Stream API
經過前面 4 篇內容的學習,我們已經掌握了 Stream 大部分的知識,本節我們針對之前 Stream 未涉及的內容及周邊知識點做個補充,
Fork/Join 框架
fork/join 框架是 Java 7 中引入的新特性 ,它是一個工具,通過 「 分而治之 」 的方法嘗試將所有可用的處理器內核使用起來幫助加速并行處理,
在實際使用程序中,這種 「 分而治之 」的方法意味著框架首先要 fork ,遞回地將任務分解為較小的獨立子任務,直到它們足夠簡單以便異步執行,然后,join 部分開始作業,將所有子任務的結果遞回地連接成單個結果,或者在回傳 void 的任務的情況下,程式只是等待每個子任務執行完畢,
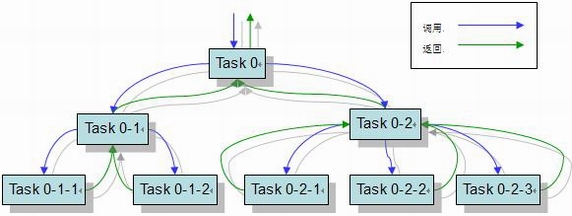
為了提供有效的并行執行,fork/join 框架使用了一個名為 ForkJoinPool 的執行緒池,用于管理 ForkJoinWorkerThread 型別的作業執行緒,
Fork/Join 優點
Fork/Join 架構使用了一種名為作業竊取( work-stealing )演算法來平衡執行緒的作業負載,
簡單來說,作業竊取演算法就是空閑的執行緒試圖從繁忙執行緒的佇列中竊取作業,
默認情況下,每個作業執行緒從其自己的雙端佇列中獲取任務,但如果自己的雙端佇列中的任務已經執行完畢,雙端佇列為空時,作業執行緒就會從另一個忙執行緒的雙端佇列尾部或全域入口佇列中獲取任務,因為這是最大概率可能找到作業的地方,
這種方法最大限度地減少了執行緒競爭任務的可能性,它還減少了作業執行緒尋找任務的次數,因為它首先在最大可用的作業塊上作業,
Fork/Join 使用
ForkJoinTask 是 ForkJoinPool 執行緒之中執行的任務的基本型別,我們日常使用時,一般不直接使用 ForkJoinTask ,而是擴展它的兩個子類中的任意一個
- 任務不回傳結果 ( 回傳 void ) 的 RecursiveAction
- 回傳值的任務的 RecursiveTask
這兩個類都有一個抽象方法 compute() ,用于定義任務的邏輯,
我們所要做的,就是繼承任意一個類,然后實作 compute() 方法,步驟如下:
- 創建一個表示作業總量的物件
- 選擇合適的閾值
- 定義分割作業的方法
- 定義執行作業的方法
如下是使用 Fork/Join 方式實作的1至1000006587的 Fork/Join 方式累加,我們和單執行緒的回圈累加做了下對比,在 Intel i5-4460 的 PC 機器下,單執行緒執行使用了 650 ms,使用了 Fork/Join 方式執行 210 ms,優化效果挺明顯,
public class NumberAddTask extends RecursiveTask<Long> {
private static final int THRESHOLD = 10_0000;
private final int begin;
private final int end;
public NumberAddTask(int begin, int end) {
super();
this.begin = begin;
this.end = end;
}
@Override
protected Long compute() {
if (end - begin <= THRESHOLD) {
long sum = 0;
for(int i = begin; i <= end; i++) {
sum += i;
}
return sum;
}
int mid = (begin + end) /2;
NumberAddTask t1 = new NumberAddTask(begin, mid);
NumberAddTask t2 = new NumberAddTask(mid + 1, end);
ForkJoinTask.invokeAll(t1, t2);
return t1.join() + t2.join();
}
}
// 1至1000006587的Fork/Join方式累加
@Test
public void testAddForkJoin() {
long begin = System.currentTimeMillis();
int n = 10_0000_6587;
ForkJoinPool pool = ForkJoinPool.commonPool();
log.info("1 + 2 + ... {} = {}", n, pool.invoke(new NumberAddTask(1, n)));
long end = System.currentTimeMillis();
log.info("ForkJoin方式執行時間:{}ms", end - begin);
}
// 1至1000006587的單執行緒累加
@Test
public void testAddFunction() {
long begin = System.currentTimeMillis();
int n = 10_0000_6587;
long sum = 0;
for(int i = 1; i <= n; i++ ) {
sum += i;
}
log.info("1 + 2 + ... {} = {}", n, sum);
long end = System.currentTimeMillis();
log.info("函式方式執行時間:{}ms", end - begin);
}
Fork/Join 使用場景
我使用 Java 8 官方 Api 中 RecursiveTask 的示例,創建了一個計算斐波那契數列的 Fork/Join 實作,雖然官方也提到了這是愚蠢的實作斐波那契數列方法,甚至效果還不如單執行緒的遞回計算,但是這也說明了 Fork/Join 并非萬能的,
@Test
public void testForkJoin() {
// 執行f(40) = 102334155使用3411ms
// 執行f(80) 2個多小時,無法計算出結果
long begin = System.currentTimeMillis();
int n = 40;
ForkJoinPool pool = ForkJoinPool.commonPool();
log.info("ForkJoinPool初始化時間:{}ms", System.currentTimeMillis() - begin);
log.info("斐波那契數列f({}) = {}", n, pool.invoke(new FibonacciTask(n)));
long end = System.currentTimeMillis();
log.info("ForkJoin方式執行時間:{}ms", end - begin);
}
// 不用遞回計算斐波那契數列反而更快
@Test
public void testFibonacci() {
// 執行f(50000) 使用 110ms
// 輸出 f(50000) = 17438開頭的10450位長的整數
long begin = System.currentTimeMillis();
int n = 50000;
log.info("斐波那契數列f({}) = {}", n, FibonacciUtil.fibonacci(n));
long end = System.currentTimeMillis();
log.info("函式方式執行時間:{}ms", end - begin);
}
以上代碼見 StreamOtherTest ,
Fork/Join 最大的優點是提供了作業竊取演算法,可以在多核CPU處理器上加速并行處理,他并非多執行緒開發替代品,
那么他們之間有什么區別呢?
Fork/Join框架是從jdk7中新特性,它同ThreadPoolExecutor一樣,也實作了Executor和ExecutorService介面,它使用了一個無限佇列來保存需要執行的任務,而執行緒的數量則是通過建構式傳入,如果沒有向建構式中傳入希望的執行緒數量,那么當前計算機可用的CPU數量會被設定為執行緒數量作為默認值,
ForkJoinPool主要用來使用分治法(Divide-and-Conquer Algorithm)來解決問題,典型的應用比如快速排序演算法,這里的要點在于,ForkJoinPool需要使用相對少的執行緒來處理大量的任務,比如要對1000萬個資料進行排序,那么會將這個任務分割成兩個500萬的排序任務和一個針對這兩組500萬資料的合并任務,以此類推,對于500萬的資料也會做出同樣的分割處理,到最后會設定一個閾值來規定當資料規模到多少時,停止這樣的分割處理,比如,當元素的數量小于10時,會停止分割,轉而使用插入排序對它們進行排序,那么到最后,所有的任務加起來會有大概2000000+個,問題的關鍵在于,對于一個任務而言,只有當它所有的子任務完成之后,它才能夠被執行,
所以當使用ThreadPoolExecutor時,使用分治法會存在問題,因為ThreadPoolExecutor中的執行緒無法像任務佇列中再添加一個任務并且在等待該任務完成之后再繼續執行,而使用ForkJoinPool時,就能夠讓其中的執行緒創建新的任務,并掛起當前的任務,此時執行緒就能夠從佇列中選擇子任務執行,
那么使用ThreadPoolExecutor或者ForkJoinPool,會有什么差異呢?
首先,使用ForkJoinPool能夠使用數量有限的執行緒來完成非常多的具有父子關系的任務,比如使用4個執行緒來完成超過200萬個任務,但是,使用ThreadPoolExecutor時,是不可能完成的,因為ThreadPoolExecutor中的Thread無法選擇優先執行子任務,需要完成200萬個具有父子關系的任務時,也需要200萬個執行緒,顯然這是不可行的,
在實踐中,ThreadPoolExecutor通常用于同時(并行)處理許多獨立請求(又稱為事務),Fork/Join通常用于加速一項連貫的作業任務,
parallelStream 并行化
parallelStream 其實就是一個并行執行的流.它通過默認的 ForkJoinPool ,可以提高你的多執行緒任務的速度,parallelStream 具有并行處理能力,處理的程序會分而治之,也就是將一個大任務切分成多個小任務,這表示每個任務都是一個操作,可以并行處理,
parallelStream 的使用
使用方式:
- 創建時回傳并行流:如 Collection
.parallelStream() - 程序中轉換為并行流:如 Stream
.parallel() - 如果需要,轉換為順序流:Stream
.sequential()
// 并行流時,并非按照1,2,3...500的順序輸出
IntStream.range(1, 500).parallel().forEach(System.out::println);
parallelStream 的陷阱
由于 parallelStream 使用的是 ForkJoinPool 中的 commonPool,該方法默認創建程式運行時所在計算機處理器內核數量的執行緒,當同時存在多個作業并行執行時,ForkJoinPool 中的執行緒將被消耗完,而當有的worker因為執行耗時操作,將導致其他作業也被阻塞,而此時我們也不清楚哪個任務導致了阻塞,這就是 parallelStream 的陷阱,
parallelStream 是無法預測的,而且想要正確地使用它有些棘手,幾乎任何 parallelStream 的使用都會影響程式中其他部分的性能,而且是一種無法預測的方式,但是在呼叫stream.parallel() 或者 parallelStream() 時候在我的代碼里之前我仍然會重新審視一遍他給我的程式究竟會帶來什么問題,他能有多大的提升,是否有使用他的意義,
那么到底是使用 stream 還是 parallelStream 呢?通過下面3個標準來鑒定
1. 是否需要并行?
在回答這個問題之前,你需要弄清楚你要解決的問題是什么,資料量有多大,計算的特點是什么?并不是所有的問題都適合使用并發程式來求解,比如當資料量不大時,順序執行往往比并行執行更快,畢竟,準備執行緒池和其它相關資源也是需要時間的,但是,當任務涉及到I/O操作并且任務之間不互相依賴時,那么并行化就是一個不錯的選擇,通常而言,將這類程式并行化之后,執行速度會提升好幾個等級,
2. 任務之間是否是獨立的?是否會引起任何競態條件?
如果任務之間是獨立的,并且代碼中不涉及到對同一個物件的某個狀態或者某個變數的更新操作,那么就表明代碼是可以被并行化的,
3. 結果是否取決于任務的呼叫順序?
由于在并行環境中任務的執行順序是不確定的,因此對于依賴于順序的任務而言,并行化也許不能給出正確的結果,
創建流的其他方式
我們在第1篇中記錄了幾種創建流的方式,但還是遺漏了一部分,再此稍作補充,
從I/O通道
方式1:從快取流中讀取為Stream,詳見如下代碼:
final String name = "明玉";
// 從網路上讀取文字內容
new BufferedReader(
new InputStreamReader(
new URL("https://www.txtxzz.com/txt/download/NWJhZjI3YjIzYWQ3N2UwMTZiNDQwYWE3")
// new URL("https://api.apiopen.top/getAllUrl")
.openStream()))
.lines()
.filter(str -> StrUtil.contains(str, name))
.forEach(System.out::println);
方式2:從檔案系統獲取下級路徑及檔案,詳見如下代碼:
// 獲取檔案系統的下級路徑及其檔案
Files.walk(FileSystems.getDefault().getPath("D:\\soft"))
.forEach(System.out::println);
方式3:從檔案系統獲取檔案內容,詳見如下代碼:
Files.lines(FileSystems.getDefault().getPath("D:\\", "a.txt"))
// .parallel()
.limit(200)
.forEach(System.out::println);
方式4:讀取JarFile內的檔案,詳見如下代碼:
new JarFile("D:\\J2EE_Tools\\repository\\org\\springframework\\spring-core\\5.2.6.RELEASE\\spring-core-5.2.6.RELEASE.jar")
.stream()
.filter(entry -> StrUtil.contains(entry.getName(), "Method"))
.forEach(System.out::println);
獲取亂數字流
使用類Random的ints、longs、doubles的方法,根據傳遞不同的引數,可以產生無限數字流、有限數字流、以及指定范圍的有限或無限數字流,示例如下:
double v = new Random()
.doubles(30, 2, 45)
.peek(System.out::println)
.max()
.getAsDouble();
log.info("一串亂數的最大值為:{}", v);
位向量流
將BitSet中位向量為真的轉換為Stream,示例如下:
BitSet bitSet = new BitSet(8);
bitSet.set(1);
bitSet.set(6);
log.info("cardinality值{}", bitSet.cardinality());
bitSet.stream().forEach(System.out::println);
正則分割流
將字串按照正則運算式分隔成子串流,示例如下:
Pattern.compile(":")
.splitAsStream("boo:and:foo")
.map(String::toUpperCase)
.forEach(System.out::println);
Stream 的其他方法
轉為無序流
使用 unordered() 方法可將 Stream 隨時轉為無序流,
轉換為Spliterator
使用 spliterator() 方法可將 Stream 轉為 Spliterator,Spliterator 介紹請看 https://juejin.im/post/5cf2622de51d4550bf1ae7ff,
綜合示例
根據1962年第1屆百花獎至2018年第34屆百花獎資料,有以下資料,撰寫代碼按斬訓得最佳男主角的演員次數排名,次數相同的按照參演年份正序排,并列印他所參演的電影,
| 序號 | 最佳男主角 | 電影 |
|---|---|---|
| 第1屆1962年 | 崔嵬 | 《紅旗譜》 |
| 第2屆1963年 | 張良 | 《哥倆好 |
| 第3屆1980年 | 李仁堂 | 《淚痕》 |
| 第4屆1981年 | 達式常 | 《燕歸來》 |
| 第5屆1982年 | 王心剛 | 《知音》 |
| 第6屆1983年 | 嚴順開 | 《阿Q正傳》 |
| 第7屆1984年 | 楊在葆 | 《血,總是熱的》 |
| 第8屆1985年 | 呂曉禾 | 《高山下的花環》 |
| 第9屆1986年 | 楊在葆 | 《代理市長》 |
| 第10屆1987年 | 姜文 | 《芙蓉鎮》 |
| 第11屆1988年 | 張藝謀 | 《老井》 |
| 第12屆1989年 | 姜文 | 《春桃》 |
| 第13屆1990年 | 古月 | 《開國大典》 |
| 第14屆1991年 | 李雪健 | 《焦裕祿》 |
| 第15屆1992年 | 王鐵成 | 《周恩來》 |
| 第16屆1993年 | 古月 | 《毛ze東的故事》 |
| 第17屆1994年 | 李保田 | 《鳳凰琴》 |
| 第18屆1995年 | 李仁堂 | 《被告山杠爺》 |
| 第19屆1996年 | 張國立 | 《混在北京》 |
| 第20屆1997年 | 高明 | 《孔繁森》 |
| 第21屆1998年 | 葛優 | 《甲方乙方》 |
| 第22屆1999年 | 趙本山 | 《男婦女主任》 |
| 第23屆2000年 | 潘長江 | 《明天我愛你》 |
| 第24屆2001年 | 王慶祥 | 《生死抉擇》 |
| 第25屆2002年 | 葛優 | 《大腕》 |
| 第26屆2003年 | 盧奇 | 《鄧小平》 |
| 第27屆2004年 | 葛優 | 《手機》 |
| 第27屆2004年 | 李幼斌 | 《驚心動魂》 |
| 第28屆2006年 | 吳軍 | 《張思德》 |
| 第29屆2008年 | 張涵予 | 《集結號》 |
| 第30屆2010年 | 陳坤 | 《畫皮》 |
| 第31屆2012年 | 文章 | 《失戀33天》 |
| 第32屆2014年 | 黃曉明 | 《中國合伙人》 |
| 第33屆2016年 | 馮紹峰 | 《狼圖騰》 |
| 第34屆2018年 | 吳京 | 《戰狼2》 |
根據題目要求,創建 HundredFlowersAwards 物體用來存盤上述資料,我們分析題目要求最終需要轉換為以演員為主的資訊,然后再根據演員的獲獎次數及出演年份做排序,
所以創建 ActorInfo 物體,包含 演員姓名和出演電影的資訊,出演電影也需創建物體 FilmInfo ,包含 出演年份和電影名稱,
有了如上存盤資料物體資訊后,代碼實作邏輯如下:
- 將百花獎的集合資料轉換為 Stream
- 將該資料流轉換為Map型別,Map 的 key 為演員名,Map 的 Value 為演員資訊
- 對于重復出現的演員,我們需要把電影資訊追加到該演員出現的電影串列中
- 對于處理完的 Map 資料,將該 Map 的 values 資料再次轉換為 Stream
- 將該 Stream 排序即可,
list.stream()
.collect(Collectors.toMap(HundredFlowersAwards::getActorName, ActorInfo::new, ActorInfo::addFilmInfos))
.values()
.stream()
.sorted(new ActorComparator())
.forEach(System.out::println);
本節代碼見 StreamOtherTest ,
經過幾天的學習和總結,以上就是 Java Stream Api 的全部內容了,從開始認識 Stream Api,我們逐漸了解了使用 Stream Api 的流程:創建 Stream 、中間操作、終端操作,
我們對創建 Stream 、中間操作、終端操作的各個 api 方法進行了介紹及案例演示,之后我們還單獨抽出一節講解了 Collector 介面的實作及使用,
上述內容雖然文字不多,大部分都在代碼中給出了演示,希望大家能下載下來代碼并運行,以加深印象,
以上是前傳部分的學習內容了,接下來我們將進入到 Reactor 部分的學習,
原始碼下載:https://github.com/crystalxmumu/spring-web-flux-study-note
參考
- 【Java8新特性】關于Java8的Stream API,看這一篇就夠了{:target="_blank"}
- 一文秒懂 Java Fork/Join{:target="_blank"}
- 深入淺出parallelStream{:target="_blank"}
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/163620.html
標籤:Java
下一篇:SQL--多表查詢(mysql)