大的區別在于:元空間并不在虛擬機中,而是使用本地記憶體,因此,默認情況下,元空間的大小僅受本地記憶體限制,
2.對永久代進行調優是很困難的,
StringTable為什么要調整?
jdk7中將StringTable放到了堆空間中,因為永久代的回收效率很低,在full gc的時候才會觸發,而full gc是老年代的空間不足、永久代不足時才會觸發,這就導致String Table回收效率不高,而我們開發中會有大量的字串被創建,回收效率低,導致永久代記憶體不足,放到堆里,能及時回收記憶體,
方法區的垃圾回收
有些人認為方法區(如HotSpot虛擬機中的元空間或者永久代)是沒有垃圾收集行為的,其實不然,《Java虛擬機規范》對方法區的約束是非常寬松的,提到過可以不要求虛擬機在方法區中實作垃圾收集,事實上也確實有未實作或未能完整實作方法區型別卸載的收集器存在(如JDK11時期的zGC收集器就不支持類卸載)
一般來說這個區域的回收效果比較難令人滿意,尤其是型別的卸載,條件相當苛刻,但是這部磁區域的回收有時又確實是必要的,以前Sun公司的Bug串列中,曾出現過的若干個嚴重的Bug;就是由于低版本的HotSpot虛擬機對此區域未完全回收而導致記憶體泄漏,方法區的垃圾收集主要回收兩部分內容:常量池中廢棄的常量和不再使用的型別,
方法區的垃圾收集主要回收兩部分內容:常量池中廢棄的常量和不再使用的型別,
先來說說方法區內常量池之中主要存放的兩大類常量:字面量和符號參考,字面量比較接近Java語言層次的常量概念,如文本字串、被宣告為final的常量值等,而符號參考則屬于編譯原理方面的概念,包括下面三類常量:
1、類和介面的全限定名
2、欄位的名稱和描述符
3、方法的名稱和描述符HotSpot,虛擬機對常量池的回收策略是很明確的,只要常量池中的常量沒有被任何地方參考,就可以被回收,
回收廢棄常量與回收Java堆中的物件非常類似,
判定一個常量是否“廢棄”還是相對簡單,而要判定一個型別是否屬于“不再被使用的類”的條件就比較苛刻了,需要同時滿足下面三個條件:
該類所有的實體都已經被回收,也就是Java堆中不存在該類及其任何派生子類的實體,
加載該類的類加載器已經被回收,這個條件除非是經過精心設計的可替換類加載器的場景,如OSGi、 JSP的重加載等,否則通常是很難達成的,
該類對應的java.1ang. Class物件沒有在任何地方被參考,無法在任何地方通過反射訪問該類的方法,
Java虛擬機被允許對滿足.上述三個條件的無用類進行回收,這里說的僅僅是“被允許”,而并不是和物件一樣,沒有參考了就必然會回收,關于是否要對型別進行回收,HotSpot虛擬機提供了-Xnoclassgc引數進行控制,還可以使用-verbose: class以及-XX:+TraceClass-Loading、-XX:+TraceClassUnLoading查看 類加載和卸載資訊
在大量使用反射、動態代理、CGLib等位元組碼框架,動態生成JSP以及oSGi這類頻繁自定義類加載器的場景中,通常都需要Java虛擬機具備型別卸載的能力,以保證不會對方法區造成過大的記憶體壓力,
物件的實體化和記憶體布局

物件的實體化
物件實體化的程序
⑧加載類元資訊
②為物件分配記憶體
⑧處理并發問題-
④屬性的默認初始化(零值初始化)設定物件頭的資訊
⑥屬性的顯式初始化、代碼塊中初始化、構造器中初始化
創建物件的步驟
1.判斷物件對應的類是否加載、鏈接、初始化
虛擬機遇到一條new指令 ,首先去檢查這個指令的引數能香在Metaspace的常量池中定位到一個類的符號參考,并且檢查這個符號參考代表的類是否已經被加載、決議和初始化,( 即判斷類元資訊是否存在),如果沒有,那么在雙親委派模式下,使用當前類加載器以ClassLoader+包名+類名為Key進行查找對應的.Class檔案,如果沒有找到檔案,則拋出ClassNotFoundException例外,如果找到,則進行類加載,并生成對應的Class類物件
2.為物件分配記憶體
首先計算物件占用空間大小,接著在堆中劃分一塊記憶體給新物件,如果實體成員變數是參考變數,僅分配參考變數空間即可,即4個位元組大小,
如果記憶體規整
如果記憶體是規整的,那么虛擬機將采用的是指標碰撞法( Burmp The Pointer )來為物件分配記憶體,
意思是所有用過的記憶體在一邊,空閑的記憶體在另外一邊,中間放著-一個指標作為分界點的指示器,分配記憶體就僅僅是把指標向空閑那邊挪動一段與物件大小相等的距離罷了,如果垃圾收集器選擇的是Serial、ParNew這種基于壓縮演算法的,虛擬機采用這種分配方式,一般使用帶有compact (整理)程序的收集器時,使用指標碰撞,
如果記憶體不規整
虛擬機需要維護一個串列
如果記憶體不是規整的,已使用的記憶體和未使用的記憶體相互交錯,那么虛擬機將采用的是空閑串列法來為物件分配記憶體,
意思是虛擬機維護了一個串列,記錄上哪些記憶體塊是可用的,再分配的時候從串列中找到一塊足夠大的空間劃分給物件實體,并更新串列上的內容,這種分配方式成為“空閑串列( Free List ) ",
選擇哪種分配方式由Java堆是否規整決定,而Java堆是否規整又由所采用的垃圾收集器是否帶有
壓縮整理功能決定,
3.處理并發安全問題
采用CAS失敗重試、區域加鎖保證更新的原子性
每個執行緒預先分配一塊TLAB一一 通過-XX:+/-UseTLAB引數來設定
4.初始化分配到的空間
默認初始化
所有屬性設定默認值,保證物件實體欄位在不賦值時可以直接使用
5.設定物件的物件頭
將物件的所屬類(即類的元資料資訊)、物件的HashCode和物件的GC資訊、 鎖資訊等資料存盤在物件的物件頭中,這個程序的具體設定方式取決于JVM實作,
類(方法區)->物件(java堆)->方法(java堆疊)
6.執行init方法進行初始化
在Java程式的視角看來,初始化才正式開始,初始化成員變數,執行實體化代碼塊,呼叫類的構造方法,并把堆內物件的首地址賦值給參考變數,
因此一般來說(由位元組碼中是否跟隨有invokespecel指令所決定), new指令之后會接著就是執行方法,把物件按照程式員的意愿進行初始化,這樣一個真正可用的物件才算完全創建出來,
物件的記憶體布局
public class Customers{
publc void Customer(){
static{
name="匿名客戶";
}
int id=1001;
Acct acct = new acct();
}
}
-------------------------------------------------------------
@Setter
@Getter
public class Acct{
private int userCode;
private int money;
public acct(){
}
}
------------------------------------------------------------------
public class test{
public void main(String[] args){
Customers customers = new Customers();
}
}
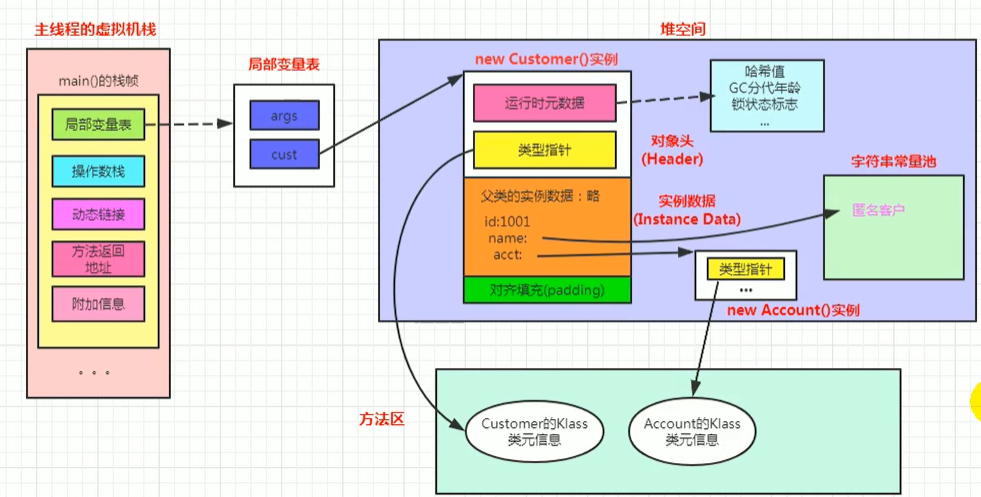
物件的訪問定位
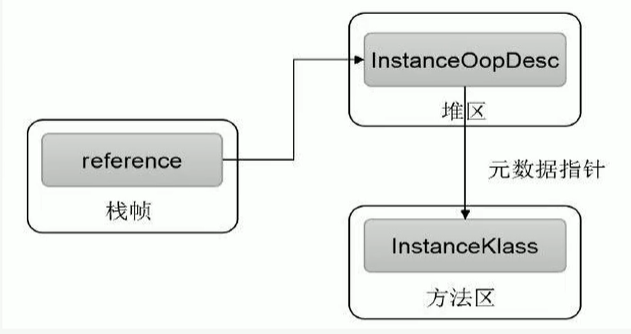
JVM是如何通過堆疊幀中的物件參考訪問到其內部的物件實體的呢?
定位,通過堆疊上reference訪問
物件的訪問方式有兩種
1.句柄訪問
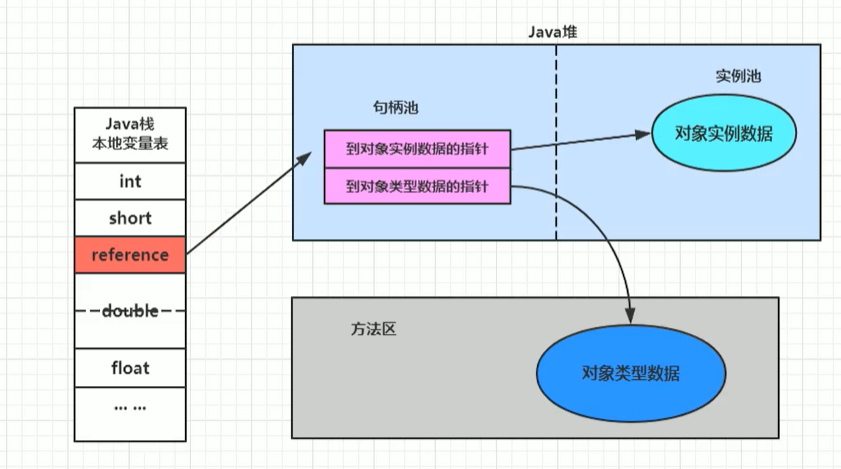
優點:
reference中存盤穩定句柄地址,物件被移動(垃圾收集時移動物件很普遍)時只會改變句柄中實體資料指標即可, reference本身不需要被修改,
缺點:
占用較多記憶體,效率較低
2.直接指標
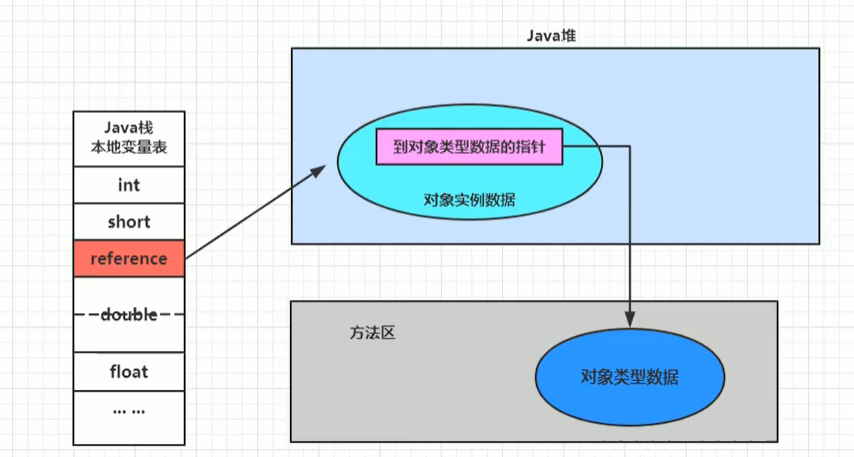
優點
節省空間,速度快,效率高
缺點
資料在移動時reference地址也要修改
直接記憶體(Direct Memory)
不是虛擬機運行時資料區的一部分, 也不是《Java虛擬機規范》中定義的記憶體區域,
直接記憶體是在Java堆外的、直接向系統申請的記憶體區間,
來源于NIO,通過存在堆中的DirectByteBuffer操作Naltive記憶體
通常,訪問直接記憶體的速度會優于Java堆, 即讀寫性能高,
因此出于性能考慮,讀寫頻繁的場合可能會考慮使用直接記憶體,
Java的NIO庫允許Java程式使用直接記憶體,用于資料緩沖區
IO與NIO
IO:byte[ ] / char[ ] Stream
NIO:buffer Channel
public class test{
public void main(String[] args){
//直接分配本地記憶體空間
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(BUFFER);
System.out.println("直接記憶體分配完畢,請求指示! ");
Scanner scanner = new Scanner(System. in);
scanner.next();
system.out.println("直接記憶體開始釋放! ");
byteBuffer = nu1l;
System.gc();
scanner.next();
}
}
讀寫檔案
需要與磁盤互動需要由用戶態切換到內核態,在內核態時,需要記憶體如圖的操作,使用IO,見圖,這里需要兩份記憶體存盤重復資料,效率低,
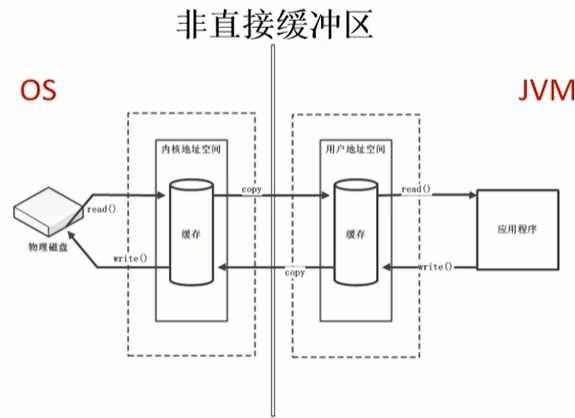
使用NIO時,如右圖,作業系統劃出的直接快取區可以被java代碼直接訪問,只有一份,NIO適合對大檔案的讀寫操作,
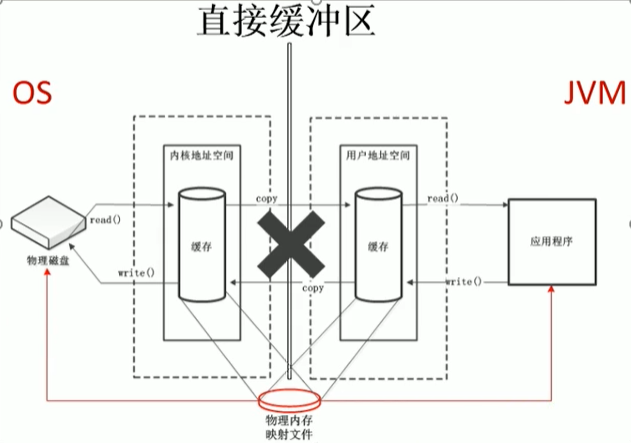
也可能導致OutOfMemoryError例外
由于直接記憶體在Java堆外,因此它的大小不會直接受限于-Xmx指定的最大堆大小,但是系統記憶體是有限的,Java堆和直接記憶體的總和依然受限于作業系統能給出的最大記憶體,
缺點
分配回收成本較高
不受JVM記憶體回收管理直接記憶體大小可以通過MaxDirectMemorySize設定,如果不指定,默認與堆的最大值-Xmx引數值一致
執行引擎(Execution Engine)
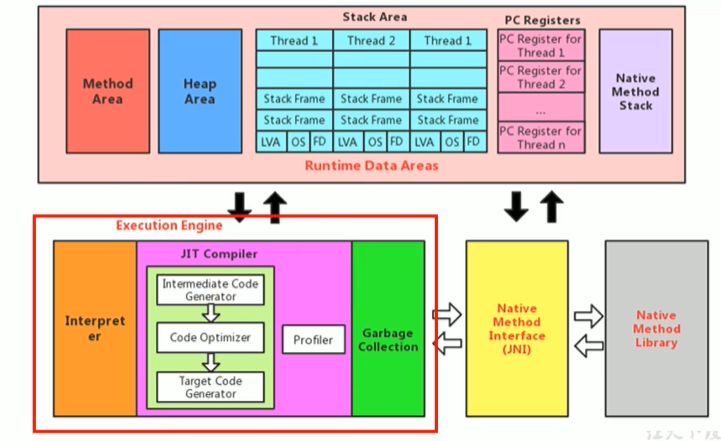
執行引擎是Java虛擬機核心的組成部分之一,
“虛擬機”是一個相對于“物理機”的概念,這兩種機器都有代碼執行能力,其區別是物理機的執行引擎是直接建立在處理器、快取、指令集和作業系統層面上的,而虛擬機的執行引擎則是由軟體自行實作的,因此可以不受物理條件制約地定制指令集與執行引擎的結構體系,能夠執行那些不被硬體直接支持的指令集格式,
JVM的主要任務是負責裝載位元組碼到其內部,但位元組碼并不能夠直接運行在作業系統之,上,因為位元組碼指令并非等價于本地機器指令,它內部包含的僅僅只是一些能夠被JVM所識別的位元組碼指令、符號表,以及其他輔助資訊,
那么,如果想要讓一個Java程式運行起來,執行引擎(Execution Engine)的任務就是將位元組碼指令解釋/編譯為對應平臺上的本地機器指令才可以,簡單來說,JVM中的執行引擎充當了將高級語言翻譯為機器語言的譯者,
執行 引擎在執行的程序中究竟需要執行什么樣的位元組碼指令完全依賴于PC暫存器,
每當執行完一項指令操作后,PC暫存器就會更新下一.條需要被執行的指令地址,
當然方法在執行的程序中,執行引擎有可能會通過存盤在區域變數表中的物件參考準確定位到存盤在Java堆區中的物件實體資訊,以及通過物件頭中的元資料指標定位到目標物件的型別資訊,
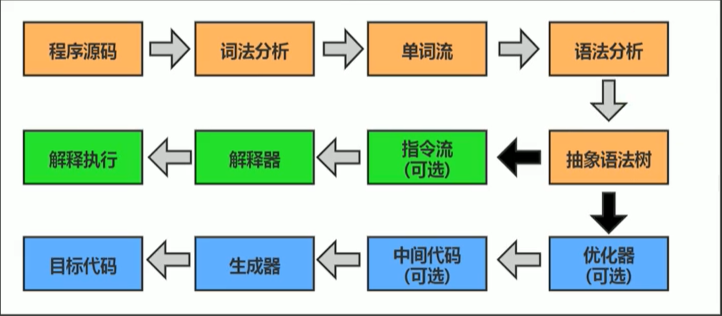
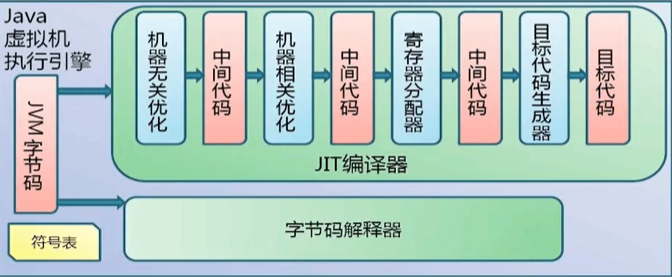
為什么說java是半解釋型半半編譯型語言?
其實就是因為java的執行引擎既有解釋器又有編譯器,
解釋器
JVM設計者們的初衷僅僅只是單純地為了滿足Java程式實作跨平臺特性,因此避免采用靜態編譯的方式直接生成本地機器指令,從而誕生了實作解釋器在運行時采用逐行解釋位元組碼執行程式的想法,
解釋器真正意義上所承擔的角色就是一一個運行時“翻譯者”,將位元組碼檔案中的內容“翻譯”為對應平臺的本地機器指令執行,
當一條位元組碼指令被解釋執行完成后,接著再根據PC暫存器中記錄的下一條需要被執行的位元組碼指令執行解釋操作,
位元組碼解釋器在執行時通過純軟體代碼模擬位元組碼的執行,效率非常低下,
而模板解釋器將每--條位元組碼和一個模板函式相關聯,模板函式中直接產生這
條位元組碼執行時的機器碼,從而很大程度上提高了解釋器的性能,在HotSpot VM中,解釋器主要由Interpreter模塊 和Code模塊構成,
Interpreter模塊:實作了解釋器的核心功能
Code模塊:用于管理HotSpot VM在運行時生成的本地機器指令
由于解釋器在設計和實作上非常簡單,因此除了Java語言之外,還有許多高級語言同樣也是基于解釋器執行的,比如Python、 Perl、 Ruby等,但是在今天,基于解釋器執行已經淪落為低效的代名詞,并且時常被一些C/C++程式員所調侃,
為了解決這個問題,JVM平臺支持--種叫作即時編譯的技術,即時編譯的目的是避免函式被解釋執行,而是將整個函式體編譯成為機器碼,每次函式執行時,只執行編譯后的機器碼即可,這種方式可以使執行效率大幅度提升,
不過無論如何,基于解釋器的執行模式仍然為中間語言的發展做出了不可磨滅的貢獻,
即時編譯器(JIT)
第一種是將源代碼編譯成位元組碼檔案,然后在運行時通過解釋器將位元組碼檔案轉為機器碼執行
第二種是編譯執行(直接編譯成機器碼),現代虛擬機為了提高執行效率,會使用即時編譯技術(JIT, Just In Time) 將方法編譯成機器碼后再執行
HotSpotVM是目前市面上高性能虛擬機的代表作之一,它采用解釋器與即時編譯器并存的架構,在Java虛擬機運行時候解釋器和即時編譯器能夠相互協作,各自取長補短,盡力去選擇最合適的方式來權衡編譯本地代碼的時間和直接解釋執行代碼的時間,
在今天,Java程式的運行性能早已脫胎換骨,已經達到了可以和C/C++程式一較高下的地步,
有些開發人員會感覺到詫異,既然HotSpot VM中已經內置JIT編譯器了,那么為什么還需要再使用解釋器來“拖累”程式的執行性能呢?比如JRockit VM內部就不包含解釋器位元組碼全部都依靠即時編譯器編譯后執行,
首先明確:
當程式啟動后,解釋器可以馬上發揮作用,省去編譯的時間,立即執行,編譯器要想發揮作用,把代碼編譯成本地代碼,需要一定的執行時間,但編譯為本地代碼后,執行效率高,
所以:
盡管JRockit VM中程式的執行性能會非常高效,但程式在啟動時必然需要花費更長的時間來進行編譯,對于服務端應用來說,啟動時間并非是關注重點,但對于那些看中啟動時間的應用場景而言,或許就需要采用解釋器與即時編譯器并存的架構來換取一-個平衡點,在此模式下,當Java虛擬器啟動時,解釋器可以首先發揮作用,而不必等待即時編譯器全部編譯完成后再執行,這樣可以省去許多不必要的編譯時間,隨著時間的推移,編譯器發揮作用,把越來越多的代碼編譯成本地代碼,獲得更高的執行效率,
同時,解釋執行在編譯器進行激進優化不成立的時候,作為編譯器的“逃生門”,
當虛擬機啟動的時候,解釋器可以首先發揮作用,而不必等待即時編譯器全部編譯完成再執行,這樣可以省去許多不必要的編譯時間,并且隨著程式運行時間的推移,即時編譯器逐漸發揮作用,根據熱點探測功能,將有價值的位元組碼編譯為本地機器指令,以換取更高的程式執行效率,
注意解釋執行與編譯執行在線上環境微妙的辯證關系,機器在熱機狀態可以承受的負載要大于冷機狀態,如果以熱機狀態時的流量進行切流,可能使處于冷機狀態的服務器因無法承載流量而假死,
在生產環境發布程序中,以分批的方式進行發布,根據機器數量劃分成多個批次,每個批次的機器數至多占到整個集群的1/8.曾經有這樣的故障案例:某程式員在發布平臺進行分批發布,在輸入發布總批數時,誤填寫成分為兩批發布,如果是熱機狀態,在正常情況下一半的機器可以勉強承載流量,但由于剛啟動的JVM均是解釋執行,還沒有進行熱點代碼統計和JIT動態編譯,導致機器啟動之后,當前1/2發布成功的服務器馬上全部宕機,此故障說明了JIT的存在,-阿里團隊
熱點代碼以及探測方式
一個被多次呼叫的方法,或者是一一個方法體內部回圈次數較多的回圈體都可以被稱之為“熱點代碼”,因此都可以通過JIT編譯器編譯為本地機器指令,由于這種編譯方式發生在方法的執行程序中,因此也被稱之為堆疊上替換,或簡稱為OSR (On Stack Replacement)編譯,
一個方法究竟要被呼叫多少次,或者-一個回圈體究竟需要執行多少次回圈才可以達到這個標準?必然需要一個明確的閾值,JIT編譯器才會將這些“熱點代碼”編譯為本地機器指令執行,這里主要依靠熱點探測功能,
目前HotSpot VM所采用的熱點探測方式是基于計數器的熱點探測,采用基于計數器的熱點探測,HotSpot VM將會為每一個方 法都建立2個不同型別的計數器,分別為方法呼叫計數器(Invocation Counter) 和回邊計數器(Back Edge Counter),
方法呼叫計數器用于統計方法的呼叫次數
回邊計數器則用于統計回圈體執行的回圈次數
1.方法呼叫計數器
這個計數器就用于統計方法被呼叫的次數,它的默認閾值在Client模式下是1500次,在Server 模式下是10000 次,超過這個閾值,就會觸發JIT編譯,
這個閥值可以通過虛擬機引數- XX: CompileThreshold來人為設定,
當一個方法被呼叫時,會先檢查該方法是否存在被JIT 編譯過的版本,如果存在,則優先使用編譯后的本地代碼來執行,如果不存在已被編譯過的版本,則將此方法的呼叫計數器值加1, 然后判斷方法呼叫計數器與回邊計數器值之和是否超過方法呼叫計數器的閾值,如果已超過閾值,那么將會向即時編譯器提交一個該方法的代碼編譯請求,
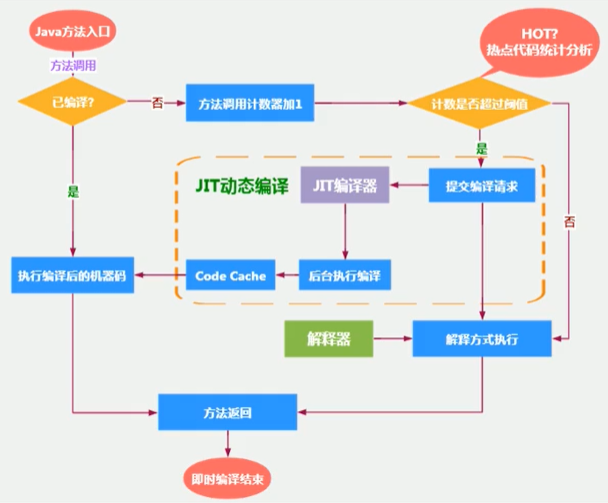
如果不做任何設定,方法呼叫計數器統計的并不是方法被呼叫的絕對次數,而是一個相對的執行頻率,即一段時間之內方法被呼叫的次數,當超過一定的時間限度, 如果方法的呼叫次數仍然不足以讓它提交給即時編譯器編譯,那這個方法的呼叫計數器就會被減少一半,這個程序稱為方法呼叫計數器熱度的衰減(Counter Decay) ,而這段時間就稱為此方法統計的半衰周期(Counter Half Life Time)
進行熱度衰減的動作是在虛擬機進行垃圾收集時順便進行的,可以使用虛擬機引數-XX:-UseCounterDecay來關閉熱度衰減,讓方法計數器統計方法呼叫的絕對次數,這樣,只要系統運行時間足夠長,絕大部分方法都會被編譯成本地代碼,
另外,可以使用-XX:CounterHalfLifeTime 引數設定半衰周期的時間,單位是秒,
2.回邊計數器
它的作用是統計一個方法中回圈體代碼執行的次數,在位元組碼中遇到控制流向后跳轉的指令稱為“回邊” (Back Edge),顯然,建立回邊計數器統計的目的就是為了觸發OSR編譯,
Hostspot VM可以設定程式的執行方式
預設情況下HotSpot VM是采用解釋器與即時編譯器并存的架構,當然開發人員可以根據具體的應用場景,通過命令顯式地為Java虛擬機指定在運行時到底是完全采用解釋器執行,還是完全采用即時編譯器執行,如下所示:
-Xint: 完全采用解釋器模式執行程式;(cmd中:java -Xint -verson 或者VM options中設定)
-Xcomp: 完全采用即時編譯器模式執行程式,如果即時編譯出現問題,解釋器會介入執行,
-Xmixed: 采用解釋器+即時編譯器的混合模式共同執行程式,
在HotSpot VM中內嵌有兩個JIT編譯器,分別為Client Compiler和ServerCompiler,但大多數情況下我們簡稱為C1編譯器和C2編譯器,開發人員可以通過如下命令顯式指定Java虛擬機在運行時到底使用哪一種即時編譯器,在64位系統中默認使用c2編譯器,如下所示:
client:指定Java虛擬機運行在Client模式下,并使用C1編譯器;
C1編譯器會對位元組碼進行簡單和可靠的優化,耗時短,以達到更快的編譯速度,
server:指定Java,虛擬機運行在Server模式下,并使用C2編譯器,
C2進行耗時較長的優化,以及激進優化,但優化的代碼執行效率更高,
C1和C2編譯器不同的優化策略:
在不同的編譯器上有不同的優化策略,C1編譯器上主要有方法行內,去虛擬化、冗余消除,
方法行內:將參考的函式代碼編譯到參考點處,這樣可以減少堆疊幀的生成,減少引數傳遞以及跳轉程序
去虛擬化:對唯一的實作類進行行內
冗余消除:在運行期間把一些不會 執行的代碼折疊掉
C2的優化主要是在全域層面,逃逸分析是優化的基礎,基于逃逸分析在C2.上有如下幾種優化:
標量替換:用標量值代替聚合物件的屬性值
堆疊上分配:對于未逃逸的物件分配物件在堆疊而不是堆
同步消除:清除同步操作,通常指synchronized
分層編譯(Tiered Compilation) 策略:程式解釋執行(不開啟性能監控)可以觸發C1編譯,將位元組碼編譯成機器碼,可以進行簡單優化,也可以加上性能監控,C2編譯會根據性能監控資訊進行激進優化,不過在Java7版本之后,一旦開發人員在程式中顯式指定命令“-server”時,默認將會開啟分層編譯策略,由C1編譯器和C2編譯器相互協作共同來執行編譯任務,
自JDK10起,HotSpot又 加入-一個全新的即時編譯器: Graal編譯 器編譯效果短短幾年時間就追評了C2編譯器,未來可期,目前,帶著“實驗狀態"標簽,需要使用開關引數-XX: +UnlockExper imentalVMOptions -XX: +UseJVMCICompiler去激活,才可以使用,
String的不可變性
String:字串,使用一對""引起來表示,
String s1 = "hello";//字面量的定義方式
String s2 = new String ("hello") ;
String聲 明為final的,不可被繼承String實作了Serializable介面:表示字串是支持序列化的,
實作了Comparable介面:表示String可以比較大小
String在jdk8及以前內部定義了final char[ ] value用于存盤字串資料,jdk9時改為byte[ ]
String:代表不可變的字符序列,簡稱:不可變性,
當對字串重新賦值時,需要重寫指定記憶體區域賦值,不能使用原有的value進行賦值,
當對現有的字串進行連接操作時,也需要重新指定記憶體區域賦值,不能使用原有的value進行賦值,
當呼叫String的replace ()方法修改指定字符或字串時,也需要重新指定記憶體區域賦值,不能使用原有的value進行賦值,通過字面量的方式(區別于new)給-一個字串賦值,此時的字串值宣告在字串常量池中,
字串常量池中是不會存盤相同內容的字串的,
String的String Pool1是一 個固定大小的Hashtable,默認值大小長度是1009,如果放進String Poo1的String非常多, 就會造成Hash沖突嚴重,從而導致鏈表會很長,而鏈表長了后直接會造成的影響就是當呼叫string. intern時性能會大幅下降,
使用-XX:StringTableSi ze可設定StringTable的長度
在jdk6中stringTable是固定的,就是1009的長度,所以如果常量池中的字串過多就會導致效率下降很快,StringTableSize 設定沒有要求
在jdk7中,StringTable的長度默認值是60013
在jdk8中,StringTable1009是可設定的最小值,
String的記憶體分配
在Java語言中有8種基本資料型別和一種比較特殊的型別String,這些型別為了使它們在運行程序中速度更快、更節省記憶體,都提供了-種常量池的概念,
常量池就類似一個Java系統級別提供的快取,8種基本資料型別的常量池都是系統協調的,String類 型的常量池比較特殊,它的主要使用方法有兩種,
直接使用雙引號宣告出來的String物件會直接存盤在常量池中,
比如: String info = "atguigu. com";
如果不是用雙引號宣告的String物件,可以使用String提供的intern()方法,這個后面重點談
在jdk7之前,字串常量池是在永久代中的,jdk8之后都將其存放在堆空間
StringTable為什么要調整?
permSize默認比較小
永久代垃圾回收頻率低
字串拼接操作
常量與常量的拼接結果在常量池,原理是編譯期優化
常量池中不會存在相同內容的常量,
只要其中有一一個是變數,結果就在堆中(非字串常量池),變數拼接的原理是str ingBui lder
如果拼接的結果呼叫intern()方法,則主動將常量池中還沒有的字串物件放入池中,并回傳此物件地址,
如下的s1 + s2的執行細節: (變數s是臨時定義的)
①StringBuilder s = new StringBuilder();
②s.append("a");
③s.append("b") ;
④s.tostring() --> 約等于new string("ab");
補充:在jdk5. 0之后使用的是stringBuilder,在jdk5. 0之前使用的是StringBuffer
字串拼接操作不一定使用的是stringBuilder,如果拼接符號左右兩邊都是字串常量或常量參考,則仍然使用編譯期優化,即非stringBuilder的方式,
改進的空間:在實際開發中,如果基本確定要前前后后添加的字串長度不高于某個限定值highLevel的情況下,建議使用StringBuilder的構造器:
StringBuilder s = new stringBuilder(highLevel);//new char[highLevel]
intern()的使用
如果不是用雙引號宣告的String物件,可以使用str ing提供的intern方法: intern方法會從字串常量池中查詢當前字串是否存在,若不存在就會將當前字串放入常量池中,
比如: String myInfo = new String("I love atguigu") .intern() ;
也就是說,如果在任意字串上呼叫String. intern方法,那么其回傳結果所指向的那個類實體,必須和直接以常量形式出現的字串實體完全相同,因此,下列運算式的值必定是true:
("a" + "b" + "c") . intern() == "abc"
通俗點講,Interned string就 是確保字串在記憶體里只有一'份拷貝,這樣可以節約記憶體空間,加快字串操作任務的執行速度,注意,這個值會被存放在字串內部池 (String Intern Pool),
new String( "ab")會創建幾個物件?
看位元組碼,就知道是兩個,
一個物件是: new關鍵字在堆空間創建的
另一個物件是:字串常量池中的物件,
位元組碼指令:ldc
new String("a")+new Sting("b")會創建幾個物件?
0 new #2 <java/lang/StringBuilder>//第一個物件,new StringBulder()
3 dup
4 invokespecial #3 <java/lang/StringBuilder.<init>>
7 new #4 <java/lang/String>//第二個物件,new String("a")
10 dup
11 ldc #5 <a>//第三個物件 字串常量池中新建的"a"
13 invokespecial #6 <java/lang/String.<init>>
16 invokevirtual #7 <java/lang/StringBuilder.append>
19 new #4 <java/lang/String>//第四個物件,new String("b")
22 dup
23 ldc #8 <b>//第五個物件,字串常量池中的"b"
25 invokespecial #6 <java/lang/String.<init>>
28 invokevirtual #7 <java/lang/StringBuilder.append>
31 invokevirtual #9 <java/lang/StringBuilder.toString>//深入剖析toString,回傳一個new String,第六個物件.注意,位元組碼中沒有使用ldc,所以字串常量池中沒有"ab"
34 astore_1
35 return
關于intern()的難題
public void mian(String args[]){
String s1 = new String("1");
s.intern();
String s2 = "1"
System.out.println(s1==s2);//false
String s3 = new String("1")+new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3==s4);//jdk6中為false,jdk7以后為true
}
詳見視頻P127&P128
總結String的intern()的使用:
jdk1.6中,將這個字串物件嘗試放入串池,
如果串池中有,則并不會放入,回傳已有的串池中的物件的地址
如果沒有,會把此物件復制一份,放入串池,并回傳串池中的物件地址Jdk1.7起,將這個字串物件嘗試放入串池,
如果串池中有,則并不會放入,回傳已有的串池中的物件的地址
如果沒有,則會把物件的參考地址復制一份,放入串池,并回傳串池中的參考地址
PS:new String()在字串常量池中存放的是物體,不是new String()地址的參考,所以new String物件的地址與其在常量池中存放的地址不相等;intern在字串常量池中存放的是其堆地址的參考,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/163616.html
標籤:Java
下一篇:SQL--資料庫的設計(范式)