在高并發、異步化等場景,執行緒池的運用可以說無處不在,執行緒池從本質上來講,即通過空間換取時間,因為執行緒的創建和銷毀都是要消耗資源和時間的,對于大量使用執行緒的場景,使用池化管理可以延遲執行緒的銷毀,大大提高單個執行緒的復用能力,進一步提升整體性能,
今天遇到了一個比較典型的線上問題,剛好和執行緒池有關,另外涉及到死鎖、jstack命令的使用、JDK不同執行緒池的適合場景等知識點,同時整個調查思路可以借鑒,特此記錄和分享一下,
01 業務背景描述
該線上問題發生在廣告系統的核心扣費服務,首先簡單交代下大致的業務流程,方便理解問題,

綠框部分即扣費服務在廣告召回扣費流程中所處的位置,簡單理解:當用戶點擊一個廣告后,會從C端發起一次實時扣費請求(CPC,按點擊扣費模式),扣費服務則承接了該動作的核心業務邏輯:包括執行反作弊策略、創建扣費記錄、click日志埋點等,
02 問題現象和業務影響
12月2號晚上11點左右,我們收到了一個線上告警通知:扣費服務的執行緒池任務佇列大小遠遠超出了設定閾值,而且佇列大小隨著時間推移還在持續變大,詳細告警內容如下:
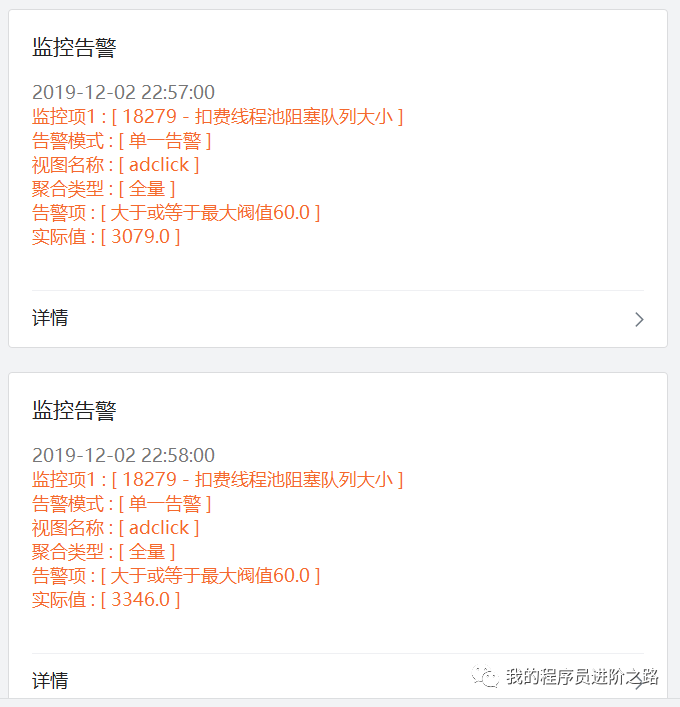
相應的,我們的廣告指標:點擊數、收入等也出現了非常明顯的下滑,幾乎同時發出了業務告警通知,其中,點擊數指標對應的曲線表現如下:
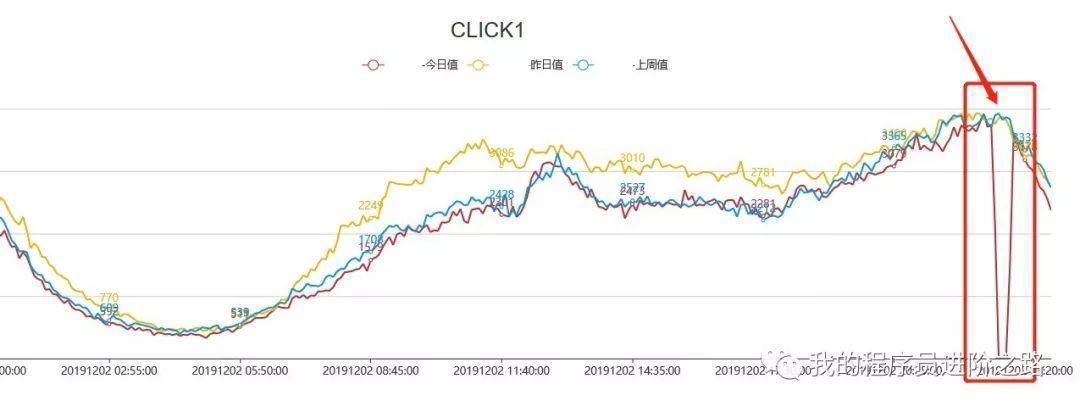
該線上故障發生在流量高峰期,持續了將近30分鐘后才恢復正常,
03 問題調查和事故解決程序
下面詳細說下整個事故的調查和分析程序,
第1步:收到執行緒池任務佇列的告警后,我們第一時間查看了扣費服務各個維度的實時資料:包括服務呼叫量、超時量、錯誤日志、JVM監控,均未發現例外,
第2步:然后進一步排查了扣費服務依賴的存盤資源(mysql、redis、mq),外部服務,發現了事故期間存在大量的資料庫慢查詢,
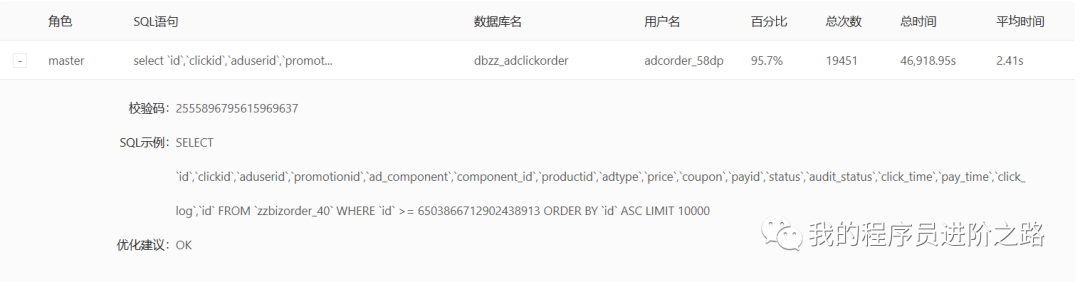
上述慢查詢來自于事故期間一個剛上線的大資料抽取任務,從扣費服務的mysql資料庫中大批量并發抽取資料到hive表,因為扣費流程也涉及到寫mysql,猜測這個時候mysql的所有讀寫性能都受到了影響,果然進一步發現insert操作的耗時也遠遠大于正常時期,
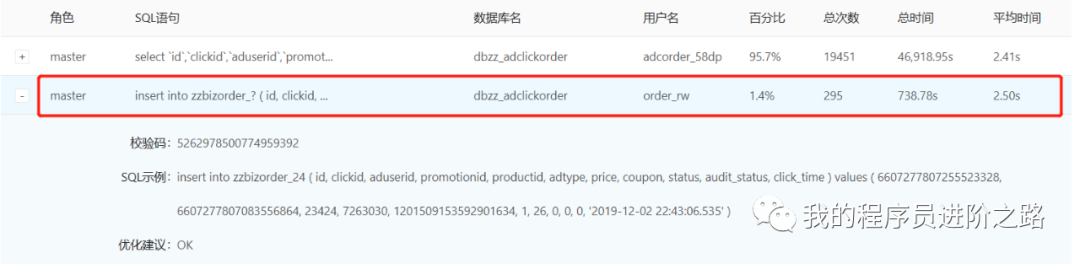
第3步:我們猜測資料庫慢查詢影響了扣費流程的性能,從而造成了任務佇列的積壓,所以決定立馬暫定大資料抽取任務,但是很奇怪:停止抽取任務后,資料庫的insert性能恢復到正常水平了,但是阻塞佇列大小仍然還在持續增大,告警并未消失,
第4步:考慮廣告收入還在持續大幅度下跌,進一步分析代碼需要比較長的時間,所以決定立即重啟服務看看有沒有效果,為了保留事故現場,我們保留了一臺服務器未做重啟,只是把這臺機器從服務管理平臺摘掉了,這樣它不會接收到新的扣費請求,
果然重啟服務的殺手锏很管用,各項業務指標都恢復正常了,告警也沒有再出現,至此,整個線上故障得到解決,持續了大概30分鐘,
04 問題根本原因的分析程序
下面再詳細說下事故根本原因的分析程序,
第1步:第二天上班后,我們猜測那臺保留了事故現場的服務器,佇列中積壓的任務應該都被執行緒池處理掉了,所以嘗試把這臺服務器再次掛載上去驗證下我們的猜測,結果和預期完全相反,積壓的任務仍然都在,而且隨著新請求進來,系統告警立刻再次出現了,所以又馬上把這臺服務器摘了下來,
第2步:執行緒池積壓的幾千個任務,經過1個晚上都沒被執行緒池處理掉,我們猜測應該存在死鎖情況,所以打算通過jstack命令dump執行緒快照做下詳細分析,
#找到扣費服務的行程號
$ ps aux|grep "adclick"
# 通過行程號dump執行緒快照,輸出到檔案中
$ jstack pid > /tmp/stack.txth
在jstack的日志檔案中,立馬發現了:用于扣費的業務執行緒池的所有執行緒都處于waiting狀態,執行緒全部卡在了截圖中紅框部分對應的代碼行上,這行代碼呼叫了countDownLatch的await()方法,即等待計數器變為0后釋放共享鎖,
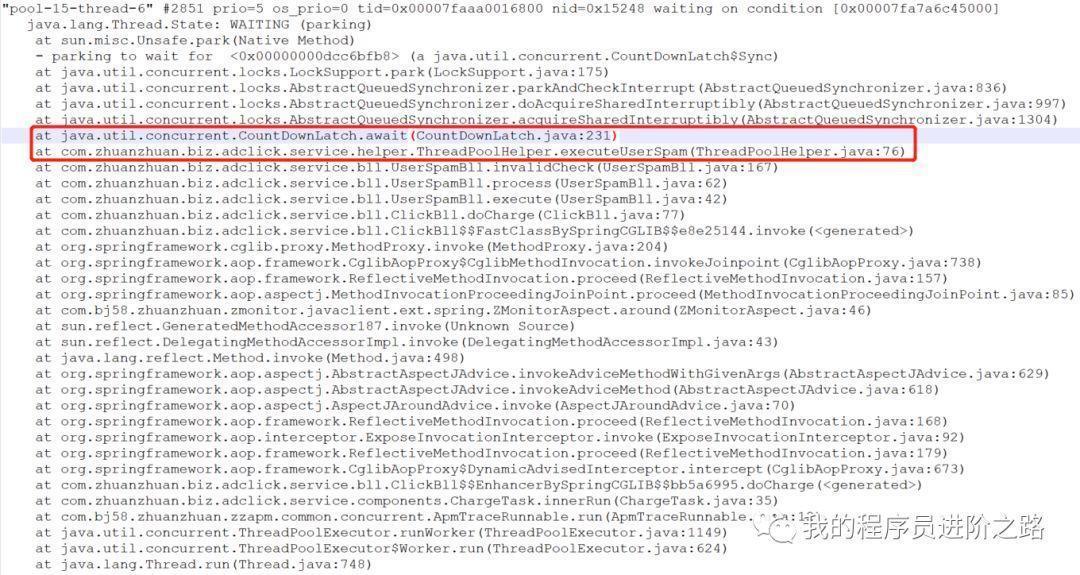
第3步:找到上述例外后,距離找到根本原因就很接近了,我們回到代碼中繼續調查,首先看了下業務代碼中使用了newFixedThreadPool執行緒池,核心執行緒數設定為25,針對newFixedThreadPool,JDK檔案的說明如下:
創建一個可重用固定執行緒數的執行緒池,以共享的無界佇列方式來運行這些執行緒,如果在所有執行緒處于活躍狀態時提交新任務,則在有可用執行緒之前,新任務將在佇列中等待,
關于newFixedThreadPool,核心包括兩點:
1、最大執行緒數 = 核心執行緒數,當所有核心執行緒都在處理任務時,新進來的任務會提交到任務佇列中等待;
2、使用了無界佇列:提交給執行緒池的任務佇列是不限制大小的,如果任務被阻塞或者處理變慢,那么顯然佇列會越來越大,
所以,進一步結論是:核心執行緒全部死鎖,新進的任務不對涌入無界佇列,導致任務佇列不斷增加,
第4步:到底是什么原因導致的死鎖,我們再次回到jstack日志檔案中提示的那行代碼做進一步分析,下面是我簡化過后的示例代碼:
/*** 執行扣費任務 */
public Result<Integer> executeDeduct(ChargeInputDTO chargeInput) {
ChargeTask chargeTask = new ChargeTask(chargeInput);
bizThreadPool.execute(() -> chargeTaskBll.execute(chargeTask ));
return Result.success();
}
/*** 扣費任務的具體業務邏輯 */
public class ChargeTaskBll implements Runnable {
public void execute(ChargeTask chargeTask) {
// 第一步:引數校驗
verifyInputParam(chargeTask);
// 第二步:執行反作弊子任務
executeUserSpam(SpamHelper.userConfigs);
// 第三步:執行扣費
handlePay(chargeTask);
// 其他步驟:點擊埋點等 ...
}
}
/*** 執行反作弊子任務 */
public void executeUserSpam(List<SpamUserConfigDO> configs) {
if (CollectionUtils.isEmpty(configs)) {
return;
} try {
CountDownLatch latch = new CountDownLatch(configs.size());
for (SpamUserConfigDO config : configs) {
UserSpamTask task = new UserSpamTask(config,latch);
bizThreadPool.execute(task);
}
latch.await();
} catch (Exception ex) {
logger.error("", ex);
}
}
通過上述代碼,大家能否發現死鎖是怎么發生的呢?根本原因在于:一次扣費行為屬于父任務,同時它又包含了多次子任務:子任務用于并行執行反作弊策略,而父任務和子任務使用的是同一個業務執行緒池,當執行緒池中全部都是執行中的父任務時,并且所有父任務都存在子任務未執行完,這樣就會發生死鎖,下面通過1張圖再來直觀地看下死鎖的情況:

假設核心執行緒數是2,目前正在執行扣費父任務1和2,另外,反作弊子任務1執行完了,反作弊子任務2和4都積壓在任務佇列中等待被調度,因為反作弊子任務2和4沒執行完,所以扣費父任務1和2都不可能執行完成,這樣就發生了死鎖,核心執行緒永遠不可能釋放,從而造成任務佇列不斷增大,直到程式OOM crash,
死鎖原因清楚后,還有個疑問:上述代碼在線上運行很長時間了,為什么現在才暴露出問題呢?另外跟資料庫慢查詢到底有沒有直接關聯呢?
暫時我們還沒有復現證實,但是可以推斷出:上述代碼一定存在死鎖的概率,尤其在高并發或者任務處理變慢的情況下,概率會大大增加,資料庫慢查詢應該就是導致此次事故出現的導火索,
05 解決方案
弄清楚根本原因后,最簡單的解決方案就是:增加一個新的業務執行緒池,用來隔離父子任務,現有的執行緒池只用來處理扣費任務,新的執行緒池用來處理反作弊任務,這樣就可以徹底避免死鎖的情況了,
06 問題總結
回顧事故的解決程序以及扣費的技術方案,存在以下幾點待繼續優化:
1、使用固定執行緒數的執行緒池存在OOM風險,在阿里巴巴Java開發手冊中也明確指出,而且用的詞是『不允許』使用Executors創建執行緒池, 而是通過ThreadPoolExecutor去創建,這樣讓寫的同學能更加明確執行緒池的運行規則和核心引數設定,規避資源耗盡的風險,
2、廣告的扣費場景是一個異步程序,通過執行緒池或者MQ來實作異步化處理都是可選的方案,另外,極個別的點擊請求丟失不扣費從業務上是允許的,但是大批量的請求丟棄不處理且沒有補償方案是不允許的,后續采用有界佇列后,拒絕策略可以考慮發送MQ做重試處理,--- 結束 ---
作者簡介:程式員,985碩士,前亞馬遜Java工程師,現58轉轉技術總監,持續分享技術和管理方向的文章,如果感興趣,可微信掃描下面的二維碼關注我的公眾號:『IT人的職場進階』

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/164032.html
標籤:Java
下一篇:【面經】5年Java面試親身經驗