1. 問題背景
某核心JAVA長連接服務使用mongodb作為主要存盤,客戶端數百臺機器連接同一mongodb集群,短期內出現多次性能抖動問題,此外,還出現一次“雪崩”故障,同時流量瞬間跌零,無法自動恢復,本文分析這兩次故障的根本原因,包括客戶端配置使用不合理、mongodb內核鏈接認證不合理、代理配置不全等一系列問題,最終經過多方努力確定問題根源,
該集群有十來個業務介面訪問,每個介面部署在數十臺業務服務器上面,訪問該mongodb機器的客戶端總數超過數百臺,部分請求一次拉取數十行甚至百余行資料,
該集群為2機房同城多活集群(選舉節不消耗太多資源,異地的第三機房來部署選舉節點),架構圖如下:
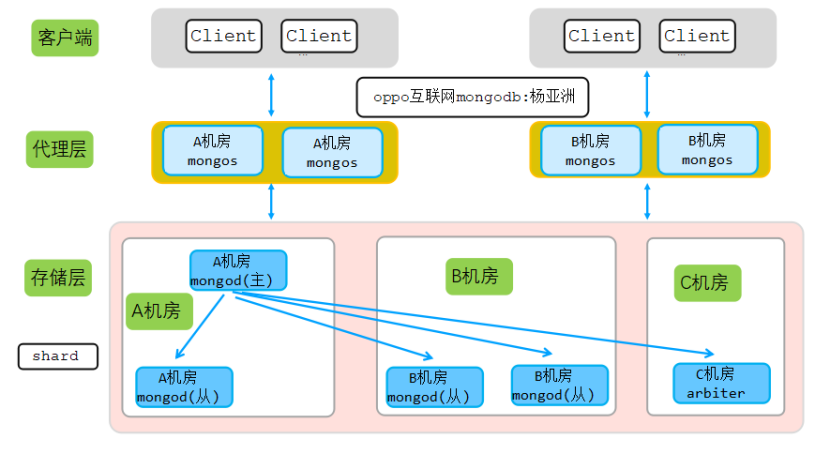
從上圖可以看出,為了實作多活,在每個機房都部署有對應代理,對應機房客戶端鏈接對應機房的mongos代理,每個機房多個代理,代理層部署IP:PORT地址串列(注意:不是真實IP地址)如下:
- A機房代理地址串列:1.1.1.1:111,2.2.2.2:1111,3.3.3.3:1111
- B機房代理地址串列:4.4.4.4:1111,4.4.4.4:2222
A機房三個代理部署在三臺不同物理機,B機房2個代理部署在同一臺物理機,此外,A機房和B機房為同城機房,跨機房訪問時延可以忽略,
集群存盤層和config server都采用同樣的架構:A機房(1主節點+1從節點) + B機房(2從節點)+C機房(1個選舉節點arbiter),即2(資料節點)+2(資料節點)+1(選舉節點)模式,
該機房多活架構可以保證任一機房掛了,對另一機房的業務無影響,具體機房多活原理如下:
- 如果A機房掛掉,由于代理是無狀態節點,A機房掛掉不會影響B機房的代理,
- 如果A機房掛掉,同時主節點在A機房,這時候B機房的2個資料節點和C機房的選舉節點一共三個節點,可以保證新選舉需要大于一半以上節點這個條件,于是B機房的資料節點會在短時間內選舉出一個新的主節點,這樣整個存盤層訪問不受任何影響,
本文重點分析如下6個疑問點:
- 為什么突發流量業務會抖動?
- 為什么資料節點沒有任何慢日志,但是代理負載缺100%?
- 為何mongos代理引起數小時的“雪崩”,并且長時間不可恢復?
- 為何一個機房代理抖動,對應機房業務切到另一個機房后,還是抖動?
- 為何例外時候抓包分析,客戶端頻繁建鏈斷鏈,并且同一個鏈接建鏈到斷鏈間隔很短?
- 理論上代理就是七層轉發,消耗資源更少,相比mongod存盤應該更快,為何mongod存盤節點無任何抖動,mongos代理缺有抖動?
2. 故障程序
2.1 業務偶爾流量高峰,業務抖動?
該集群一段時間內有多次短暫的抖動,當A機房客戶端抖動后,發現A機房對應代理負載很高,于是切換A機房訪問B機房代理,但是切換后B機房代理同樣抖動,也就是多活切換沒有作用,具體程序分析如下,
2.1.1 存盤節點慢日志分析
首先,分析該集群所有mongod存盤節點系統CPU、MEM、IO、load等監控資訊,發現一切正常,于是分析每個mongod節點慢日志(由于該集群對時延敏感,因此慢日志調整為30ms),分析結果如下:



從上圖可以看出,存盤節點在業務抖動的時候沒有任何慢日志,因此可以判斷存盤節點一切正常,業務抖動和mongod存盤節點無關,
2.1.2 Mongos代理分析
存盤節點沒有任何問題,因此開始排查mongos代理節點,由于歷史原因,該集群部署在其他平臺,該平臺對QPS、時延等監控不是很全,造成早期抖動的時候監控沒有及時發現,抖動后,遷移該平臺集群到oppo自研的新管控平臺,新平臺有詳細的監控資訊,遷移后QPS監控曲線如下:
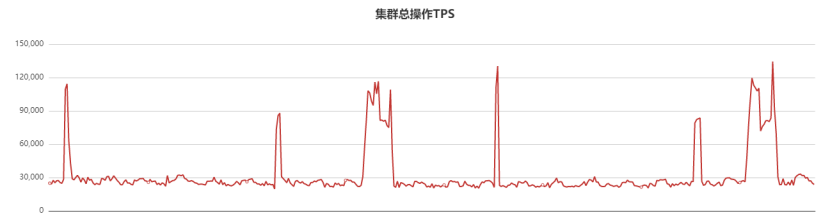
每個流量徒增時間點,對應業務監控都有一波超時或者抖動,如下:

分析對應代理mongos日志,發現如下現象:抖動時間點mongos.log日志有大量的建鏈接和斷鏈接的程序,如下圖所示:

從上圖可以看出,一秒鐘內有幾千個鏈接建立,同時有幾千個鏈接斷開,此外抓包發現很多鏈接短期內即斷開鏈接,現象如下(斷鏈時間-建鏈時間=51ms, 部分100多ms斷開):

對應抓包如下:

此外,該機器代理上客戶端鏈接低峰期都很高,甚至超過正常的QPS值,QPS大約7000-8000,但是conn鏈接缺高達13000,
mongostat獲取到監控資訊如下:

2.1.3 代理機器負載分析
每次突發流量的時候,代理負載很高,通過部署腳本定期采樣,抖動時間點對應監控圖如下圖所示:
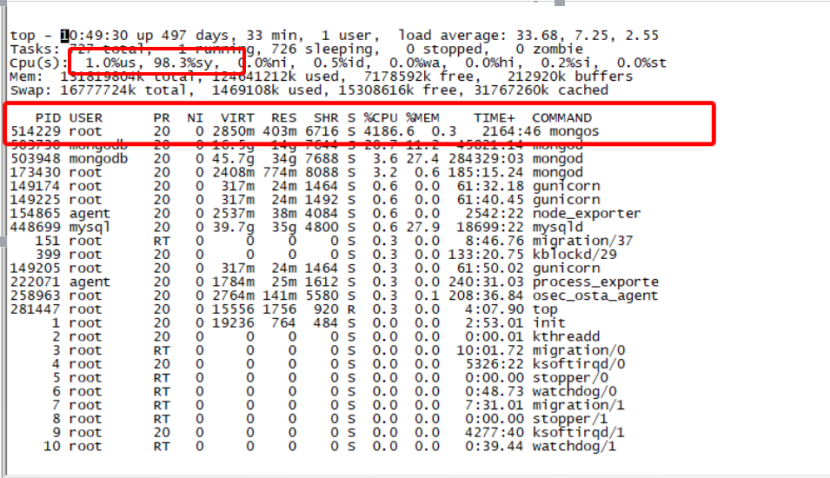

從上圖可以看出,每次流量高峰的時候CPU負載都非常的高,而且是sy%負載,us%負載很低,同時Load甚至高達好幾百,偶爾甚至過千,
2.1.4 抖動分析總結
從上面的分析可以看出,某些時間點業務有突發流量引起系統負載很高,根因真的是因為突發流量嗎?其實不然,請看后續分析,這其實是一個錯誤結論,沒過幾天,同一個集群雪崩了,
于是業務梳理突發流量對應介面,梳理出來后下掉了該介面,QPS監控曲線如下:
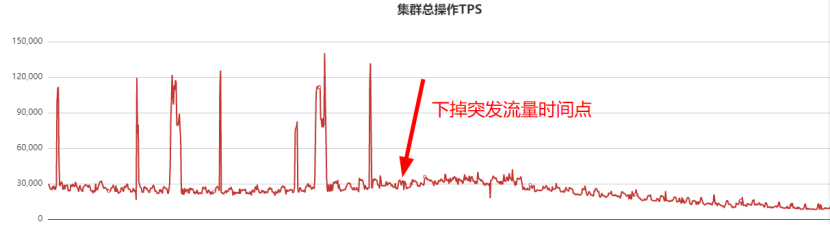
為了減少業務抖動,因此下掉了突發流量介面,此后幾個小時業務不再抖動,當下掉突發流量介面后,我們還做了如下幾件事情:
- 由于沒找到mongos負載100%真正原因,于是每個機房擴容mongs代理,保持每個機房4個代理,同時保證所有代理在不同服務器,通過分流來盡量減少代理負載,
- 通知A機房和B機房的業務配置上所有的8個代理,不再是每個機房只配置對應機房的代理(因為第一次業務抖動后,我們分析mongodb的java sdk,確定sdk均衡策略會自動剔除請求時延高的代理,下次如果某個代理再出問題,也會被自動剔除),
- 通知業務把所有客戶端超時時間提高到500ms,
但是,心里始終有很多疑惑和懸念,主要在以下幾個點:
- 存盤節點4個,代理節點5個,存盤節點無任何抖動 ,反而七層轉發的代理負載高?
- 為何抓包發現很多新連接幾十ms或者一百多ms后就斷開連接了?頻繁建鏈斷鏈?
- 為何代理QPS只有幾萬,這時代理CPU消耗就非常高,而且全是sy%系統負載? 以我多年中間件代理研發經驗,代理消耗的資源很少才對,而且CPU只會消耗us%,而不是sy%消耗,
2.2 同一個業務幾天后”雪崩”了
好景不長,業務下掉突發流量的介面沒過幾天,更嚴重的故障出現了,機房B的業務流量在某一時刻直接跌0了,不是簡單的抖動問題,而是業務直接流量跌0,系統sy%負載100%,業務幾乎100%超時重連,
2.2.1 機器系統監控分析
機器CPU和系統負載監控如下:
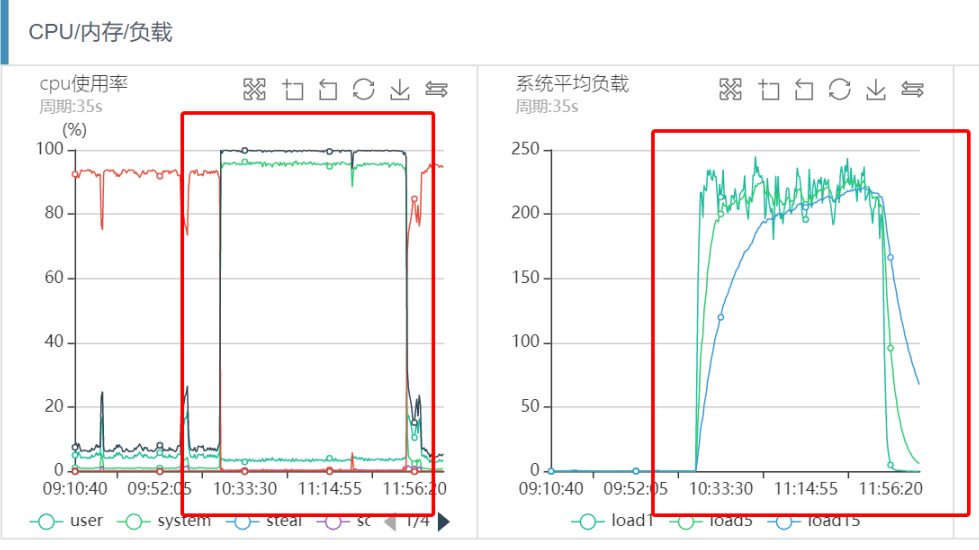
從上圖可以看出,幾乎和前面的突發流量引起的系統負載過高現象一致,業務CPU sy%負載100%,load很高,登陸機器獲取top資訊,現象和監控一致,

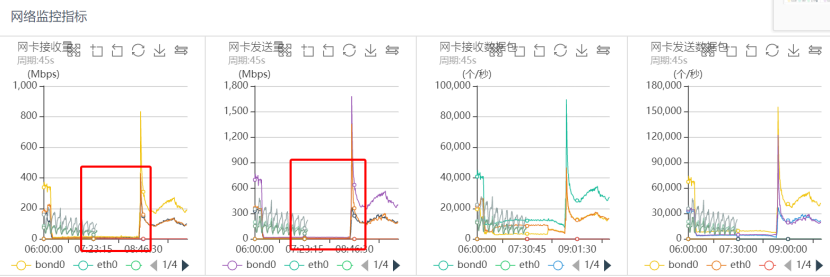
同一時刻對應網路監控如下:
磁盤IO監控如下:
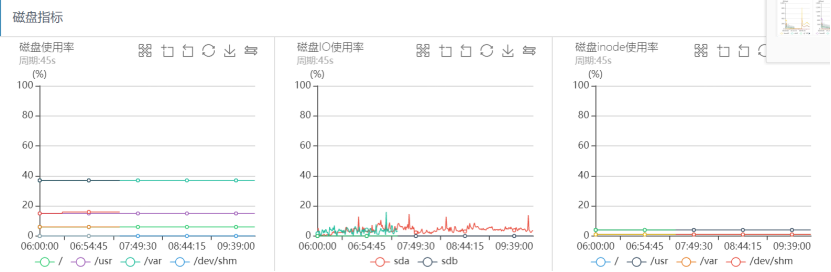
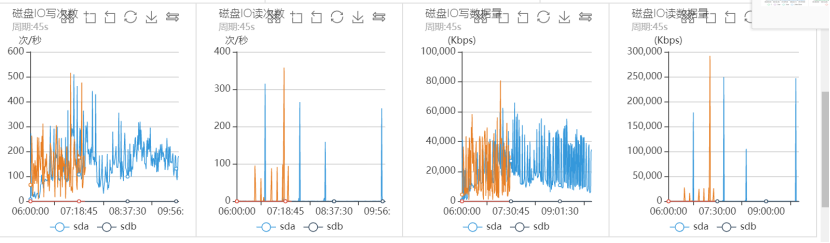
從上面的系統監控分析可以看出,出問題的時間段,系統CPU sy%、load負載都很高,網路讀寫流量幾乎跌0,磁盤IO一切正常,可以看出整個程序幾乎和之前突發流量引起的抖動問題完全一致,
2.2.2 業務如何恢復
第一次突發流量引起的抖動問題后,我們擴容所有的代理到8個,同時通知業務把所有業務介面配置上所有代理,由于業務介面眾多,最終B機房的業務沒有配置全部代理,只配置了原先的兩個處于同一臺物理機的代理(4.4.4.4:1111,4.4.4.4:2222),最終觸發mongodb的一個性能瓶頸(詳見后面分析),引起了整個mongodb集群”雪崩”
最終,業務通過重啟服務,同時把B機房的8個代理同時配置上,問題得以解決,
2.2.3 mongos代理實體監控分析
分析該時間段代理日志,可以看出和2.1同樣得現象,大量的新鍵連接,同時新連接在幾十ms、一百多ms后又關閉連接,整個現象和之前分析一致,這里不在統計分析對應日志,
此外,分析當時的代理QPS監控,正常query讀請求的QPS訪問曲線如下,故障時間段QPS幾乎跌零雪崩了:
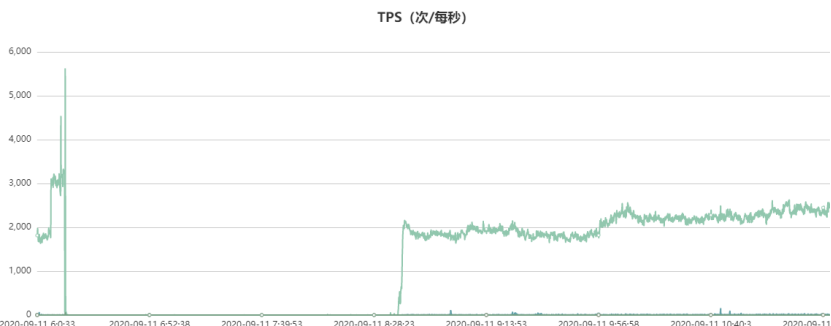
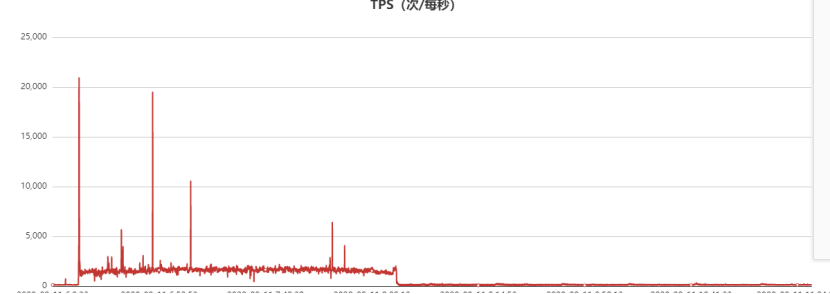
從上面的統計可以看出,當該代理節點的流量故障時間點有一波尖刺,同時該時間點的command統計瞬間飆漲到22000(實際可能更高,因為我們監控采樣周期30s,這里只是平均值),也就是瞬間有2.2萬個連接瞬間進來了,Command統計實際上是db.ismaster()統計,客戶端connect服務端成功后的第一個報文就是ismaster報文,服務端執行db.ismaster()后應答客戶端,客戶端收到后開始正式的sasl認證流程,
正常客戶端訪問流程如下:
- 客戶端發起與mongos的鏈接
- Mongos服務端accept接收鏈接后,鏈接建立成功
- 客戶端發送db.isMaster()命令給服務端
- 服務端應答isMaster給客戶端
- 客戶端發起與mongos代理的sasl認證(多次和mongos互動)
- 客戶端發起正常的find()流程
客戶端SDK鏈接建立成功后發送db.isMaster()給服務端的目的是為了負載均衡策略和判斷節點是什么型別,保證客戶端快速感知到訪問時延高的代理,從而快速剔除往返時延高的節點,同時確定訪問的節點型別,
此外,通過提前部署的腳本,該腳本在系統負載高的時候自動抓包,從抓包分析結果如下圖所示:
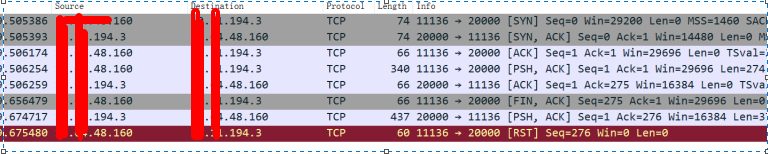
上圖時序分析如下:
- 11:21:59.506174鏈接建立成功
- 11:21:59.506254 客戶端發送db.IsMaster()到服務端
- 11:21:59.656479 客戶端發送FIN斷鏈請求
- 11:21:59.674717 服務端發送db.IsMaster()應答給客戶端
- 11:21:59.675480 客戶端直接RST
第3和第1個報文之間相差大約150ms,最后和業務確定該客戶端IP對應的超時時間配置,確定就是150ms,此外,其他抓包中有類似40ms、100ms等超時配置,通過對應客戶端和業務確認,確定對應客戶端業務介面超時時間配置的就是40ms、100ms等,因此,結合抓包和客戶端配置,可以確定當代理超過指定超時時間還沒有給客戶端db.isMaster()回傳值,則客戶端立馬超時,超時后立馬發起重連請求,
總結:通過抓包和mongos日志分析,可以確定鏈接建立后快速斷開的原因是:客戶端訪問代理的第一個請求db.isMaster()超時了,因此引起客戶端重連,重連后又開始獲取db.isMaster()請求,由于負載CPU 100%, 很高,每次重連后的請求都會超時,其中配置超時時間為500ms的客戶端,由于db.isMaster()不會超時,因此后續會走sasl認證流程,
因此可以看出,系統負載高和反復的建鏈斷鏈有關,某一時刻客戶端大量建立鏈接(2.2W)引起負載高,又因為客戶端超時時間配置不一,超時時間配置得比較大得客戶端最侄訓進入sasl流程,從內核態獲取亂數,引起sy%負載高,sy%負載高又引起客戶端超時,這樣整個訪問程序就成為一個“死回圈”,最終引起mongos代理雪崩,
2.3 線下模擬故障
到這里,我們已經大概確定了問題原因,但是為什么故障突發時間點那一瞬間2萬個請求就會引起sy%負載100%呢,理論上一秒鐘幾萬個鏈接不會引起如此嚴重的問題,畢竟我們機器有40個CPU,因此,分析反復建鏈斷鏈為何引起系統sy%負載100%就成為了本故障的關鍵點,
2.3.1 模擬故障程序
模擬頻繁建鏈斷鏈故障步驟如下:
- 修改mongos內核代碼,所有請求全部延時600ms
- 同一臺機器起兩個同樣的mongos,通過埠區分
- 客戶端啟用6000個并發鏈接,超時時間500ms
通過上面的操作,可以保證所有請求超時,超時后客戶端又會立馬開始重新建鏈,再次建鏈后訪問mongodb還會超時,這樣就模擬了反復建鏈斷鏈的程序,此外,為了保證和雪崩故障環境一致,把2個mongos代理部署在同一臺物理機,
2.3.2 故障模擬測驗結果
為了保證和故障的mongos代理硬體環境一致,因此選擇故障同樣型別的服務器,并且作業系統版本一樣(2.6.32-642.el6.x86_64),程式都跑起來后,問題立馬浮現:

由于出故障的服務器作業系統版本linux-2.6過低,因此懷疑可能和作業系統版本有問題,因此升級同一型別的一臺物理機到linux-3.10版本,測驗結果如下:

從上圖可以看出,客戶端6000并發反復重連,服務端壓力正常,所有CPU消耗在us%,sy%消耗很低,用戶態CPU消耗3個CPU,內核態CPU消耗幾乎為0,這是我們期待的正常結果,因此覺得該問題可能和作業系統版本有問題,
為了驗證更高并反復建鏈斷鏈在Linux-3.10內核版本是否有2.6版本同樣的sy%內核態CPU消耗高的問題,因此把并發從6000提升到30000,驗證結果如下:
測驗結果:通過修改mongodb內核版本故意讓客戶端超時反復建鏈斷鏈,在linux-2.6版本中,1500以上的并發反復建鏈斷鏈系統CPU sy% 100%的問題即可浮現,但是,在Linux-3.10版本中,并發到10000后,sy%負載逐步增加,并發越高sy%負載越高,
總結:linux-2.6系統中,mongodb只要每秒有幾千的反復建鏈斷鏈,系統sy%負載就會接近100%,Linux-3.10,并發20000反復建鏈斷鏈的時候,sy%負載可以達到30%,隨著客戶端并發增加,sy%負載也相應的增加,Linux-3.10版本相比2.6版本針對反復建鏈斷鏈的場景有很大的性能改善,但是不能解決根本問題,
2.4 客戶端反復建鏈斷鏈引起sy% 100%根因
為了分析%sy系統負載高的原因,安裝perf獲取系統top資訊,發現所有CPU消耗在如下介面:
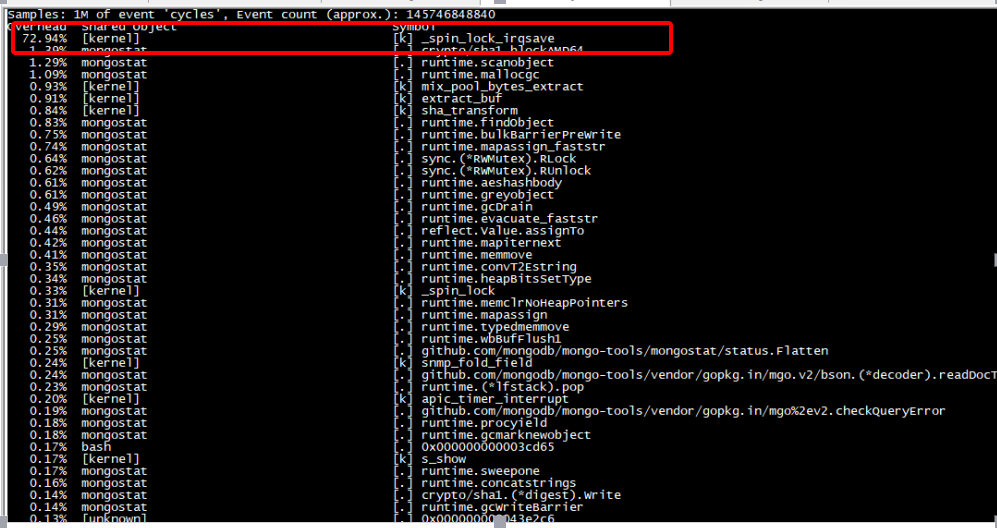
從perf分析可以看出,cpu 消耗在_spin_lock_irqsave函式,繼續分析內核態呼叫堆疊,得到如下堆疊資訊:
- 89.81% 89.81% [kernel] [k] _spin_lock_irqsave ?
- _spin_lock_irqsave ?
- mix_pool_bytes_extract ?
- extract_buf ?
extract_entropy_user ?
urandom_read ?
vfs_read ?
sys_read ?
system_call_fastpath ?
0xe82d
上面的堆疊資訊說明,mongodb在讀取 /dev/urandom ,并且由于多個執行緒同時讀取該檔案,導致消耗在一把spinlock上,
到這里問題進一步明朗了,故障root case 不是每秒幾萬的連接數導致sys 過高引起,根本原因是每個mongo客戶端的新鏈接會導致mongodb后端新建一個執行緒,該執行緒在某種情況下會呼叫urandom_read 去讀取亂數/dev/urandom ,并且由于多個執行緒同時讀取,導致內核態消耗在一把spinlock鎖上,出現cpu 高的現象,
2.5 mongodb內核亂數優化
2.5.1 mongodb內核原始碼定位分析
上面的分析已經確定,問題根源是mongodb內核多個執行緒讀取/dev/urandom亂數引起,走讀mongodb內核代碼,發現讀取該檔案的地方如下:
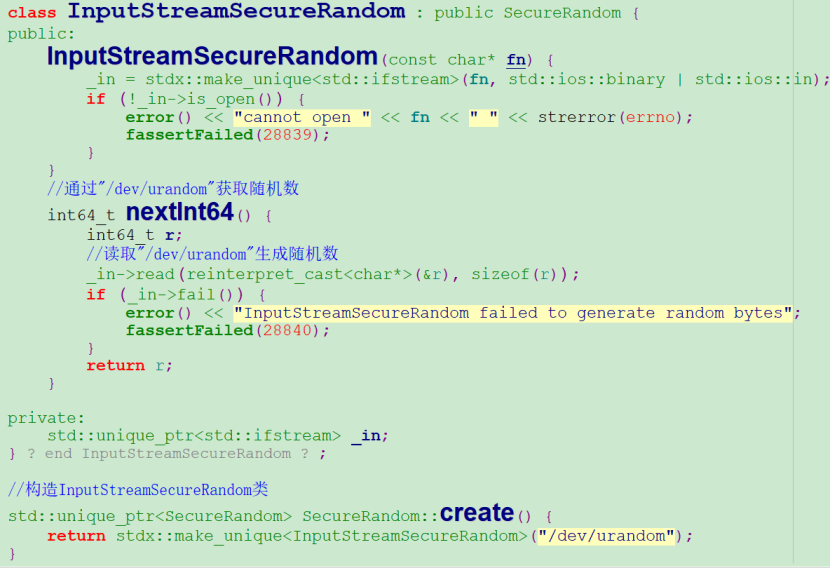
上面是生成亂數的核心代碼,每次獲取亂數都會讀取”/dev/urandom”系統檔案,所以只要找到使用該介面的地方即可即可分析出問題,
繼續走讀代碼,發現主要在如下地方:
//服務端收到客戶端sasl認證的第一個報文后的處理,這里會生成亂數
//如果是mongos,這里就是接收客戶端sasl認證的第一個報文的處理流程
Sasl_scramsha1_server_conversation::_firstStep(...) {
... ...
unique_ptr<SecureRandom> sr(SecureRandom::create());
binaryNonce[0] = sr->nextInt64();
binaryNonce[1] = sr->nextInt64();
binaryNonce[2] = sr->nextInt64();
... ...
}
//mongos相比mongod存盤節點就是客戶端,mongos作為客戶端也需要生成亂數
SaslSCRAMSHA1ClientConversation::_firstStep(...) {
... ...
unique_ptr<SecureRandom> sr(SecureRandom::create());
binaryNonce[0] = sr->nextInt64();
binaryNonce[1] = sr->nextInt64();
binaryNonce[2] = sr->nextInt64();
... ...
}
2.5.2 mongodb內核原始碼亂數優化
從2.5.1分析可以看出,mongos處理客戶端新連接sasl認證程序都會通過"/dev/urandom"生成亂數,從而引起系統sy% CPU過高,我們如何優化亂數演算法就是解決本問題的關鍵,
繼續分析mongodb內核原始碼,發現使用亂數的地方很多,其中有部分亂數通過用戶態演算法生成,因此我們可以采用同樣方法,在用戶態生成亂數,用戶態亂數生成核心演算法如下:
class PseudoRandom {
... ...
uint32_t _x;
uint32_t _y;
uint32_t _z;
uint32_t _w;
}

該演算法可以保證產生的資料隨機分布,該演算法原理詳見:
http://en.wikipedia.org/wiki/Xorshift
也可以查看如下git地址獲取演算法實作:
mongodb亂數生成演算法注釋
總結:通過優化sasl認證的亂數生成演算法為用戶態演算法后,CPU sy% 100%的問題得以解決,同時代理性能在短鏈接場景下有了數倍/數十倍的性能提升,
- 問題總結及疑問解答
從上面的分析可以看出,該故障由多種因素連環觸發引起,包括客戶端配置使用不當、mongodb服務端內核極端情況例外缺陷、監控不全等,總結如下:
- 客戶端配置不統一,同一個集群多個業務介面配置千奇百怪,超時配置、鏈接配置各不相同,增加了抓包排查故障的難度,超時時間設定太小容易引起反復重連,
- 客戶端需要配全所有mongos代理,這樣當一個代理故障的時候,客戶端SDK默認會剔除該故障代理節點,從而可以保證業務影響最小,就不會存在單點問題,
- 同一集群多個業務介面應該使用同一配置中心統一配置,避免配置不統一,
- Mongodb內核的新連接隨機演算法存在嚴重缺陷,在極端情況下引起嚴重性能抖動,甚至業務“雪崩”,
分析到這里,我們可以回答第1章節的6個疑問點了,如下:
為什么突發流量業務會抖動?
答:由于業務是java業務,采用鏈接池方式鏈接mongos代理,當有突發流量的時候,鏈接池會增加鏈接數來提升訪問mongodb的性能,這時候客戶端就會新增鏈接,由于客戶端眾多,造成可能瞬間會有大量新連接和mongos建鏈,鏈接建立成功后開始做sasl認證,由于認證的第一步需要生成亂數,就需要訪問作業系統"/dev/urandom"檔案,又因為mongos代理模型是默認一個鏈接一個執行緒,所以會造成瞬間多個執行緒訪問該檔案,進而引起內核態sy%負載過高,
為何mongos代理引起“雪崩”,流量為何跌零不可用?
答:原因客戶端某一時刻可能因為流量突然有增加,鏈接池中鏈接數不夠用,于是增加和mongos代理的鏈接,由于是老集群,代理還是默認的一個鏈接一個執行緒模型,這樣瞬間就會有大量鏈接,每個鏈接建立成功后,就開始sasl認證,認證的第一步服務端需要產生亂數,mongos服務端通過讀取"/dev/urandom"獲取亂數,由于多個執行緒同時讀取該檔案觸發內核態spinlock鎖CPU sy% 100%問題,由于sy%系統負載過高,由于客戶端超時時間設定過小,進一步引起客戶端訪問超時,超時后重連,重連后又進入sasl認證,又加劇了讀取"/dev/urandom"檔案,如此反復回圈持續,
此外,第一次業務抖動后,服務端擴容了8個mongos代理,但是客戶端沒有修改,造成B機房業務配置的2個代理在同一臺服務器,無法利用mongo java sdk的自動剔除負載高節點這一策略,所以最終造成”雪崩”
為什么資料節點沒有任何慢日志,但是代理負載卻CPU sy% 100%?
答:由于客戶端java程式直接訪問的是mongos代理,所以大量鏈接只發生在客戶端和mongos之間,同時由于客戶端超時時間設定太短(有介面設定位幾十ms,有的介面設定位一百多ms,有的介面設定位500ms),就造成在流量峰值的時候引起連鎖反應(突發流量系統負載高引起客戶端快速超時,超時后快速重連,進一步引起超時,無限死回圈),Mongos和mongod之間也是鏈接池模型,但是mongos作為客戶端訪問mongod存盤節點的超時很長,默認都是秒級別,所以不會引起反復超時建鏈斷鏈,
為何A機房代理抖動的時候,A機房業務切到B機房后,還是抖動?
答:當A機房業務抖動,業務切換到B機房的時候,客戶端需要重新和服務端建立鏈接認證,又會觸發大量反復建鏈斷鏈和讀取亂數"/dev/urandom"的流程,所以最終造成機房多活失敗,
為何例外時候抓包分析,客戶端頻繁建鏈斷鏈,并且同一個鏈接建鏈到斷鏈間隔很短?
答:頻繁建鏈斷鏈的根本原因是系統sy%負載高,客戶端極短時間內建立鏈接后又埠的原因是客戶端配置超時時間太短,
理論上代理就是七層轉發,消耗資源更少,相比mongod存盤應該更快,為何mongod存盤節點無任何抖動,mongos代理卻有嚴重抖動?
答:由于采用分片架構,所有mongod存盤節點前面都有一層mongos代理,mongos代理作為mongod存盤節點的客戶端,超時時間默認秒級,不會出現超時現象,也就不會出現頻繁的建鏈斷鏈程序,
如果mongodb集群采用普通復制集模式,客戶端頻繁建鏈斷鏈是否可能引起mongod存盤節點同樣的”雪崩”?
答:會,如果客戶端過多,作業系統內核版本過低,同時超時時間配置過段,直接訪問復制集的mongod存盤節點,由于客戶端和存盤節點的認證程序和與mongos代理的認證程序一樣,所以還是會觸發引起頻繁讀取"/dev/urandom"檔案,引起CPU sy%負載過高,極端情況下引起雪崩,
- “雪崩”解決辦法
從上面的一系列分析,問題在于客戶端配置不合理,加上mongodb內核認證程序讀取亂數在極端情況下存在缺陷,最終造成雪崩,如果沒有mongodb內核研發能力,可以通過規范化客戶端配置來避免該問題,當然,如果客戶端配置規范化,同時mongodb內核層面解決極端情況下的亂數讀取問題,這樣問題可以得到徹底解決,
4.1 JAVA SDK客戶端配置規范化
在業務介面很多,客戶端機器很多的業務場景,客戶端配置一定要做到如下幾點:
- 超時時間設定為秒級,避免超時時間設定過端引起反復的建鏈斷鏈,
- 客戶端需要配置所有mongos代理地址,不能配置單點,否則流量到一個mongos很容易引起瞬間流量峰值的建鏈認證,
- 增加mongos代理數量,這樣可以分流,保證同一時刻每個代理的新鍵鏈接盡可能的少,客戶端在多代理配置時,默認是均衡流量分發的,如果某個代理負載高,客戶端會自動剔除,
如果沒有mongodb內核原始碼研發能力,可以參考該客戶端配置方法,同時淘汰linux-2.6版本內核,采用linux-3.10或者更高版本內核,基本上可以規避踩同樣型別的坑,
4.2 mongodb內核原始碼優化(擯棄內核態獲取亂數,選擇用戶態亂數演算法)
詳見2.5.2 章節,
4.3 PHP短鏈接業務,如何規避踩坑
由于PHP業務屬于短鏈接業務,如果流量很高,不可避免的要頻繁建鏈斷鏈,也就會走sasl認證流程,最終多執行緒頻繁讀取"/dev/urandom"檔案,很容易引起前面的問題,這種情況,可以采用4.1 java客戶端類似的規范,同時不要使用低版本的Linux內核,采用3.x以上內核版本,就可以規避該問題的存在,
5. Mongodb內核原始碼設計與實作分析
本文相關的Mongodb執行緒模型及亂數演算法實作相關原始碼分析如下:
mongodb動態執行緒模型原始碼設計與實作分析
mongodb一個鏈接一個執行緒模型原始碼設計與實作分析
mongodb內核態及用戶態亂數演算法實作分析
看完三件事??
如果你覺得這篇內容對你還蠻有幫助,我想邀請你幫我三個小忙:
-
點贊,轉發,有你們的 『點贊和評論』,才是我創造的動力,
-
關注公眾號 『 java爛豬皮 』,不定期分享原創知識,
-
同時可以期待后續文章ing??
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/163887.html
標籤:Java
上一篇:SpringMVC系列之SpringMVC快速入門 MVC設計模式介紹+什么是SpringMVC+ SpringMVC的作用及其基本使用+組件決議+注解決議
下一篇:2、Spring Boot配置