KNN(K-Nearest Neighbors)演算法,又稱K近鄰演算法,單從字面意思我們就能知道,這個演算法肯定是和距離有關的,
KNN演算法的核心思想:
在一個特征空間中,如果某個樣本身邊和他最相鄰的K個樣本大多都屬于一個類別,那么這個樣本在很大程度上也屬于這個類別,且該樣本同樣具有這個類別的特性,
其實說白了就是“近朱者赤、近墨者黑”,你身邊離你最近的K個人中大多數人都屬于某一個類別,那么你很有可能也屬于這一個類別(當然,用人來舉例子不是很恰當)
該方法在“分類決策”上只依據最近鄰的k個樣本的類別來判斷待分樣本的類別,K通常是不大于20的一個整數,具體怎么選取,這個也很有學問,后邊會詳細講解,
上邊說了,一個待分樣本的所屬的類別,很大程度上取決于和他最近的K個樣本的類別,那么這個“最近”是如何計算出來的呢,比如一堆人站在一塊兒,我們可以可以輕易的計算出
一個人距他身邊的每個人的距離,那么資料呢?其實道理是一樣的,我們可以使用歐拉距離來計算,其實我們在中學幾何中學習二維平面內兩點間距離、三維空間內兩點間距離時已經學過了,
我們可以將二維資料看作是這兩個點都只有兩個特征,三維資料可以看成是有三個特征,那么當一組資料中每個資料都有多個特征時,我們也可以將其看作是多維空間中的一個點,
也同樣可以使用歐拉距離來計算,

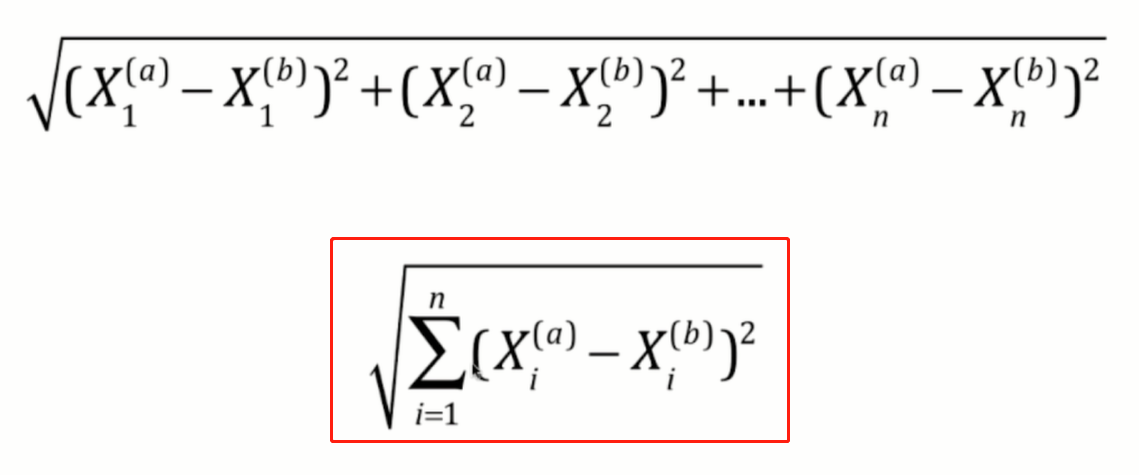
當拓展到多個特征之后,就會簡寫成上邊紅框中的公式,這在機器學習演算法中較為常見,
KNN演算法的計算步驟:
(1)計算待分類資料與各個樣本資料之間的距離
(2)對距離進行排序
(3)選取距離最小的前K個點
(4)統計前k個點所屬的類別
(5)回傳前K個點出現頻率最高的類別做為待分類資料的預測分類
手動封裝一個KNN演算法:
import math import numpy as np from collections import Counter class NKKClass(object): def __init__(self, K): # 初始化KNN類屬性 assert K > 0, "常數K需為正整數" self.K = K self._X_train = None # 私有的訓練特征陣列 self._y_train = None # 私有的訓練標簽向量 def fit(self, X_train, y_train): # 根據訓練特征陣列X_train和標簽向量y_train來訓練模型(當然,KNN演算法中是不需要訓練模型的) self._X_train = X_train self._y_train = y_train def predict(self, X_predict): # 傳入待預測的特征資料集X_predict,回傳這個特征資料集所對應的標簽向量 y_predict = [self._predict(i) for i in X_predict] return y_predict def _predict(self, i): # 給定單個特征資料,根據計算歐拉距離,回傳預測標簽 # 利用歐拉距離計算兩點間距離 distances = [ math.sqrt(np.sum((x_train - i)**2)) for x_train in self._X_train] nearset = np.argsort(distances) #將陣列升序排序,然后提取其所對應的索引index進行回傳 # 根據索引取出標簽向量中的值 topK_y = [ self._y_train[index] for index in nearset[:self.K]] # 統計array中每個元素出現頻率,n=1表示取出出現頻率最高的那個元素 votes = Counter.most_common(n=1)[0][0] return votes
def accuracy_score(self, y_test, y_predict): # 根據train_test_split得到的y_test和預測得到的y_predict計算分類準確度 return sum(y_true == y_predict) / len(y_true)
def score(self, X_test, y_test): # 根據 train_test_split拆分出來的X_test,y_test直接計算分類準確度 y_predict = self.predict(X_test) return self.accuracy_score(y_test, y_predict)
上邊這個類其實就是模仿著 scikit-learn機器學習庫中封裝的的kNN演算法來寫的,
下邊我們來加載 sklearn 庫中自帶的鳶尾花資料集來測驗一下吧
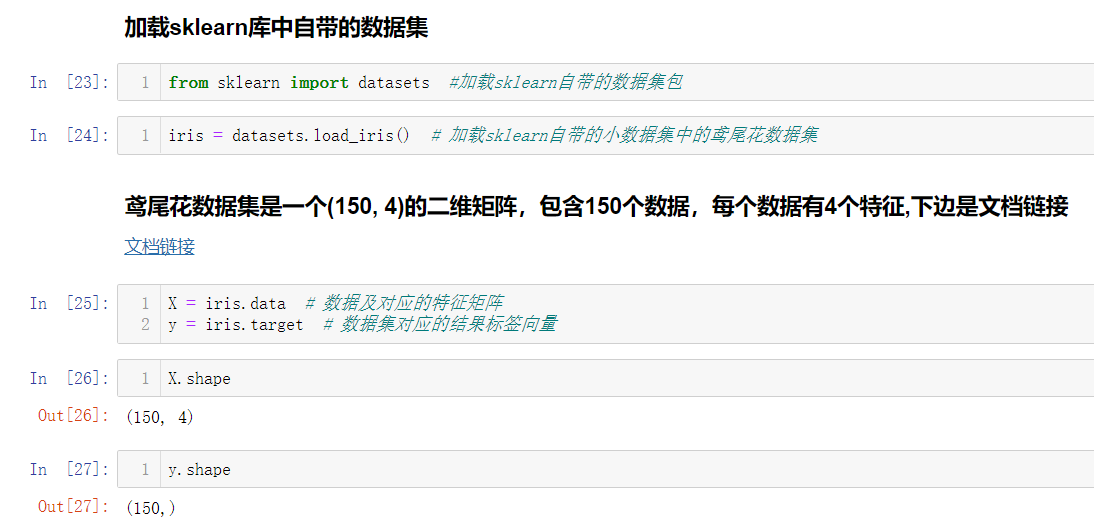
我們獲取到資料集后,并不能直接將所有資料集都作為訓練資料集,還是需要留下一小部分作為測驗資料集的,所以又牽扯到train_test_split的問題,而且鳶尾花資料集已經默認排過序了,
所以我們在進行train_test_split之前還需要先將特征資料集和標簽向量進行亂序才行的,
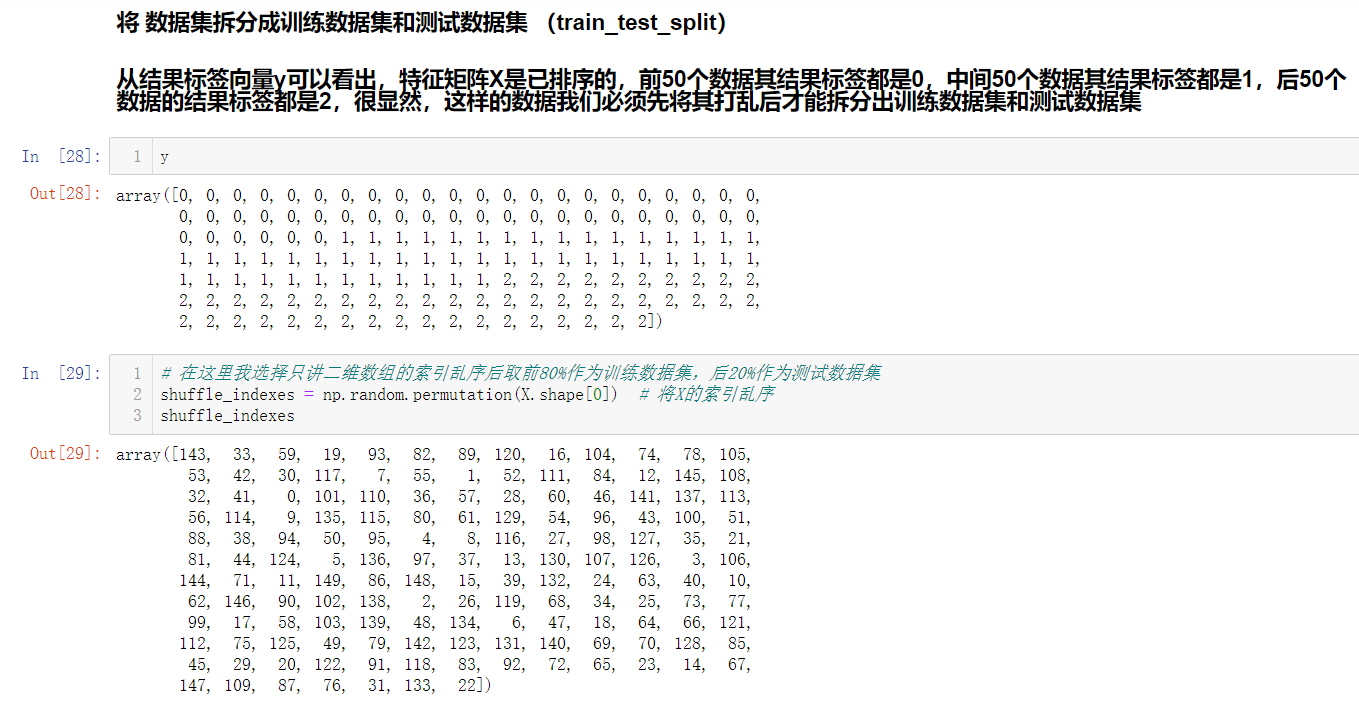
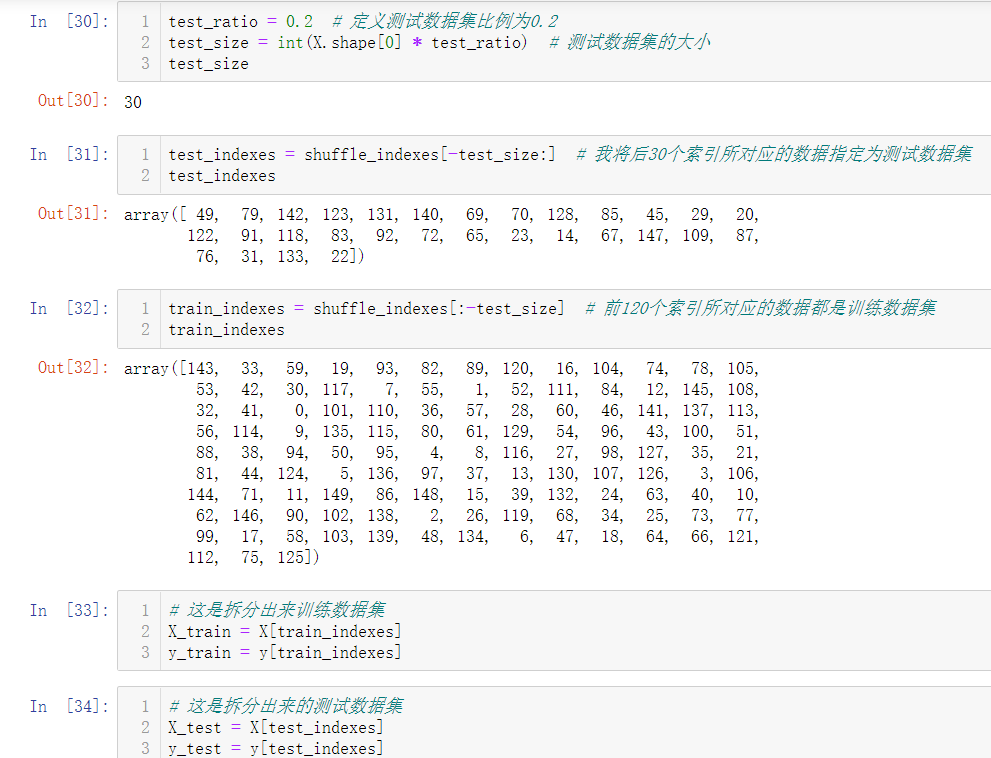
其實這個train_test_split程序,在sklearn中已經封裝好了,可以直接呼叫,
from sklearn.model_selection import train_test_split
train_test_split函式有4個引數,并且回傳四個回傳值:
4個引數:
train_data:需要被拆分的特征陣列
train_target:需要被拆分的標簽向量
test_size:如果是浮點數,在0-1之間,表示測驗資料集占總資料集的百分比,如果是整數,代表測驗資料集的行數,
random_state:隨機種子,默認為None
4個回傳值:
X_train 訓練特征陣列
X_test 測驗特征陣列
y_train 訓練標簽向量
y_test 測驗標簽向量
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
接下來呼叫sklearn庫,直接使用KNN演算法對鳶尾花資料集進行預測,計算分類準確度:
# 加載sklearn庫中KNN演算法的類 from sklearn.neighbors import KNeighborsClassifier # 加載sklearn自帶的資料包 from sklearn import datasets # 加載sklearn自帶的train_test_split函式 from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # 加載資料包中自帶的小資料集(鳶尾花資料集) iris = datasets.load_iris() X = iris.data # 資料集的特征矩陣 y = iris.target # 資料集的標簽向量 # 將資料集拆分,二八分 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=5) # 實體化,n_neighbors就是KNN演算法中的那個K KNN_classifier = KNeighborsClassifier(n_neighbors=6) KNN_classifier.fit(X_train, y_train) # 對訓練資料集進行擬合 predict_y_test = KNN_classifier.predict(X_test) # 對測驗的特征陣列進行預測 # 針對train_test_split得到的y_test和預測出來的標簽向量進行計算分類準確度 Classification_accuracy = accuracy_score(y_test, predict_y_test) print(Classification_accuracy) # 針對train_test_split得到的測驗用的特征陣列和標簽向量,直接計算其分類準確度(不用先計算出測驗標簽向量) Classification_accuracy = KNN_classifier.score(X_test, y_test) print(Classification_accuracy)

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/164058.html
標籤:Python